Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takahiro Kubo
PDF, PPTX
9,524 views
機械学習の力を引き出すための依存性管理
Dependency management to overcome the high interest credit card.
Data & Analytics
◦
Read more
135
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 63
2
/ 63
3
/ 63
4
/ 63
5
/ 63
6
/ 63
7
/ 63
8
/ 63
9
/ 63
10
/ 63
11
/ 63
12
/ 63
13
/ 63
14
/ 63
15
/ 63
16
/ 63
17
/ 63
18
/ 63
19
/ 63
20
/ 63
21
/ 63
22
/ 63
23
/ 63
24
/ 63
25
/ 63
26
/ 63
27
/ 63
28
/ 63
29
/ 63
30
/ 63
31
/ 63
32
/ 63
33
/ 63
34
/ 63
35
/ 63
36
/ 63
37
/ 63
38
/ 63
39
/ 63
40
/ 63
41
/ 63
42
/ 63
43
/ 63
44
/ 63
45
/ 63
46
/ 63
47
/ 63
48
/ 63
49
/ 63
50
/ 63
51
/ 63
52
/ 63
53
/ 63
54
/ 63
55
/ 63
56
/ 63
57
/ 63
58
/ 63
59
/ 63
60
/ 63
61
/ 63
62
/ 63
63
/ 63
More Related Content
PDF
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
PDF
最適化計算の概要まとめ
by
Yuichiro MInato
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PPTX
優れた研究論文の書き方―7つの提案
by
Masanori Kado
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
状態空間モデルの考え方・使い方 - TokyoR #38
by
horihorio
PPTX
分散深層学習 @ NIPS'17
by
Takuya Akiba
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
最適化計算の概要まとめ
by
Yuichiro MInato
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
優れた研究論文の書き方―7つの提案
by
Masanori Kado
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
状態空間モデルの考え方・使い方 - TokyoR #38
by
horihorio
分散深層学習 @ NIPS'17
by
Takuya Akiba
What's hot
PDF
先端技術とメディア表現1 #FTMA15
by
Yoichi Ochiai
PPTX
CatBoost on GPU のひみつ
by
Takuji Tahara
PDF
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15
by
Shuyo Nakatani
PDF
Active Learning の基礎と最近の研究
by
Fumihiko Takahashi
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
PDF
【DL輪読会】Domain Generalization by Learning and Removing Domainspecific Features
by
Deep Learning JP
PDF
ブレインパッドにおける機械学習プロジェクトの進め方
by
BrainPad Inc.
PPTX
【宝くじ仮説】The Lottery Ticket Hypothesis: Finding Small, Trainable Neural Networks
by
Yosuke Shinya
PPTX
劣モジュラ最適化と機械学習1章
by
Hakky St
PPTX
Triplet Loss 徹底解説
by
tancoro
PPTX
優れた研究論文の書き方
by
Masanori Kado
PPTX
データサイエンティスト向け性能問題対応の基礎
by
Tetsutaro Watanabe
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
PCAの最終形態GPLVMの解説
by
弘毅 露崎
PPTX
卒論執筆・スライド作成のポイント
by
Tsubasa Hirakawa
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PDF
言語モデル入門
by
Yoshinari Fujinuma
PDF
[DLHacks]Comet ML -機械学習のためのGitHub-
by
Deep Learning JP
PDF
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
先端技術とメディア表現1 #FTMA15
by
Yoichi Ochiai
CatBoost on GPU のひみつ
by
Takuji Tahara
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15
by
Shuyo Nakatani
Active Learning の基礎と最近の研究
by
Fumihiko Takahashi
数学で解き明かす深層学習の原理
by
Taiji Suzuki
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
【DL輪読会】Domain Generalization by Learning and Removing Domainspecific Features
by
Deep Learning JP
ブレインパッドにおける機械学習プロジェクトの進め方
by
BrainPad Inc.
【宝くじ仮説】The Lottery Ticket Hypothesis: Finding Small, Trainable Neural Networks
by
Yosuke Shinya
劣モジュラ最適化と機械学習1章
by
Hakky St
Triplet Loss 徹底解説
by
tancoro
優れた研究論文の書き方
by
Masanori Kado
データサイエンティスト向け性能問題対応の基礎
by
Tetsutaro Watanabe
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PCAの最終形態GPLVMの解説
by
弘毅 露崎
卒論執筆・スライド作成のポイント
by
Tsubasa Hirakawa
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
言語モデル入門
by
Yoshinari Fujinuma
[DLHacks]Comet ML -機械学習のためのGitHub-
by
Deep Learning JP
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
Similar to 機械学習の力を引き出すための依存性管理
PPTX
AIシステムの要求とプロジェクトマネジメント-前半:機械学習工学概論
by
Nobukazu Yoshioka
PDF
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PPTX
Hidden technical debt in machine learning systems(日本語資料)
by
Ogushi Masaya
PPTX
機械学習応用システムのための要求工学
by
Nobukazu Yoshioka
PPTX
プロジェクトマネージャのための機械学習工学入門
by
Nobukazu Yoshioka
PPTX
「機械学習:技術的負債の高利子クレジットカード」のまとめ
by
Recruit Technologies
PDF
あなたの業務に機械学習を活用する5つのポイント
by
Shohei Hido
PDF
機械学習の課題設定講座
by
幹雄 小川
PPTX
エンタープライズと機械学習技術
by
maruyama097
PPTX
東北大学AIE - 機械学習中級編とAzure紹介
by
Daiyu Hatakeyama
PDF
kintone Café 大阪 Vol.13 〜karuraで学ぶ、機械学習の活かし方〜
by
Takahiro Kubo
PPTX
機械学習を活用するための、3本の柱~教育型の機械学習ツールの必要性~
by
Takahiro Kubo
PDF
【20170414みんなのAI】機械学習の民主化を促進するAI活用術
by
ナレッジコミュニケーション
PPTX
機械学習の基礎
by
Ken Kumagai
PPTX
「人工知能」との正しい付き合い方
by
Takahiro Kubo
PDF
「人工知能」をあなたのビジネスで活用するには
by
Takahiro Kubo
PDF
機械学習技術の紹介
by
Takahiro Kubo
PDF
機械学習の実践を始める
by
ssuseraebb59
AIシステムの要求とプロジェクトマネジメント-前半:機械学習工学概論
by
Nobukazu Yoshioka
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
Hidden technical debt in machine learning systems(日本語資料)
by
Ogushi Masaya
機械学習応用システムのための要求工学
by
Nobukazu Yoshioka
プロジェクトマネージャのための機械学習工学入門
by
Nobukazu Yoshioka
「機械学習:技術的負債の高利子クレジットカード」のまとめ
by
Recruit Technologies
あなたの業務に機械学習を活用する5つのポイント
by
Shohei Hido
機械学習の課題設定講座
by
幹雄 小川
エンタープライズと機械学習技術
by
maruyama097
東北大学AIE - 機械学習中級編とAzure紹介
by
Daiyu Hatakeyama
kintone Café 大阪 Vol.13 〜karuraで学ぶ、機械学習の活かし方〜
by
Takahiro Kubo
機械学習を活用するための、3本の柱~教育型の機械学習ツールの必要性~
by
Takahiro Kubo
【20170414みんなのAI】機械学習の民主化を促進するAI活用術
by
ナレッジコミュニケーション
機械学習の基礎
by
Ken Kumagai
「人工知能」との正しい付き合い方
by
Takahiro Kubo
「人工知能」をあなたのビジネスで活用するには
by
Takahiro Kubo
機械学習技術の紹介
by
Takahiro Kubo
機械学習の実践を始める
by
ssuseraebb59
More from Takahiro Kubo
PDF
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
PDF
財務・非財務一体型の企業分析に向けて
by
Takahiro Kubo
PDF
感情の出どころを探る、一歩進んだ感情解析
by
Takahiro Kubo
PPTX
ESG評価を支える自然言語処理基盤の構築
by
Takahiro Kubo
PDF
自然言語処理で読み解く金融文書
by
Takahiro Kubo
PDF
技術文書を書く際の、心技体<改訂版>
by
Takahiro Kubo
PDF
Graph Attention Network
by
Takahiro Kubo
PDF
国際会計基準(IFRS)適用企業の財務評価方法
by
Takahiro Kubo
PDF
あるべきESG投資の評価に向けた、自然言語処理の活用
by
Takahiro Kubo
PDF
Reinforcement Learning Inside Business
by
Takahiro Kubo
PDF
ACL2018の歩き方
by
Takahiro Kubo
PPTX
2018年12月4日までに『呪術廻戦』を読む理由
by
Takahiro Kubo
PDF
arXivTimes Review: 2019年前半で印象に残った論文を振り返る
by
Takahiro Kubo
PDF
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
by
Takahiro Kubo
PDF
EMNLP2018 Overview
by
Takahiro Kubo
PDF
TISにおける、研究開発の方針とメソッド 2018
by
Takahiro Kubo
PDF
Curiosity may drives your output routine.
by
Takahiro Kubo
PDF
自然言語処理で新型コロナウィルスに立ち向かう
by
Takahiro Kubo
PDF
nlpaper.challenge NLP/CV交流勉強会 画像認識 7章
by
Takahiro Kubo
PDF
Expressing Visual Relationships via Language: 自然言語による画像編集を目指して
by
Takahiro Kubo
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
財務・非財務一体型の企業分析に向けて
by
Takahiro Kubo
感情の出どころを探る、一歩進んだ感情解析
by
Takahiro Kubo
ESG評価を支える自然言語処理基盤の構築
by
Takahiro Kubo
自然言語処理で読み解く金融文書
by
Takahiro Kubo
技術文書を書く際の、心技体<改訂版>
by
Takahiro Kubo
Graph Attention Network
by
Takahiro Kubo
国際会計基準(IFRS)適用企業の財務評価方法
by
Takahiro Kubo
あるべきESG投資の評価に向けた、自然言語処理の活用
by
Takahiro Kubo
Reinforcement Learning Inside Business
by
Takahiro Kubo
ACL2018の歩き方
by
Takahiro Kubo
2018年12月4日までに『呪術廻戦』を読む理由
by
Takahiro Kubo
arXivTimes Review: 2019年前半で印象に残った論文を振り返る
by
Takahiro Kubo
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
by
Takahiro Kubo
EMNLP2018 Overview
by
Takahiro Kubo
TISにおける、研究開発の方針とメソッド 2018
by
Takahiro Kubo
Curiosity may drives your output routine.
by
Takahiro Kubo
自然言語処理で新型コロナウィルスに立ち向かう
by
Takahiro Kubo
nlpaper.challenge NLP/CV交流勉強会 画像認識 7章
by
Takahiro Kubo
Expressing Visual Relationships via Language: 自然言語による画像編集を目指して
by
Takahiro Kubo
機械学習の力を引き出すための依存性管理
1.
Copyright © 2017
TIS Inc. All rights reserved. 機械学習の力を引き出すための依存性管理 戦略技術センター 久保隆宏 Dependency management to overcome the high interest credit card.
2.
Copyright © 2017
TIS Inc. All rights reserved. 2 システムの中で活用される機械学習 機械学習を利用するメリット 機械学習と既存プログラムとの差異(ギャップ) ギャップを埋める処理による影響 機械学習の副作用 モデルの利用を通じた依存関係 データを通じた依存関係 機械学習モデルの依存関係の管理方法 開発面からのアプローチ 運用面からのアプローチ メリット・デメリット 実践 目次(1/2)
3.
Copyright © 2017
TIS Inc. All rights reserved. 3 今後の機械学習の活用領域 現在の機械学習の活用領域 機械学習エンジニアの果たす役割 機械学習活用の次のステップへ 目次(2/2)
4.
