Download as PDF, PPTX





![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Tensor Factorization
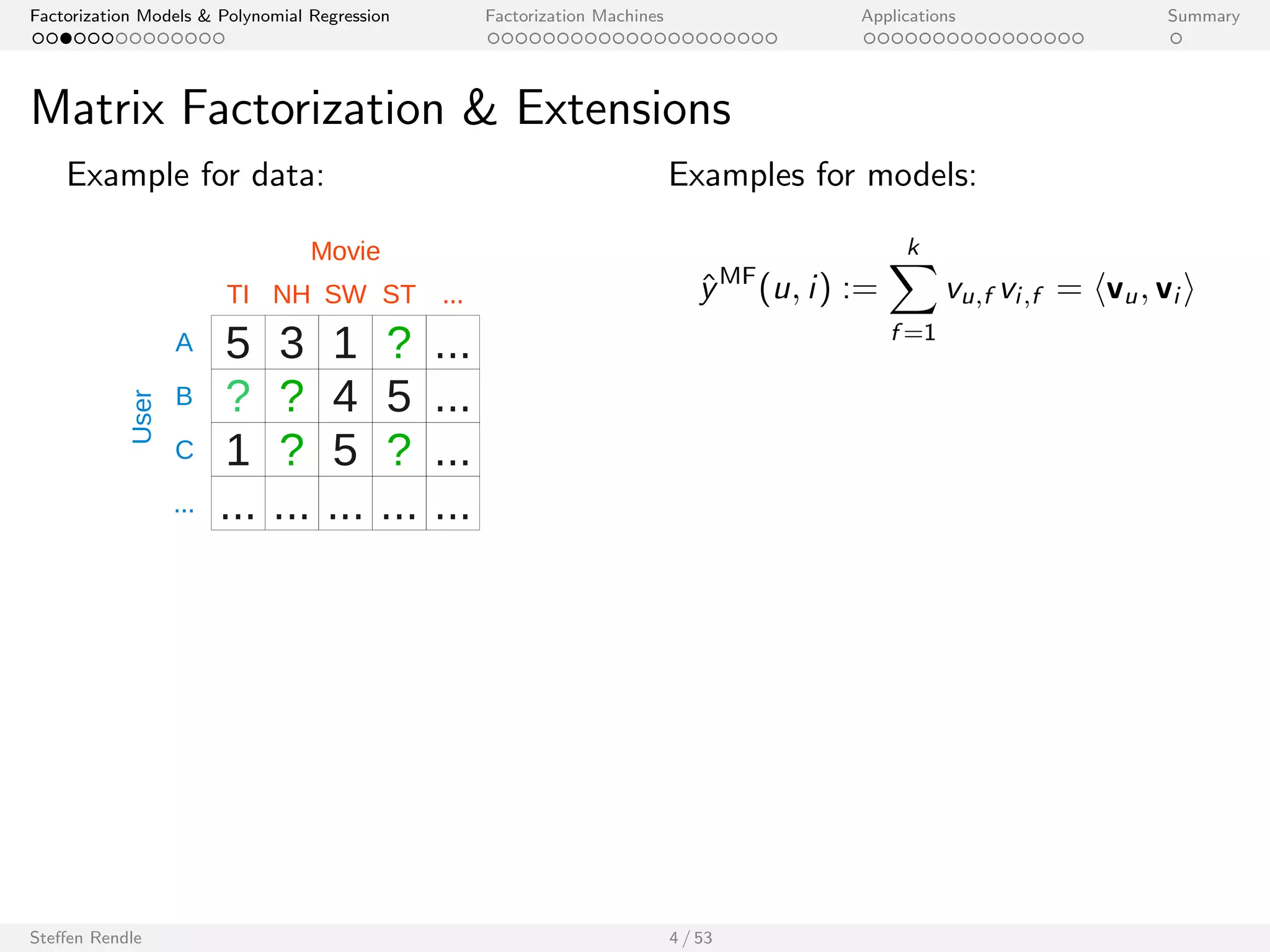
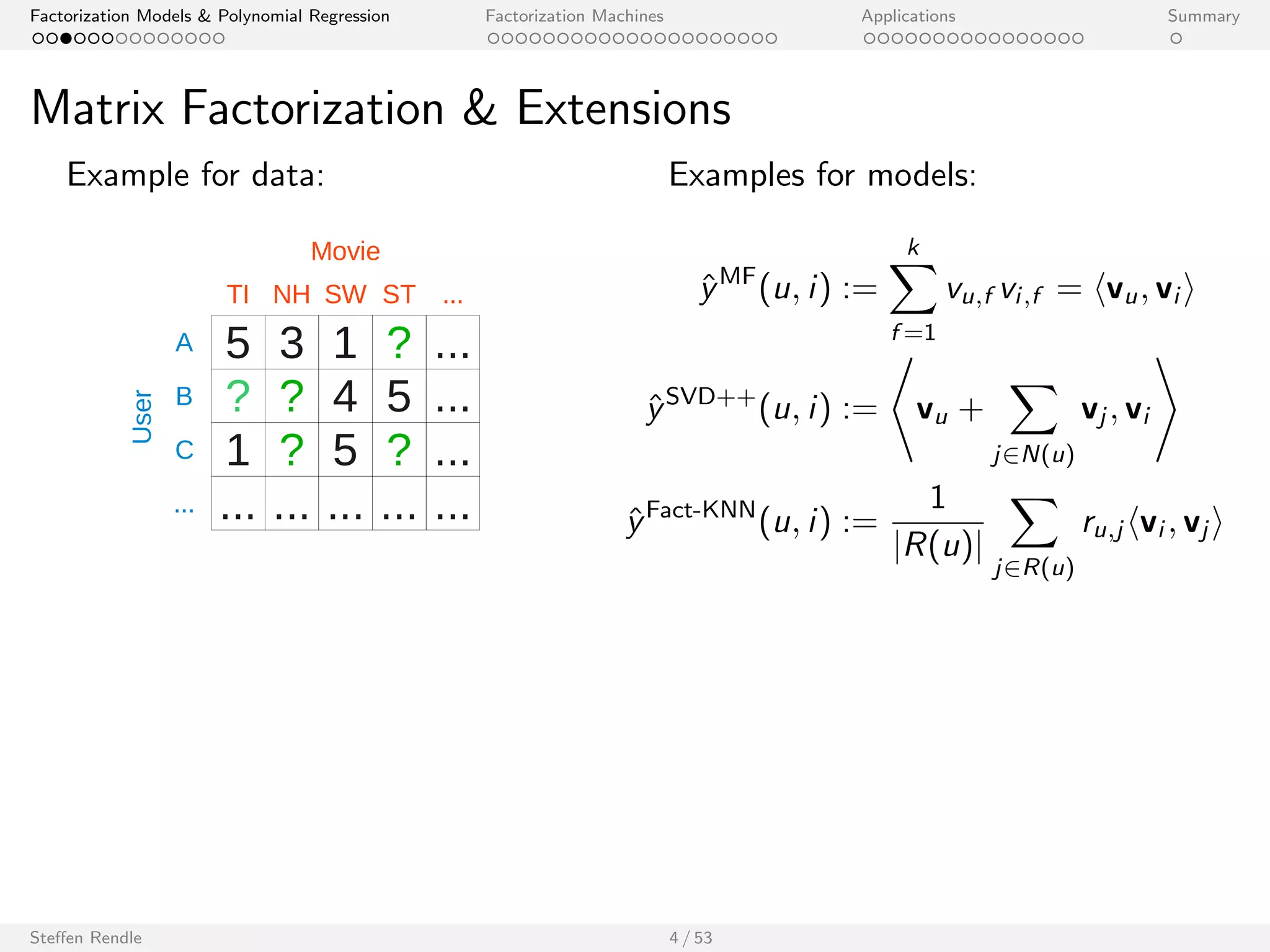
Example for data: Examples for models:
Triples of Subject, Predicate, Object
^yPARAFAC(s; p; o) :=
Xk
f =1
vs;f vp;f vo;f
^yPITF(s; p; o) := hvs ; vpi + hvs ; voi + hvp; voi
: : :
Steen Rendle 5 / 53
[illustration from Drumond et al. 2012]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-8-2048.jpg)























![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Factorization Machine (FM)
I Let x 2 Rp be an input vector with p predictor variables.
I Model equation (degree 2):
^y(x) := w0 +
Xp
i=1
wi xi +
Xp
i=1
Xp
ji
hvi ; vj i xi xj
I Model parameters:
w0 2 R; w 2 Rp; V 2 Rpk
Steen Rendle 17 / 53
[Rendle 2010, Rendle 2012]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-34-2048.jpg)
