Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takahiro Kubo
65,222 views
機械学習で泣かないためのコード設計
機械学習におけるコード設計のベストプラクティスについて
Data & Analytics
◦
Read more
344
Save
Share
Embed
Embed presentation
Download
Downloaded 223 times
1
/ 30
2
/ 30
3
/ 30
4
/ 30
5
/ 30
6
/ 30
7
/ 30
8
/ 30
9
/ 30
10
/ 30
11
/ 30
12
/ 30
13
/ 30
14
/ 30
15
/ 30
16
/ 30
17
/ 30
18
/ 30
19
/ 30
Most read
20
/ 30
21
/ 30
22
/ 30
23
/ 30
24
/ 30
25
/ 30
26
/ 30
27
/ 30
28
/ 30
Most read
29
/ 30
Most read
30
/ 30
More Related Content
PDF
全力解説!Transformer
by
Arithmer Inc.
PDF
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
PDF
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
Active Learning 入門
by
Shuyo Nakatani
PPTX
Triplet Loss 徹底解説
by
tancoro
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PDF
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
全力解説!Transformer
by
Arithmer Inc.
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
Active Learning 入門
by
Shuyo Nakatani
Triplet Loss 徹底解説
by
tancoro
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
分散学習のあれこれ~データパラレルからモデルパラレルまで~
by
Hideki Tsunashima
What's hot
PDF
Data-Centric AIの紹介
by
Kazuyuki Miyazawa
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
最適化超入門
by
Takami Sato
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
PPTX
ResNetの仕組み
by
Kota Nagasato
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
Data-Centric AIの紹介
by
Kazuyuki Miyazawa
最適輸送の計算アルゴリズムの研究動向
by
ohken
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
Optimizer入門&最新動向
by
Motokawa Tetsuya
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
近年のHierarchical Vision Transformer
by
Yusuke Uchida
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
最適化超入門
by
Takami Sato
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
ResNetの仕組み
by
Kota Nagasato
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
機械学習モデルの判断根拠の説明
by
Satoshi Hara
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
報酬設計と逆強化学習
by
Yusuke Nakata
Viewers also liked
PDF
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
PDF
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
PDF
機械学習の理論と実践
by
Preferred Networks
PPTX
失敗から学ぶ データ分析グループの チームマネジメント変遷 (デブサミ2016) #devsumi
by
Tokoroten Nakayama
PDF
プロトタイプで終わらせない死の谷を超える機械学習プロジェクトの進め方 #MLCT4
by
shakezo
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
PPTX
主成分分析 (pca)
by
Ji Wang
PDF
KDD2016勉強会 資料
by
Toshihiro Kamishima
PPTX
Deep learningの世界に飛び込む前の命綱
by
Junya Kamura
PDF
サーバーレスの今とこれから
by
真吾 吉田
PDF
「人工知能」をあなたのビジネスで活用するには
by
Takahiro Kubo
PDF
kintone evangelist meetup 2017
by
Takahiro Kubo
PPTX
10分で見る人工知能
by
kwp_george
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
機械学習の理論と実践
by
Preferred Networks
失敗から学ぶ データ分析グループの チームマネジメント変遷 (デブサミ2016) #devsumi
by
Tokoroten Nakayama
プロトタイプで終わらせない死の谷を超える機械学習プロジェクトの進め方 #MLCT4
by
shakezo
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
主成分分析 (pca)
by
Ji Wang
KDD2016勉強会 資料
by
Toshihiro Kamishima
Deep learningの世界に飛び込む前の命綱
by
Junya Kamura
サーバーレスの今とこれから
by
真吾 吉田
「人工知能」をあなたのビジネスで活用するには
by
Takahiro Kubo
kintone evangelist meetup 2017
by
Takahiro Kubo
10分で見る人工知能
by
kwp_george
More from Takahiro Kubo
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PDF
感情の出どころを探る、一歩進んだ感情解析
by
Takahiro Kubo
PDF
財務・非財務一体型の企業分析に向けて
by
Takahiro Kubo
PDF
機械学習の力を引き出すための依存性管理
by
Takahiro Kubo
PDF
Graph Attention Network
by
Takahiro Kubo
PDF
国際会計基準(IFRS)適用企業の財務評価方法
by
Takahiro Kubo
PDF
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
PPTX
ESG評価を支える自然言語処理基盤の構築
by
Takahiro Kubo
PDF
自然言語処理で読み解く金融文書
by
Takahiro Kubo
PDF
あるべきESG投資の評価に向けた、自然言語処理の活用
by
Takahiro Kubo
PDF
Reinforcement Learning Inside Business
by
Takahiro Kubo
PDF
ACL2018の歩き方
by
Takahiro Kubo
PPTX
2018年12月4日までに『呪術廻戦』を読む理由
by
Takahiro Kubo
PDF
EMNLP2018 Overview
by
Takahiro Kubo
PDF
TISにおける、研究開発の方針とメソッド 2018
by
Takahiro Kubo
PDF
Curiosity may drives your output routine.
