Downloaded 130 times

















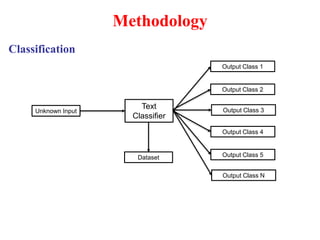










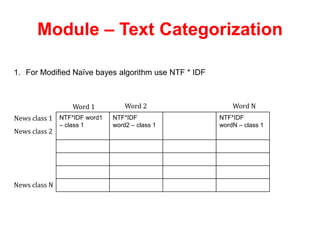














The document provides an overview of a proposed text categorization system using a modified Naive Bayes algorithm. It includes sections on the problem definition, objectives, literature review, methodology, proposed system architecture consisting of modules for dataset preprocessing, text categorization using the modified algorithm, a comparative study. The system would use a 20 newsgroup dataset, perform text reduction during preprocessing, classify unknown text, and compare the performance of the existing and proposed algorithms. It lists the software and hardware requirements and provides references for related work.




























































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2785-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2740-thumbnail.jpg?width=640&height=640&fit=bounds)

