![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Factorization Machine (FM)
I Let x 2 Rp be an input vector with p predictor variables.
I Model equation (degree 2):
^y(x) := w0 +
Xp
i=1
wi xi +
Xp
i=1
Xp
ji
hvi ; vj i xi xj
I Model parameters:
w0 2 R; w 2 Rp; V 2 Rpk
Compared to Polynomial regression:
I Model equation (degree 2):
^y(x) := w0 +
Xp
i=1
wi xi +
Xp
i=1
Xp
ji
wi ;j xi xj
I Model parameters:
w0 2 R; w 2 Rp; W 2 Rpp
Steen Rendle 17 / 53
[Rendle 2010, Rendle 2012]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-35-2048.jpg)
![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Factorization Machine (FM)
I Let x 2 Rp be an input vector with p predictor variables.
I Model equation (degree 2):
^y(x) := w0 +
Xp
i=1
wi xi +
Xp
i=1
Xp
ji
hvi ; vj i xi xj
I Model parameters:
w0 2 R; w 2 Rp; V 2 Rpk
Steen Rendle 17 / 53
[Rendle 2010, Rendle 2012]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-36-2048.jpg)
![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Factorization Machine (FM)
I Let x 2 Rp be an input vector with p predictor variables.
I Model equation (degree 3):
^y(x) := w0 +
Xp
i=1
wi xi +
Xp
i=1
Xp
ji
hvi ; vj i xi xj
+
Xp
i=1
Xp
ji
Xp
lj
Xk
f =1
v(3)
i ;f v(3)
j ;f v(3)
l ;f xi xj xl
I Model parameters:
w0 2 R; w 2 Rp; V 2 Rpk ; V(3) 2 Rpk
Steen Rendle 17 / 53
[Rendle 2010, Rendle 2012]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-37-2048.jpg)
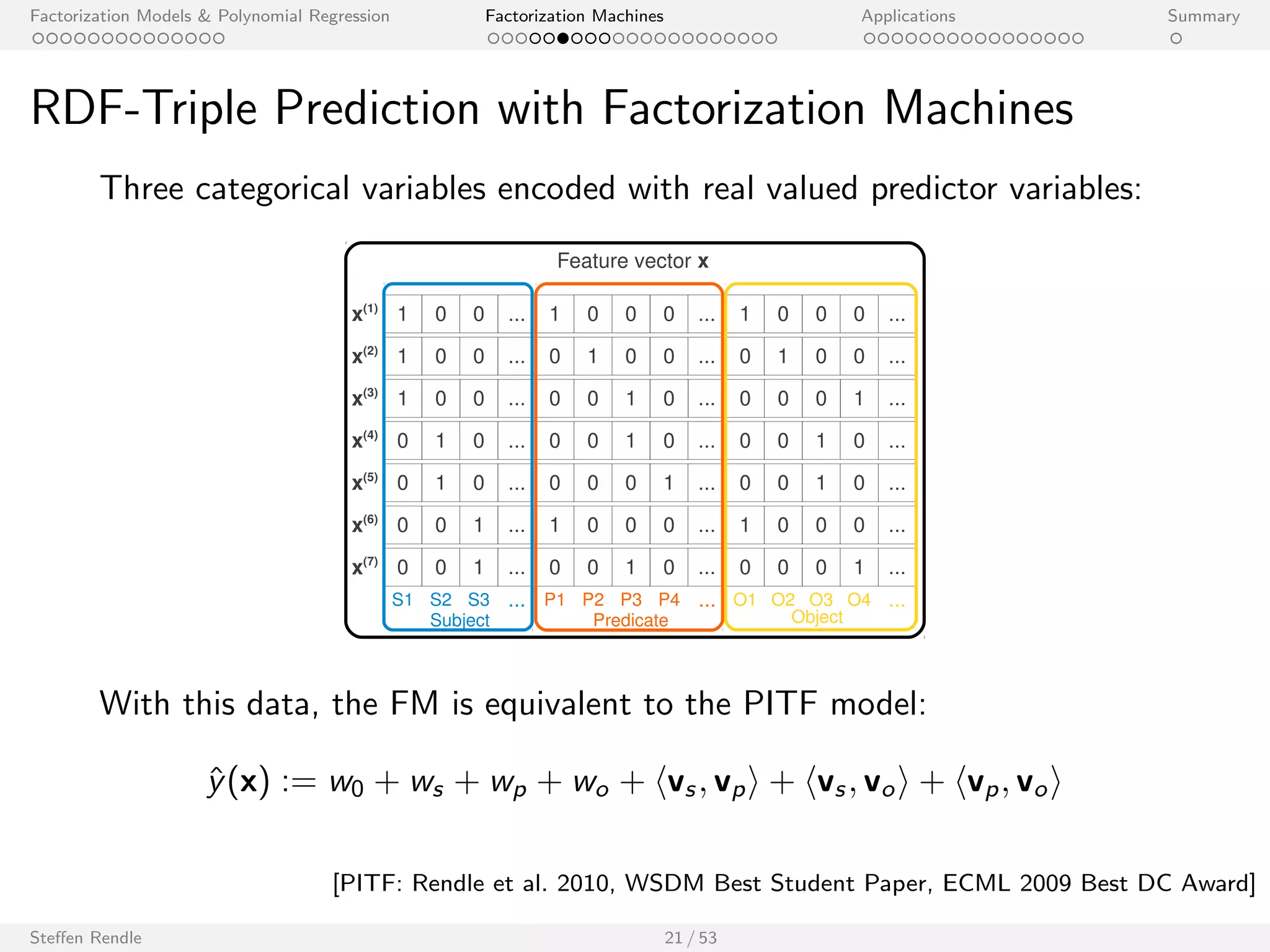


![Factorization Models Polynomial Regression Factorization Machines Applications Summary
RDF-Triple Prediction with Factorization Machines
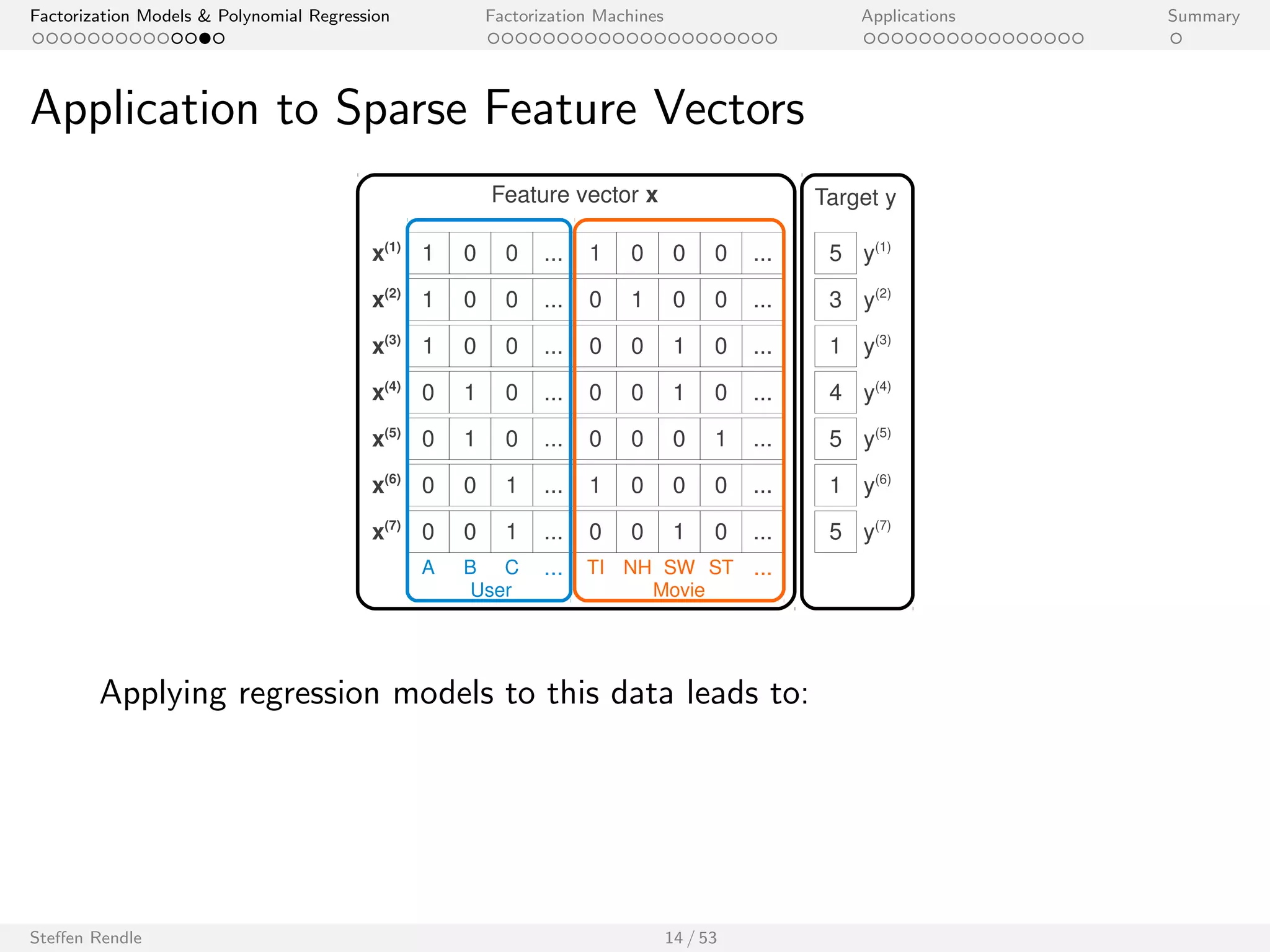
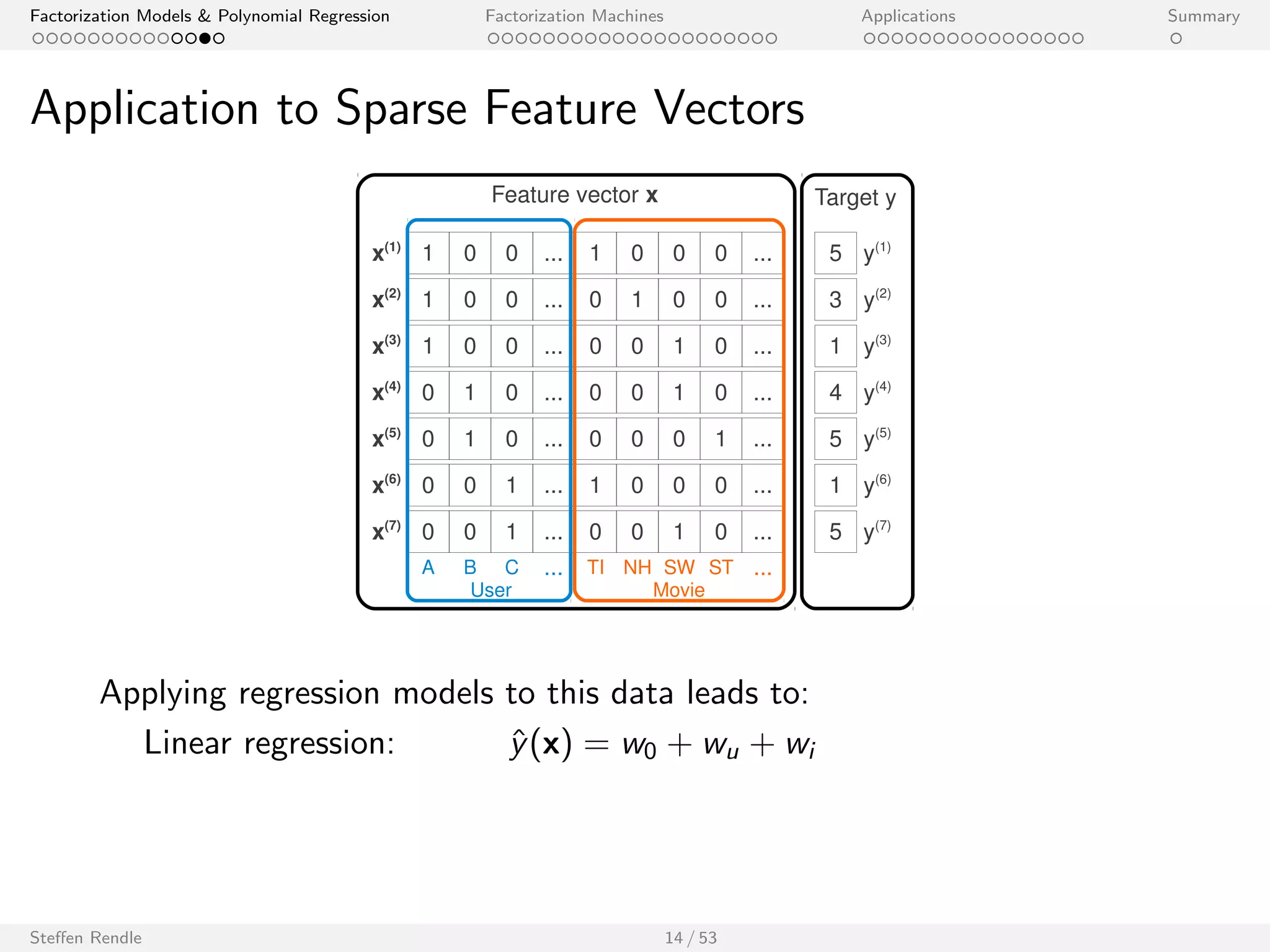
Three categorical variables encoded with real valued predictor variables:
1 0 0 ...
1 0 0 ...
x(3) 1 0 0 ... 0 0 1 0 ... 0 0 0 1 ...
0 1 0 ...
0 1 0 ...
0 0 1 ...
1
0
0
0
1
0
1
0
0
0
0
0
1
0
0
0
0
0
1
0
...