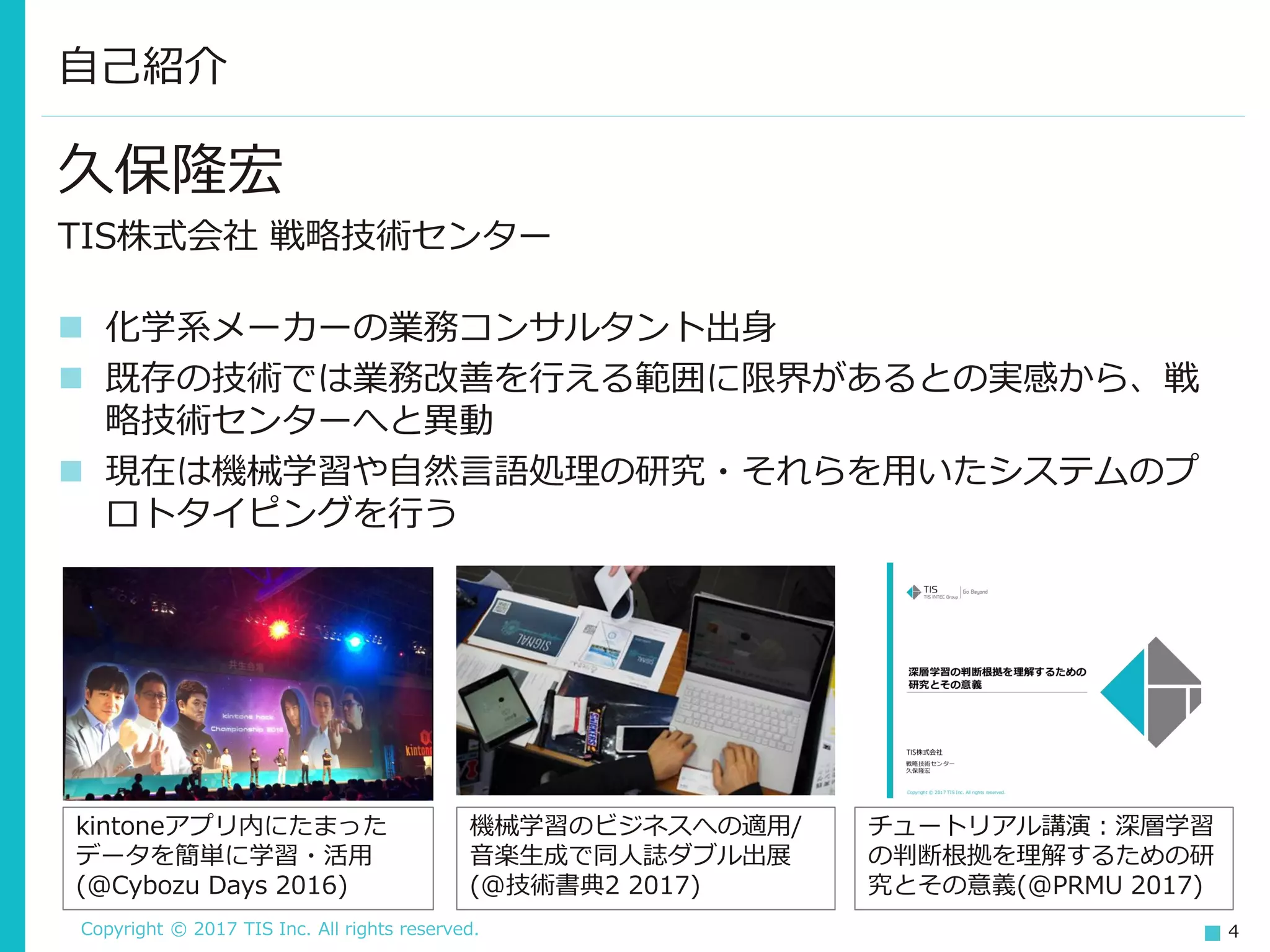
Copyright © 2017
TIS Inc. All rights reserved. 4 久保隆宏 TIS株式会社 戦略技術センター 化学系メーカーの業務コンサルタント出身 既存の技術では業務改善を行える範囲に限界があるとの実感から、戦 略技術センターへと異動 現在は機械学習や自然言語処理の研究・それらを用いたシステムのプ ロトタイピングを行う 自己紹介 kintoneアプリ内にたまった データを簡単に学習・活用 (@Cybozu Days 2016) 機械学習のビジネスへの適用/ 音楽生成で同人誌ダブル出展 (@技術書典2 2017) チュートリアル講演:深層学習 の判断根拠を理解するための研 究とその意義(@PRMU 2017)
5.
Copyright © 2017
TIS Inc. All rights reserved. 5 所属するチームのミッション すべての人が、ティータイムに帰れるようにする すべての人が、ティータイム(15:00)に帰れる(茶帰) 社会の実現を目指します。 この実現には、既存の仕事を効率化するのでなく、 根本的に「仕事の仕方」を変える必要があります。 しかし、慣れた仕事の仕方というのは簡単には変わ りません。だからこそ、実際に「体験」をし、効果 を「実感」してもらうことが重要になります。 そのため、私たちは先進的技術を用い、仕事の仕方 が変わる体験を提供していきます。 (1/3)
6.
Copyright © 2017
TIS Inc. All rights reserved. 6 観点を指定した自然言語処理 観点単位にまとめることで、情報の欠落を 防ぐと共に図表化を行いやすくする。 モデルにお任せで「こんなん出ました」で なく、利用者が出力をコントロールする。 ex: 観点要約 ペンギンのサイズは小さくて、手触りは冷たい。 「サイズ」は「小さく」 「手触り」は「冷たい」 サイズ 手触り ペンギン 小さい 冷たい ライオン 大きい 温かい ウサギ 中くらい 温かい 業務要件により観点は異なる。そして、観点の学習データは少ない。 ⇒自然言語処理における転移学習に注力し、「少ないデータでカスタマ イズ可能な分類/生成器の作成」を目指している。 (2/3)
7.
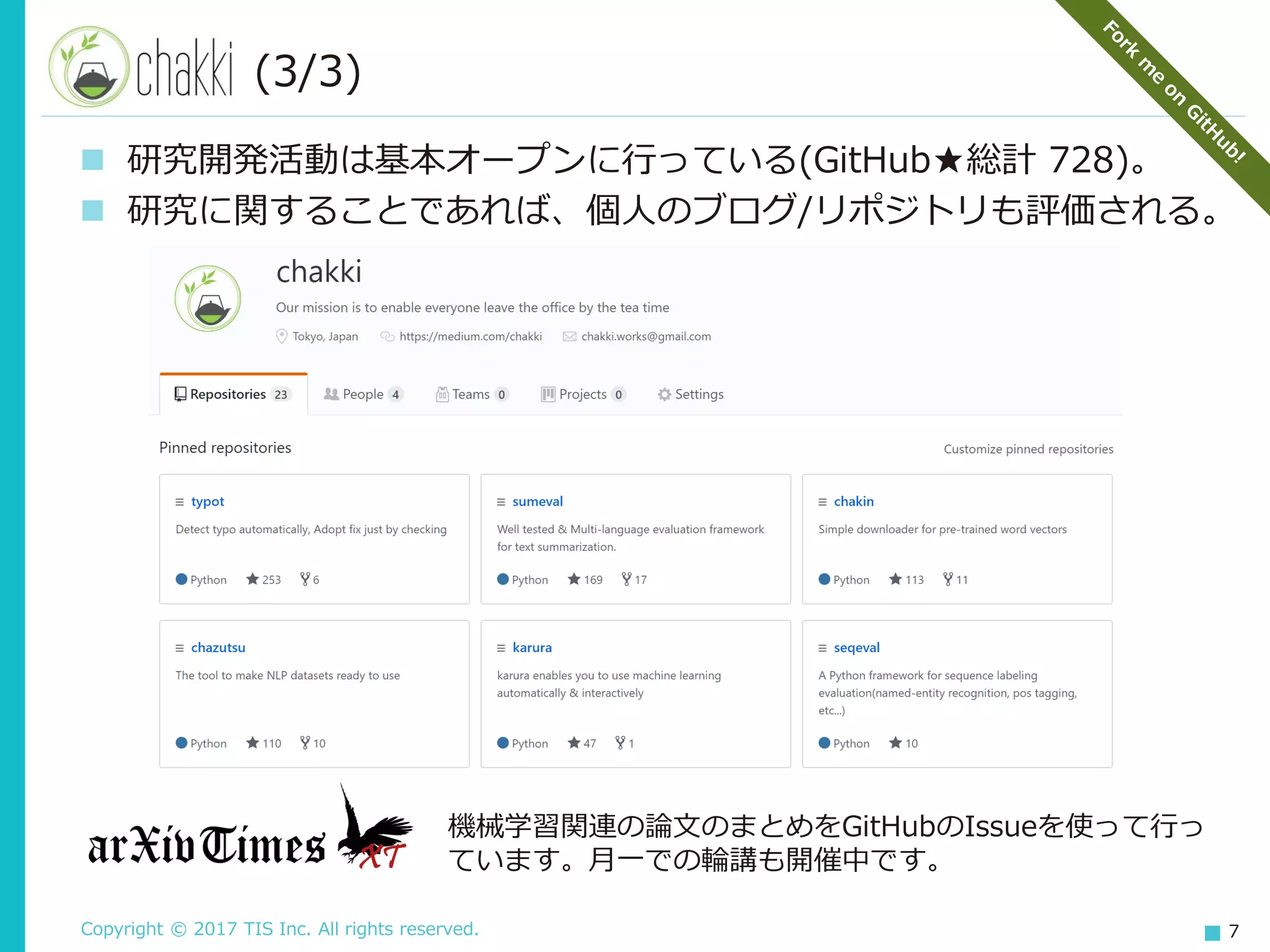
Copyright © 2017
TIS Inc. All rights reserved. 7 (3/3) 研究開発活動は基本オープンに行っている(GitHub★総計 728)。 研究に関することであれば、個人のブログ/リポジトリも評価される。 機械学習関連の論文のまとめをGitHubのIssueを使って行っ ています。月一での輪講も開催中です。
8.
システムの中で活用される機械学習
9.
Copyright © 2017
TIS Inc. All rights reserved. 9 機械学習という技術は、研究面だけでなくソフトウェア面でも大きな発展 を遂げている。 機械学習を利用するメリット(1/2) 各種機械学習関連のライブラリで実装されたコードは、論文の公開と同時 にアクセス可能になることも多い。また、データ分析のコンペティション が開かれるKaggleでは、Kernelという形で様々な参加者のアプローチが 公開されている(ブログでのインタビューもある)。 これにより、システムへの組み込みが容易になっている。
10.
Copyright © 2017
TIS Inc. All rights reserved. 10 機械学習を組み込むことで、認識機能を利用したアプリケーションが簡単 に作れるようになった。 機械学習を利用するメリット(2/2) ビクトリア州で約一億円かけて作っ た盗難車両の検知システムを、たっ た57行のコードで実装した例。 from How I replicated an $86 million project in 57 lines of code 名刺の画像から氏名や会社名を抽出 する、簡単名刺管理システムを自前 で作る。 from Vision APIとNatural Language APIを組 み合わせて名刺から情報抽出する
11.
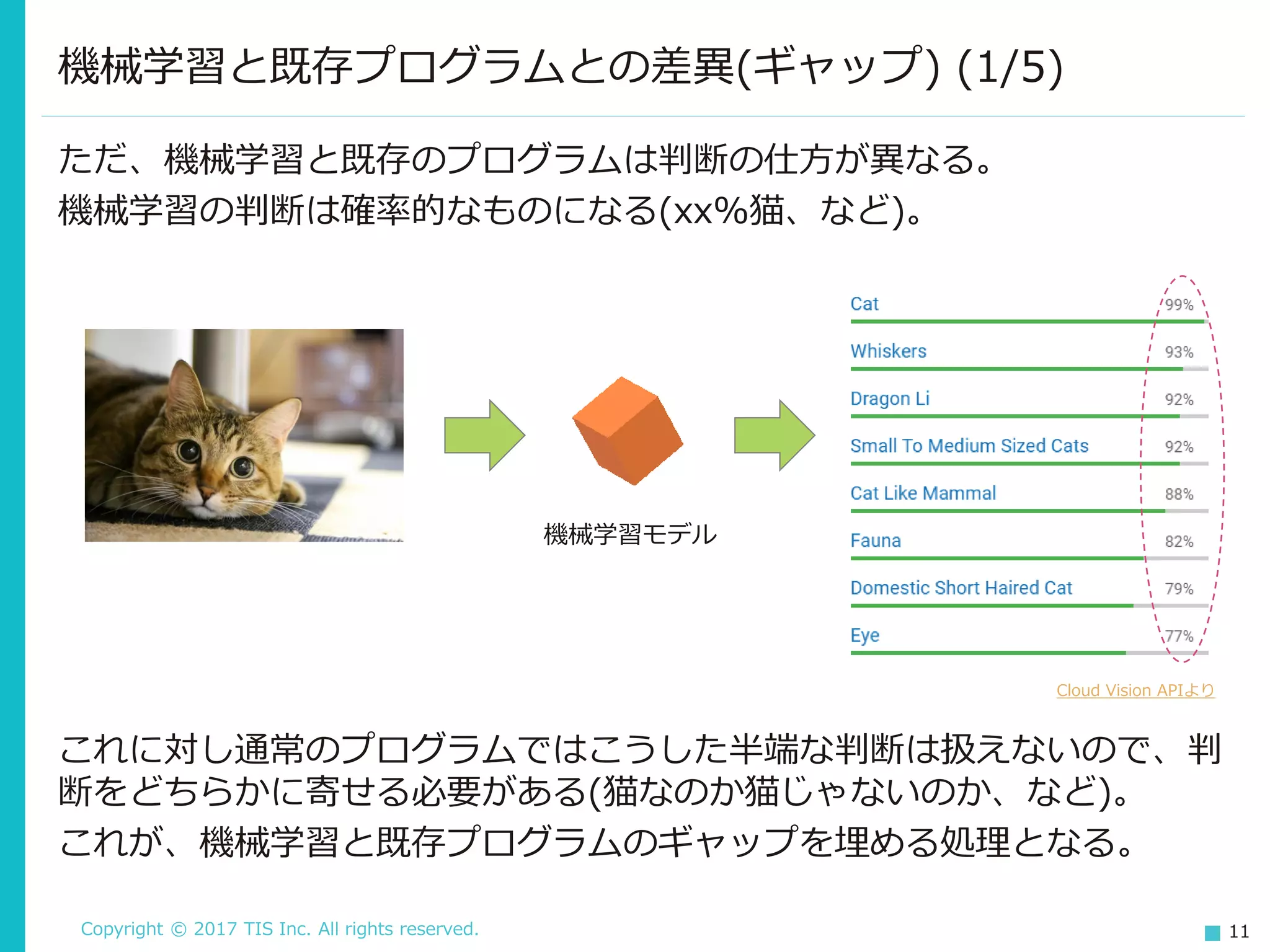
Copyright © 2017
TIS Inc. All rights reserved. 11 ただ、機械学習と既存のプログラムは判断の仕方が異なる。 機械学習の判断は確率的なものになる(xx%猫、など)。 機械学習と既存プログラムとの差異(ギャップ) (1/5) 機械学習モデル Cloud Vision APIより これに対し通常のプログラムではこうした半端な判断は扱えないので、判 断をどちらかに寄せる必要がある(猫なのか猫じゃないのか、など)。 これが、機械学習と既存プログラムのギャップを埋める処理となる。
12.
