Downloaded 73 times


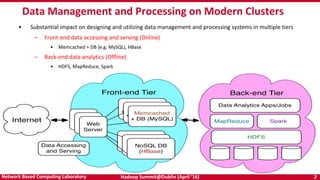
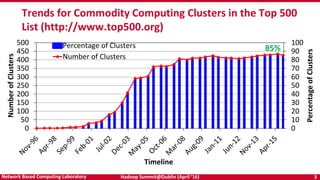


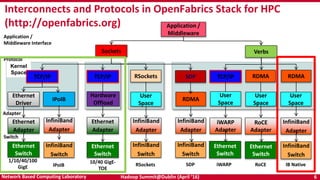
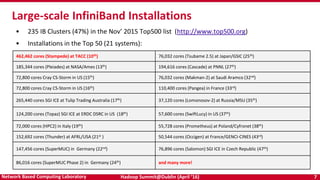

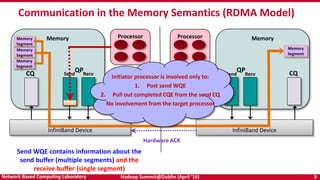
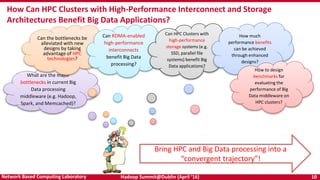
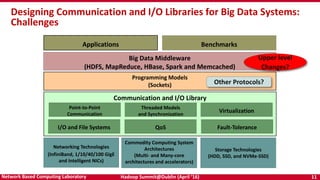
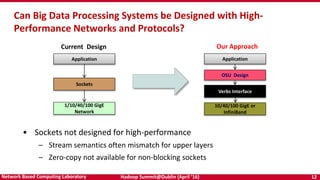







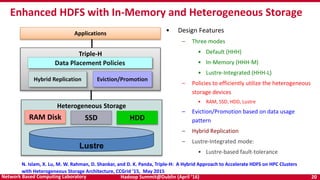
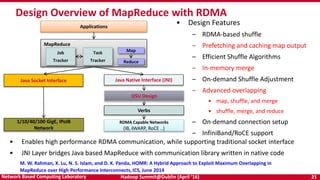

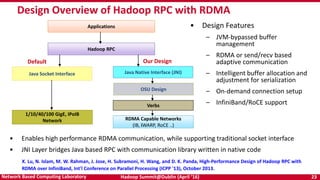
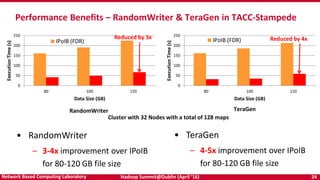
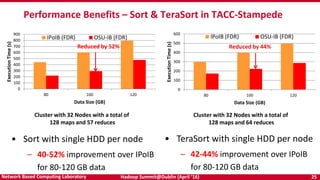
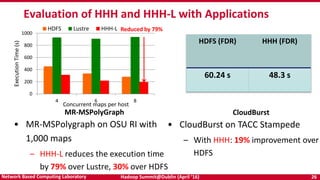
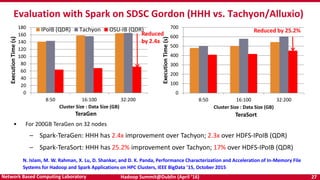
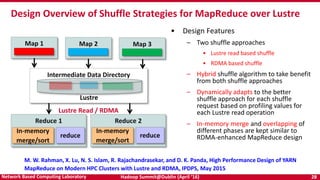
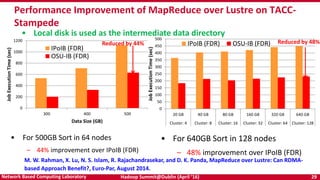
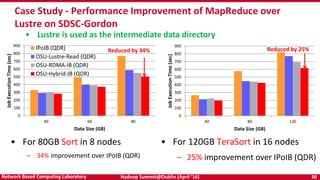

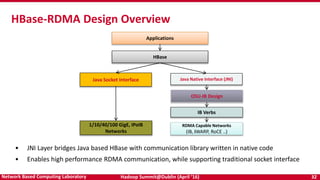
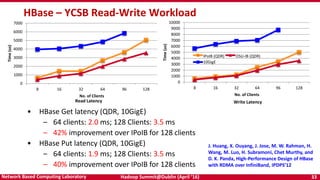



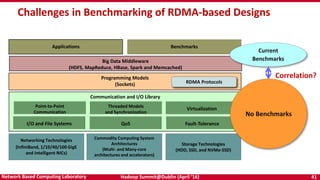
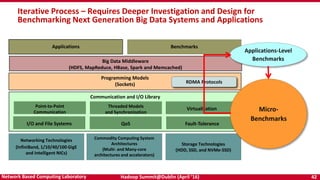








The document discusses accelerating Apache Hadoop through high-performance networking and I/O technologies. It describes how technologies like InfiniBand, RoCE, SSDs, and NVMe can benefit big data applications by alleviating bottlenecks. It outlines projects from the High-Performance Big Data project that implement RDMA for Hadoop, Spark, HBase and Memcached to improve performance. Evaluation results demonstrate significant acceleration of HDFS, MapReduce, and other workloads through the high-performance designs.

































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









