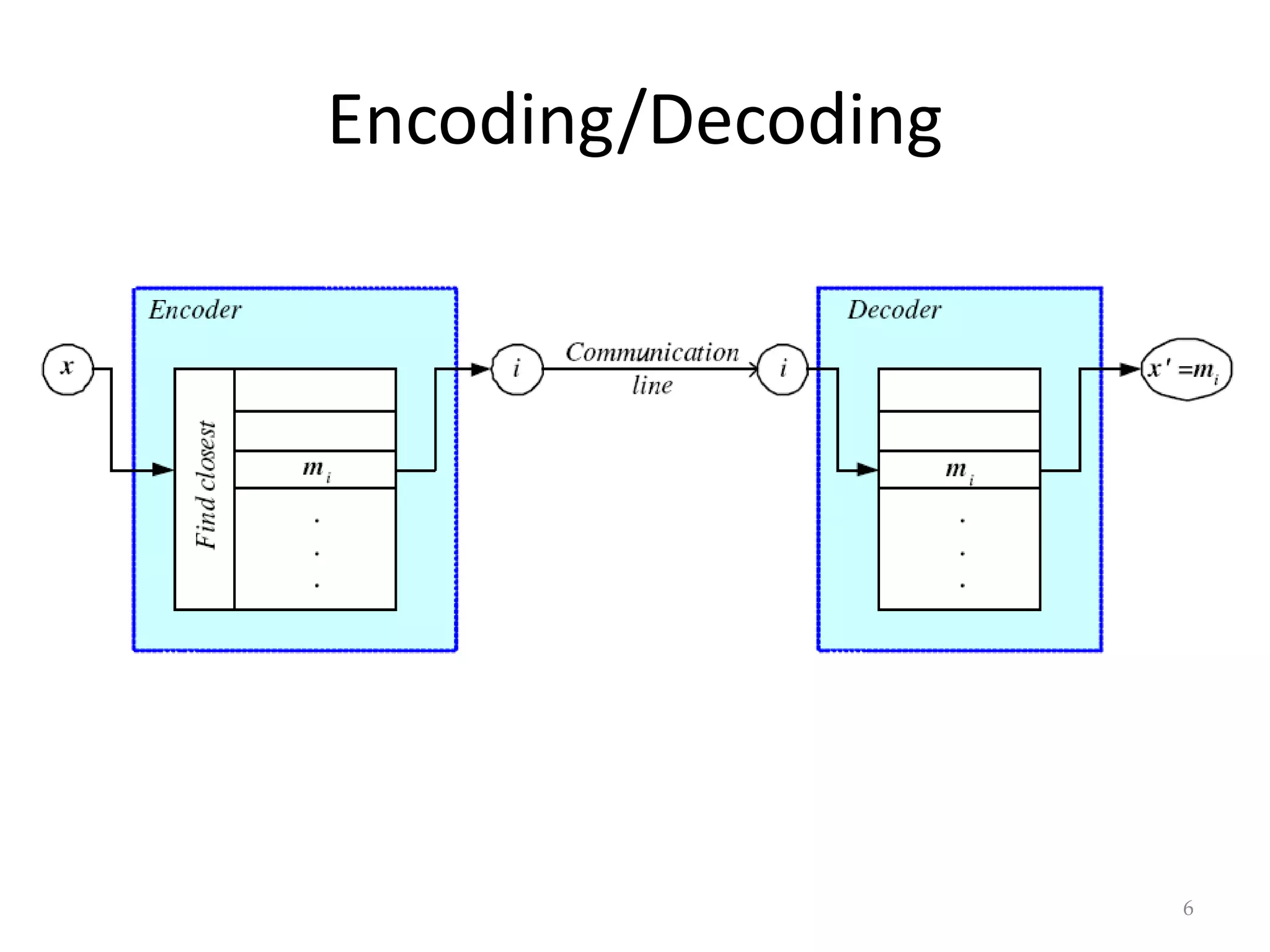
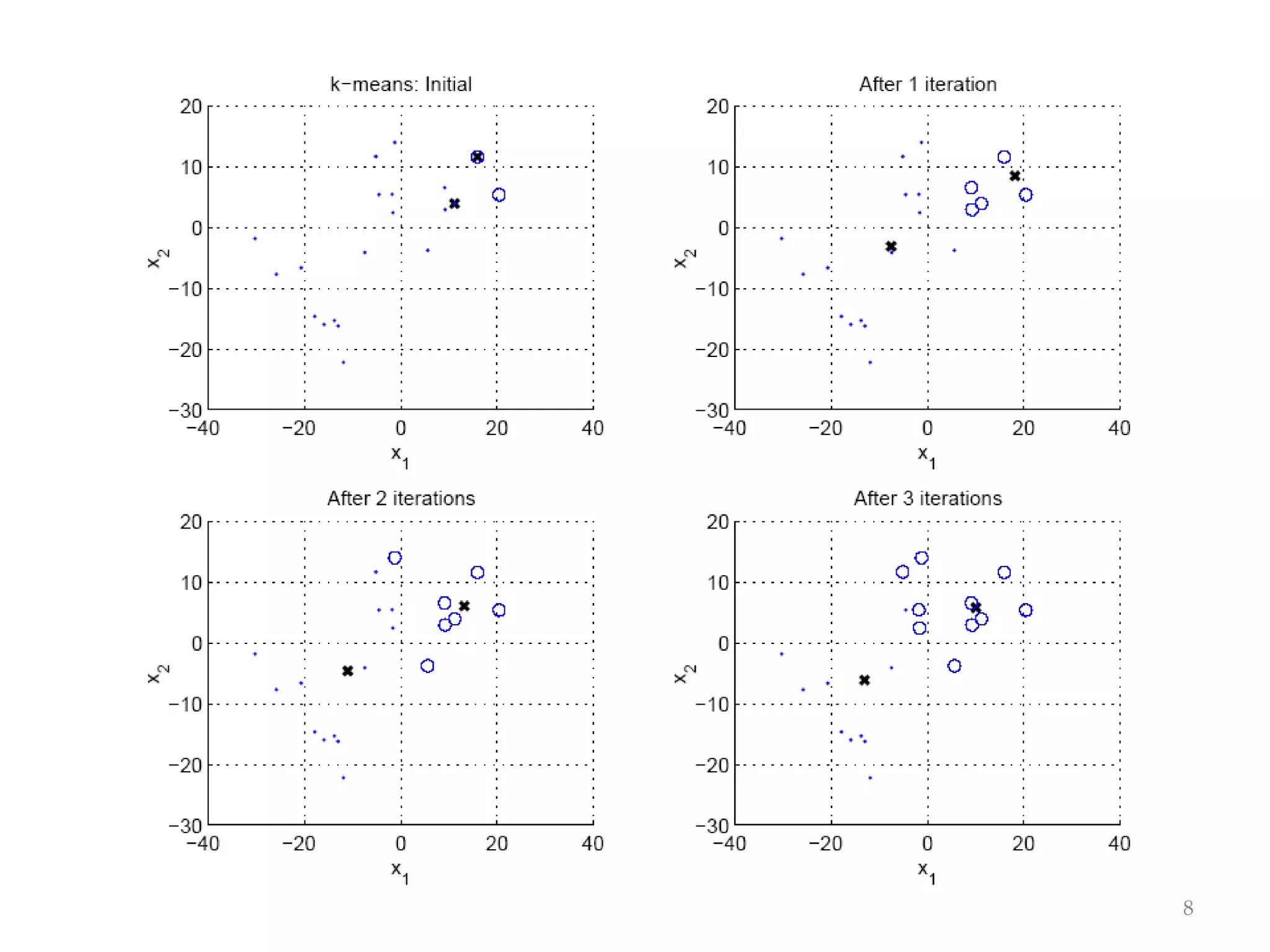
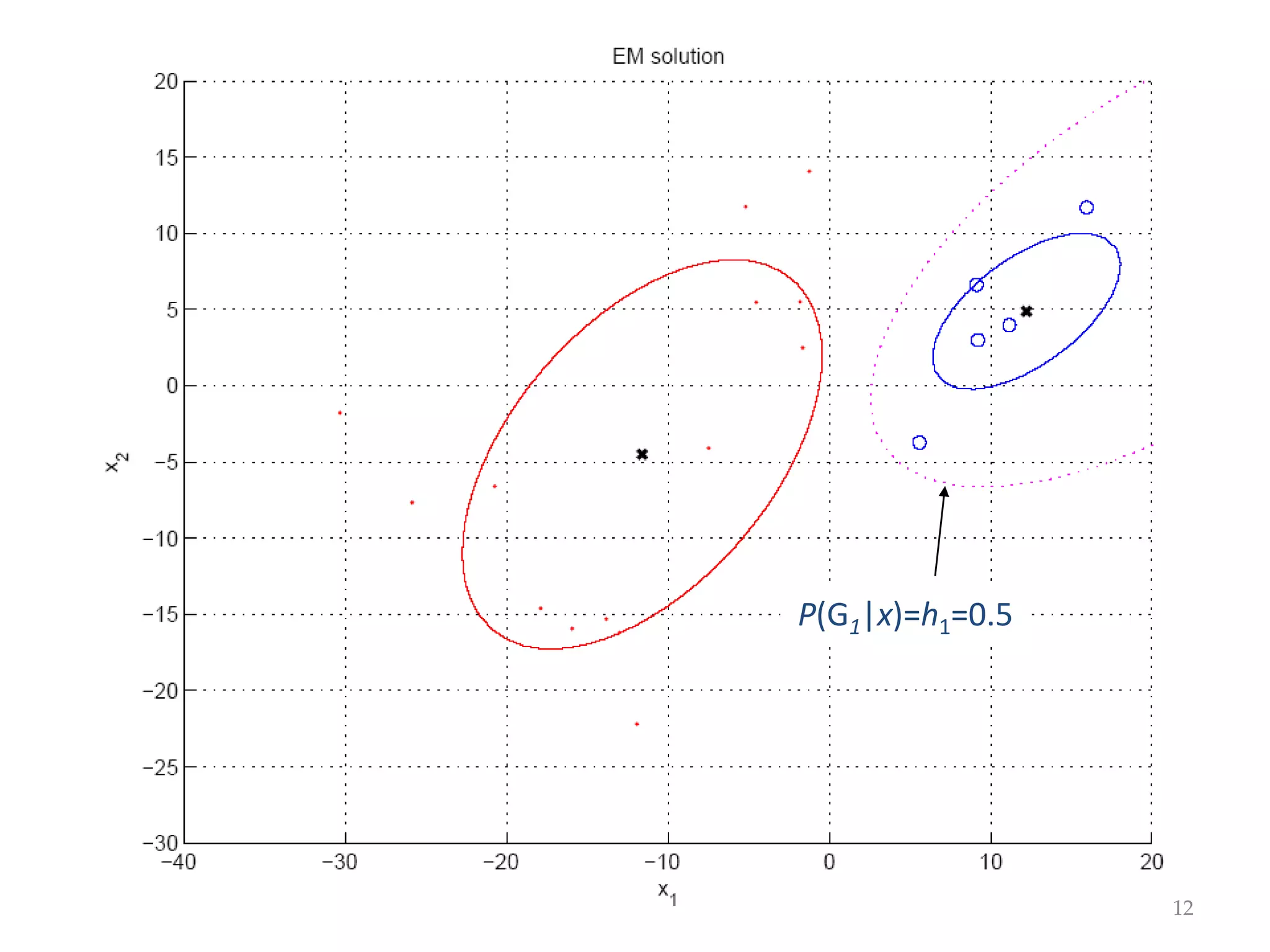
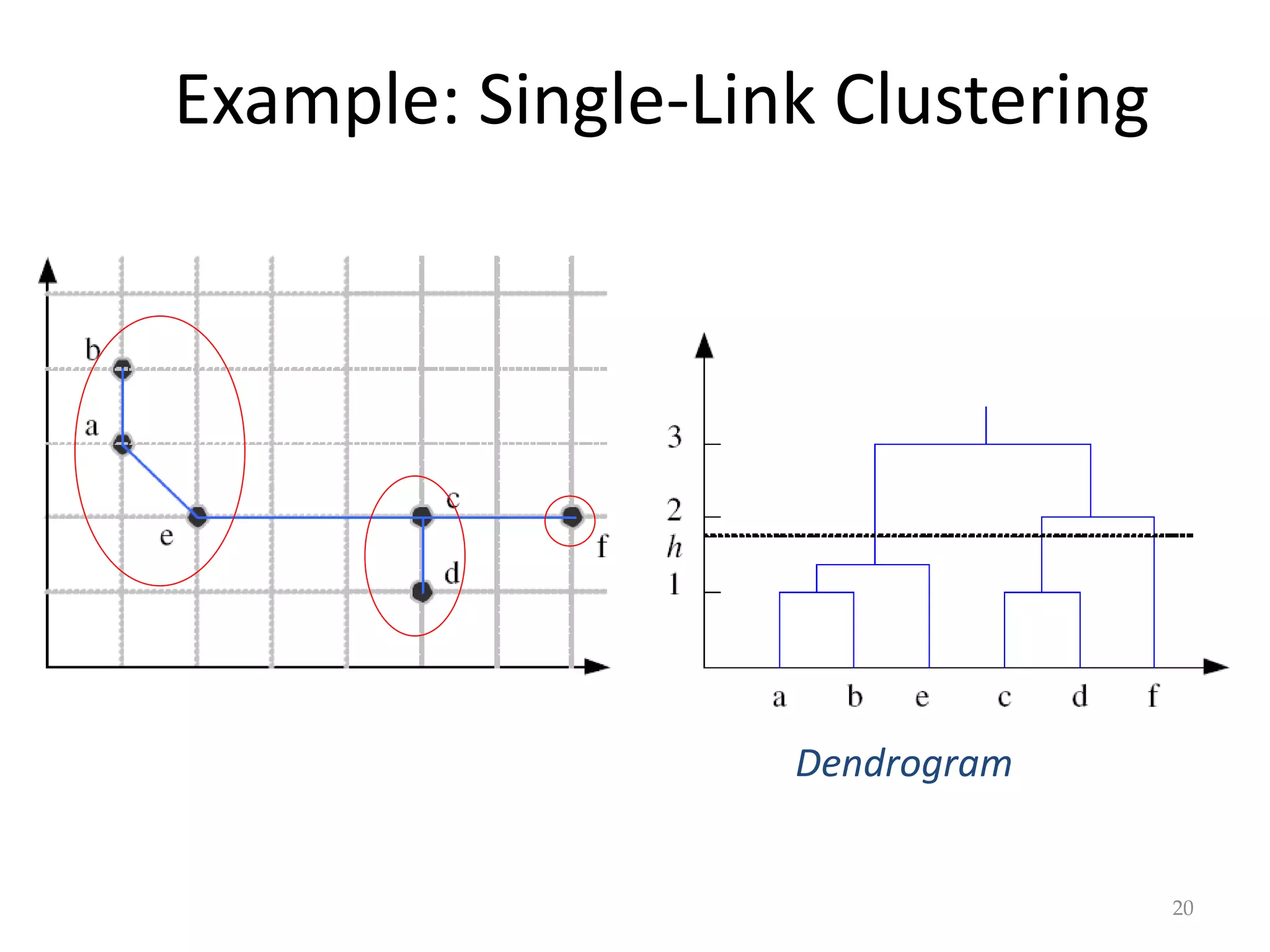