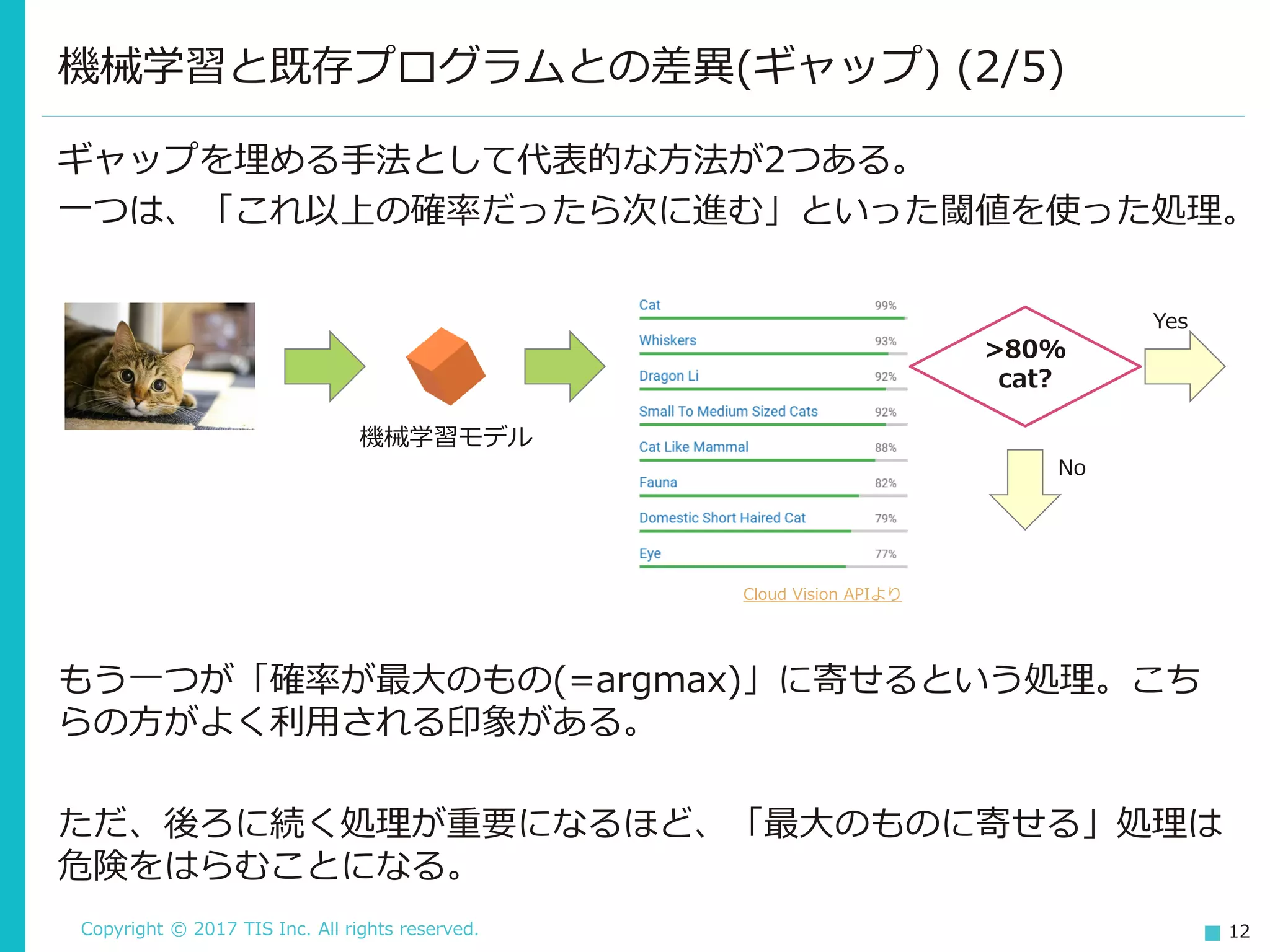
Copyright © 2017
TIS Inc. All rights reserved. 12 ギャップを埋める手法として代表的な方法が2つある。 一つは、「これ以上の確率だったら次に進む」といった閾値を使った処理。 機械学習と既存プログラムとの差異(ギャップ) (2/5) 機械学習モデル Cloud Vision APIより もう一つが「確率が最大のもの(=argmax)」に寄せるという処理。こち らの方がよく利用される印象がある。 ただ、後ろに続く処理が重要になるほど、「最大のものに寄せる」処理は 危険をはらむことになる。 >80% cat? Yes No
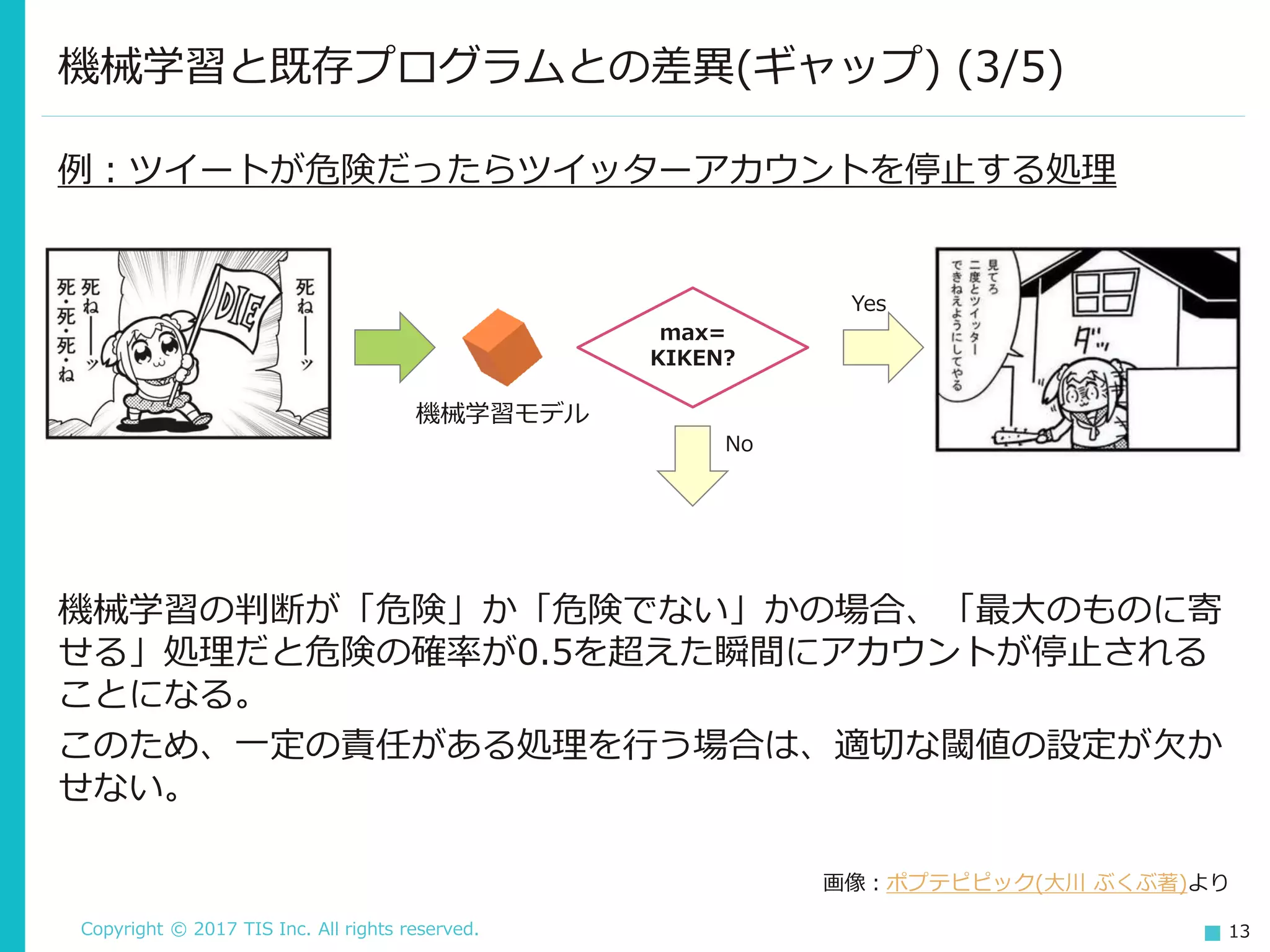
13.
Copyright © 2017
TIS Inc. All rights reserved. 13 機械学習と既存プログラムとの差異(ギャップ) (3/5) Yes No 画像:ポプテピピック(大川 ぶくぶ著)より max= KIKEN? 機械学習モデル 例:ツイートが危険だったらツイッターアカウントを停止する処理 機械学習の判断が「危険」か「危険でない」かの場合、「最大のものに寄 せる」処理だと危険の確率が0.5を超えた瞬間にアカウントが停止される ことになる。 このため、一定の責任がある処理を行う場合は、適切な閾値の設定が欠か せない。
14.