by
Takahiro Kubo
PDF
arXivTimes Review: 2019年前半で印象に残った論文を振り返る
by
Takahiro Kubo
PDF
自然言語処理で新型コロナウィルスに立ち向かう
by
Takahiro Kubo
PDF
nlpaper.challenge NLP/CV交流勉強会 画像認識 7章
by
Takahiro Kubo
PDF
Expressing Visual Relationships via Language: 自然言語による画像編集を目指して
by
Takahiro Kubo
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
感情の出どころを探る、一歩進んだ感情解析
by
Takahiro Kubo
財務・非財務一体型の企業分析に向けて
by
Takahiro Kubo
機械学習の力を引き出すための依存性管理
by
Takahiro Kubo
Graph Attention Network
by
Takahiro Kubo
国際会計基準(IFRS)適用企業の財務評価方法
by
Takahiro Kubo
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
ESG評価を支える自然言語処理基盤の構築
by
Takahiro Kubo
自然言語処理で読み解く金融文書
by
Takahiro Kubo
あるべきESG投資の評価に向けた、自然言語処理の活用
by
Takahiro Kubo
Reinforcement Learning Inside Business
by
Takahiro Kubo
ACL2018の歩き方
by
Takahiro Kubo
2018年12月4日までに『呪術廻戦』を読む理由
by
Takahiro Kubo
EMNLP2018 Overview
by
Takahiro Kubo
TISにおける、研究開発の方針とメソッド 2018
by
Takahiro Kubo
Curiosity may drives your output routine.
by
Takahiro Kubo
arXivTimes Review: 2019年前半で印象に残った論文を振り返る
by
Takahiro Kubo
自然言語処理で新型コロナウィルスに立ち向かう
by
Takahiro Kubo
nlpaper.challenge NLP/CV交流勉強会 画像認識 7章
by
Takahiro Kubo
Expressing Visual Relationships via Language: 自然言語による画像編集を目指して
by
Takahiro Kubo
機械学習で泣かないためのコード設計
1.
Copyright © 2016
TIS Inc. All rights reserved. 機械学習で泣かないためのコード設計 戦略技術センター 久保隆宏
2.
2 Agenda • Who are
you • TIS株式会社について • 戦略技術センターについて • 機械学習あるある物語 • 機械学習で泣かないための設計(案) • Model • Trainer • DataProcessor • ModelAPI • Resource • Appendix: API一覧
3.
3 Who are you
4.
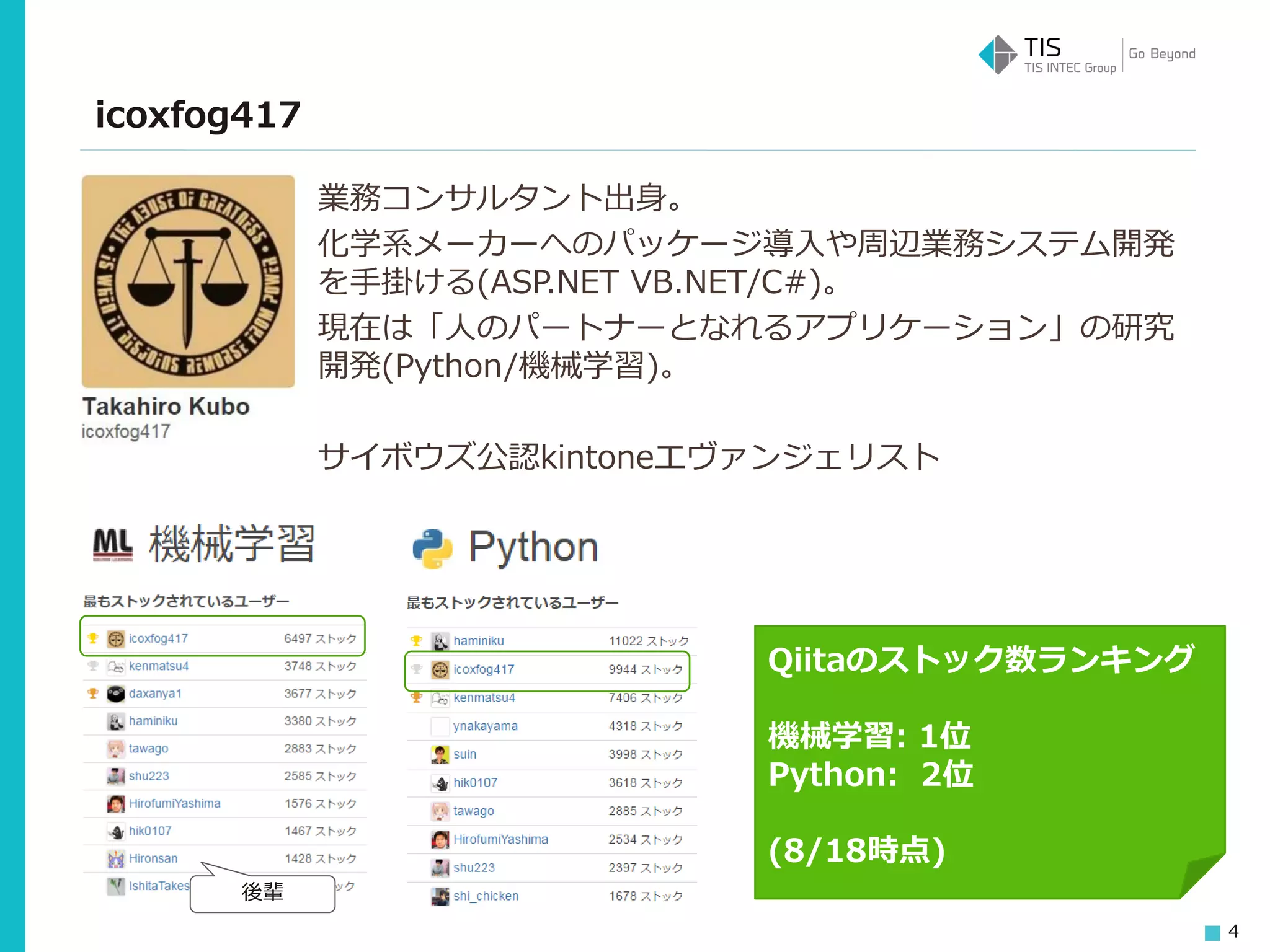