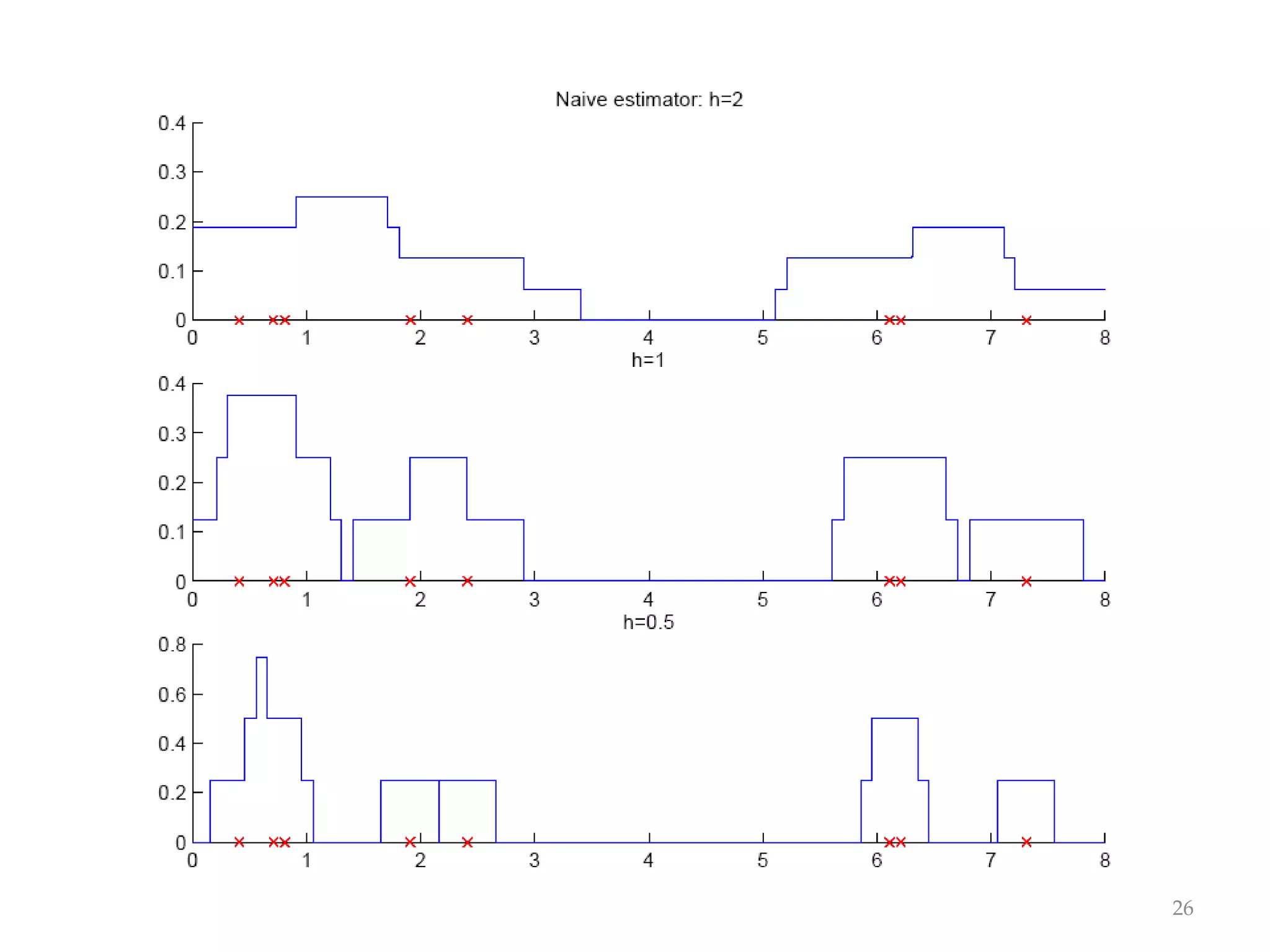
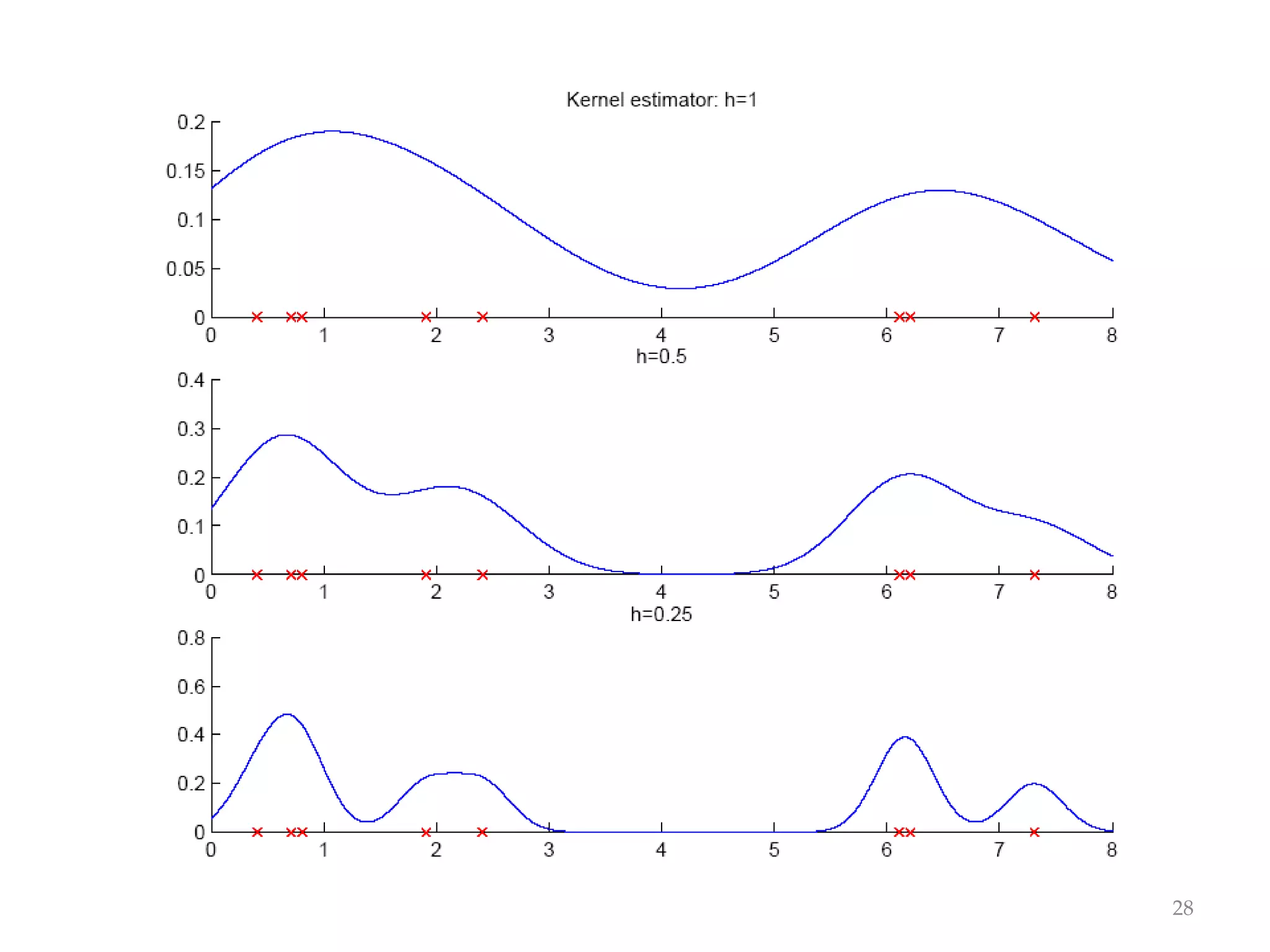
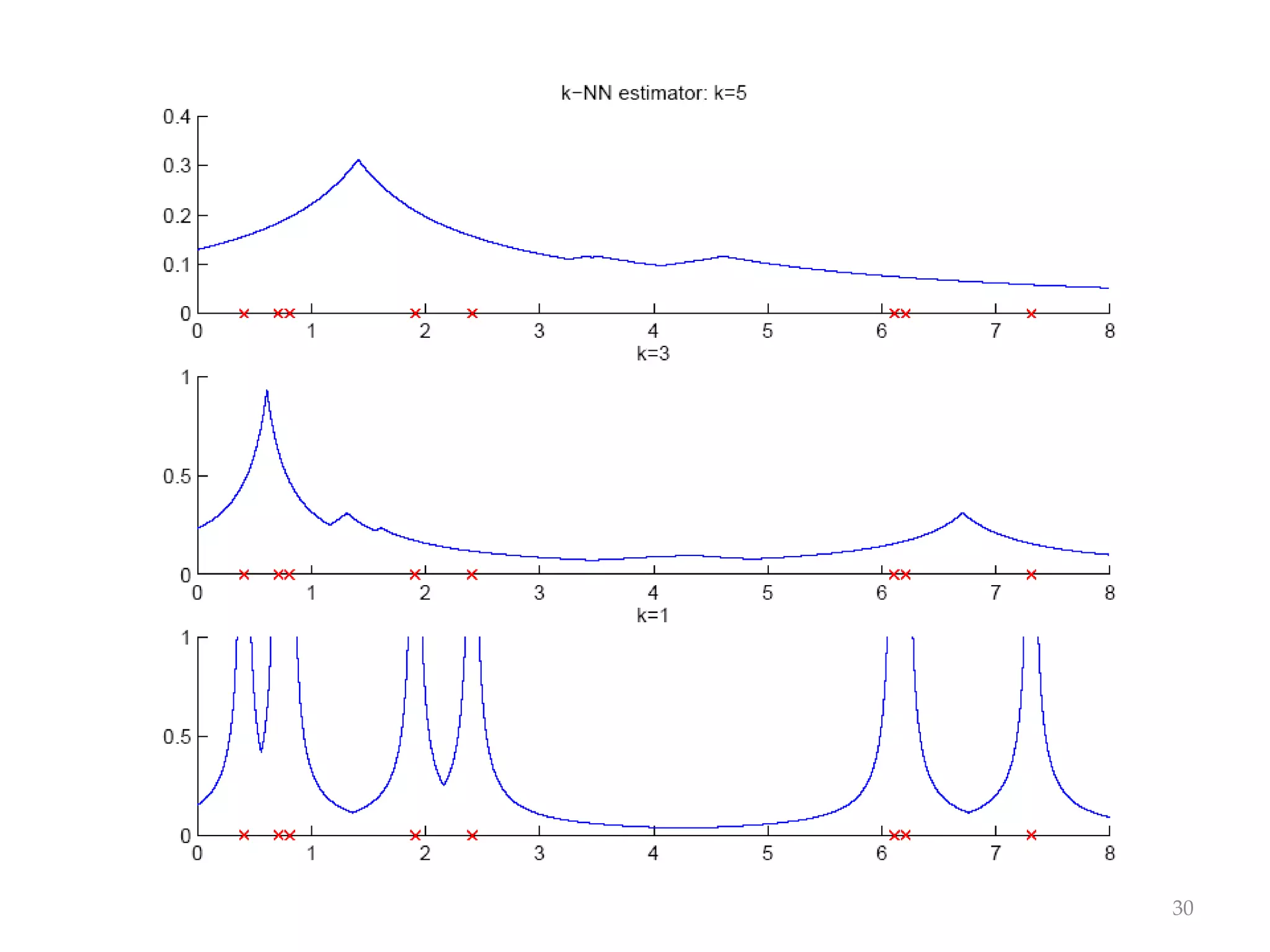
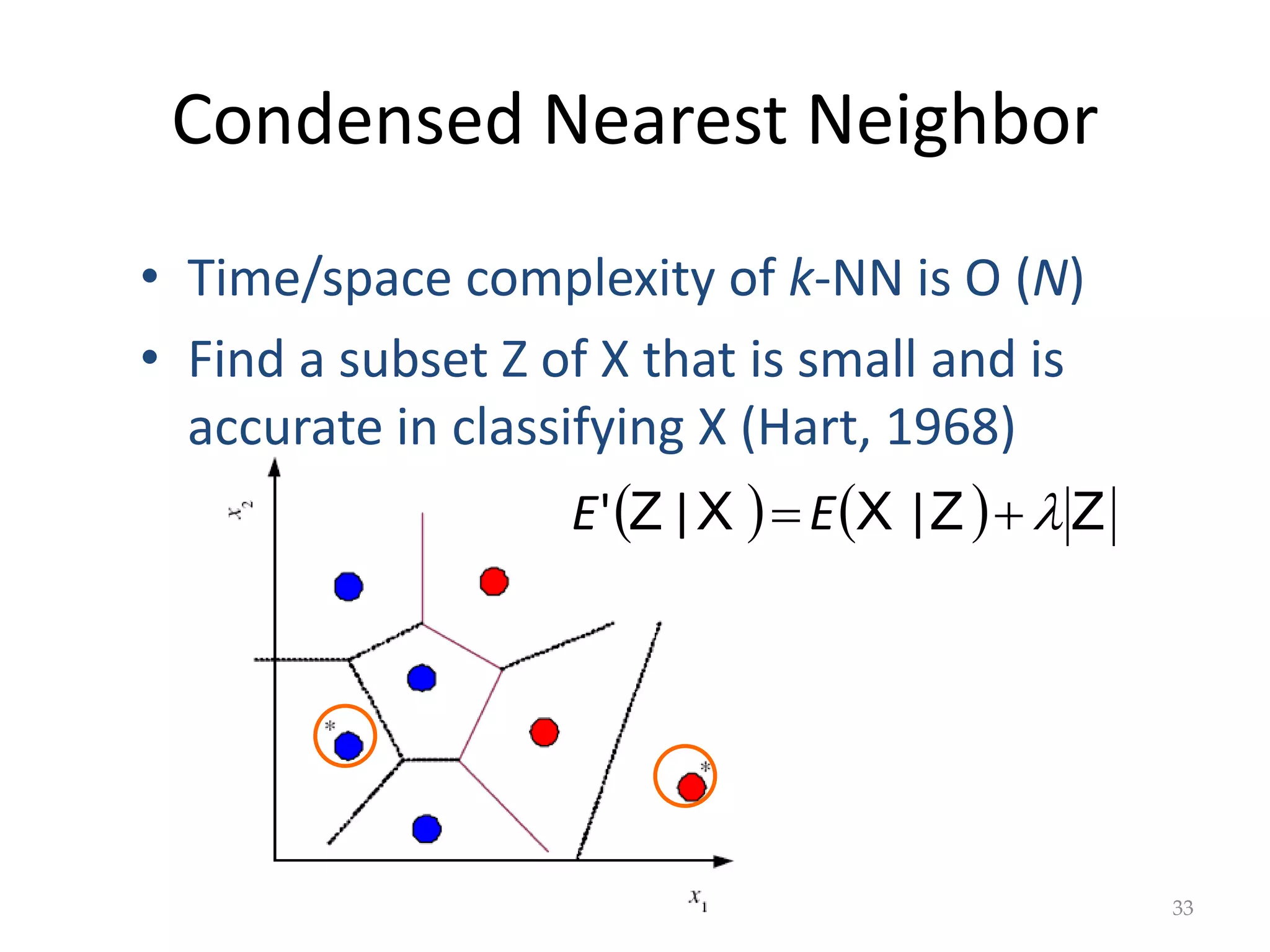
