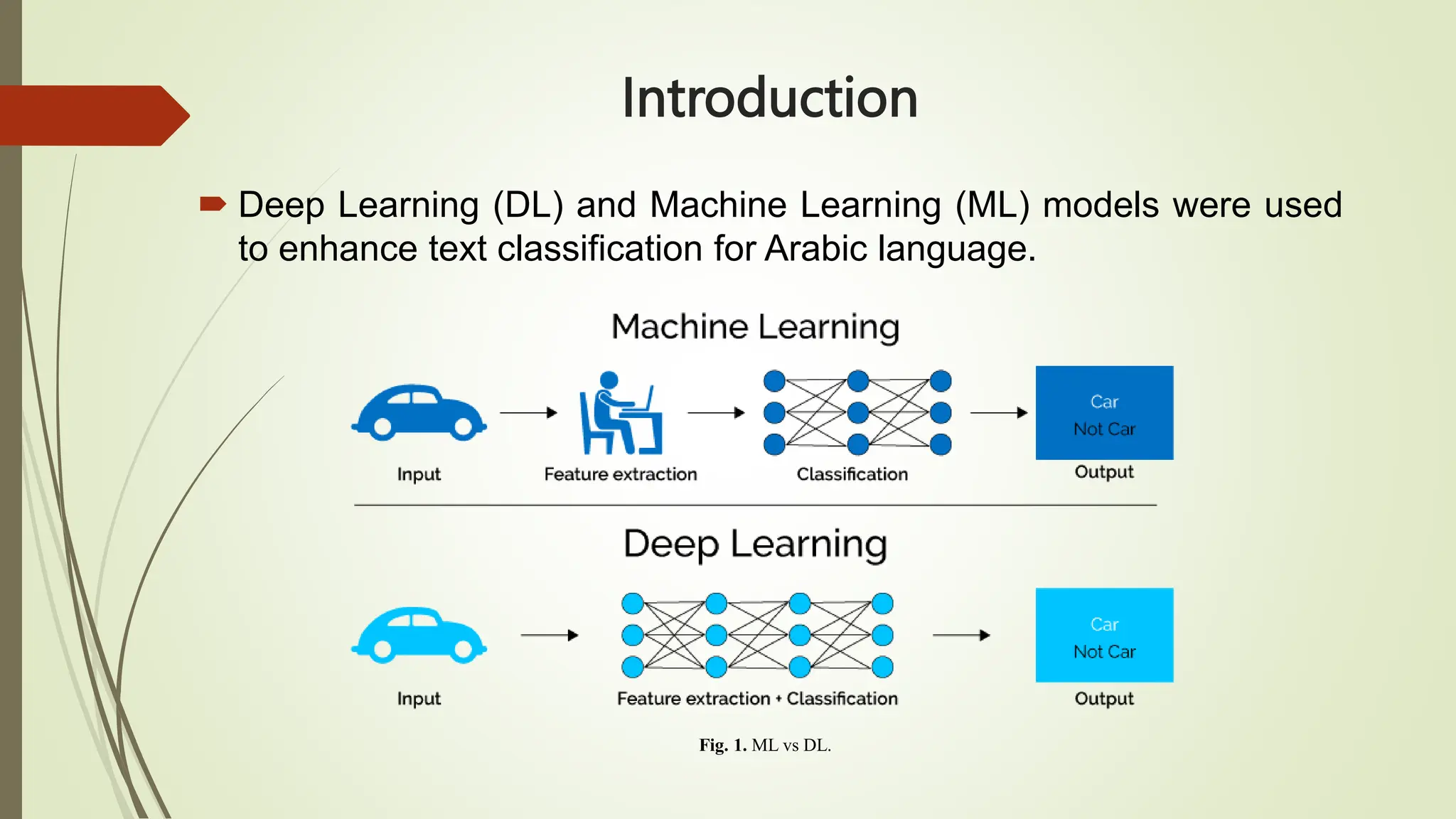
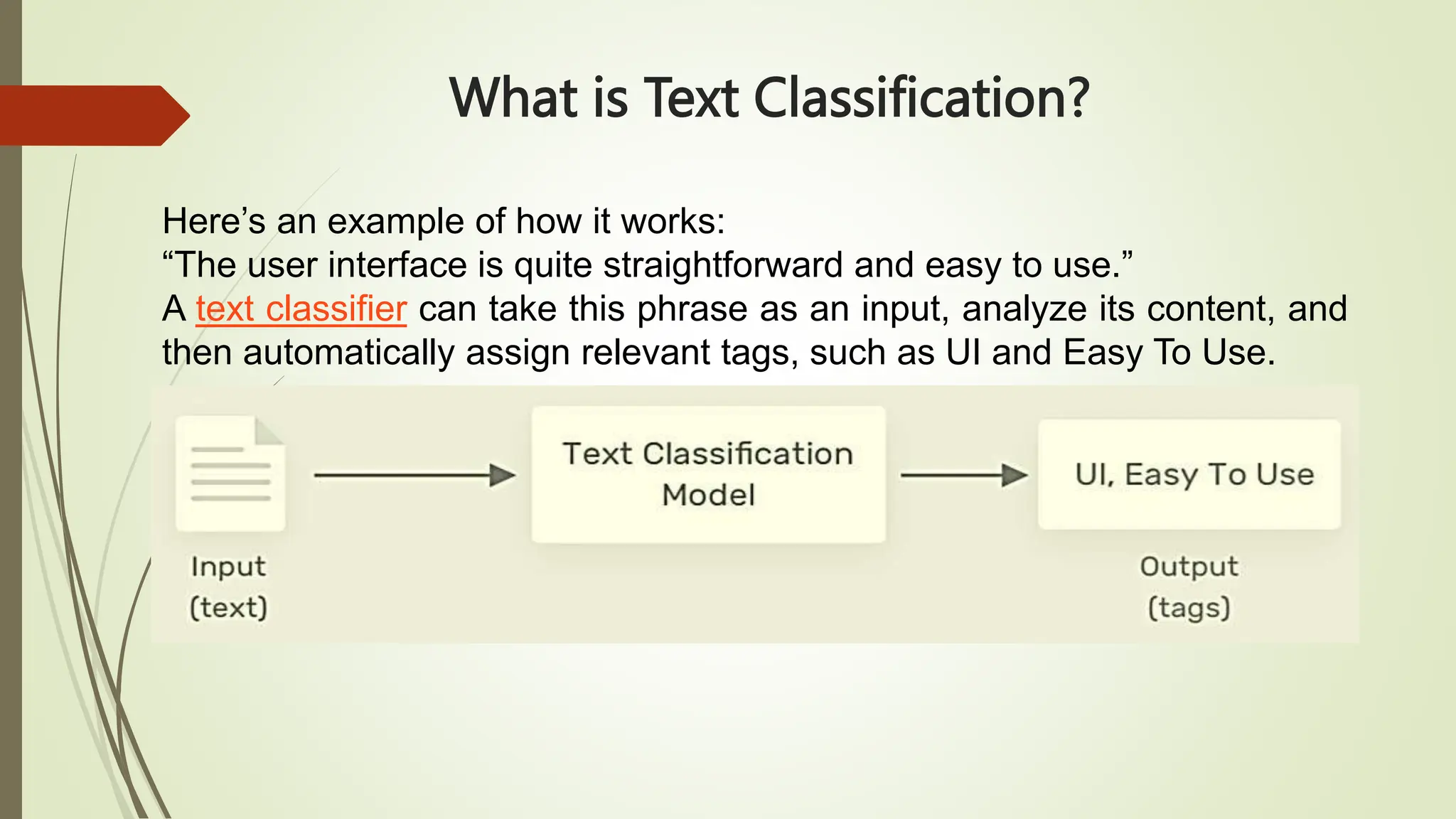
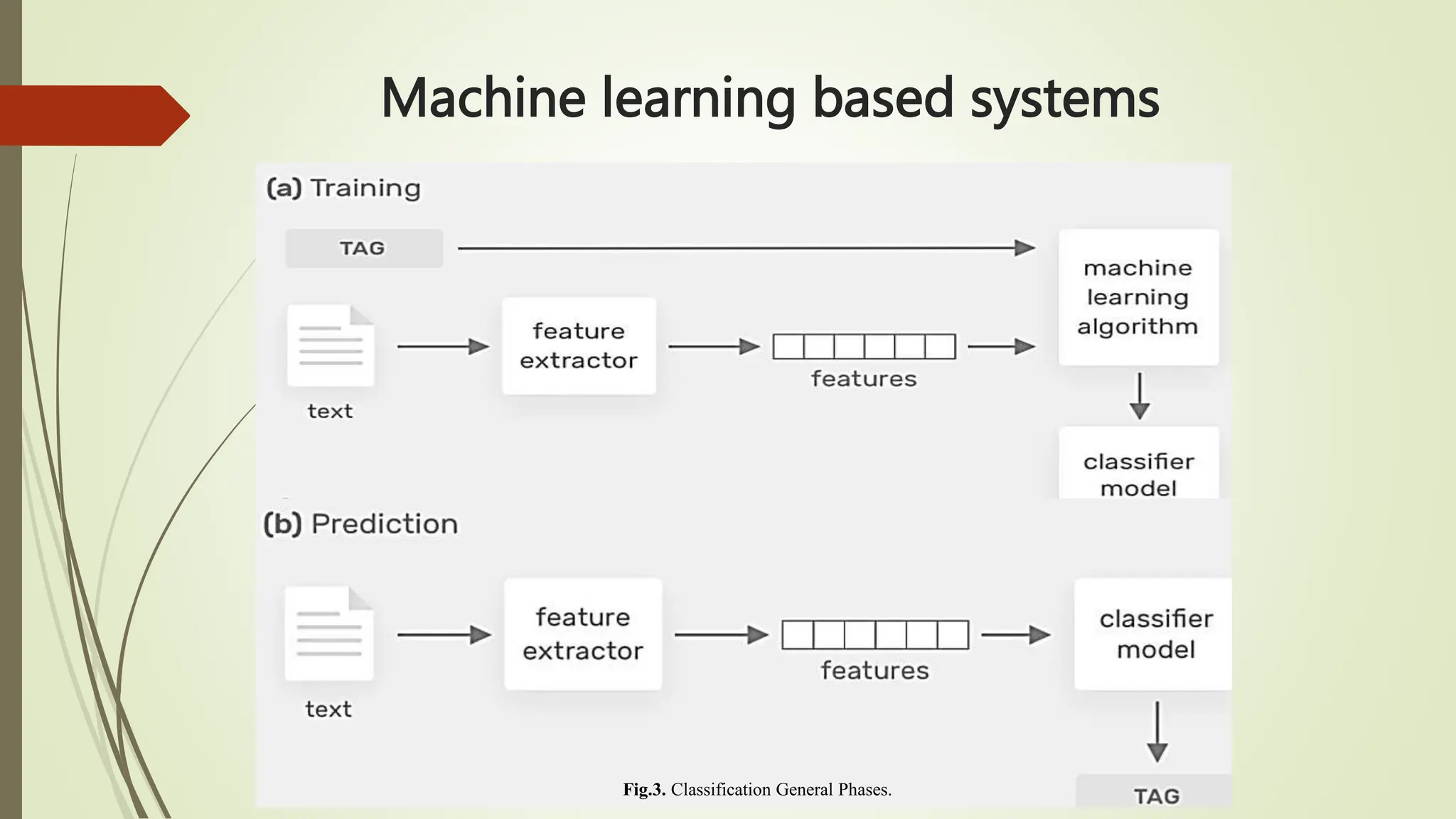
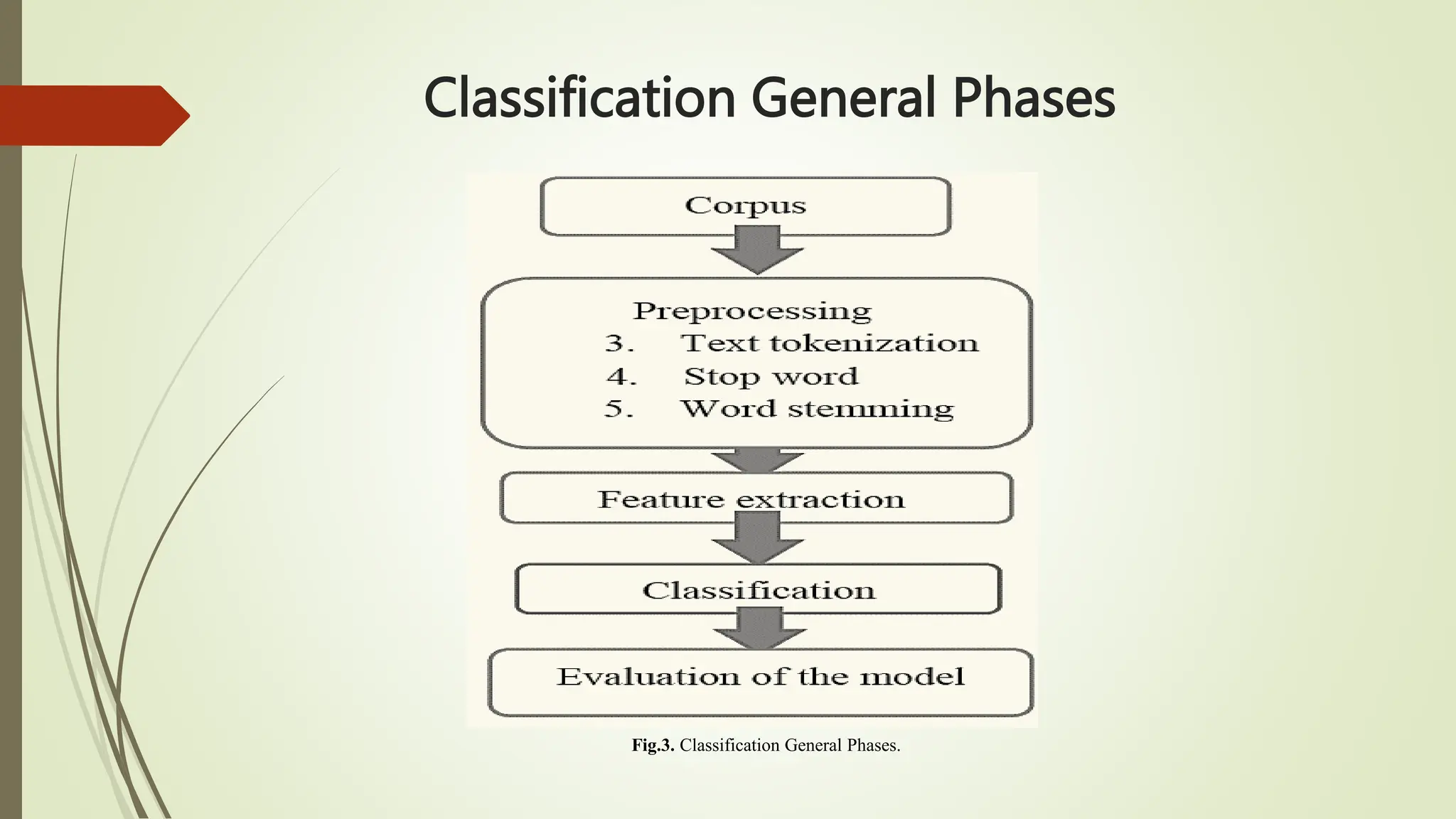