4 業務コンサルタント出身。 化学系メーカーへのパッケージ導入や周辺業務システム開発 を手掛ける(ASP.NET VB.NET/C#)。 現在は「人のパートナーとなれるアプリケーション」の研究 開発(Python/機械学習)。 サイボウズ公認kintoneエヴァンジェリスト Qiitaのストック数ランキング 機械学習: 1位 Python:
2位 (8/18時点) icoxfog417 後輩
5.
5 TISとは?
6.
6 会社紹介 TISはTISインテックグループの中核会社となります。 TISインテックグループは多様な得意分野をもつ企業の総体であり、一体感のあるグル ープフォーメーションの下お客様のニーズにお応えします。 TIS INTEC GROUP(59社
19,393名) お客様
7.
7 TISとは?
8.
8 戦略技術センターについて(1/2) ミッション ・中長期(3~10年)的な視点からのサービスのプロトタイプ開発・検証 ・技術プレゼンスの向上(=研究活動の対外発信) サービスのプロトタイプ開発 技術プレゼンスの向上 薬剤師BOT 会議診断AI 観光ルート自動生成 etc・・・ カンファレンスへの 登壇、ハッカソンへ の参加、勉強会の開 催etc・・・
9.
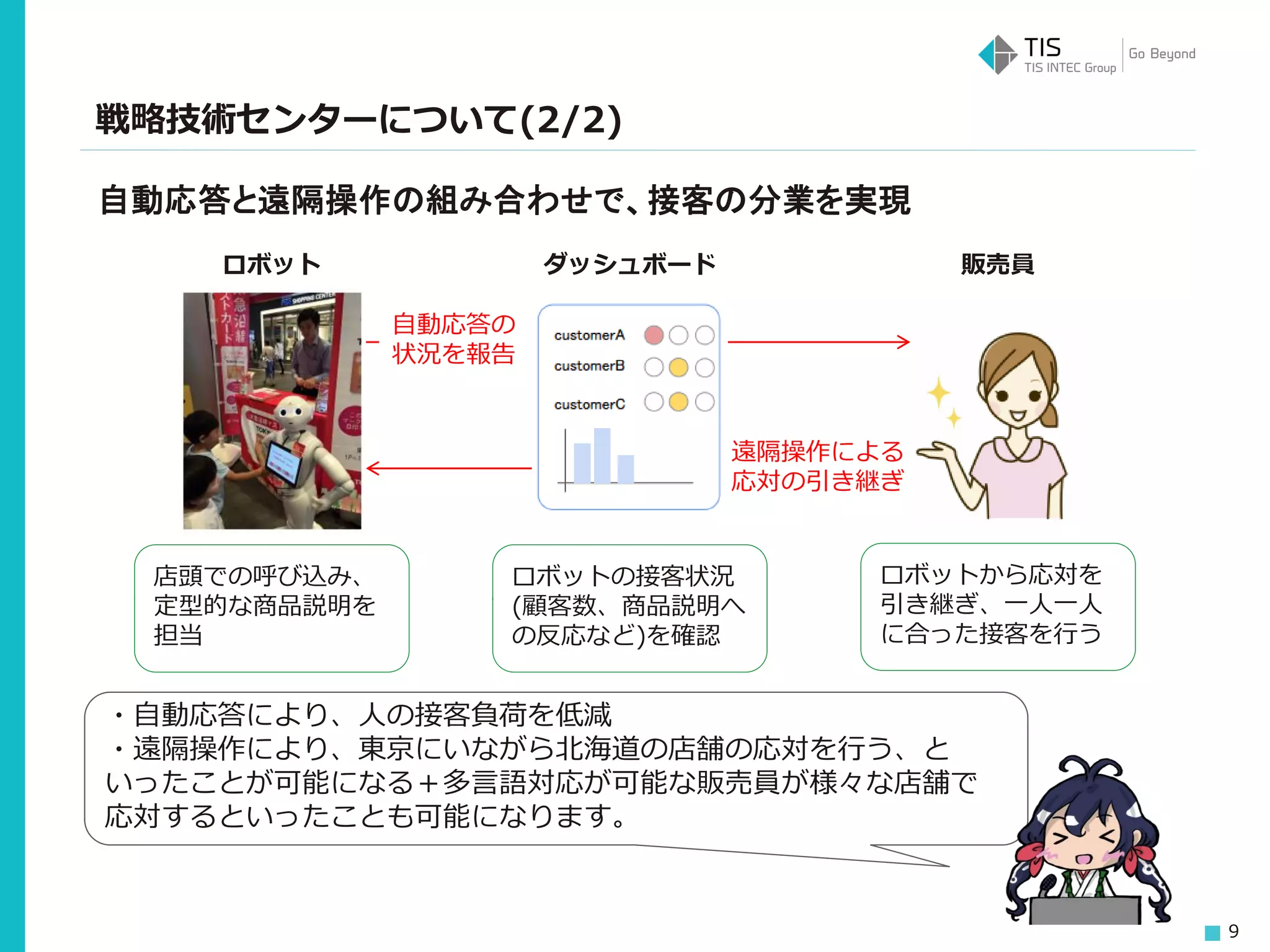
9 戦略技術センターについて(2/2) ロボット 販売員 店頭での呼び込み、 定型的な商品説明を 担当 自動応答と遠隔操作の組み合わせで、接客の分業を実現 遠隔操作による 応対の引き継ぎ ロボットから応対を 引き継ぎ、一人一人 に合った接客を行う ダッシュボード ロボットの接客状況 (顧客数、商品説明へ の反応など)を確認 自動応答の 状況を報告 ・自動応答により、人の接客負荷を低減 ・遠隔操作により、東京にいながら北海道の店舗の応対を行う、と いったことが可能になる+多言語対応が可能な販売員が様々な店舗で 応対するといったことも可能になります。