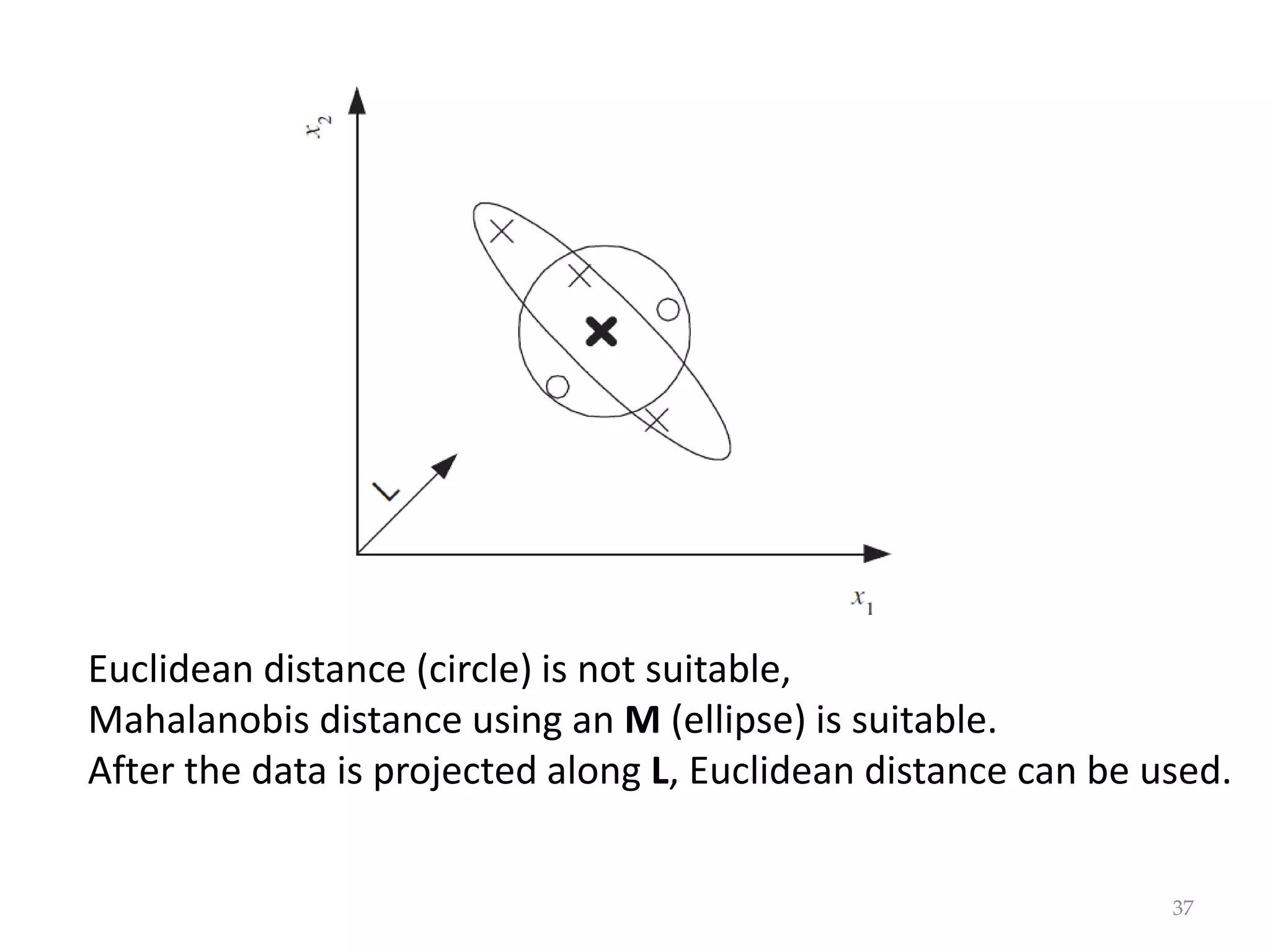
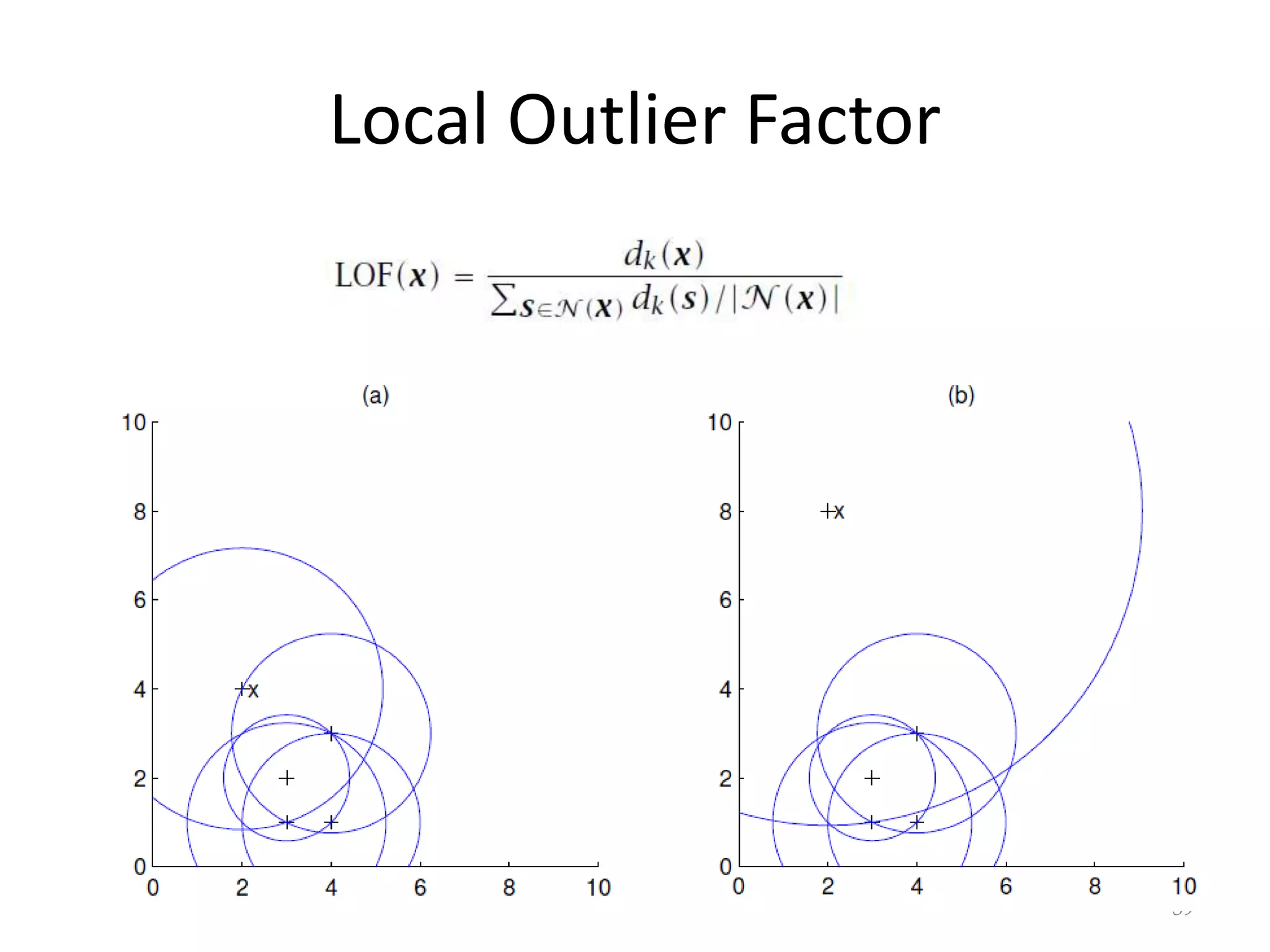
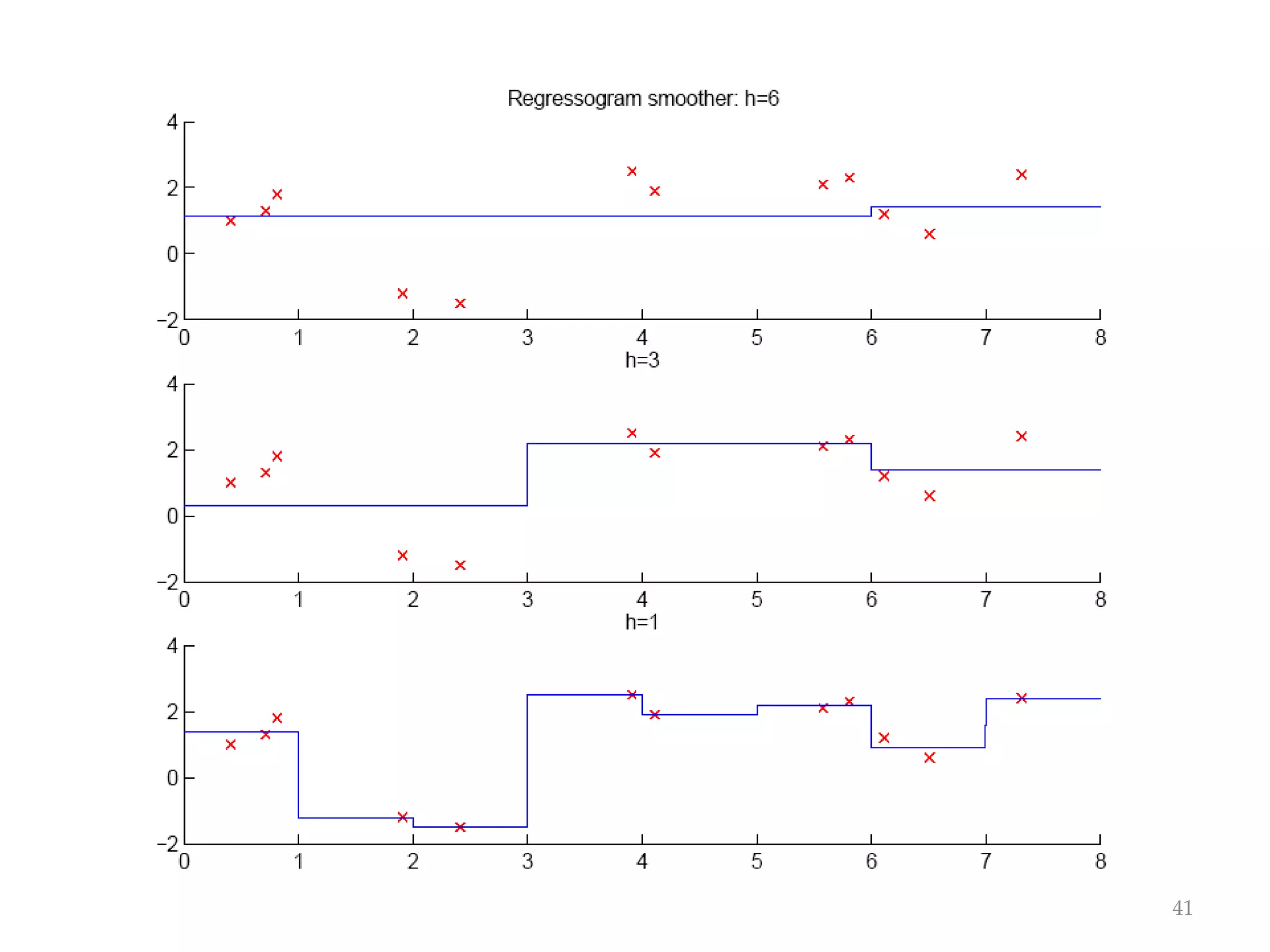
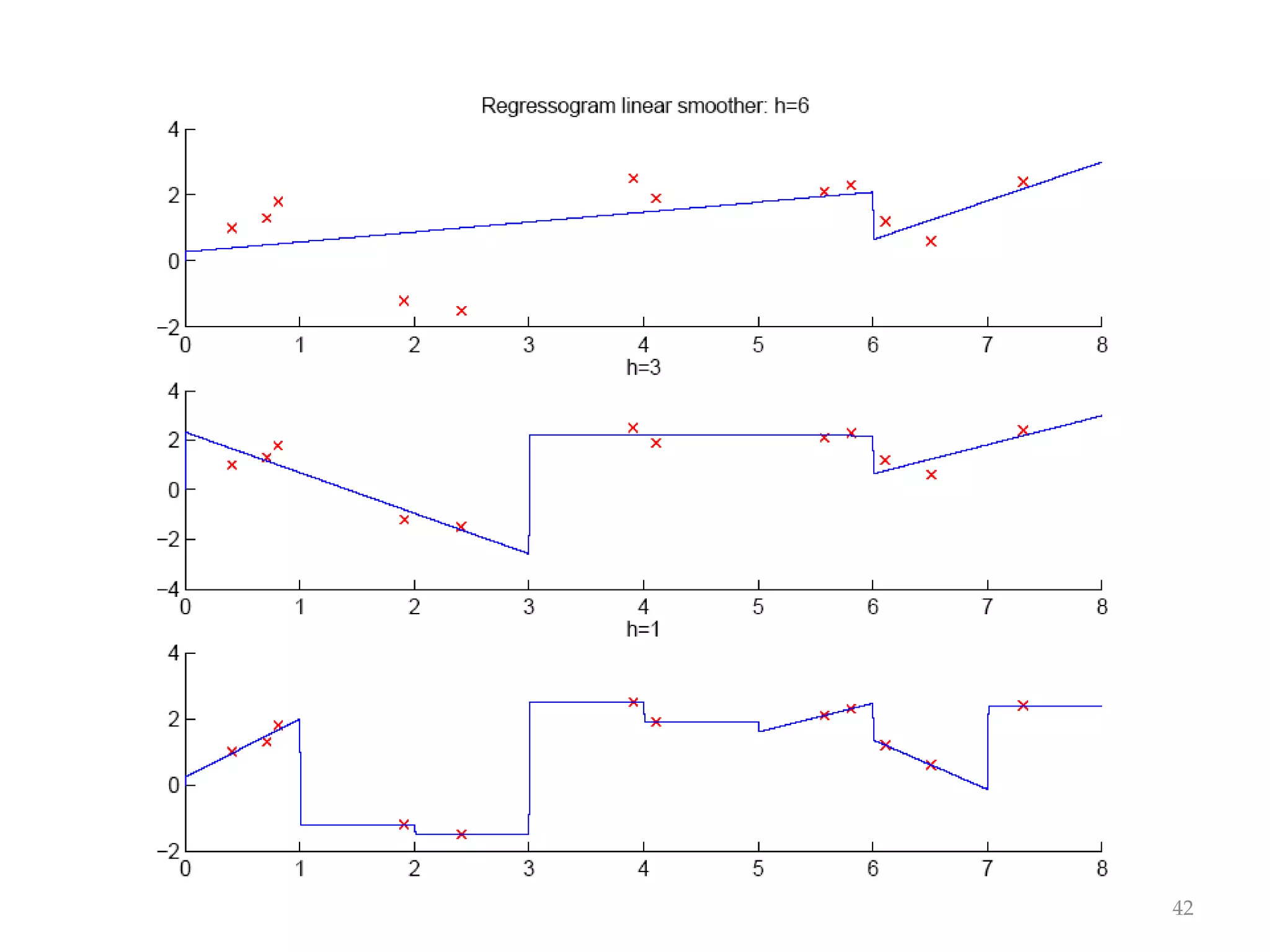