...
...
...
...
0 0 1 ... 0 0 1 0 ...
S1 S2 S3 ... P1 P2 P3 P4 ...
x(1)
x(2)
x(4)
x(5)
x(6)
x(7)
Feature vector x
1
0
0
0
1
0
1
0
0
0
0
0
1
1
0
0
0
0
0
0
...
...
...
...
...
0 0 0 1 ...
O1 O2 O3 O4 ...
Subject Predicate Object
With this data, the FM is equivalent to the PITF model:
^y(x) := w0 + ws + wp + wo + hvs ; vpi + hvs ; voi + hvp; voi
[PITF: Rendle et al. 2010, WSDM Best Student Paper, ECML 2009 Best DC Award]
Steen Rendle 21 / 53](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-41-2048.jpg)
![Factorization Models Polynomial Regression Factorization Machines Applications Summary
SVD++
1 0 0 ...
1 0 0 ...
x(3) 1 0 0 ... 0 0 1 0 ... 0.3 0.3 0.3 0 ...
0 1 0 ...
0 1 0 ...
0 0 1 ...
1
0
0
0
1
0
1
0
0
0
0
0
1
0
0
0
0
0
1
0
...
...
...
...
...
0 0 1 ... 0 0 1 0 ...
A B C ... TI NH SW ST ...
x(1)
x(2)
x(4)
x(5)
x(6)
x(7)
Feature vector x
0.3
0.3
0
0
0.5
0.3
0.3
0
0
0
0.3
0.3
0.5
0.5
0.5
0
0
0.5
0.5
0
...