10.
10 機械学習あるある物語
11.
11 MNISTとかのExampleを動かしてうまく動いているとき →NEXT: 自分のデータで試してみよう!
12.
12 自分で集めたデータでうまく動かなくて戸惑っている時 →NEXT: でもここから本番、がんばるぞい!
13.
13 修正したら繰り出される謎の例外 初期化の方法・学習率・レイヤ数・・・いろいろなパラメーター 精度が出ない・・・データがないせい?モデルが自分のデータに合わないせい? データの前処理→こんにちは線形代数
14.
14 まあ(Example)動いたしな? 中途半端だけどおしまいにする(完)
15.
15 機械学習の難しさ 機械学習は、うまくうごかないときに考えられる理由がたくさんある。 ・データが悪いのか ・そもそものデータが良くない(データの量・データの質) ・前処理に問題がある ・モデルが悪いのか ・バグがある(伝搬が上手くいっていないなど) ・構成が悪い ・(逆に間違っててもそれなりに動くことがあり、混乱を助長する) ・学習方法が悪いのか ・ノードの初期化方法、学習率、学習率低減のタイミングetc→職人芸 ・辛抱が足りない(明日になれば学習が進んでるかも?) モデルや学習方法の書き換えには、機械学習の理論的な理解が必要になる場 面も多い。それぞれのフレームワークのクセにもかなり翻弄される(Example だけでなく、ライブラリ内部のコードを読まないといけないことになること も多い)。
16.
16 ただでさえ難しい+原因の切り分けができない
17.