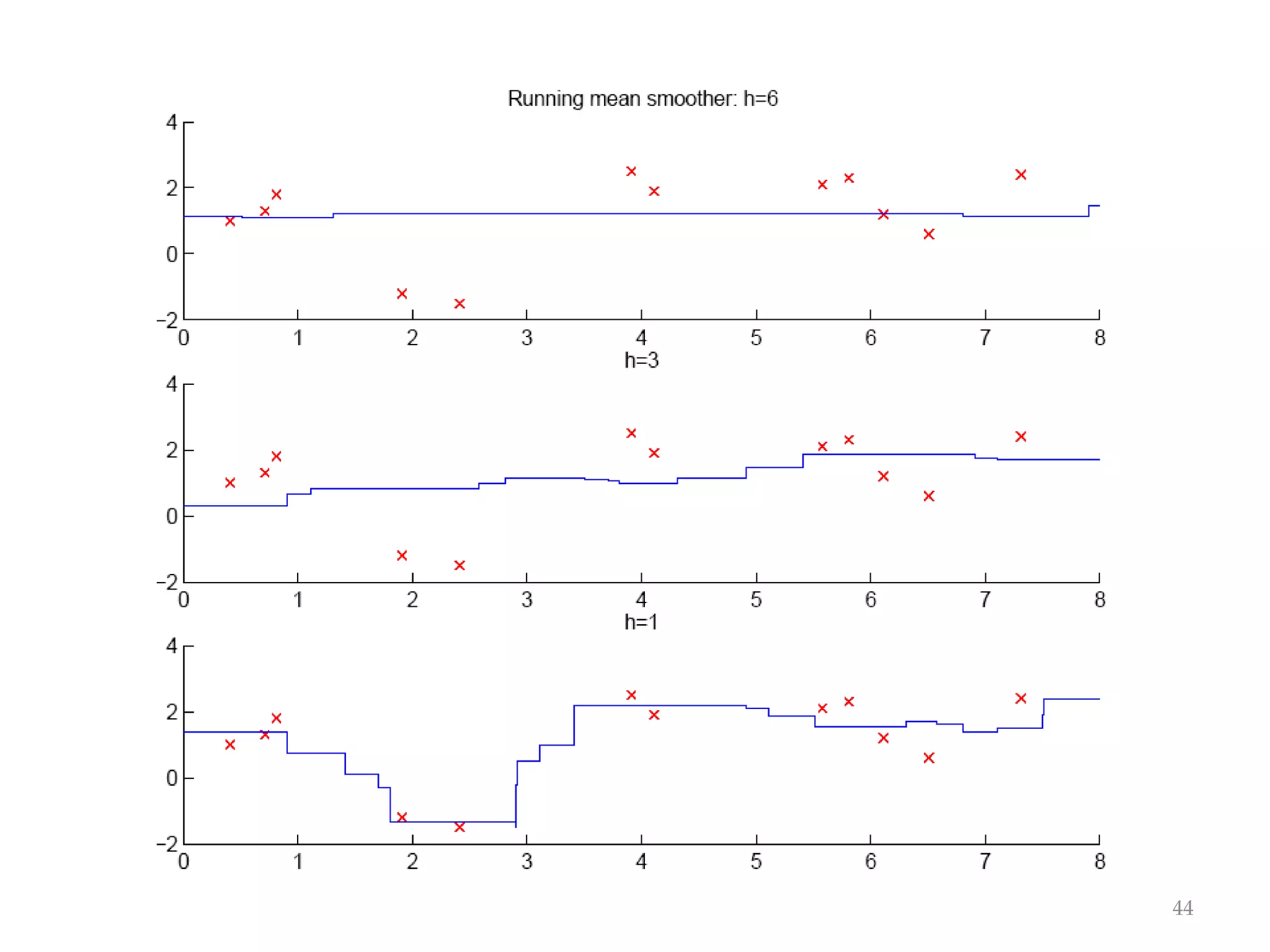
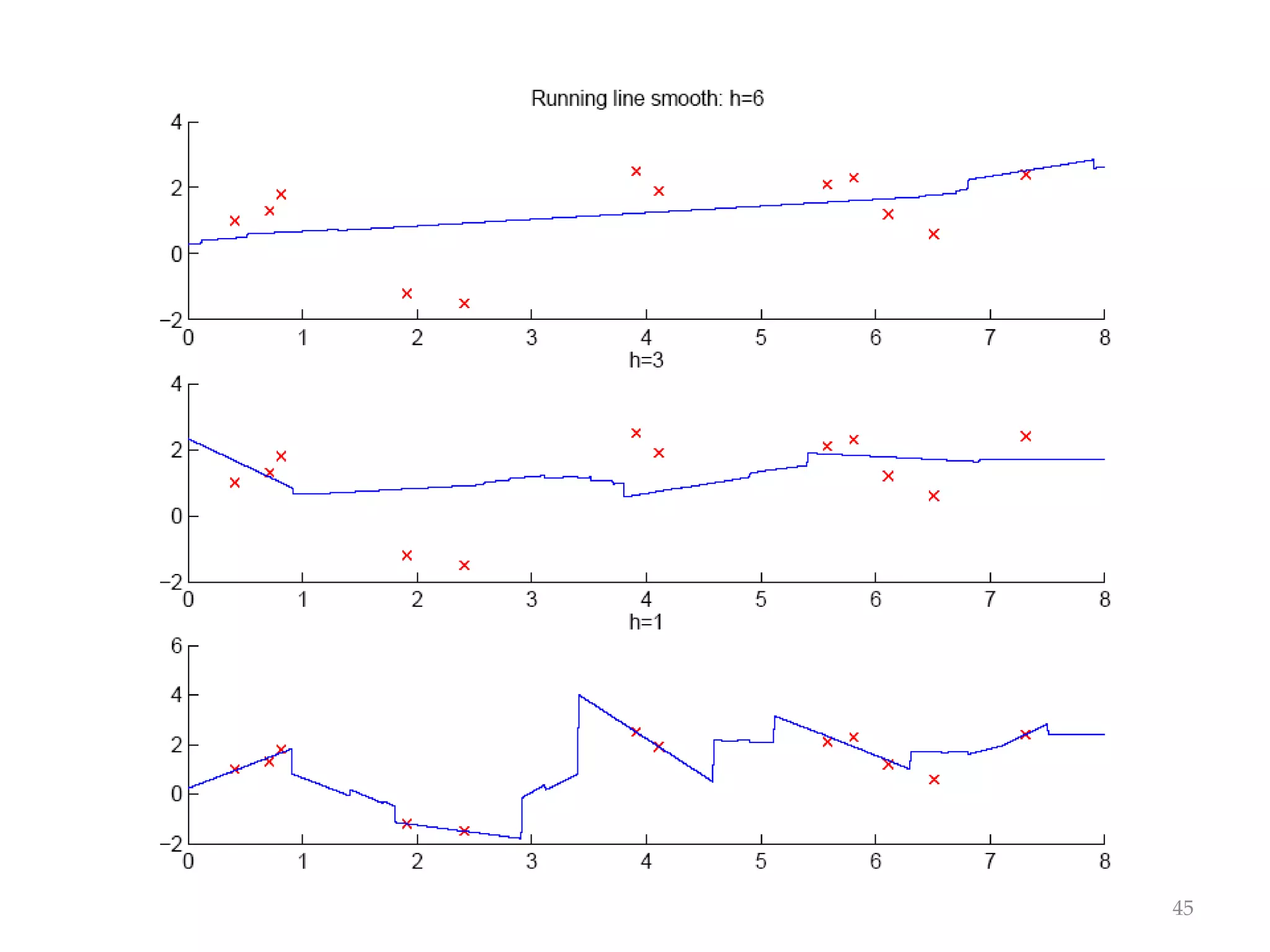
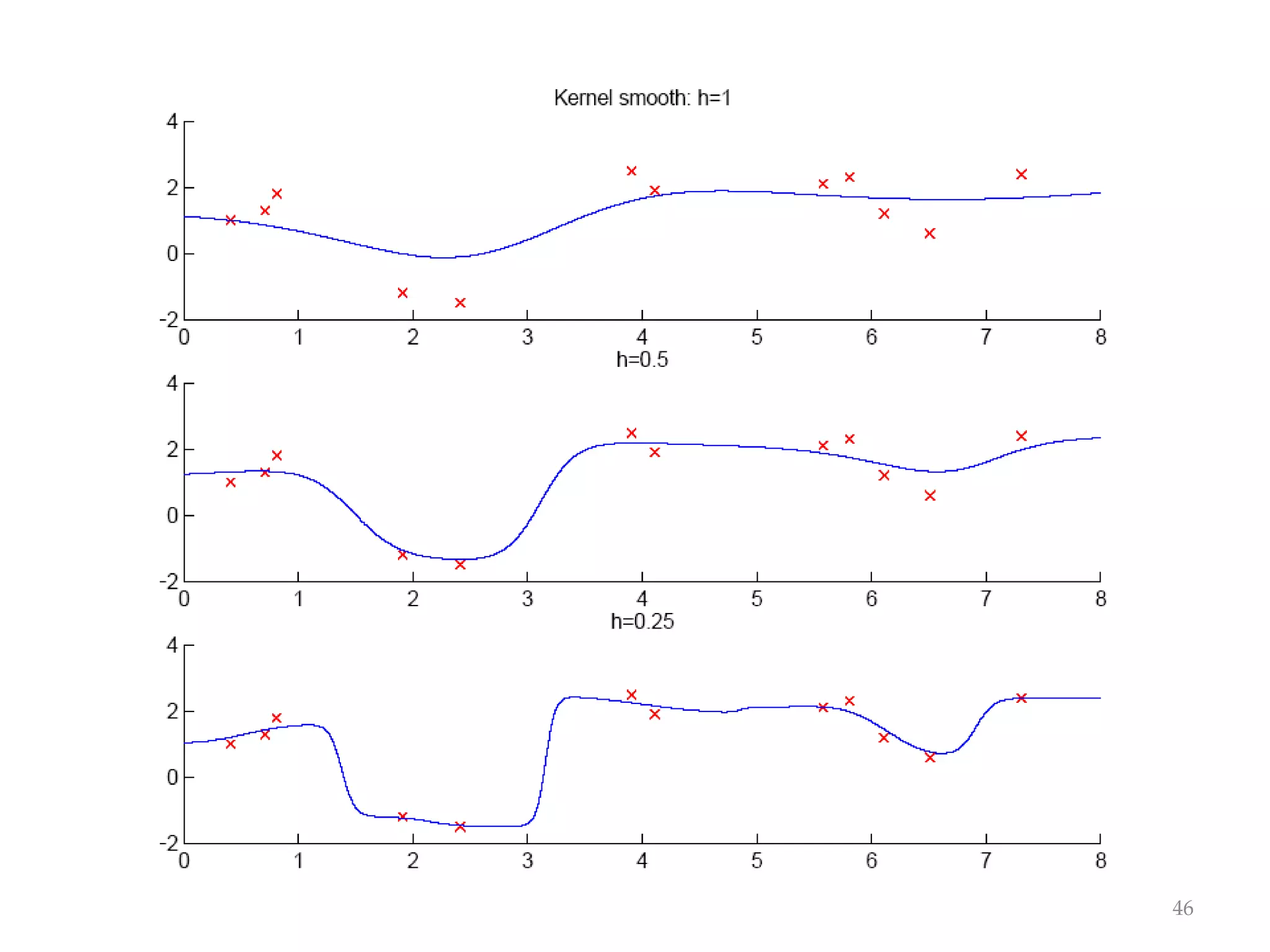
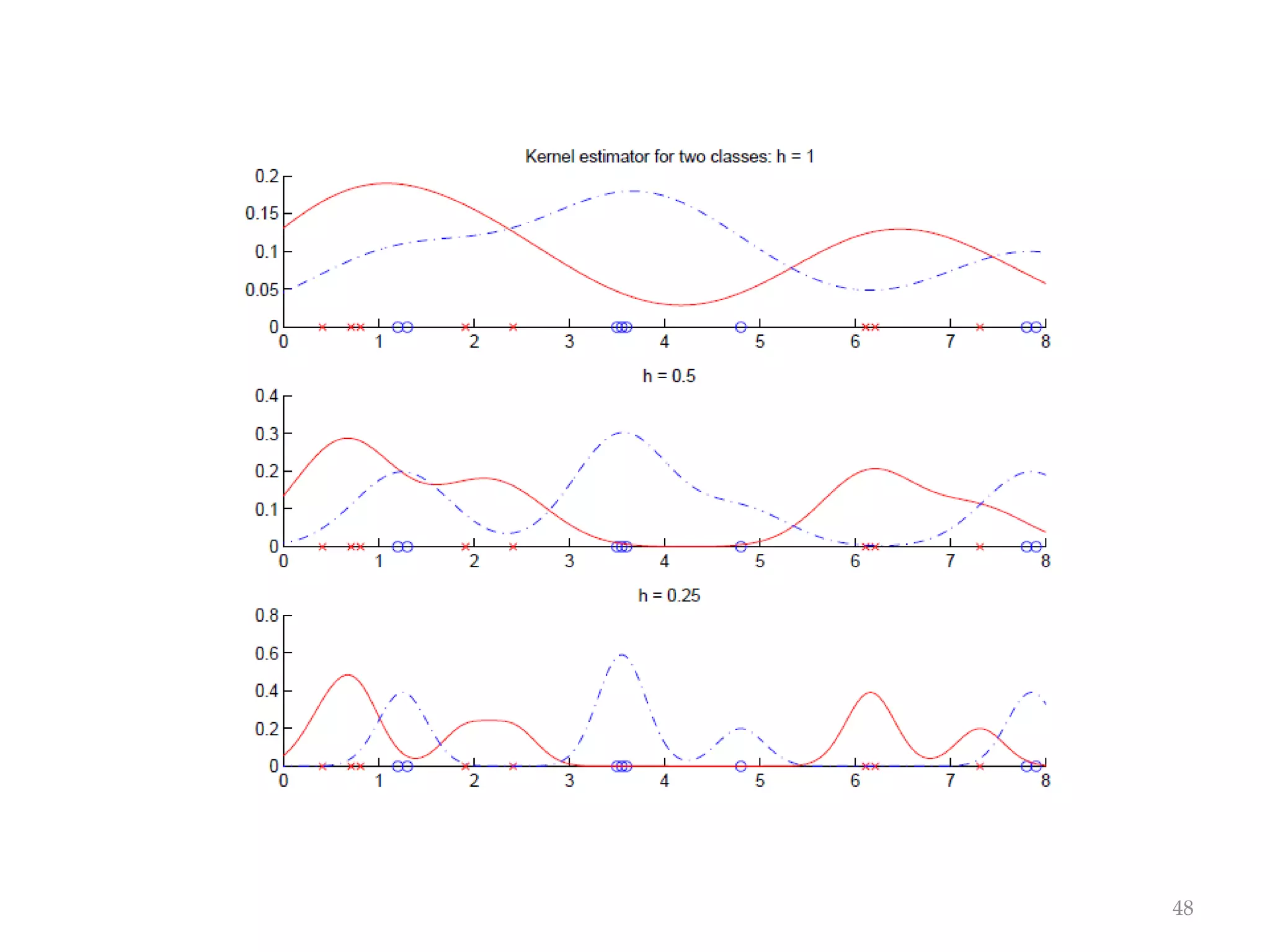
This document discusses clustering and density estimation techniques. It begins by introducing mixture models for density estimation, where the density is represented as a weighted sum of component densities. It then discusses k-means clustering, which groups data by finding cluster centers (prototypes) that minimize within-cluster variance. The document also covers Expectation-Maximization (EM) for parameter estimation in mixture models, hierarchical clustering approaches, and nonparametric density estimation methods like kernel density estimation and k-nearest neighbor estimation that make few assumptions about the underlying distributions.