Copyright © 2017
TIS Inc. All rights reserved. 14 適切な閾値の設定には、単に精度上の指標だけでなく、ビジネス上の要件 もかかわってくる。 機械学習と既存プログラムとの差異(ギャップ) (4/5) 判断をミスるとユーザーが 会社に乗り込んできたりす る場合など なるべく判断を誤らないよ うにしたい=閾値は高めに設 定する。 画像:ポプテピピック(大川 ぶくぶ著)より ちょっとでも(パクリの)可能 性があればなるべく補足し て制裁を加えたい場合など 多少ノイズがあっても可能 性のあるものは捕捉したい= 閾値は低めに設定する。
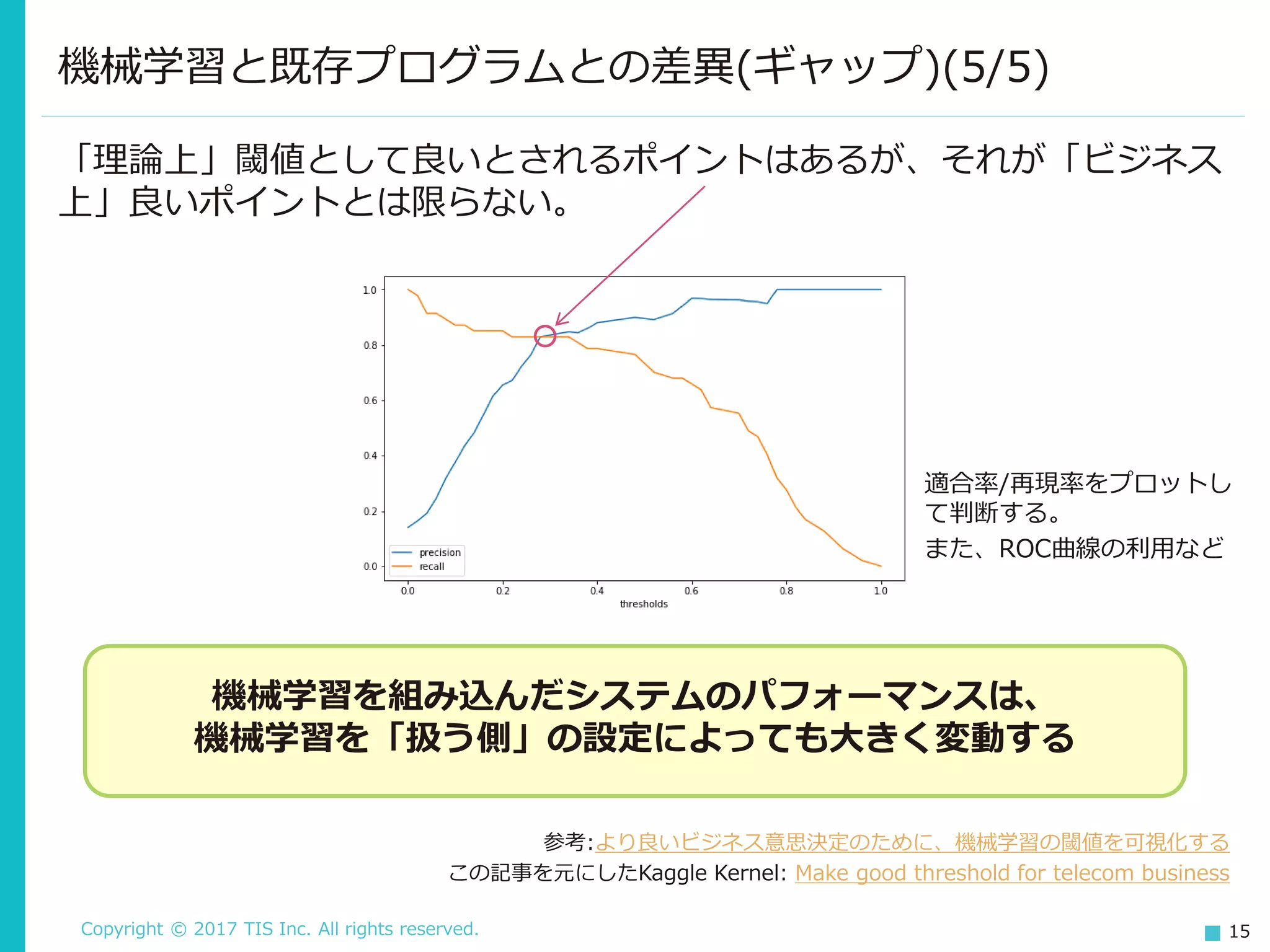
15.
Copyright © 2017
TIS Inc. All rights reserved. 15 「理論上」閾値として良いとされるポイントはあるが、それが「ビジネス 上」良いポイントとは限らない。 機械学習と既存プログラムとの差異(ギャップ)(5/5) 参考:より良いビジネス意思決定のために、機械学習の閾値を可視化する この記事を元にしたKaggle Kernel: Make good threshold for telecom business 機械学習を組み込んだシステムのパフォーマンスは、 機械学習を「扱う側」の設定によっても大きく変動する 適合率/再現率をプロットし て判断する。 また、ROC曲線の利用など
16.
Copyright © 2017
TIS Inc. All rights reserved. 16 ギャップを埋める処理による影響(1/3) つまり・・・
17.
Copyright © 2017
TIS Inc. All rights reserved. 17 ギャップを埋める処理による影響(2/3) if model.predict(user).prob[“kiken”] > 0.81394: user.account.stop() よく考えられた閾値 これが機械学習モデルの力を引き出すコードだ! 画像:MMR:マガジンミステリー調査班より ※(さすがに)閾値については、固定値ではなくバリデーションデータを使って自動調整する 手法がある。 Detecting Adversarial Advertisements in the Wild
18.
Copyright © 2017
TIS Inc. All rights reserved. 18 機械学習モデルを既存システムに組み込む場合、「機械学習を利用する側 の設定」もビジネス上のパフォーマンスを最大化するのに重要になる。 これは、機械学習モデルを更新する際は「扱う側」にも連鎖的な更新が必 要なことを意味している。更新をミスると、モデルは更新したけど閾値は そのまま、といったような事態が発生する。 よって、「連鎖範囲」の把握が重要になる。モデルと閾値が1:1の場合は わかりやすいが、依存関係はそれだけなのか? ギャップを埋める処理による影響(3/3)
19.
Copyright © 2017
TIS Inc. All rights reserved. 19 機械学習の副作用
20.
Copyright © 2017
TIS Inc. All rights reserved. 20 機械学習モデルの「連鎖範囲」を把握するには、以下2つの依存関係を把 握する必要がある。 モデルの利用を通じた依存関係 データを通じた依存関係 機械学習がもたらす不可視の依存関係
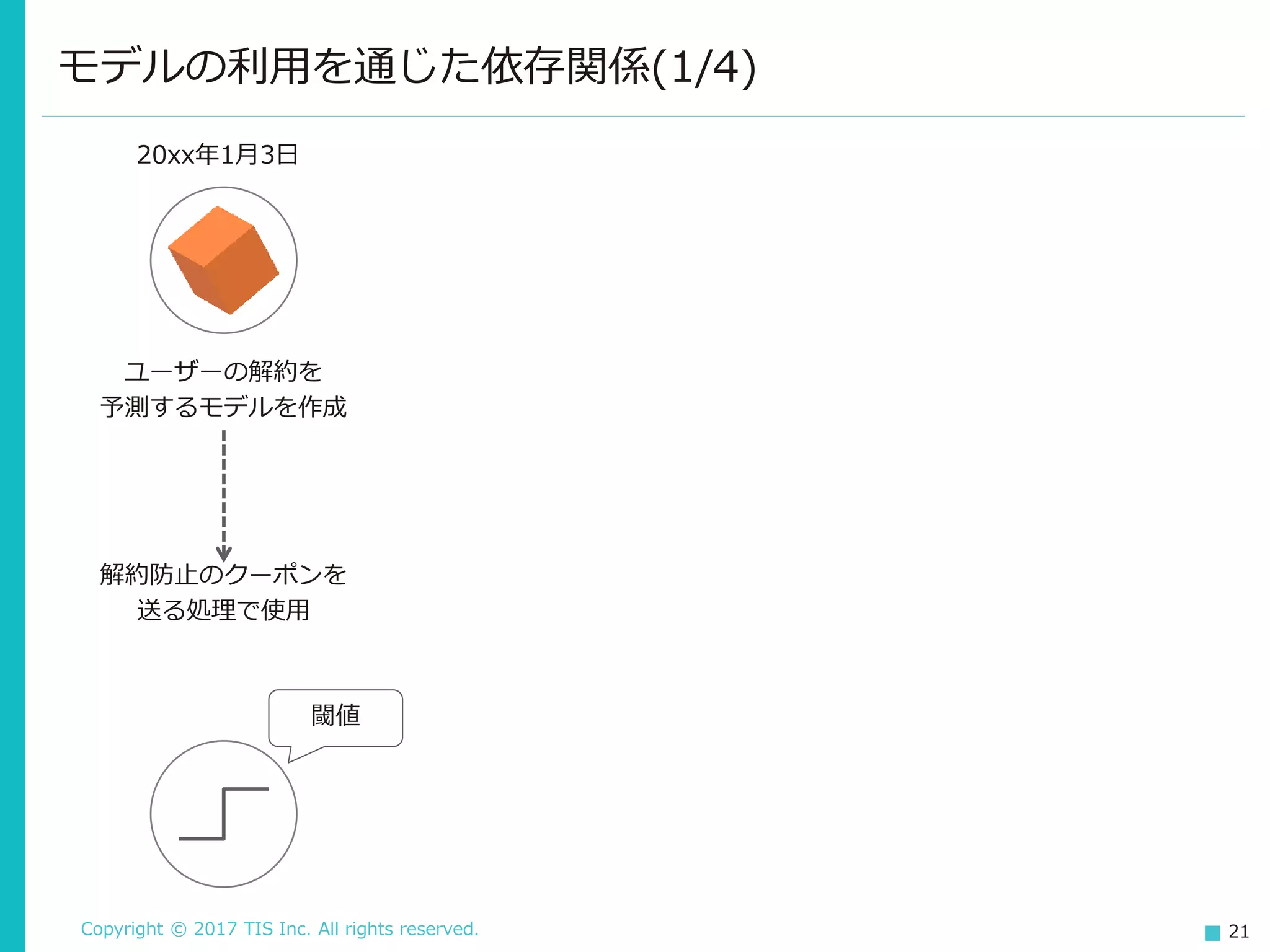
21.
Copyright © 2017
TIS Inc. All rights reserved. 21 モデルの利用を通じた依存関係(1/4) 解約防止のクーポンを 送る処理で使用 20xx年1月3日 ユーザーの解約を 予測するモデルを作成 閾値
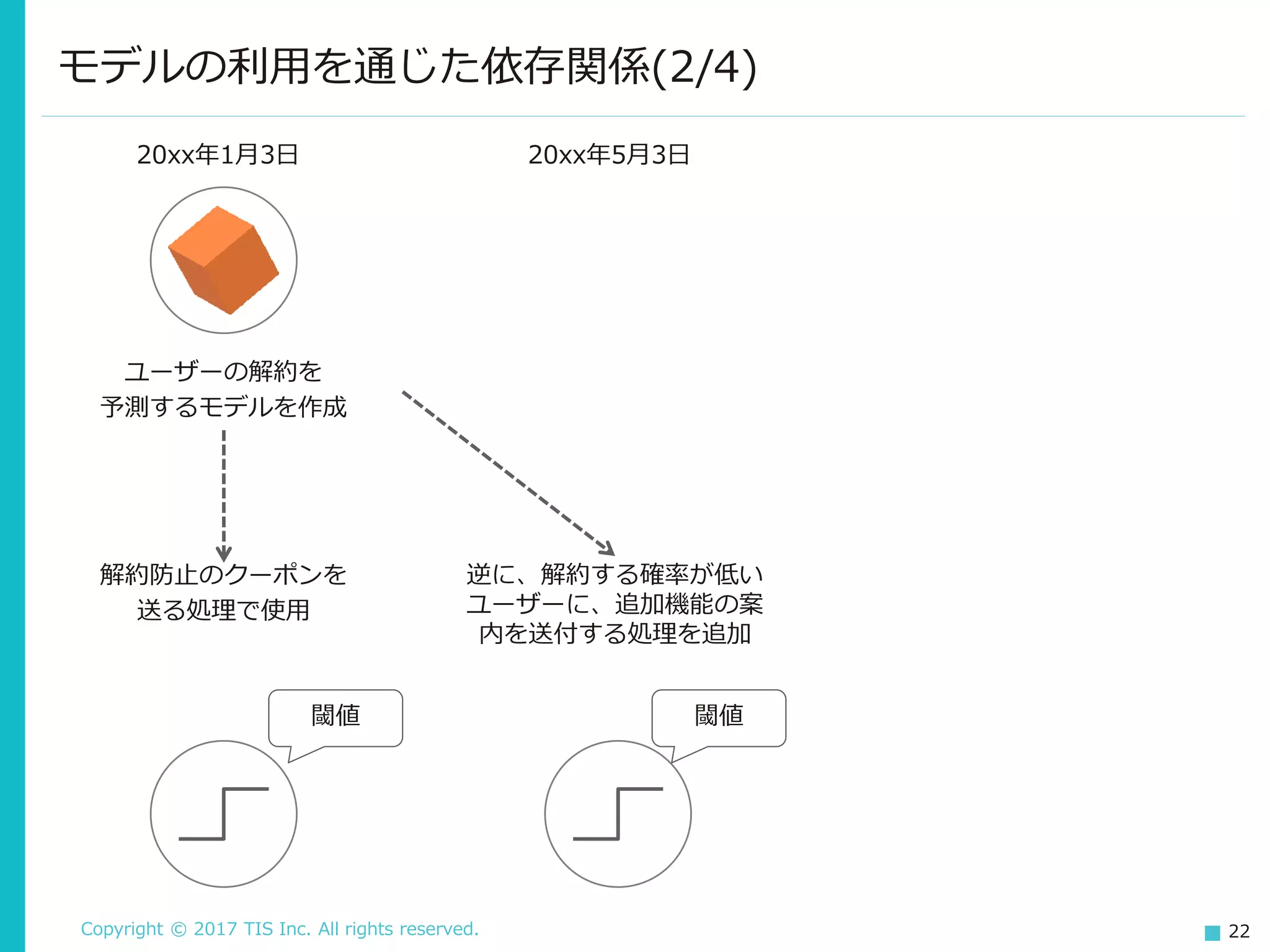
22.