17 機械学習で泣かないための設計(案)
18.
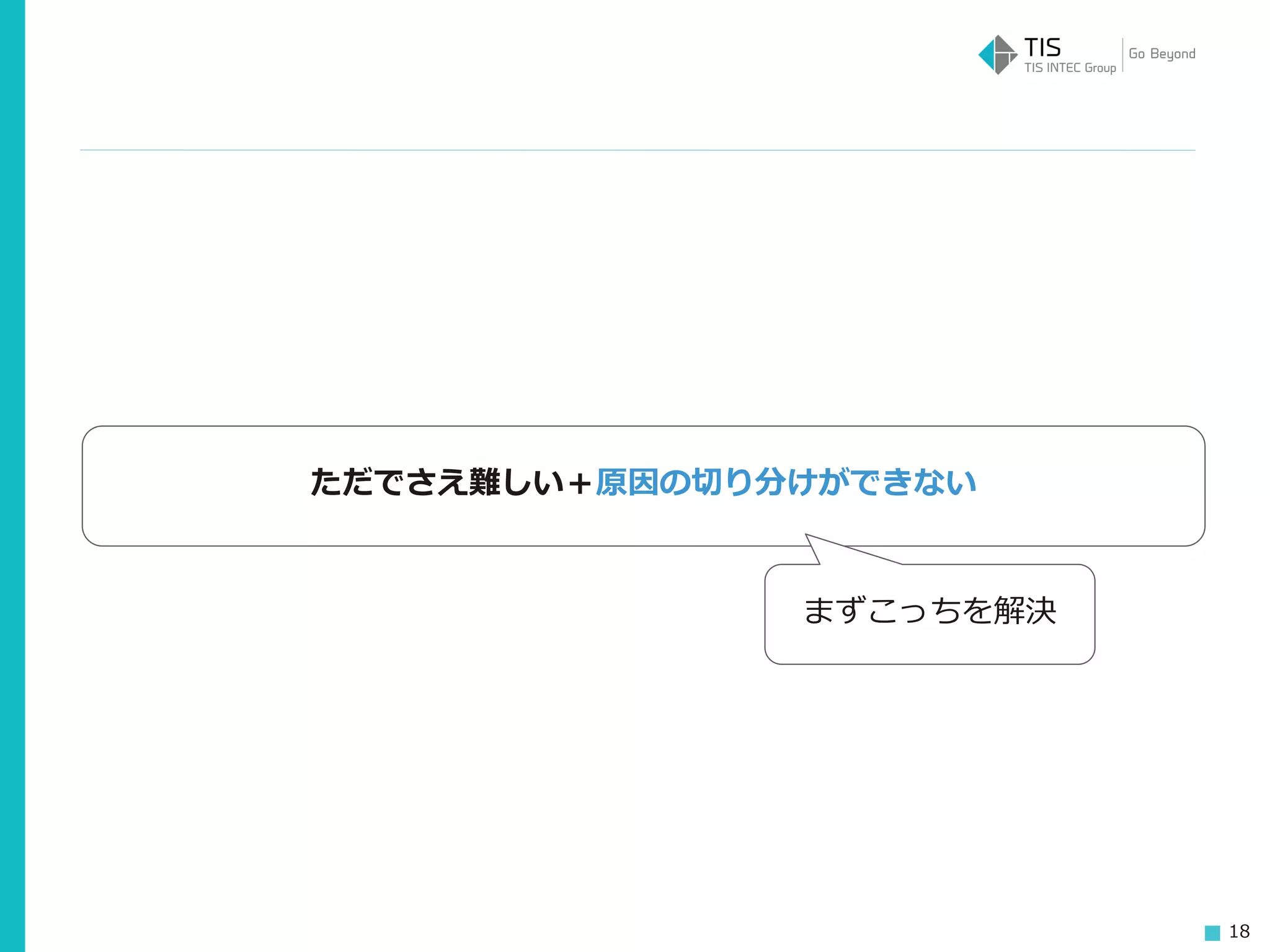
18 ただでさえ難しい+原因の切り分けができない まずこっちを解決
19.
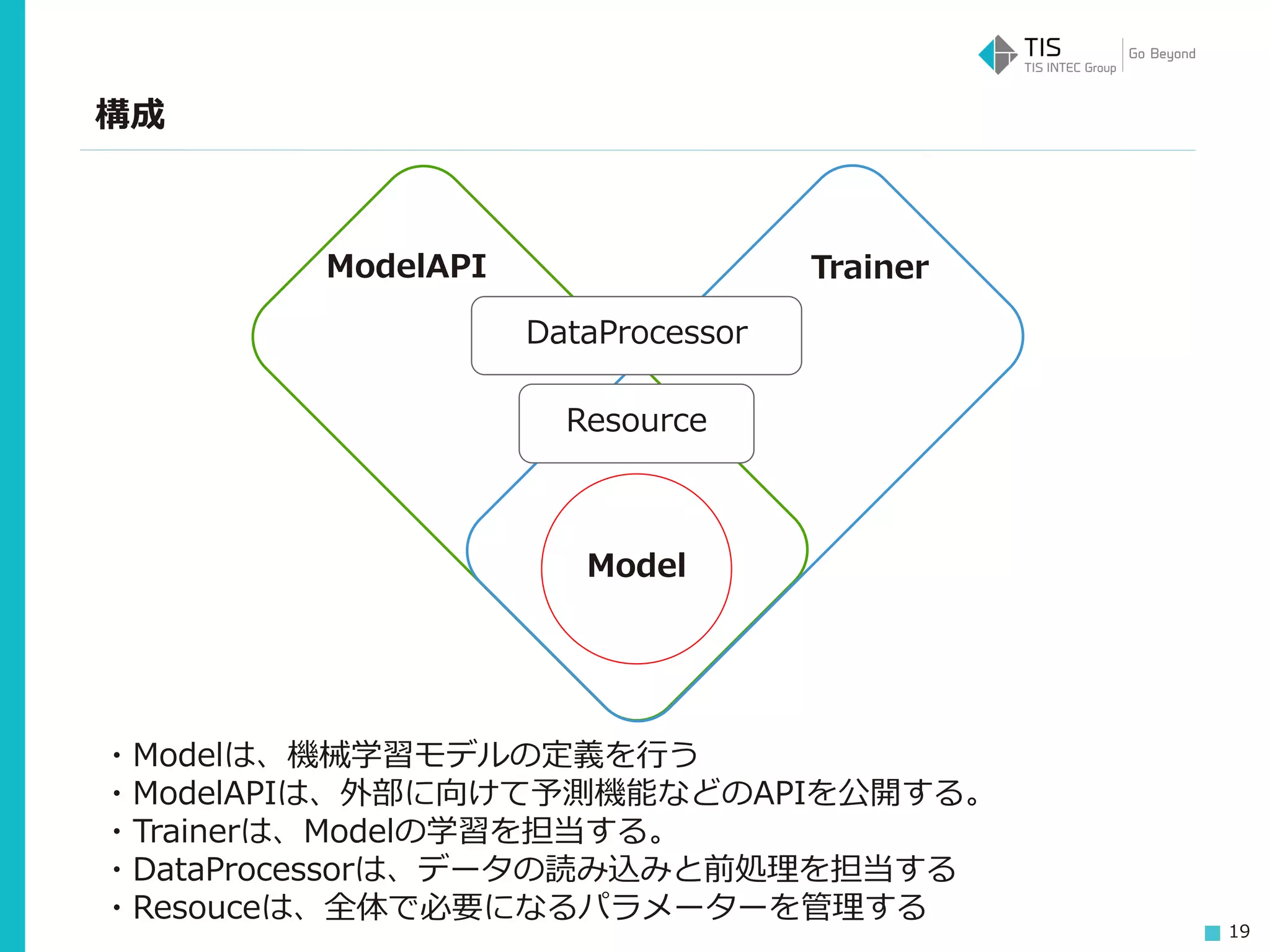
19 構成 Model DataProcessor Resource ModelAPI Trainer ・Modelは、機械学習モデルの定義を行う ・ModelAPIは、外部に向けて予測機能などのAPIを公開する。 ・Trainerは、Modelの学習を担当する。 ・DataProcessorは、データの読み込みと前処理を担当する ・Resouceは、全体で必要になるパラメーターを管理する
20.
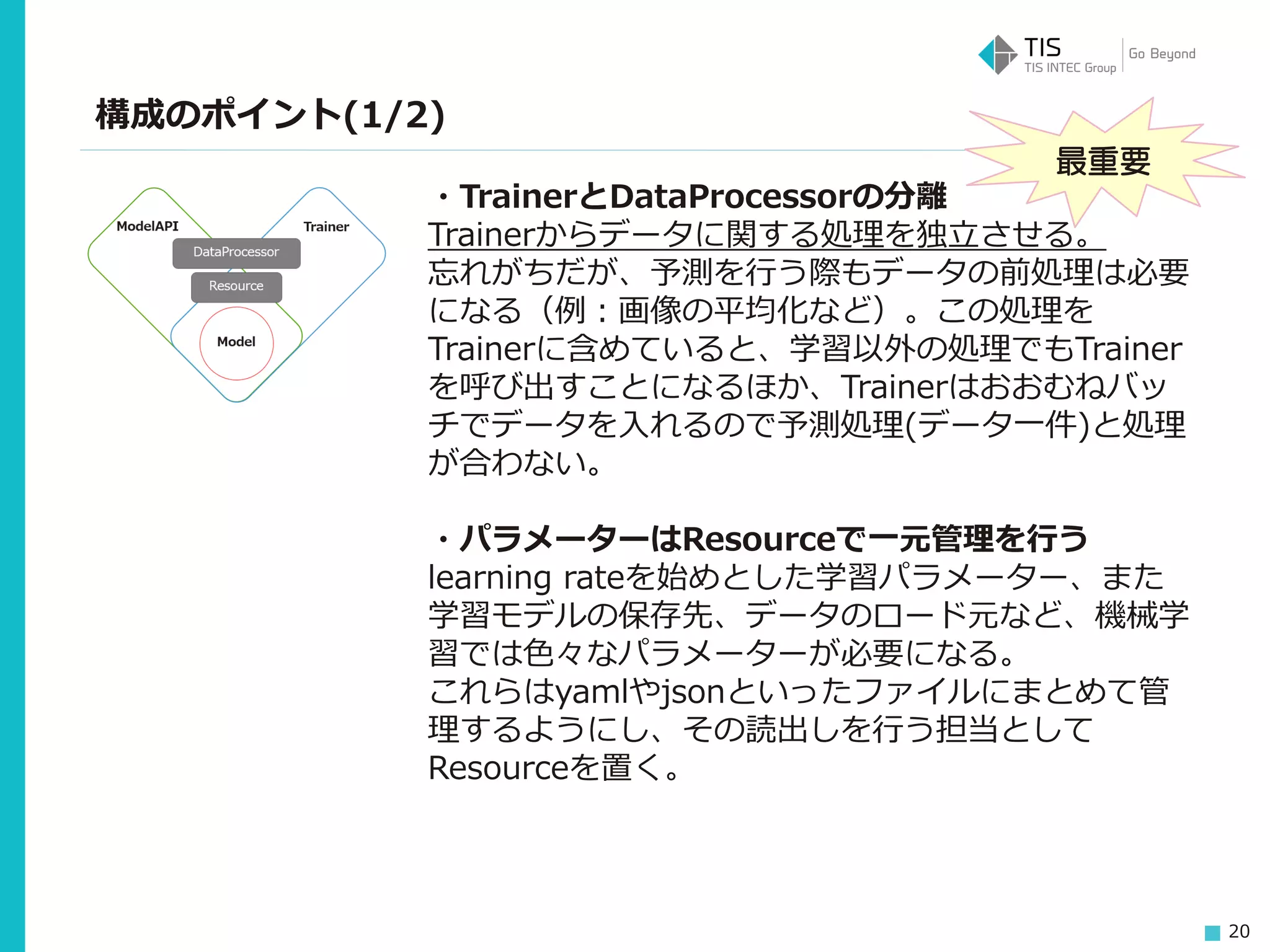
20 構成のポイント(1/2) ・TrainerとDataProcessorの分離 Trainerからデータに関する処理を独立させる。 忘れがちだが、予測を行う際もデータの前処理は必要 になる(例:画像の平均化など)。この処理を Trainerに含めていると、学習以外の処理でもTrainer を呼び出すことになるほか、Trainerはおおむねバッ チでデータを入れるので予測処理(データ一件)と処理 が合わない。 ・パラメーターはResourceで一元管理を行う learning rateを始めとした学習パラメーター、また 学習モデルの保存先、データのロード元など、機械学 習では色々なパラメーターが必要になる。 これらはyamlやjsonといったファイルにまとめて管 理するようにし、その読出しを行う担当として Resourceを置く。 最重要
21.