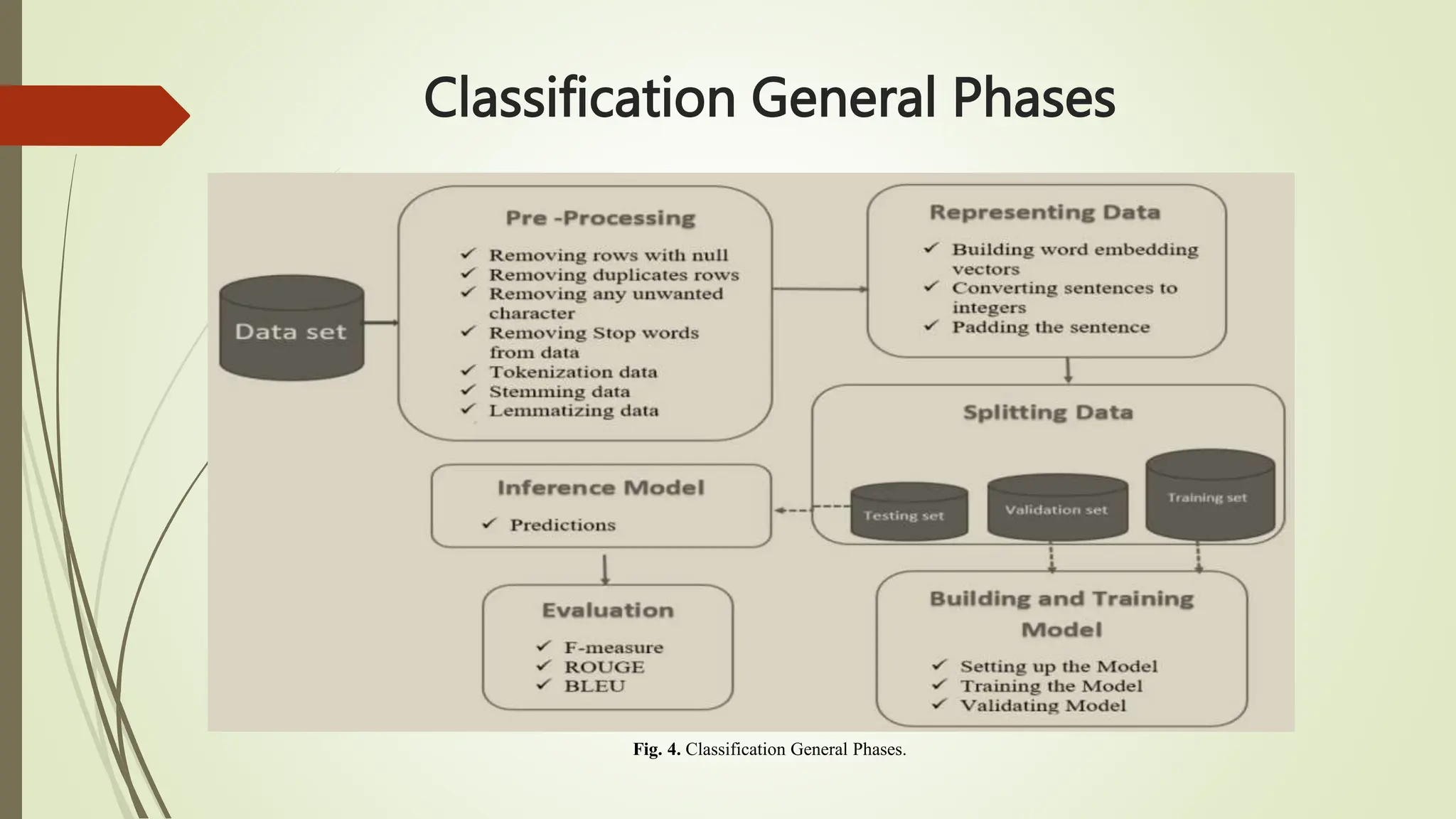
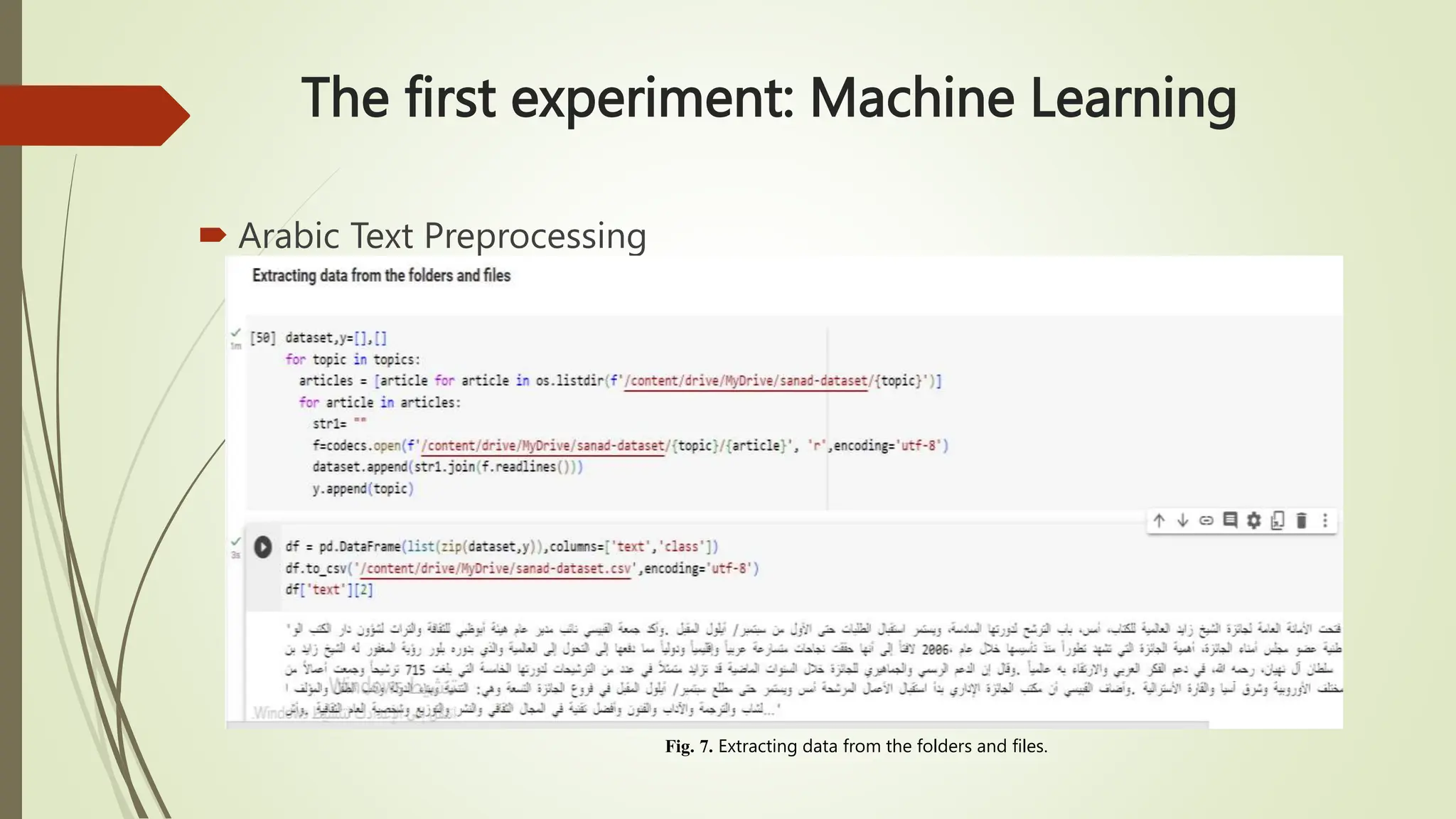
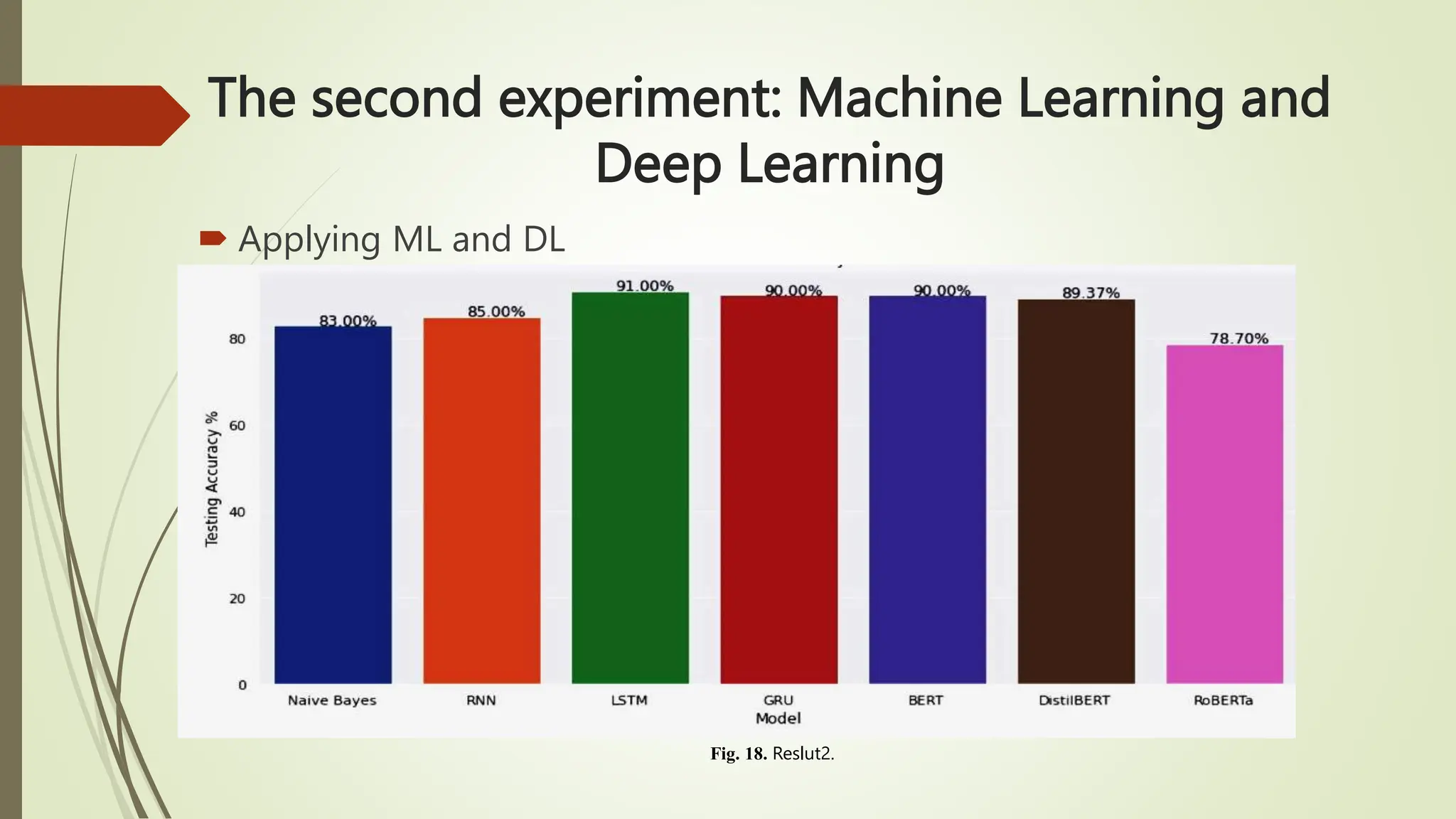
The document outlines text classification, a crucial technique in natural language processing (NLP) that organizes unstructured text data into predefined categories, enhancing data analysis while addressing challenges specific to the Arabic language. It discusses the growing importance of Arabic NLP due to limited content availability and presents findings from experiments utilizing machine learning and deep learning techniques, highlighting algorithms like logistic regression and GRU. The conclusion emphasizes the need for improved classification frameworks to optimize Arabic text processing and its applications.



