...
...
...
...
0.5 0 0.5 0 ...
TI NH SW ST ...
User Movie Other Movies rated
With this data, the FM3 is identical to:
^y(x) =
SVD++ z }| {
w0 + wu + wi + hvu; vi i +
1 p
jNuj
X
l2Nu
hvi ; vl i
+
1 p
jNuj
X
l2Nu
0
@wl + hvu; vl i +
1 p
jNuj
X
l 02Nu ;l 0l
hvl ; v0
l i
1
A
3libFM, k = 128, MCMC inference, Net
ix RMSE=0.8865
Steen Rendle 23 / 53
[Koren, 2008]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-44-2048.jpg)
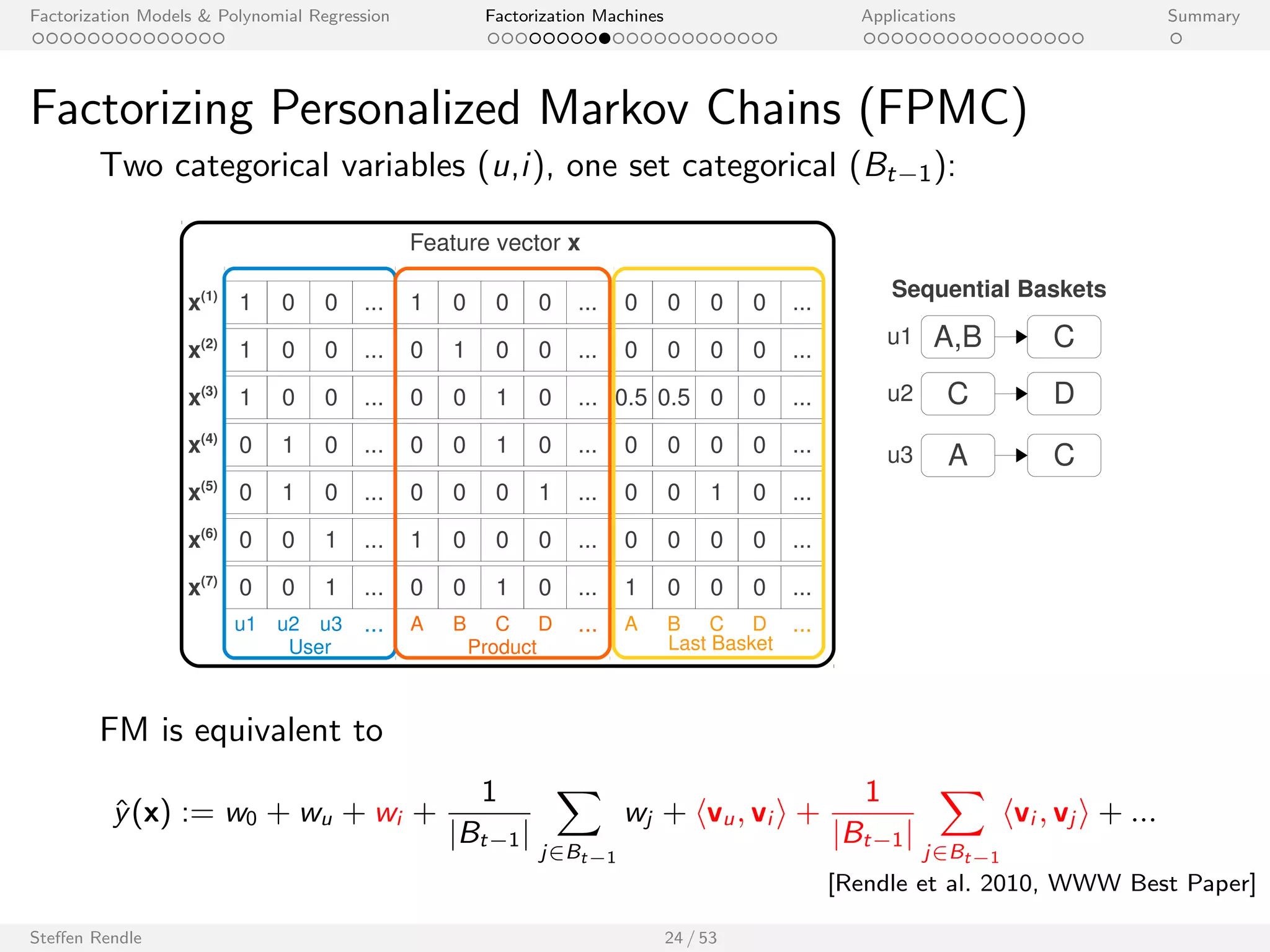
![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Factorizing Personalized Markov Chains (FPMC)
Two categorical variables (u,i ), one set categorical (Bt1):
1 0 0 ...
1 0 0 ...
x(3) 1 0 0 ... 0 0 1 0 ... 0.5 0.5 0 0 ...
0 1 0 ...
0 1 0 ...
0 0 1 ...
1
0
0
0
1
0
1
0
0
0
0
0
1
0
0
0
0
0
1
0
...
...
...
...
...
0 0 1 ... 0 0 1 0 ...
u1 u2 u3 ... A B C D ...
x(1)
x(2)
x(4)
x(5)
x(6)
x(7)
Feature vector x
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
...
...
...
...
...
1 0 0 0 ...
User Product
A B C D ...
Last Basket
Sequential Baskets
u1 A,B C
u2 C D
u3 A C
FM is equivalent to
^y(x) := w0 + wu + wi +
1
jBt1j
X
j2Bt1
wj + hvu; vi i +
1
jBt1j
X
j2Bt1
hvi ; vj i + :::
Steen Rendle 24 / 53
[Rendle et al. 2010, WWW Best Paper]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-45-2048.jpg)











![cation:
I Stochastic gradient descent [Rendle, 2010]
I Alternating least squares/ Coordinate Descent [Rendle et al., 2011,
Rendle 2012]
I Markov Chain Monte Carlo (for Bayesian FMs) [Freudenthaler et al.