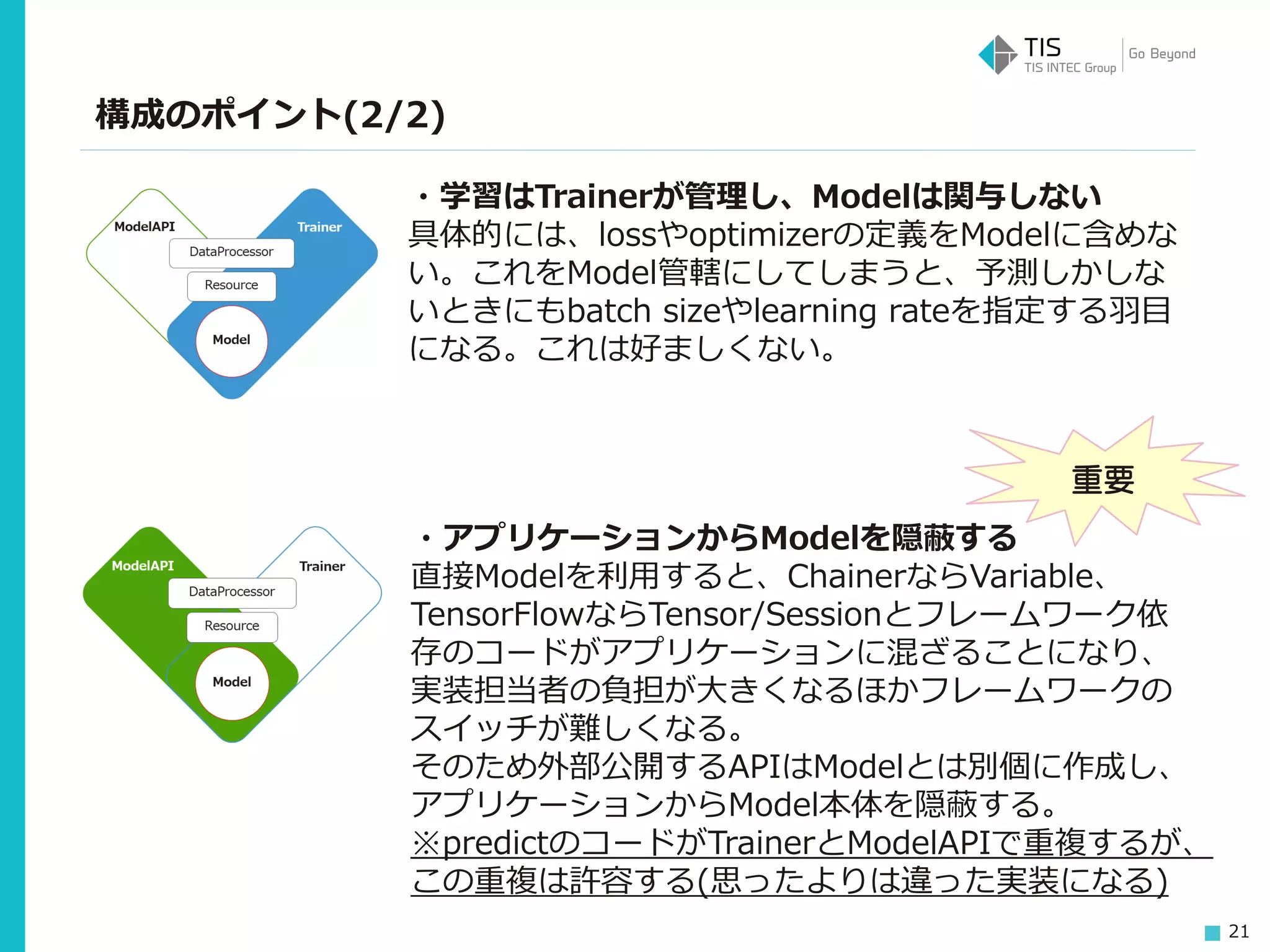
21 構成のポイント(2/2) ・学習はTrainerが管理し、Modelは関与しない 具体的には、lossやoptimizerの定義をModelに含めな い。これをModel管轄にしてしまうと、予測しかしな いときにもbatch sizeやlearning rateを指定する羽目 になる。これは好ましくない。 ・アプリケーションからModelを隠蔽する 直接Modelを利用すると、ChainerならVariable、 TensorFlowならTensor/Sessionとフレームワーク依 存のコードがアプリケーションに混ざることになり、 実装担当者の負担が大きくなるほかフレームワークの スイッチが難しくなる。 そのため外部公開するAPIはModelとは別個に作成し、 アプリケーションからModel本体を隠蔽する。 ※predictのコードがTrainerとModelAPIで重複するが、 この重複は許容する(思ったよりは違った実装になる) 重要
22.
