

















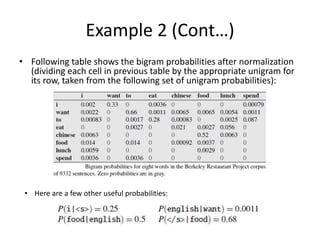


The document discusses N-gram language models, which assign probabilities to sequences of words. An N-gram is a sequence of N words, such as a bigram (two words) or trigram (three words). The N-gram model approximates the probability of a word given its history as the probability given the previous N-1 words. This is called the Markov assumption. Maximum likelihood estimation is used to estimate N-gram probabilities from word counts in a corpus.









































![[Book Reading] 機械翻訳 - Section 3 No.1](https://cdn.slidesharecdn.com/ss_thumbnails/languagemodel-150903031654-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)













