2011, Rendle 2012]
I L2-regularized ranking:
I Stochastic gradient descent [Rendle, 2010]
All the proposed learning algorithms have a runtime of O(k Nz (X) i ),
where i is the number of iterations and Nz (X) the number of non-zero
elements in the design matrix X.
Steen Rendle 30 / 53](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-57-2048.jpg)
![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Stochastic Gradient Descent (SGD)
I For each training case (x; y) 2 S, SGD updates the FM model
parameter using:
0 =
(^y(x) y)h()(x) + ()
I is the learning rate / step size.
I () is the regularization value of the parameter .
I SGD can easily be applied to other loss functions.
Steen Rendle 31 / 53
[Rendle, 2010]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-58-2048.jpg)

![cation [Rendle, 2012].
Steen Rendle 32 / 53
[Rendle et al., 2011]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-60-2048.jpg)

![cation using link functions.
Steen Rendle 33 / 53
[Freudenthaler et al. 2011, Rendle 2012]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-62-2048.jpg)
![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Learning Regularization Values
v ,v
yi
w ,w
wj
w0
xij
i=1,...,n
v j
j=1,...,p
, 0 ,0
yi
wj
w0
w
xij
i=1,...,n
v j
j=1,...,p
w0 ,w0
0 ,0
w0 ,w0
w v v
Standard FM with priors. Two level FM with hyperpriors.
Steen Rendle 34 / 53
[Freudenthaler et al., 2011]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-63-2048.jpg)

![cation and regression
I Uses the same data format as LIBSVM, LIBLINEAR [Lin et. al],
SVMlight [Joachims].
I Supports variable grouping.
I Open source: GPLv3.
Steen Rendle 36 / 53
[http://www.libfm.org/]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-66-2048.jpg)

![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Net
ix Prize
Method (Name) Ref. Learning Method k Quiz RMSE
Models using user ID and item ID
Probabilistic Matrix Factorization [14, 13] Batch GD 40 *0.9170
Probabilistic Matrix Factorization [14, 13] Batch GD 150 0.9211
Matrix Factorization [6] Variational Bayes 30 *0.9141