Copyright © 2017
TIS Inc. All rights reserved. 22 モデルの利用を通じた依存関係(2/4) 解約防止のクーポンを 送る処理で使用 逆に、解約する確率が低い ユーザーに、追加機能の案 内を送付する処理を追加 20xx年1月3日 ユーザーの解約を 予測するモデルを作成 20xx年5月3日 閾値 閾値
23.
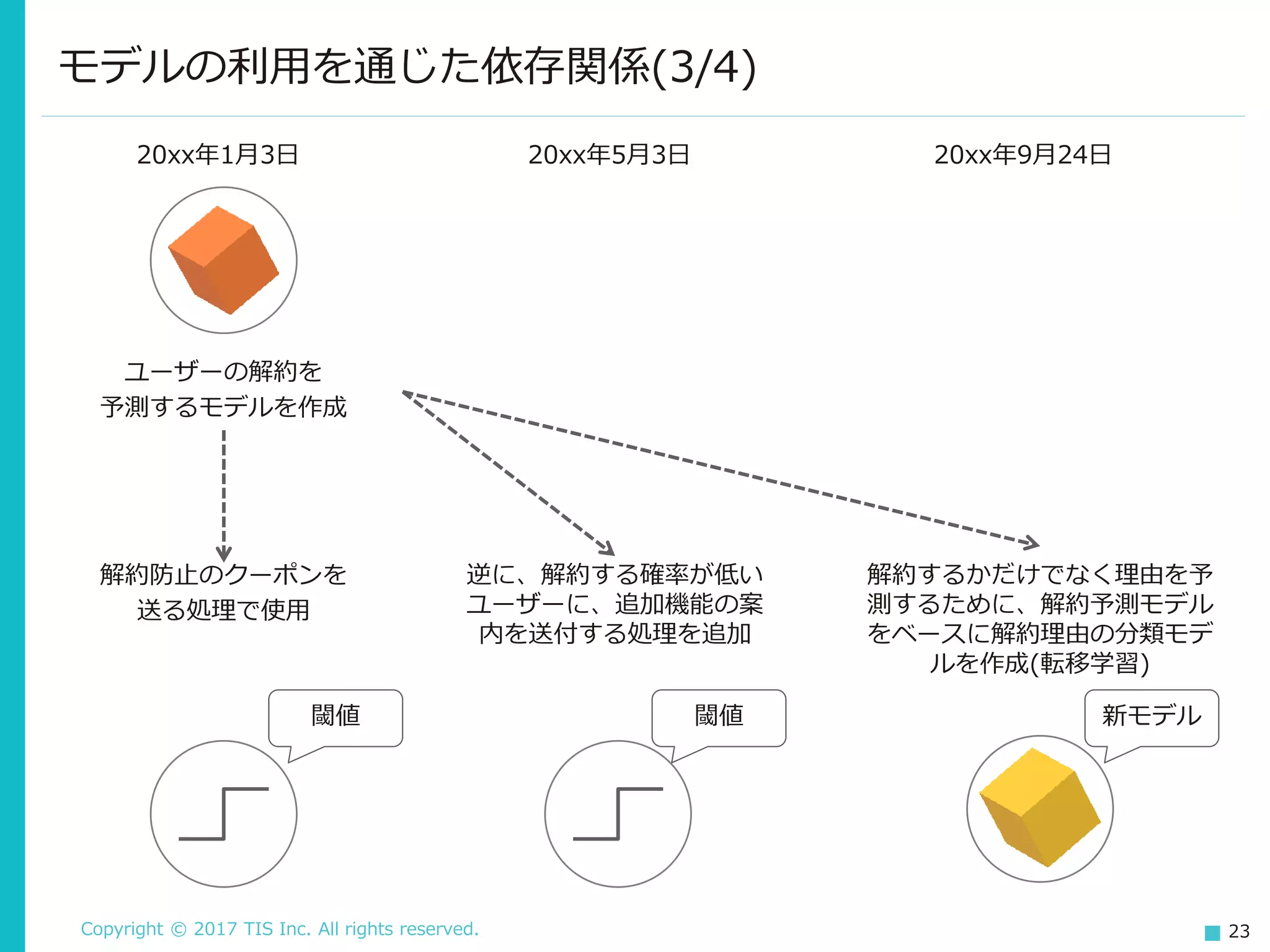
Copyright © 2017
TIS Inc. All rights reserved. 23 モデルの利用を通じた依存関係(3/4) 解約防止のクーポンを 送る処理で使用 逆に、解約する確率が低い ユーザーに、追加機能の案 内を送付する処理を追加 20xx年1月3日 ユーザーの解約を 予測するモデルを作成 20xx年5月3日 解約するかだけでなく理由を予 測するために、解約予測モデル をベースに解約理由の分類モデ ルを作成(転移学習) 20xx年9月24日 閾値 閾値 新モデル
24.
Copyright © 2017
TIS Inc. All rights reserved. 24 作成したモデルが、当初の処理とは異なる場所でも使用される 画像分類のモデルを、猫の判断だけでなく犬の判断にも使用する 作成したモデルをベースに、別のモデルが作成される 経済ニュースの分類を行うモデルを元に、政治ニュースの分類を行 うモデルを作る こうした「モデルの利用」を通じた依存関係を把握しておく必要がある。 モデルの利用を通じた依存関係(4/4) 機械学習モデルの利用が増えるにつれ、更新対象も増えていく
25.
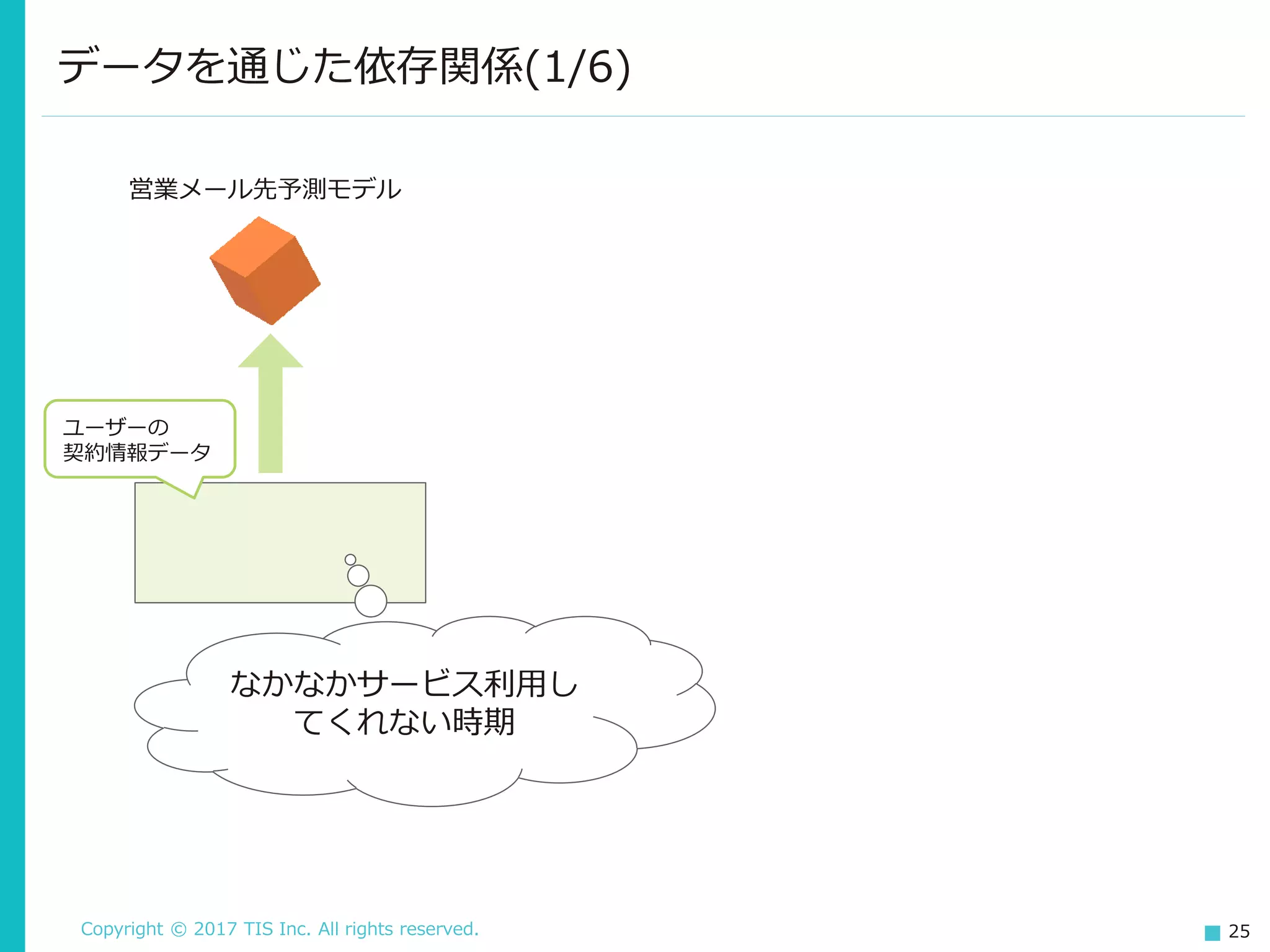
Copyright © 2017
TIS Inc. All rights reserved. 25 データを通じた依存関係(1/6) ユーザーの 契約情報データ 営業メール先予測モデル なかなかサービス利用し てくれない時期
26.
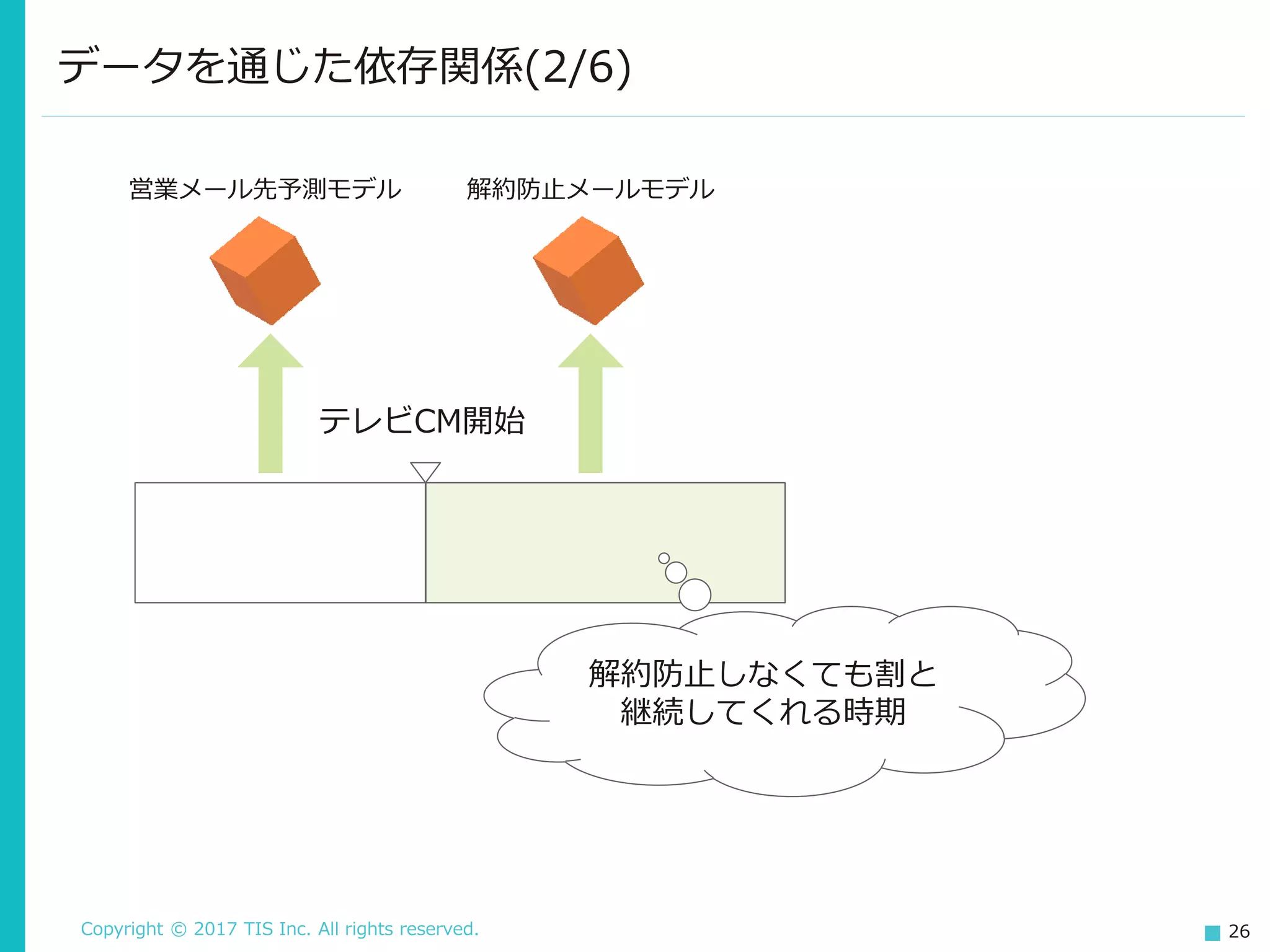
Copyright © 2017
TIS Inc. All rights reserved. 26 データを通じた依存関係(2/6) テレビCM開始 解約防止メールモデル営業メール先予測モデル 解約防止しなくても割と 継続してくれる時期
27.
