




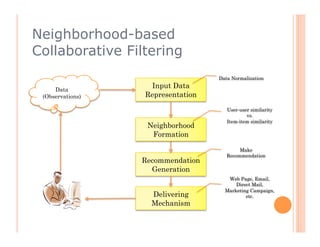

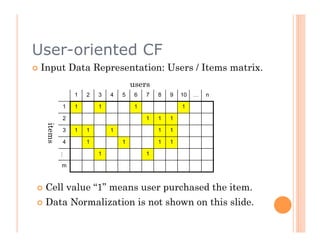
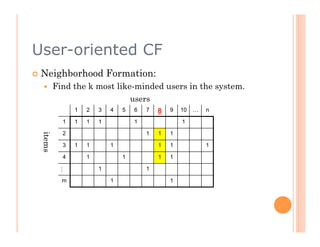
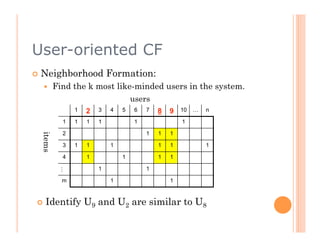
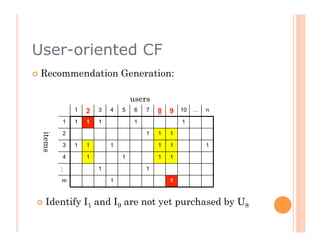
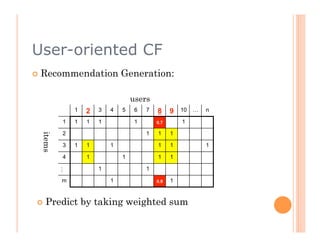


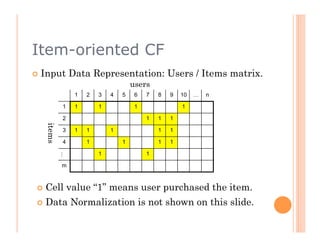
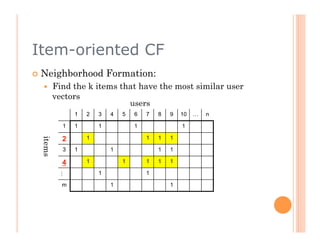
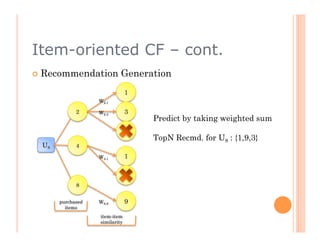



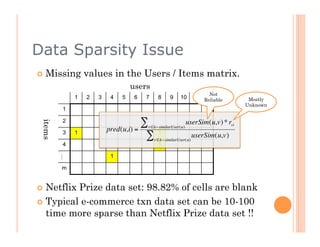

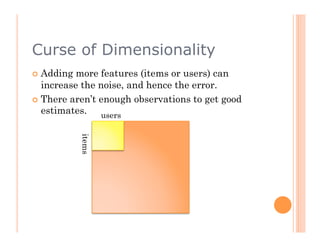




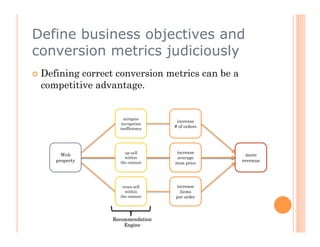

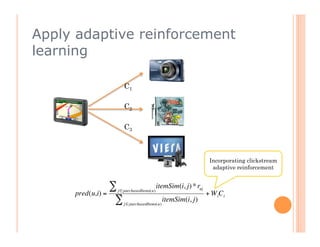
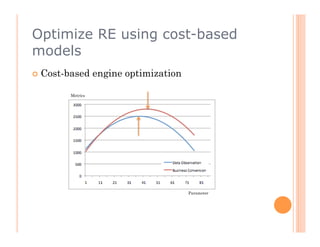
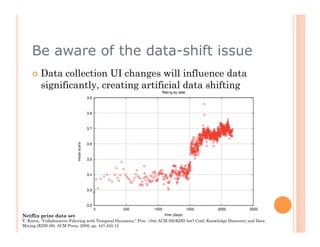
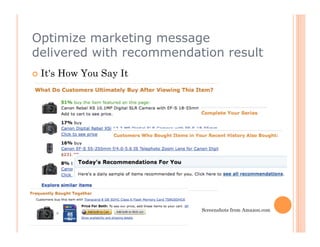


The document discusses recommendation engines, focusing primarily on neighborhood-based collaborative filtering methods, both user-oriented and item-oriented approaches. It outlines data normalization, similarity measures, recommendation generation, and practical implementation while addressing challenges such as data sparsity, cold start problems, and scalability. Best practices for optimizing recommendation engines, including understanding data, defining business objectives, and incorporating adaptive reinforcement learning are also highlighted.










































![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)
























