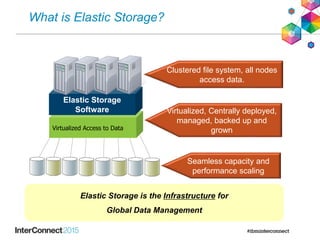
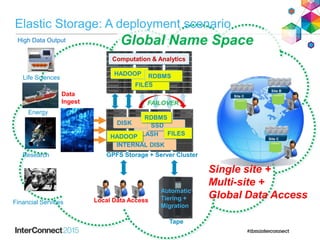
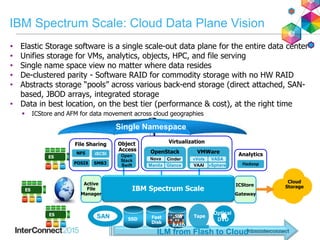
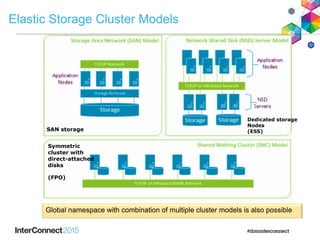
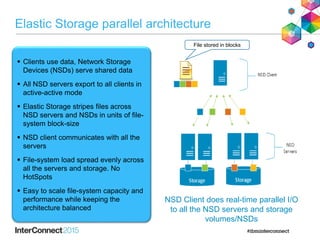
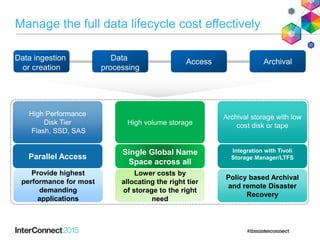
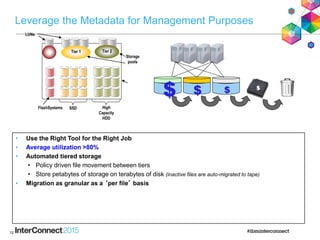
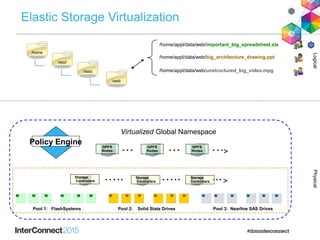
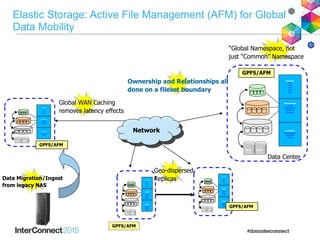
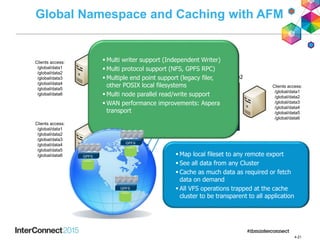
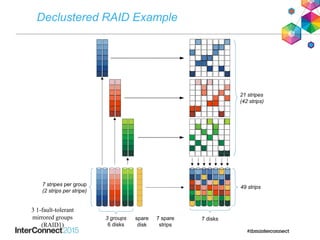
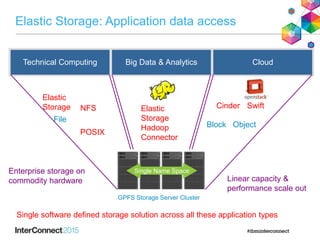
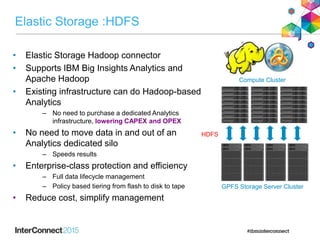
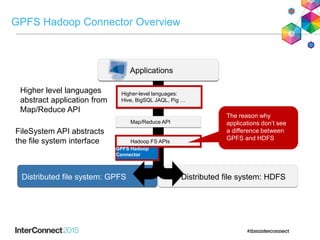
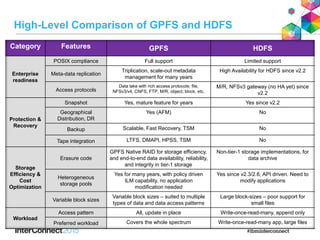
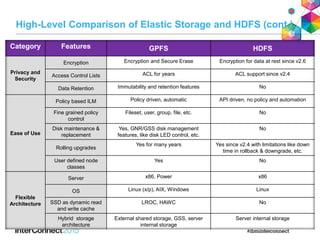
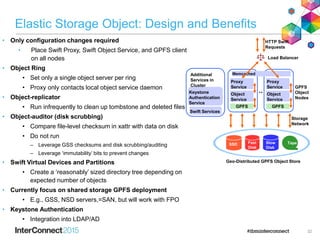
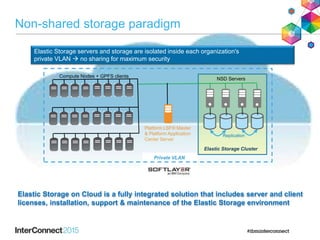
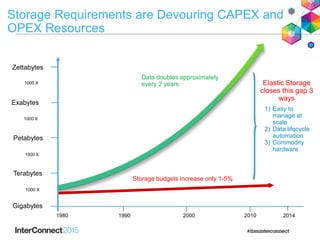
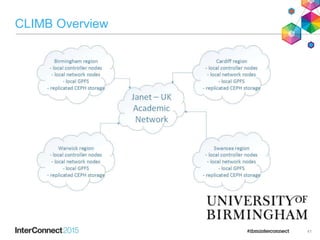
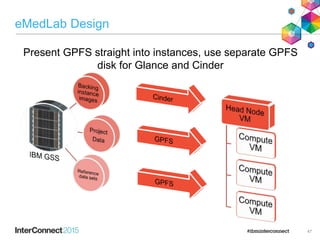
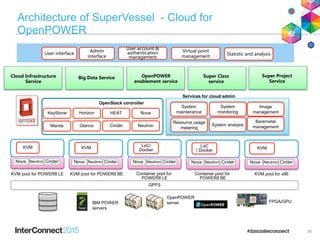
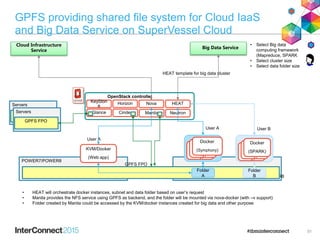
IBM Spectrum Scale (formerly Elastic Storage) provides software defined storage capabilities using standard commodity hardware. It delivers automated, policy-driven storage services through orchestration of the underlying storage infrastructure. Key features include massive scalability up to a yottabyte in size, built-in high availability, data integrity, and the ability to non-disruptively add or remove storage resources. The software provides a single global namespace, inline and offline data tiering, and integration with applications like HDFS to enable analytics on existing storage infrastructure.