Matchbox [15] Variational Bayes 50 *0.9100
ALS-MF [7] ALS 100 0.9079
ALS-MF [7] ALS 1000 *0.9018
SVD/ MF [3] SGD 100 0.9025
SVD/ MF [3] SGD 200 *0.9009
Bayesian Probablistic Matrix Factorization
[13] MCMC 150 0.8965
(BPMF)
Bayesian Probablistic Matrix Factorization
(BPMF)
[13] MCMC 300 *0.8954
FM, pred. var: user ID, movie ID - MCMC 128 0.8937
Models using implicit feedback
Probabilistic Matrix Factorization with Cons-
traints
[14] Batch GD 30 *0.9016
SVD++ [3] SGD 100 0.8924
SVD++ [3] SGD 200 *0.8911
BSRM/F [18] MCMC 100 0.8926
BSRM/F [18] MCMC 400 *0.8874
FM, pred. var: user ID, movie ID, impl. - MCMC 128 0.8865
Steen Rendle 40 / 53](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-71-2048.jpg)
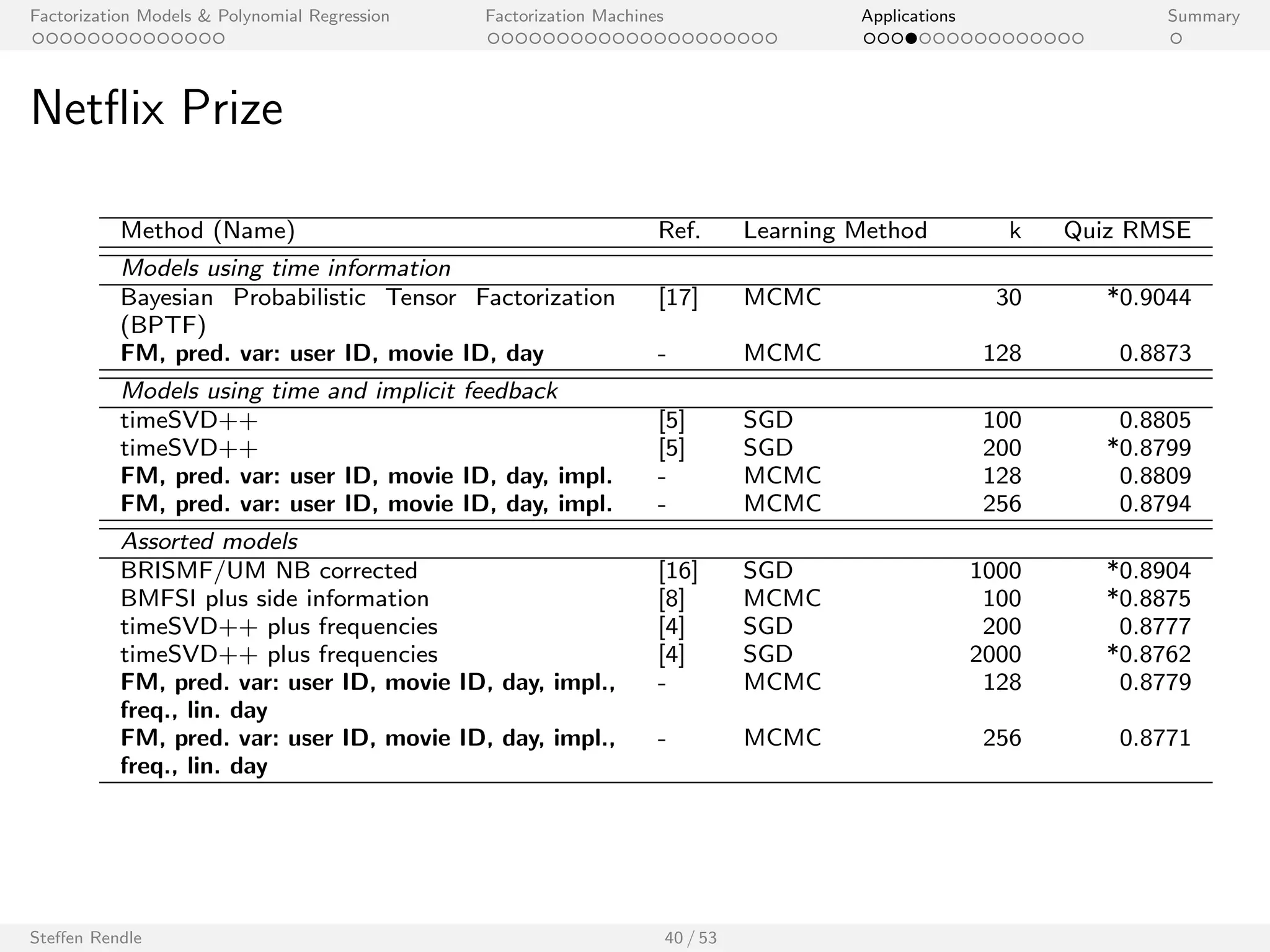
![Factorization Models Polynomial Regression Factorization Machines Applications Summary
Net
ix Prize
Method (Name) Ref. Learning Method k Quiz RMSE
Models using time information
Bayesian Probabilistic Tensor Factorization
[17] MCMC 30 *0.9044
(BPTF)
FM, pred. var: user ID, movie ID, day - MCMC 128 0.8873
Models using time and implicit feedback
timeSVD++ [5] SGD 100 0.8805
timeSVD++ [5] SGD 200 *0.8799
FM, pred. var: user ID, movie ID, day, impl. - MCMC 128 0.8809
FM, pred. var: user ID, movie ID, day, impl. - MCMC 256 0.8794
Assorted models
BRISMF/UM NB corrected [16] SGD 1000 *0.8904
BMFSI plus side information [8] MCMC 100 *0.8875
timeSVD++ plus frequencies [4] SGD 200 0.8777
timeSVD++ plus frequencies [4] SGD 2000 *0.8762
FM, pred. var: user ID, movie ID, day, impl.,
- MCMC 128 0.8779
freq., lin. day
FM, pred. var: user ID, movie ID, day, impl.,
freq., lin. day
- MCMC 256 0.8771
Steen Rendle 40 / 53](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-72-2048.jpg)


![Factorization Models Polynomial Regression Factorization Machines Applications Summary
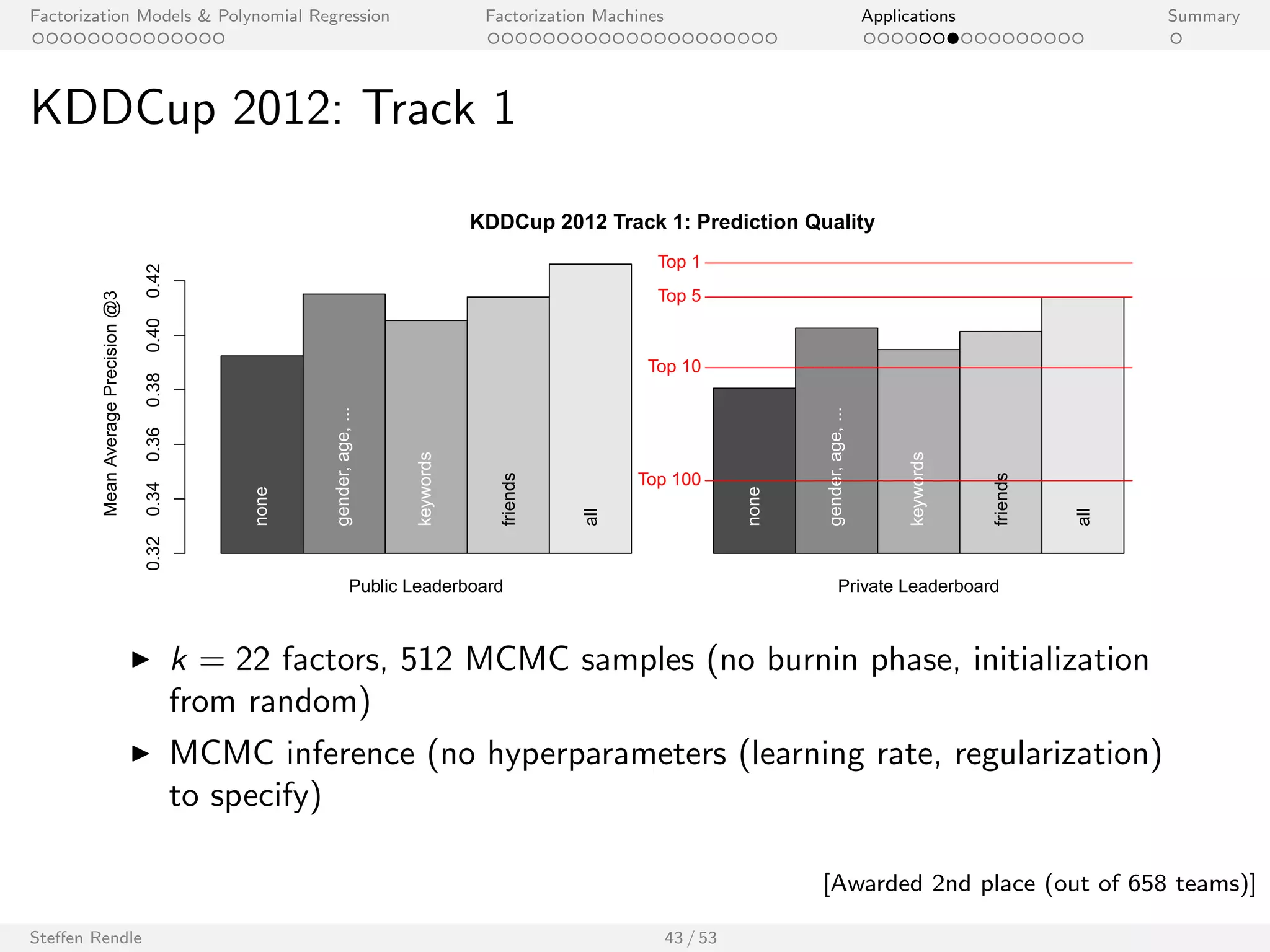
KDDCup 2012: Track 1
KDDCup 2012 Track 1: Prediction Quality
Public Leaderboard Private Leaderboard
Mean Average Precision @3
0.32 0.34 0.36 0.38 0.40 0.42
none
gender, age, ...