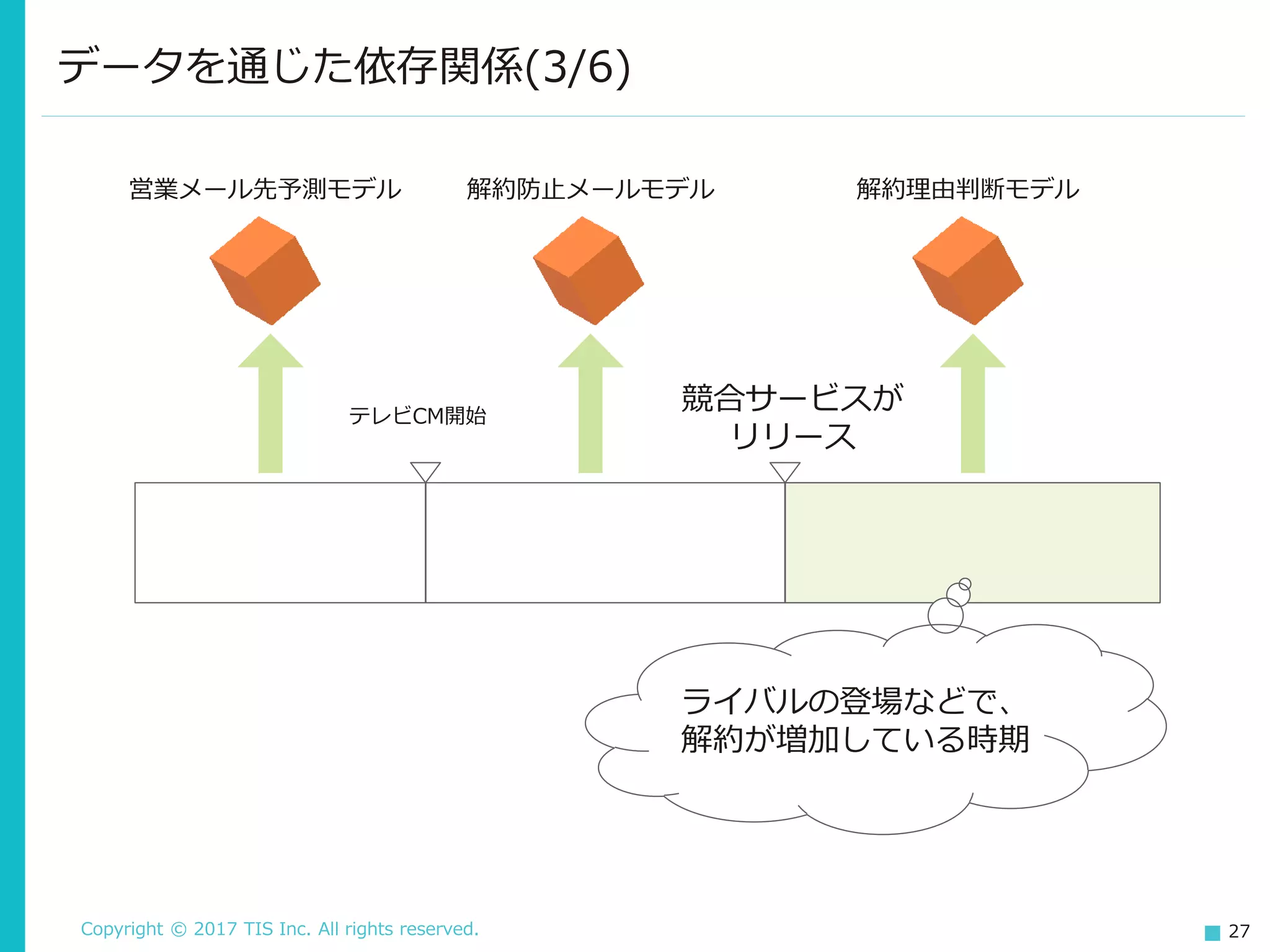
Copyright © 2017
TIS Inc. All rights reserved. 27 データを通じた依存関係(3/6) テレビCM開始 競合サービスが リリース 解約防止メールモデル営業メール先予測モデル 解約理由判断モデル ライバルの登場などで、 解約が増加している時期
28.
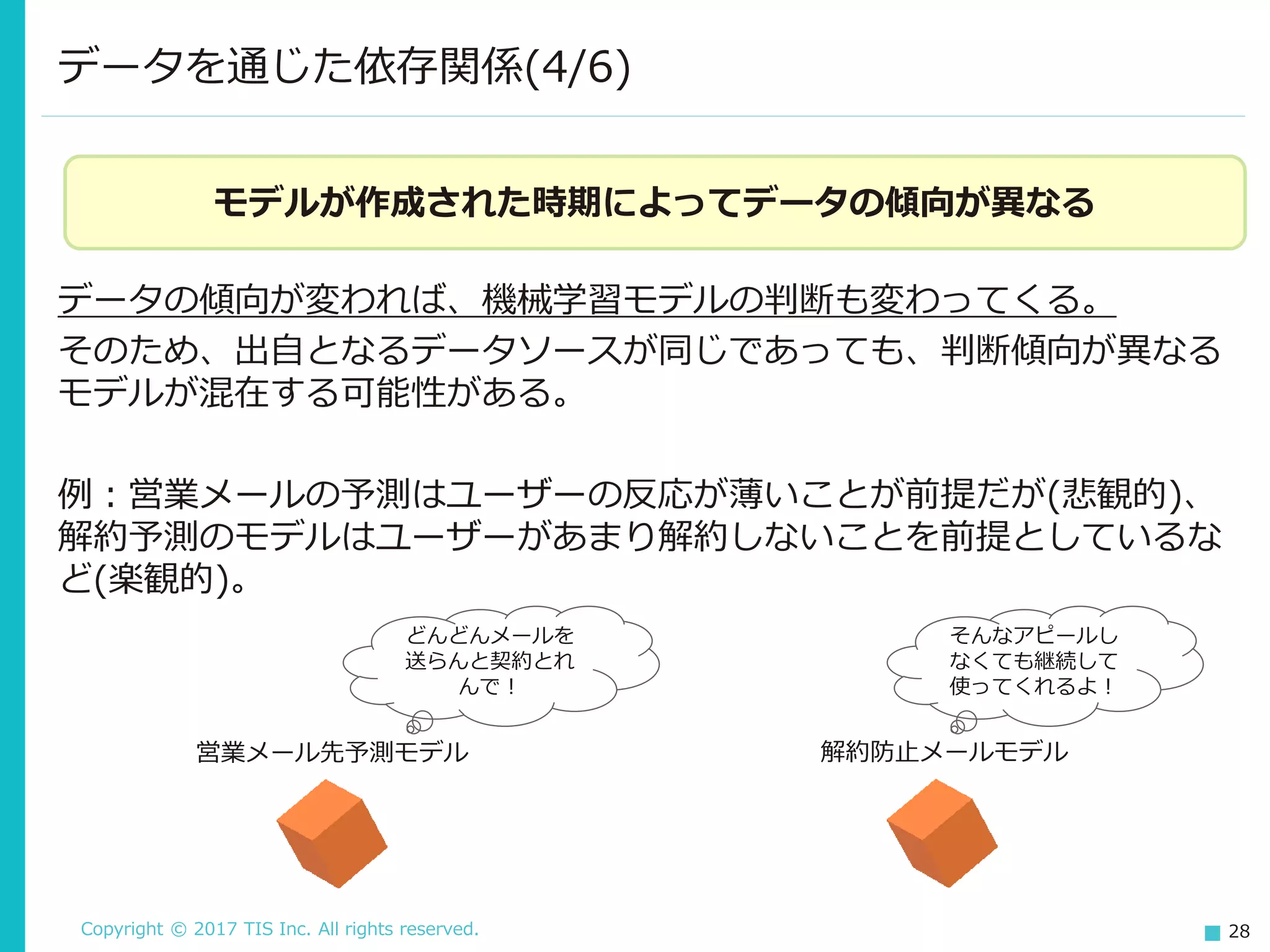
Copyright © 2017
TIS Inc. All rights reserved. 28 データの傾向が変われば、機械学習モデルの判断も変わってくる。 そのため、出自となるデータソースが同じであっても、判断傾向が異なる モデルが混在する可能性がある。 例:営業メールの予測はユーザーの反応が薄いことが前提だが(悲観的)、 解約予測のモデルはユーザーがあまり解約しないことを前提としているな ど(楽観的)。 データを通じた依存関係(4/6) モデルが作成された時期によってデータの傾向が異なる 営業メール先予測モデル 解約防止メールモデル どんどんメールを 送らんと契約とれ んで! そんなアピールし なくても継続して 使ってくれるよ!
29.
Copyright © 2017
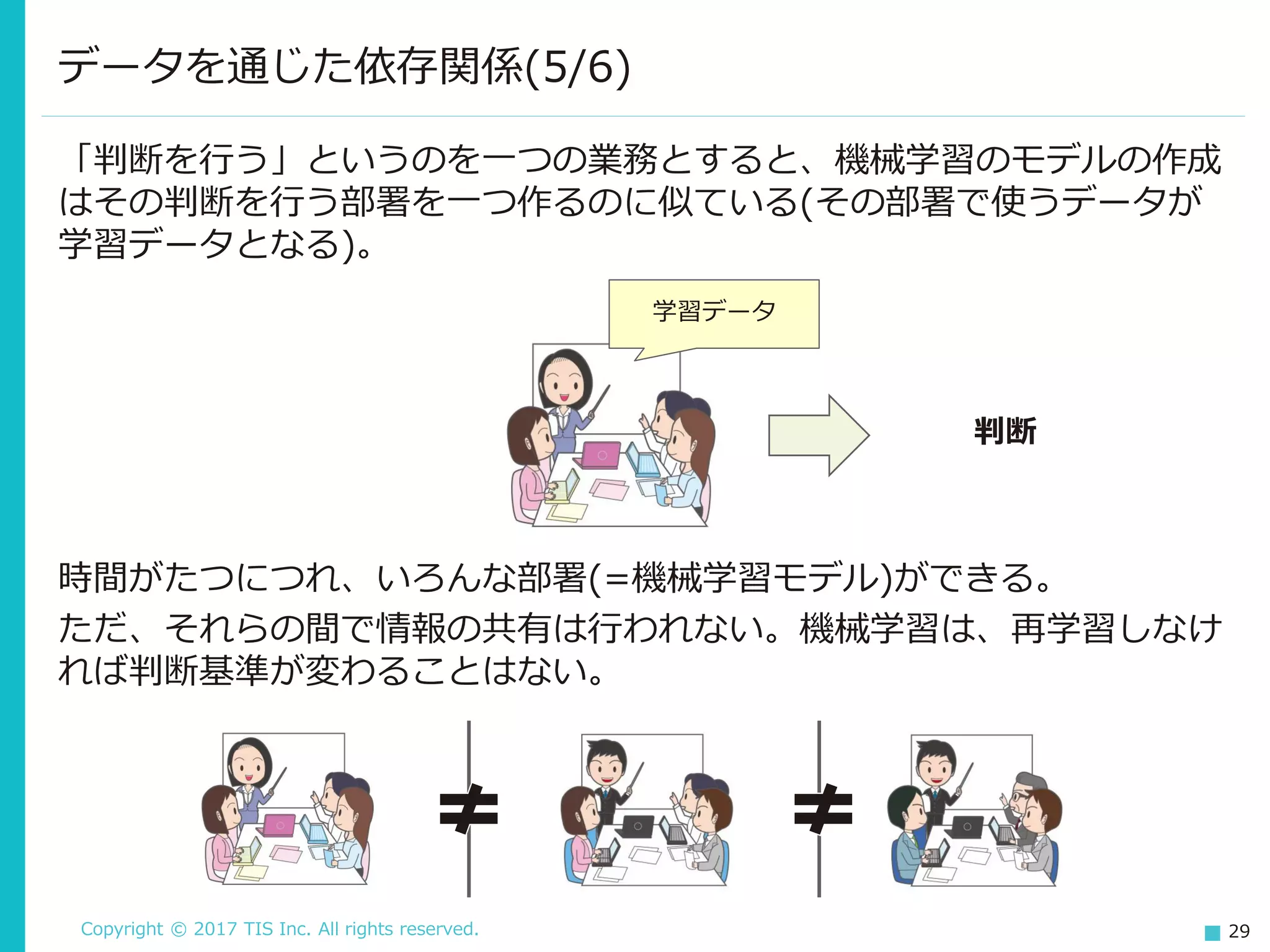
TIS Inc. All rights reserved. 29 「判断を行う」というのを一つの業務とすると、機械学習のモデルの作成 はその判断を行う部署を一つ作るのに似ている(その部署で使うデータが 学習データとなる)。 データを通じた依存関係(5/6) 学習データ 判断 時間がたつにつれ、いろんな部署(=機械学習モデル)ができる。 ただ、それらの間で情報の共有は行われない。機械学習は、再学習しなけ れば判断基準が変わることはない。
30.
