Downloaded 38 times









![Speeds
• 1, 10, 25, 40, 100, 200Gbps
• Faster network doesn’t
necessarily mean a faster
runtime
• Many workloads consist of
relatively short bursts rather
than sustainable throughput:
higher bandwidth may not have
any effect
10#UnifiedAnalytics #SparkAISummit
0
100
200
300
400
500
600
700
800
Flink
TeraSort
Flink
PageRank
PowerGraph
PageRank
Timely
PageRank
Effect of network speed
on workload runtime*
1GbE 10GbE 40GbE
* “On The [Ir]relevance of Network Performance for Data Processing” by Trivedi et al.](https://image.slidesharecdn.com/072020yuvaldeganijithinjose-190508203942/75/Tackling-Network-Bottlenecks-with-Hardware-Accelerations-Cloud-vs-On-Premise-10-2048.jpg)







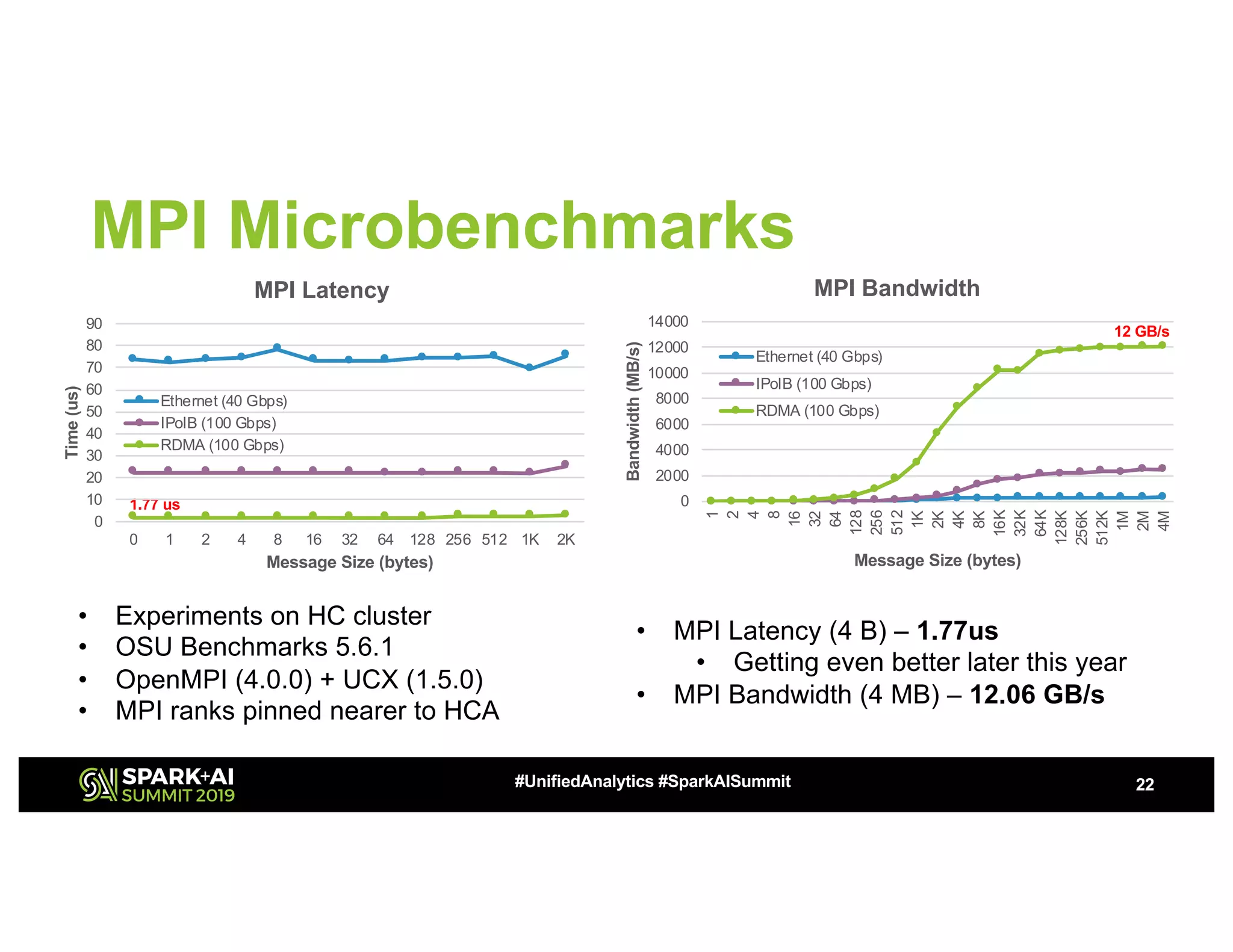





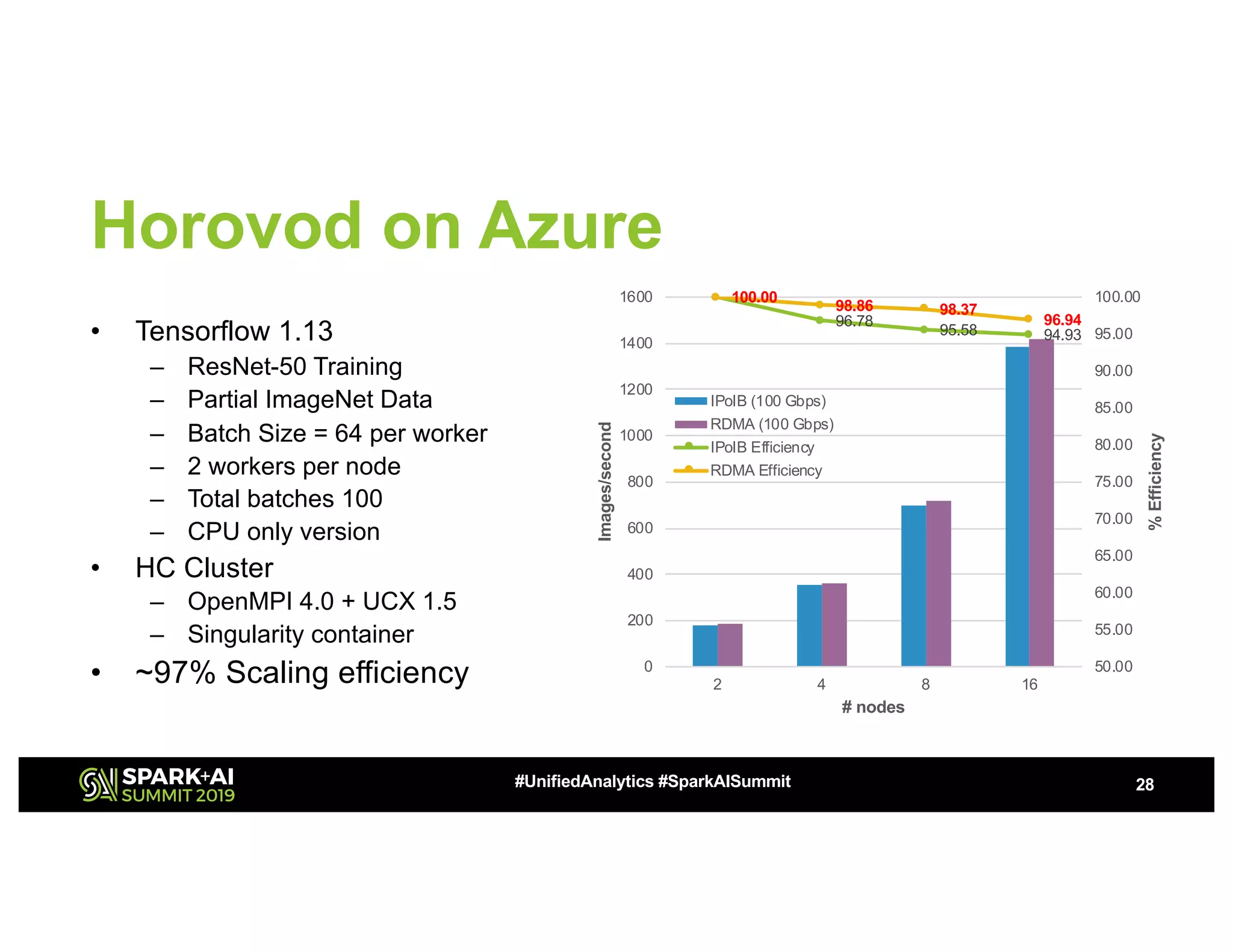

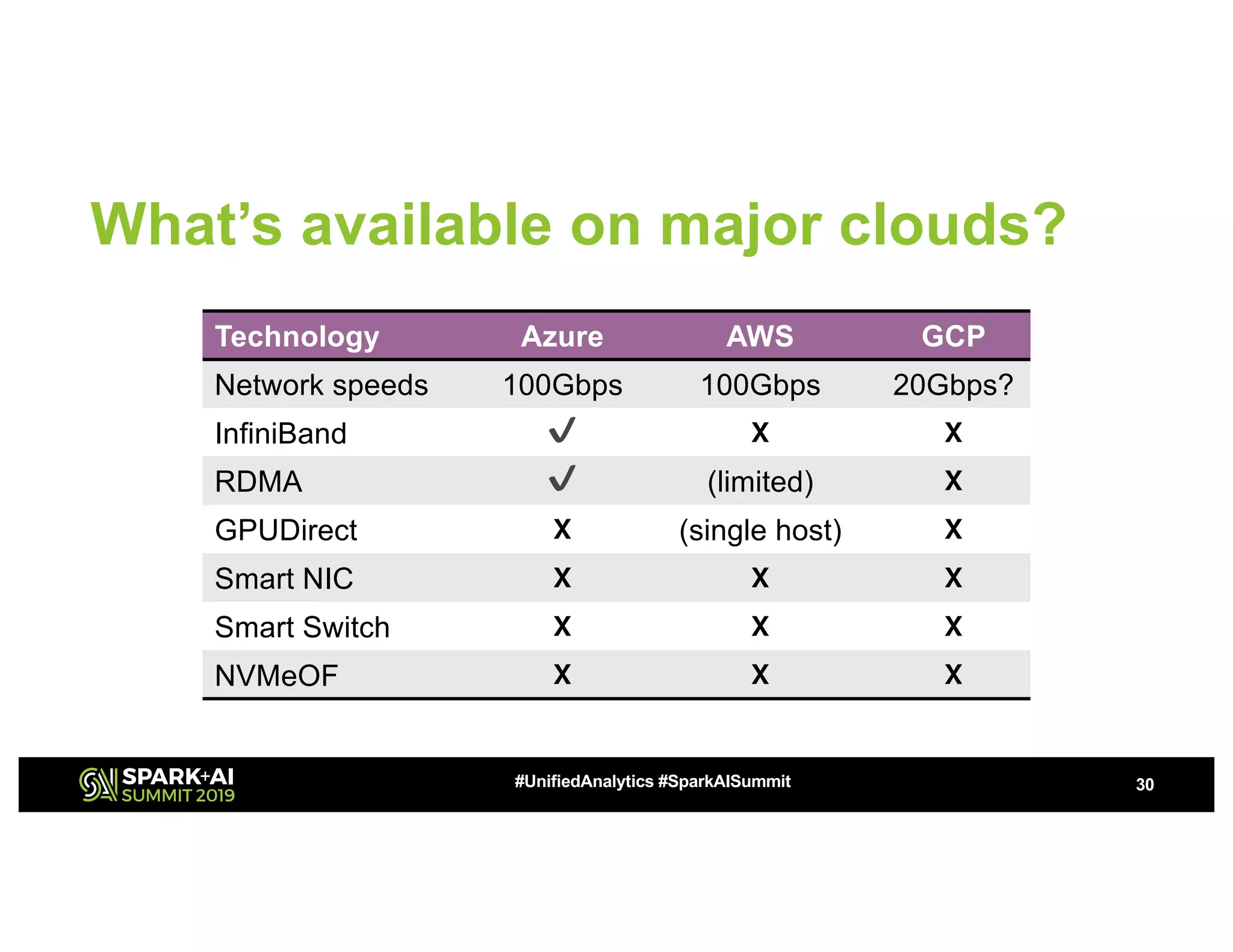




The document discusses the challenges of network bottlenecks in compute clusters and how hardware acceleration can address these issues to improve performance. It highlights technologies such as RDMA, GPUDirect, and NVMe over Fabrics, along with their potential to reduce latency and overhead. The document also presents Azure's HPC offerings and the benefits of accelerated frameworks for big data applications.














![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)