keywords
friends
all
none
gender, age, ...
keywords
friends
all
Top 1
Top 5
Top 10
Top 100
I k = 22 factors, 512 MCMC samples (no burnin phase, initialization
from random)
I MCMC inference (no hyperparameters (learning rate, regularization)
to specify)
Steen Rendle 43 / 53
[Awarded 2nd place (out of 658 teams)]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-76-2048.jpg)



![Factorization Models Polynomial Regression Factorization Machines Applications Summary
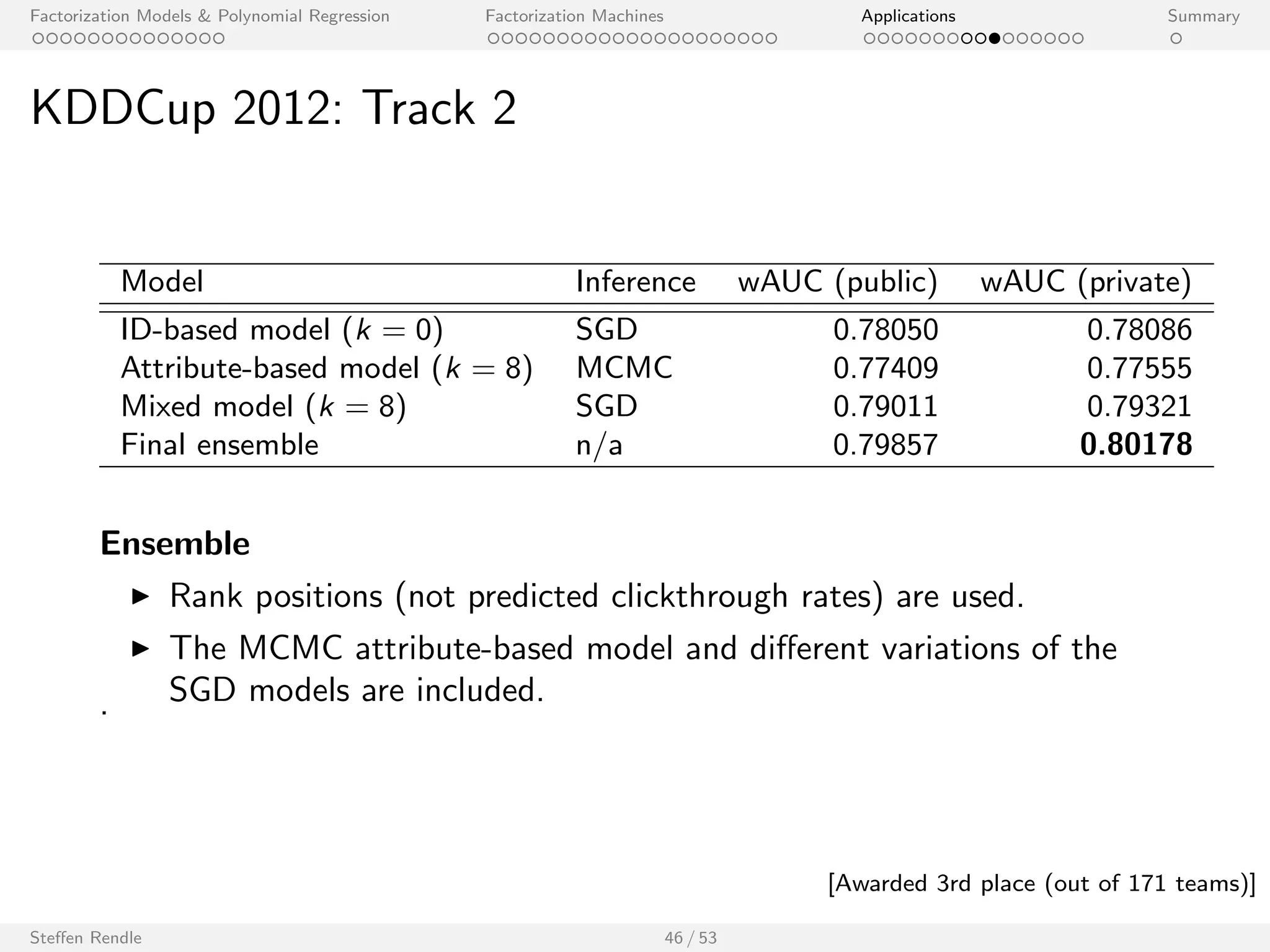
KDDCup 2012: Track 2
Model Inference wAUC (public) wAUC (private)
ID-based model (k = 0) SGD 0.78050 0.78086
Attribute-based model (k = 8) MCMC 0.77409 0.77555
Mixed model (k = 8) SGD 0.79011 0.79321
Final ensemble n/a 0.79857 0.80178
Ensemble
I Rank positions (not predicted clickthrough rates) are used.
I The MCMC attribute-based model and dierent variations of the
. SGD models are included.
Steen Rendle 46 / 53
[Awarded 3rd place (out of 171 teams)]](https://image.slidesharecdn.com/steffenrendlemlconf141114-141121121618-conversion-gate01/75/Steffen-Rendle-Research-Scientist-Google-at-MLconf-SF-80-2048.jpg)



The document presents an overview of factorization models and their applications, particularly focusing on factorization machines and polynomial regression. It discusses advantages, disadvantages, and various examples of modeling interactions between variables through matrix and tensor representations. The document also highlights the challenges faced by traditional regression models in handling sparse feature vectors.




















![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)






















































