Copyright © 2017
TIS Inc. All rights reserved. 30 システム内で判断傾向が割れないようにするためには、同じデータソース から生まれたモデルについては同期をとる必要がある。 つまり、あるモデルを再学習するなら、データソースを同じくする他のモ デルもこれに追随させる。これが、データを通じた依存関係となる。 データを通じた依存関係(6/6)
31.
Copyright © 2017
TIS Inc. All rights reserved. 31 これらの依存関係を、どう把握するか? モデルの利用を通じた依存関係 利用先で閾値が設定されている 学習元のモデルとして使用されている データを通じた依存関係 同じデータソースを出自とするモデル 機械学習がもたらす不可視の依存関係
32.
Copyright © 2017
TIS Inc. All rights reserved. 32 機械学習モデルの依存関係の管理方法
33.
Copyright © 2017
TIS Inc. All rights reserved. 33 依存関係の管理には、開発面と運用面からのアプローチが考えられる。 開発面からのアプローチ コードにおけるモジュール依存関係の文脈で管理する 運用面からのアプローチ 学習プロセスなど機械学習にまつわる処理をログとして管理してお き、そこから依存関係をたどる。 これらは対立する対策ではないので、併用することが可能。 機械学習モデルの依存関係の管理方法
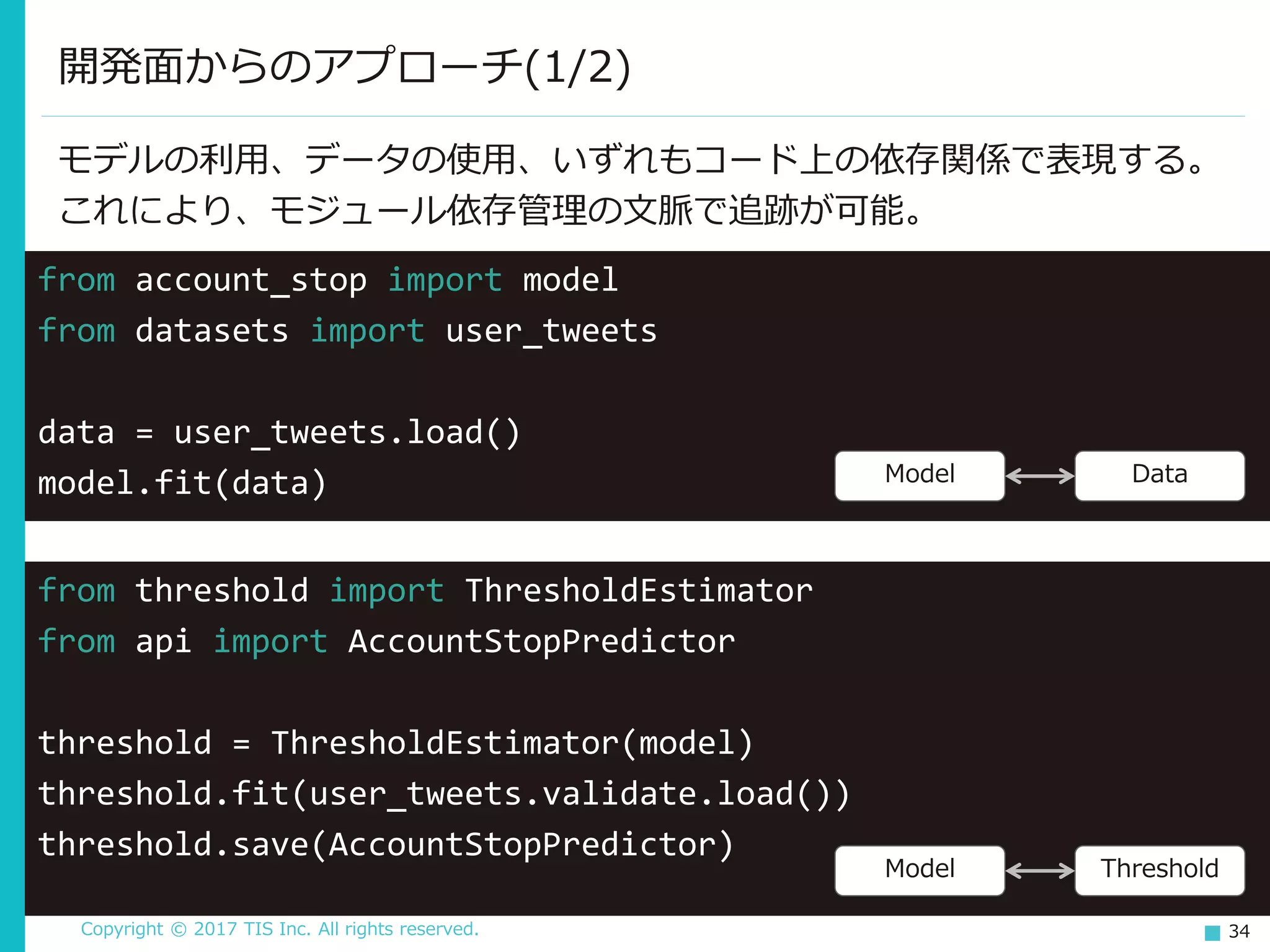
34.
Copyright © 2017
TIS Inc. All rights reserved. 34 モデルの利用、データの使用、いずれもコード上の依存関係で表現する。 これにより、モジュール依存管理の文脈で追跡が可能。 開発面からのアプローチ(1/2) from account_stop import model from datasets import user_tweets data = user_tweets.load() model.fit(data) from threshold import ThresholdEstimator from api import AccountStopPredictor threshold = ThresholdEstimator(model) threshold.fit(user_tweets.validate.load()) threshold.save(AccountStopPredictor) Model Data Model Threshold
35.
Copyright © 2017
TIS Inc. All rights reserved. 35 開発面からのアプローチ(2/2) from account_stop import model from threshold import Threshold class AccountStopPredictor(): def predict(self, user): model = model.load() threshold = Threshold.load(model, self) return threshold(model.predict(user)) api.py (コードはイメージです)
36.
Copyright © 2017
TIS Inc. All rights reserved. 36 運用面からのアプローチ 画面はCloud MLのもの Cloud ML/Amazon Sage Makerと いった機械学習の学習プロセスをサ ポートしてくれるサービスは、学習 の記録がログとして残る。 このログには、学習時指定したパラ メーター(使用したデータ、ハイパー パラメーターなど)を記録できる。こ のログを利用すればデータへの依存 を管理することができる。 ただ、モデル利用の依存関係につい ては難しい。ジョブ管理ツールなど との合わせ技が必要にある。
37.
Copyright © 2017
TIS Inc. All rights reserved. 37 開発面からのアプローチ もう使ってほしくないデータにDeprecated Warningをつける/利用時に 例外を飛ばす、データを利用できるモデルを限定するなど(継承クラスの チェックetc)、コード上で使えるチェック機能を活用できる。ただ、ハイ パーパラメーターなどの記録はできない。 運用面からのアプローチ 機械学習の学習プロセスの管理は、依存関係の把握以外の課題にとっても 必要になる(ハイパーパラメーターを残しておく、モデルのバージョン管 理etc)。つまりどのみち導入が必要になってくるので、その中に含んでし まえば特別なコストなく対応できる。ただ、ログベースなのでそもそもど うあるべきなのかといった管理はできない。 これらは対立する対策ではないので、併用して使用することも可能。 メリット・デメリット
38.
Copyright © 2017
TIS Inc. All rights reserved. 38 やってみた 実践(1/8) icoxfog417/jetbull
39.
Copyright © 2017
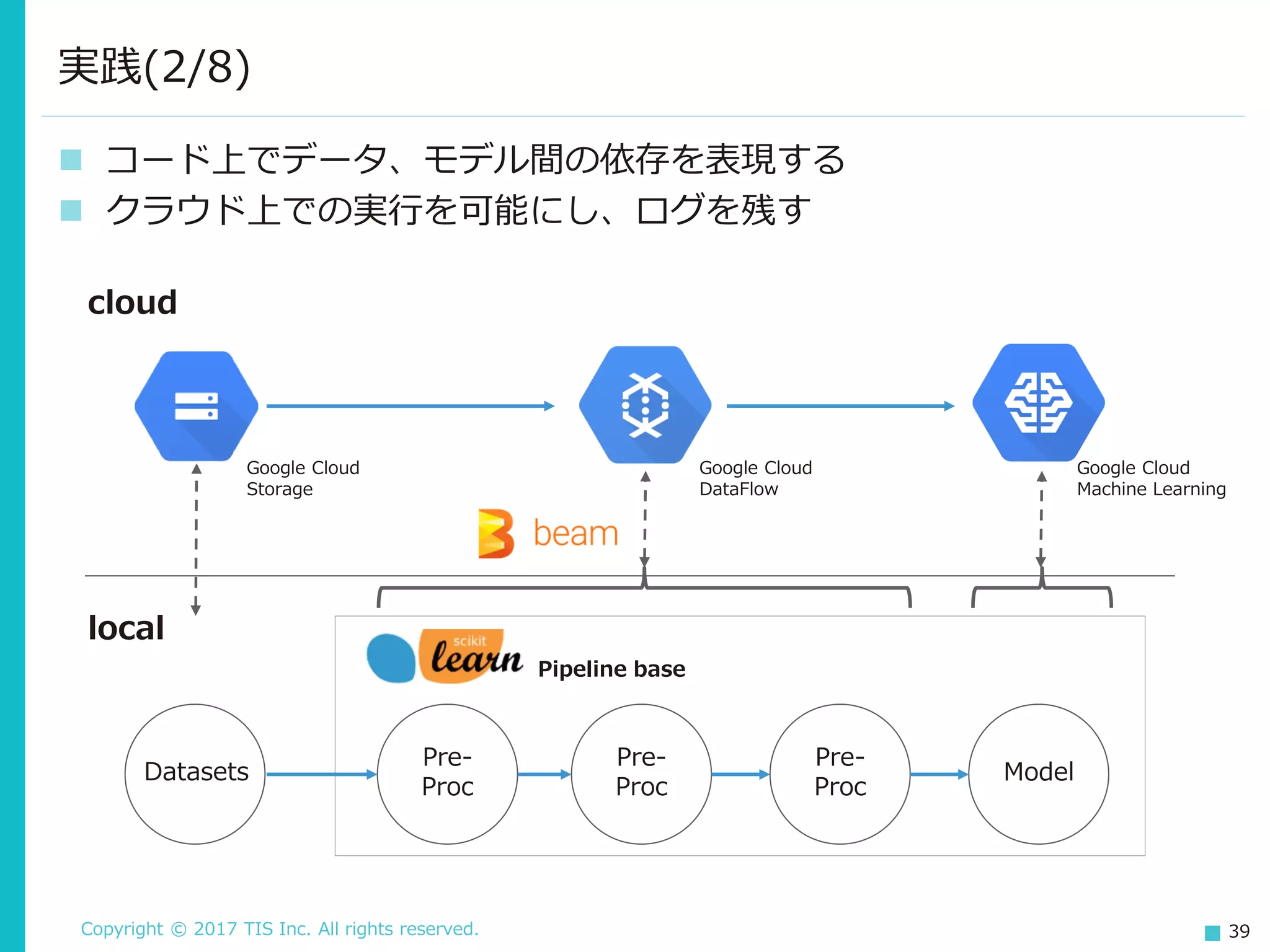
TIS Inc. All rights reserved. 39 コード上でデータ、モデル間の依存を表現する クラウド上での実行を可能にし、ログを残す 実践(2/8) cloud local Model Pre- Proc Pre- Proc Pre- Proc Datasets Pipeline base Google Cloud Storage Google Cloud DataFlow Google Cloud Machine Learning
40.
