Download as ODP, PPTX












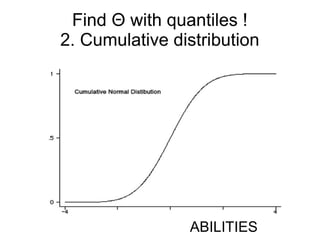
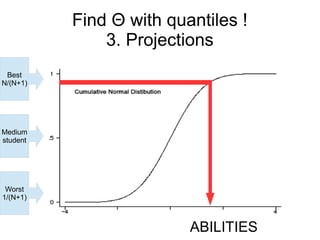
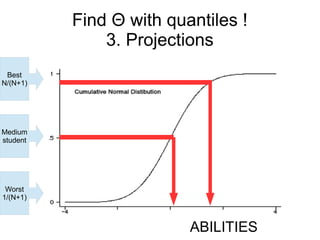



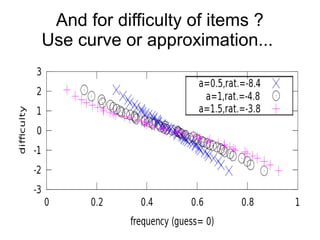



This document provides an overview of statistical concepts related to item response theory (IRT), including posterior probability, Bayes' theorem, maximum a posteriori (MAP) estimation, and the Jacobi algorithm. It discusses how to initialize IRT parameters like student abilities and item parameters, and evaluates options for fitting IRT models like R and Octave packages.

















































































