Downloaded 184 times




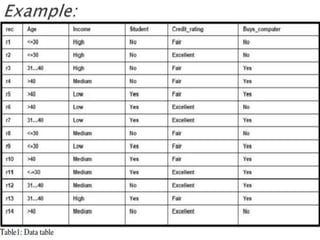










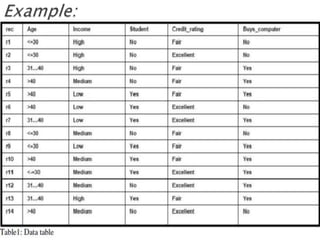









The document provides an overview of Bayesian decision theory and naive Bayesian classification. It discusses how Bayesian decision theory predates other machine learning techniques and forms the basis of classifiers like naive Bayes. It then explains the Bayes theorem and how it is used for probability inference and decision making. An example of predicting whether a customer will buy a computer is used to illustrate Bayesian reasoning. Finally, the document describes how the naive Bayes classifier works by making a strong independence assumption between features to simplify computations. It gives the mathematical formulas and works through an example to classify a customer profile.















































