This document introduces machine learning and supervised learning. It discusses learning a classifier from labeled examples to predict a target variable. The key points covered are:
- Supervised learning involves learning a function that maps inputs to outputs from example input-output pairs.
- The goal is to learn a hypothesis h that has low error on the training set and generalizes well to new examples.
- The version space is the set of all hypotheses consistent with the training data.
- Controlling the complexity of the hypothesis class H via measures like VC dimension can improve generalization.
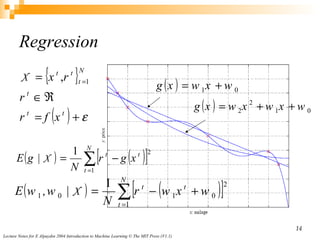
- For classification, multiple target classes are handled by learning one hypothesis per class. Regression learns a real-valued target function.
- There is a trade
![INTRODUCTION TO Machine Learning ETHEM ALPAYDIN © The MIT Press, 2004 [email_address] http://www.cmpe.boun.edu.tr/~ethem/i2ml Lecture Slides for](https://image.slidesharecdn.com/alpaydin-chapter-22167/85/Alpaydin-Chapter-2-1-320.jpg)