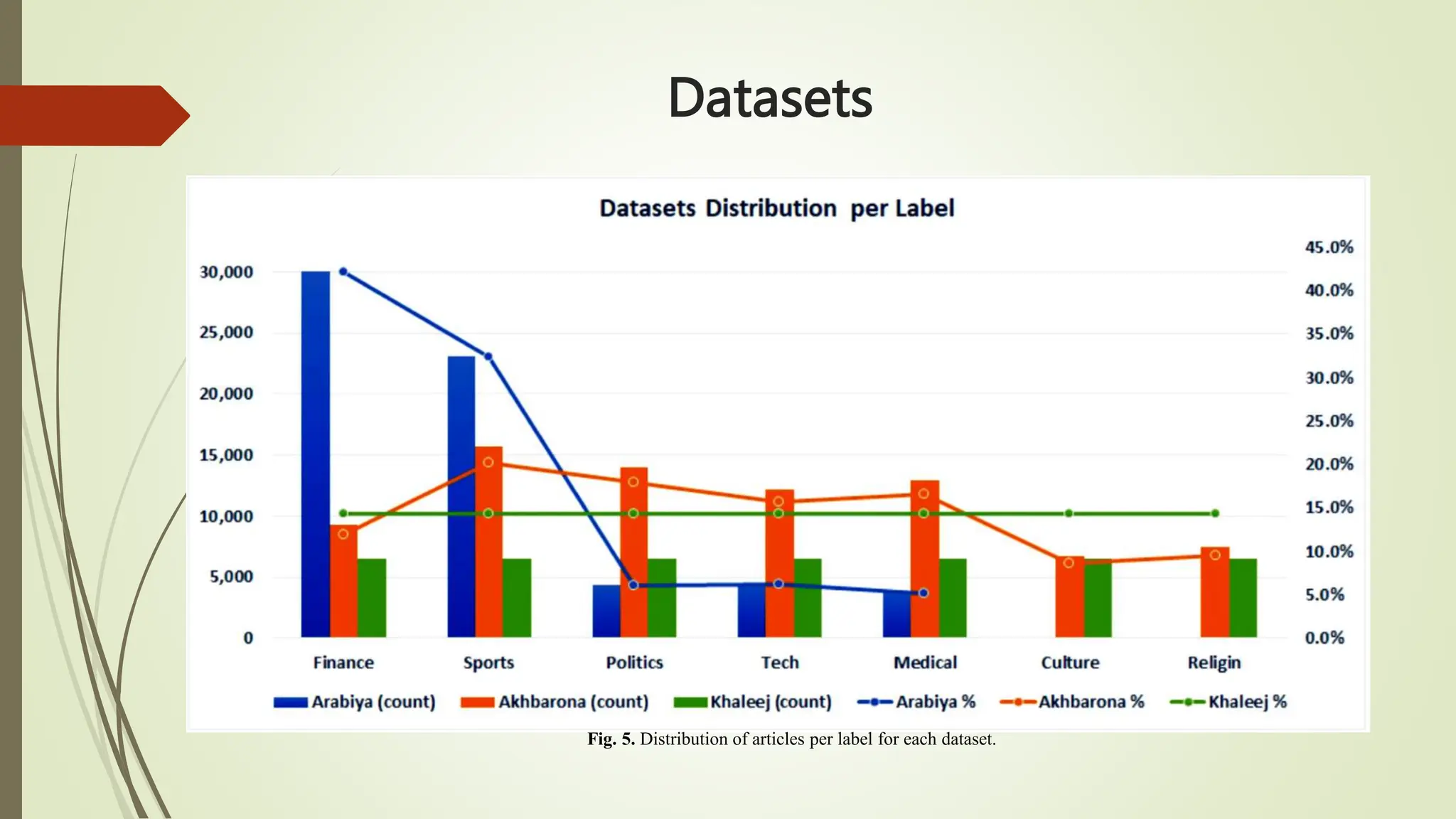
![Datasets
SANAD Dataset is a large collection of Arabic news articles that can be
used in different Arabic NLP tasks such as Text Classification and Word
Embedding. The articles were collected using Python scripts written
specifically for three popular news websites: AlKhaleej, AlArabiya and
Akhbarona.
