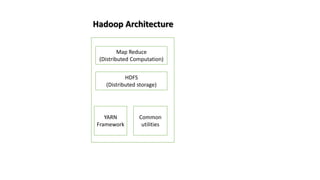
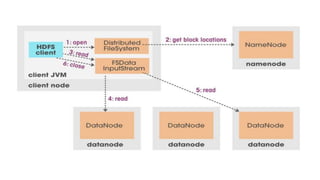
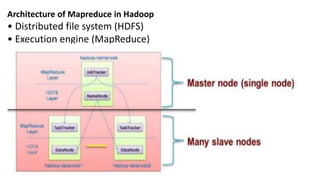
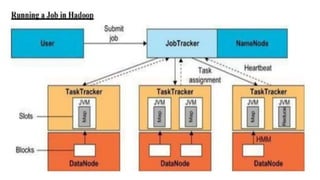
Hadoop is an open source framework that allows distributed processing of large datasets across clusters of computers. It uses a master-slave architecture where a single node acts as the master (NameNode) to manage file system metadata and job scheduling, while other nodes (DataNodes) store data blocks and perform parallel processing tasks. Hadoop distributes data storage across clusters using HDFS for fault tolerance and high throughput. It distributes computation using MapReduce for parallel processing of large datasets. Common users of Hadoop include large internet companies for applications like log analysis, machine learning and reporting.