22 テストの実施 ・モデルのテスト ModelAPIと一体でテストし、入力からきちんと値が出力されることを確認。 ・データ、またデータ前処理のテスト DataProcessorを単独でテストする。可能であれば、baselineとなるモデル (SVMなど)でデータそのものの分類性能を測ったりする。scikit-learnの Feature Selectionを使えばこのあたりのテストを簡単に実装できる。 ・学習のテスト モデル、およびデータ処理のテストがパスすることを確認した後にテストす る(これによりモデルのバグ・データ処理に起因するバグを想定から外せる)。 lossがきちんと下がるかなどを確認する。このあたりでGPUがないと辛抱が 足りない問題が顕在化するので、GPUの使い方(Amazon GPU
Instanceな ど)はしっかりマスターしておく(Terraform/Ansibleはこの助けになる)。 複数パラメーターの設定でいろいろ回すことになるので、この際Resourceと いう形で、どこでどのパラメーターの学習が動いているのかがわかるのはと ても安心できる。
23.
23 ただでさえ難しい+原因の切り分けができない だいぶ解決 これで・・・
24.
24 ただでさえ難しい+原因の切り分けができない ・・・
25.
25 おすすめ 単純なモデルからはじめる(scikit-learnなど) • どのみちDataProcessorのところで必要になる • 最終的にChainerやTensorFlowでやるにしても、ベースラインのモデルは 必要になる •
自分でデータを用意するなら、Deepの恩恵が得られるほど集められないこ とが多い(=使うだけ徒労になる可能性も高い)。 基礎知識はCourseraのMachine Learningをおすすめ(英語という壁はあ るが、現時点出ているどの書籍よりもわ かりやすい+日本語字幕もある)
26.
26 ぜひ new machine learning life!
27.
THANK YOU
28.
28 Appendix: API一覧(1/3) Model • constructor:
モデルに必要な構成要素(隠れ層)などの定義 • forward(inference): constructorで定義した構成要素を利用し、入力を出 力にする(伝搬)プロセスを定義する。 • 学習中とそうでない場合で構成が変わる場合(Dropoutなど)、それを引数 に取る。※ここでlossを出さないこと(出してもいいが、outputもちゃんと 返す) ModelAPI • constructor: 最低限Modelのパスを取得し、読み込む • predict: 配列などの一般的な変数から、Modelを利用した予測値を返す
29.
29 Appendix: API一覧(2/3) Trainer • constructor:
modelと学習に必要なパラメーターを受け取る。 DataProcessorは、この段階か、trainのメソッド内で作成する。 • calc_loss: 最適化の対象となる誤差の計算プロセスを定義する (TensorFlow的にはtrain_op) • set_optimizer(build): calc_lossの最適化プロセスを定義する • train: 学習データ、または作成済みDataProcessorを受け取り、学習の実 行(set_optimizerで作成したoptimizerのupdate)を行う。この過程で、進 捗状況を定期的にreportする。 • report: 学習の進捗状況の出力、また学習モデルの保存などを行う DataProcessor • constructor: データへのパスなど • prepare: データを読み込み、後処理で必要な統計量(平均など)を計算する • format(preprocess): 生のデータを学習・予測用にフォーマットする • batch_iter(feed): batch size/shuffleするかどうかなどを受け取り、要求 に応じたデータを返す。iteratorとして機能する。
30.
30 Appendix: API一覧(3/3) Resource • constructor:
設定ファイルの保存先パスを受け取る • get_xxxx: 設定ファイル内の所定の項目を取得する。※get(“data_path”) というように、文字列でパラメータを受け取らないこと(利用側が環境変数 名を覚えていないといけなくなるので)。 • get_data_root • get_model_path • get_log_folder • などなど • create_trainer/create_dataprocessorという感じで、読み込んだパ ラメーターを元に各インスタンスを生成するメソッドを持たせるとい う手もある。
Download


























![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)


