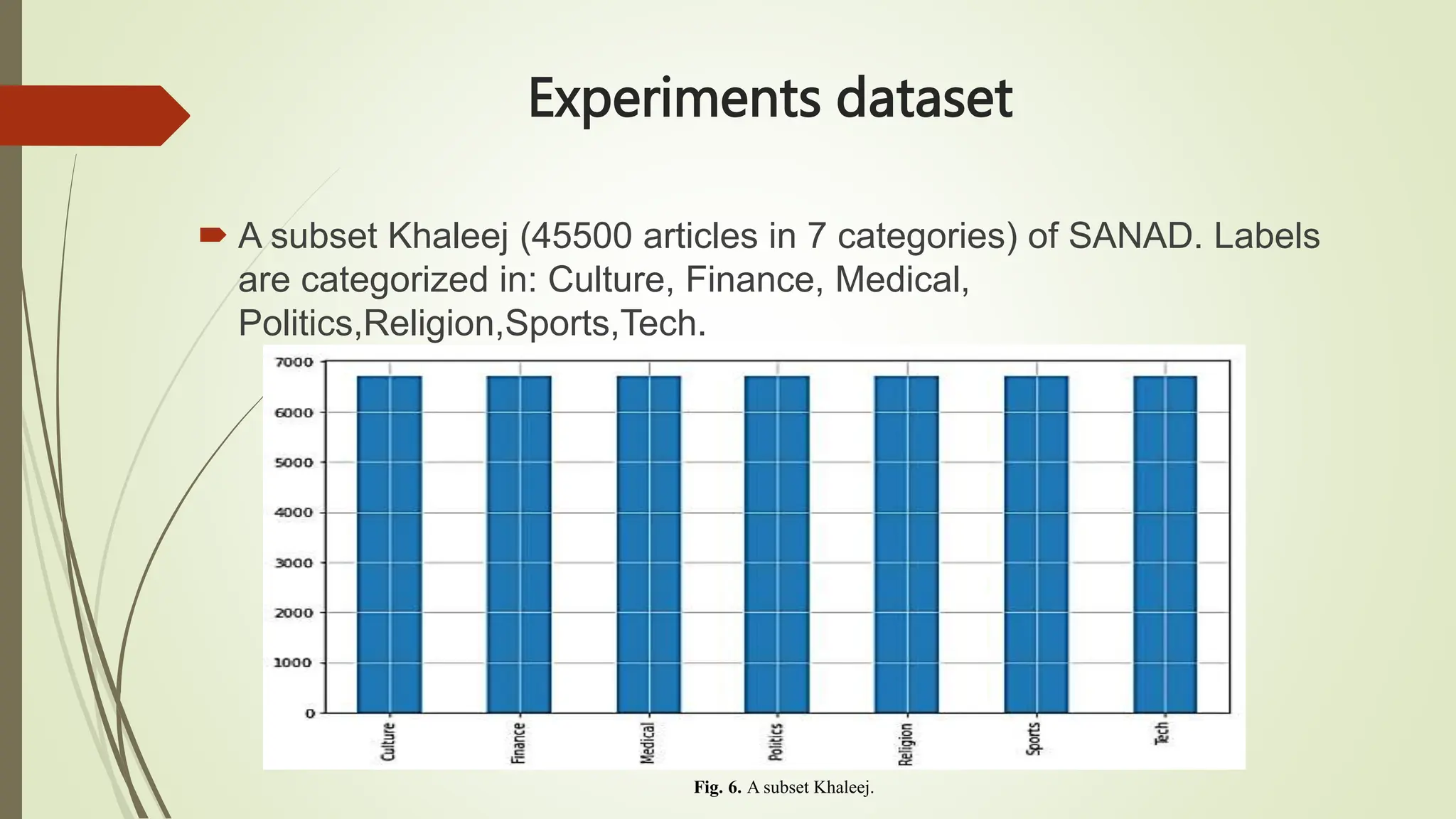
All datasets have seven categories [Culture, Finance, Medical, Politics,
Religion, Sports and Tech], except AlArabiya which doesn’t have
[Religion]. SANAD contains a total number of 190k+ articles.
SANAD has a total number of 194,797 articles categorized and formatted
as shown in Fig.2
In general, SANAD adopted the annotation of each article as appeared in
its news portal source. Only one collection of articles is manually re-
labeled to enrich the ‘politics’ category in AlArabiya dataset.](https://image.slidesharecdn.com/textclassification-231111150156-88efb0bd/75/Text-Classification-pptx-25-2048.jpg)


























![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2785-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2740-thumbnail.jpg?width=640&height=640&fit=bounds)





