Copyright © 2017
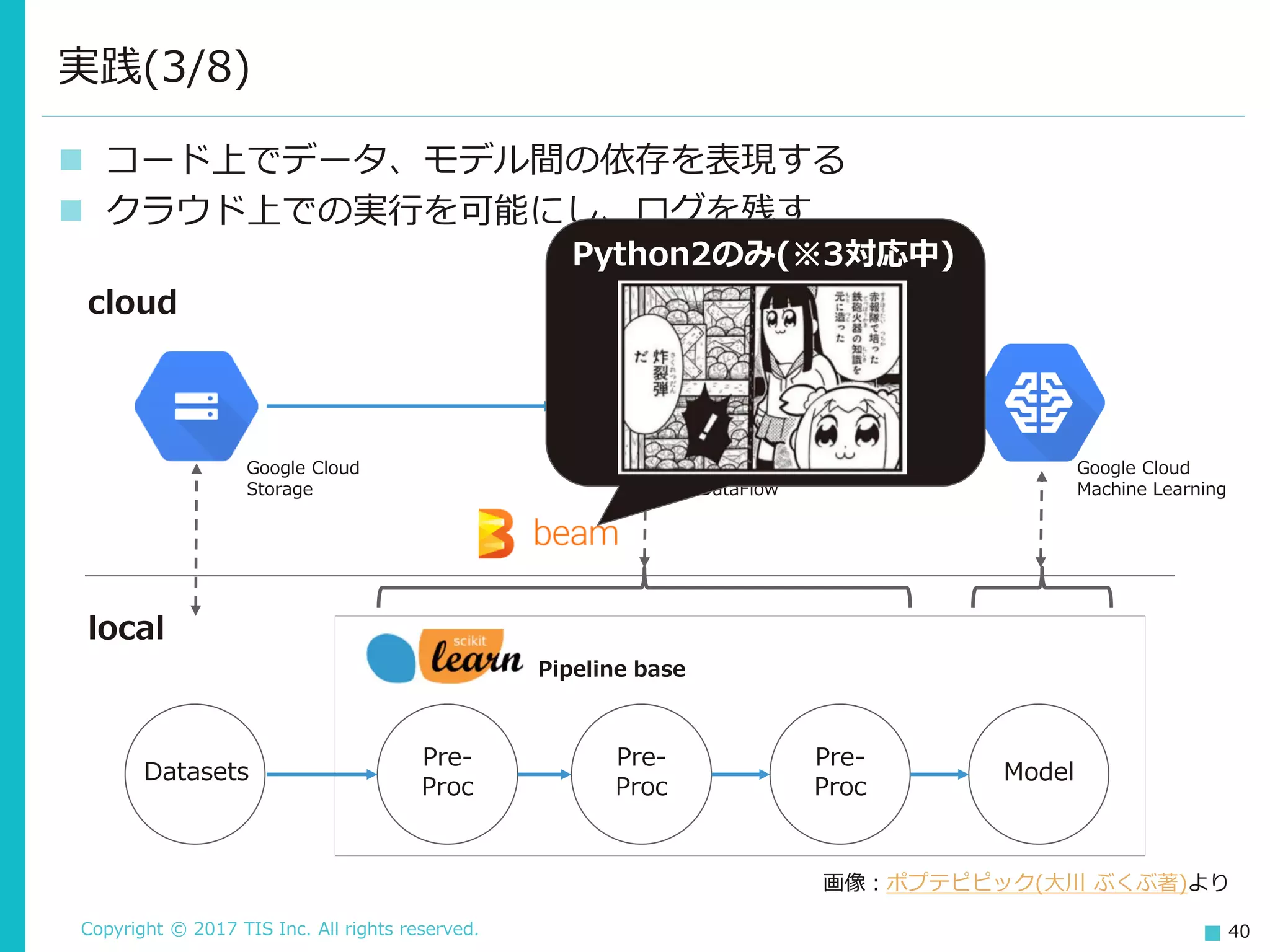
TIS Inc. All rights reserved. 40 コード上でデータ、モデル間の依存を表現する クラウド上での実行を可能にし、ログを残す 実践(3/8) cloud local Model Pre- Proc Pre- Proc Pre- Proc Datasets Pipeline base Google Cloud Storage Google Cloud DataFlow Google Cloud Machine Learning Python2のみ(※3対応中) 画像:ポプテピピック(大川 ぶくぶ著)より
41.
Copyright © 2017
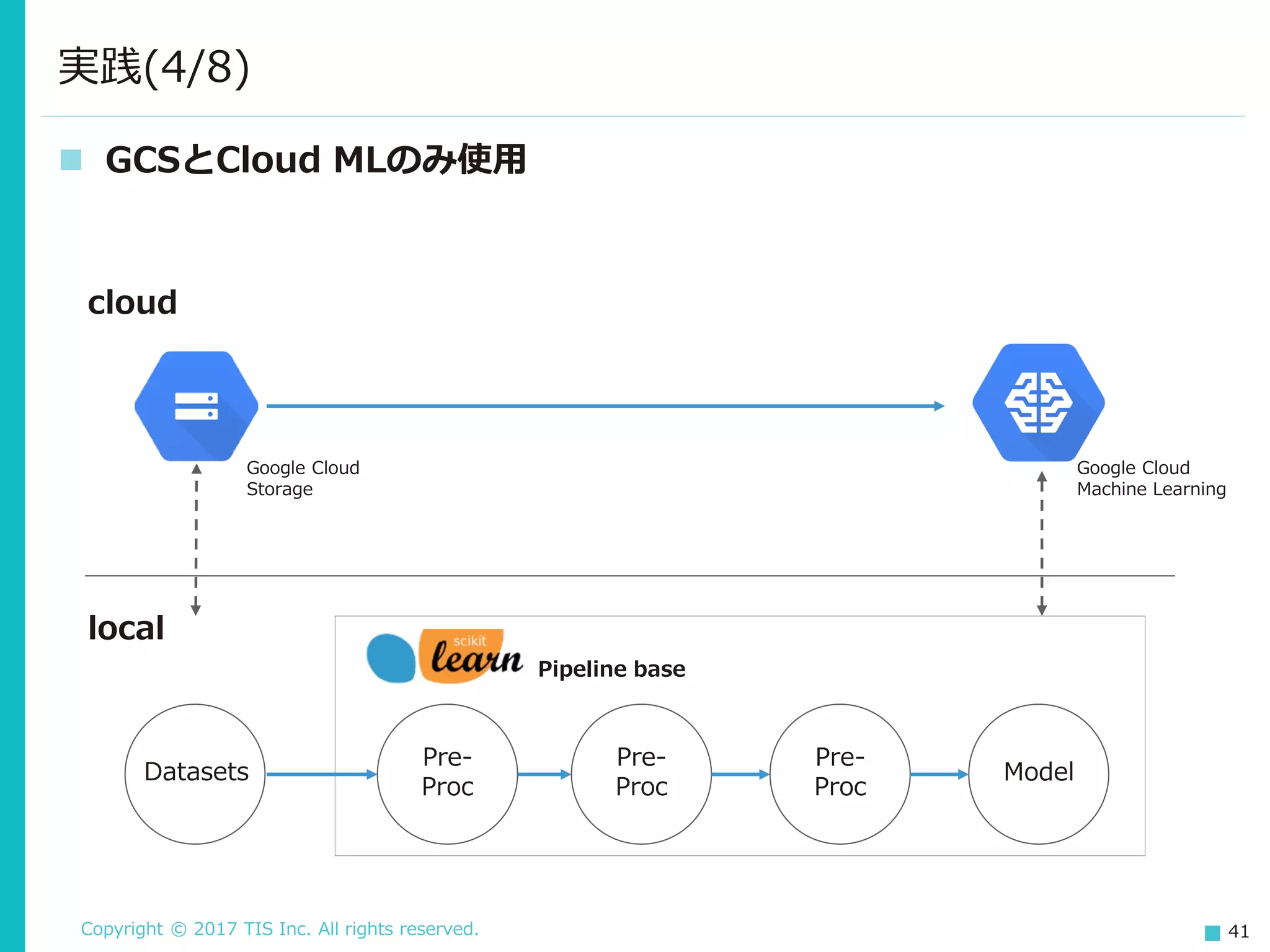
TIS Inc. All rights reserved. 41 GCSとCloud MLのみ使用 実践(4/8) cloud local Model Pre- Proc Pre- Proc Pre- Proc Datasets Pipeline base Google Cloud Storage Google Cloud Machine Learning
42.
Copyright © 2017
TIS Inc. All rights reserved. 42 local 実践(5/8) cloud demo.trainer.task 同一コードがlocal/cloudで動かせる データセットモジュールによるデー タ管理
43.
Copyright © 2017
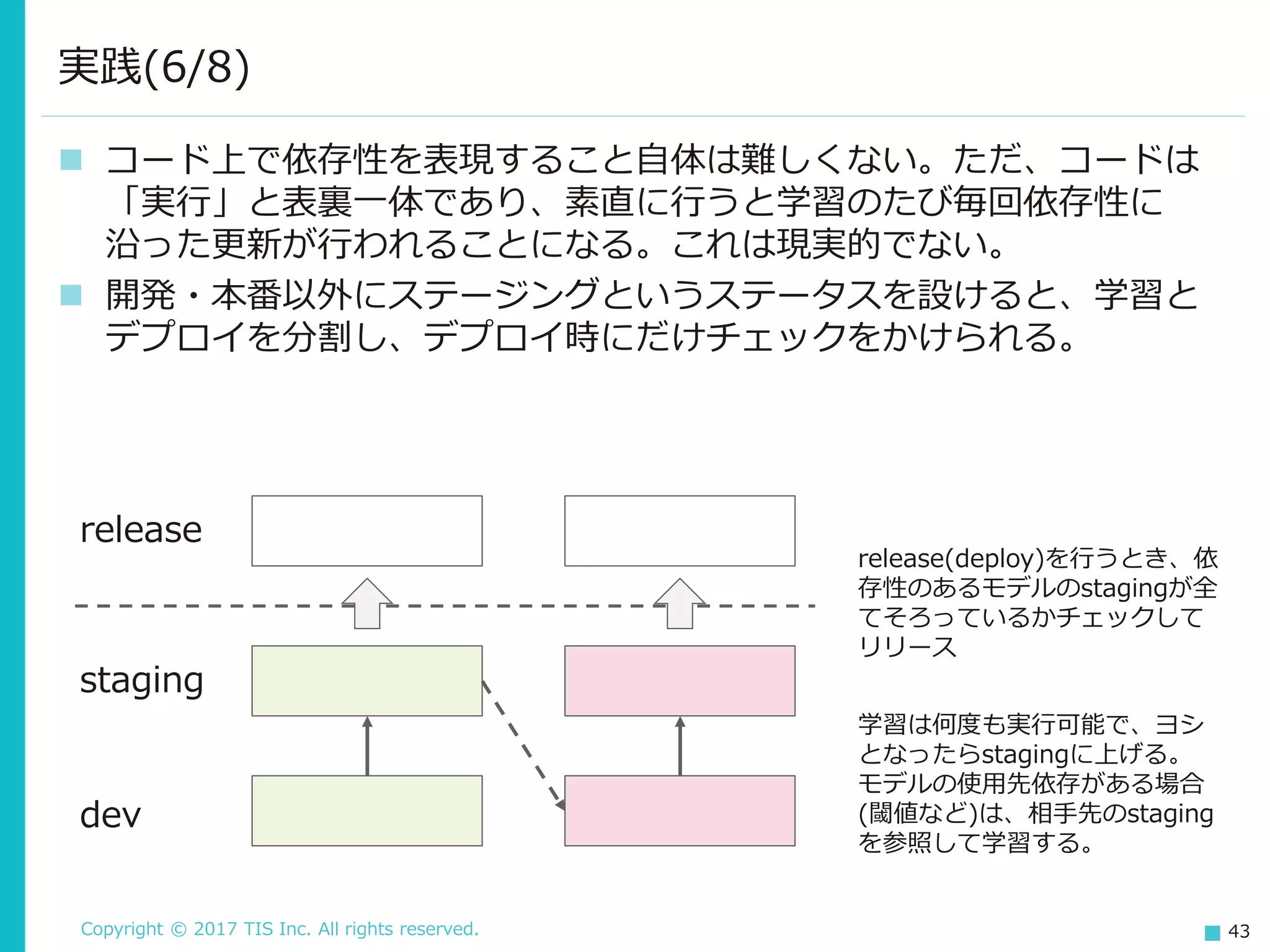
TIS Inc. All rights reserved. 43 コード上で依存性を表現すること自体は難しくない。ただ、コードは 「実行」と表裏一体であり、素直に行うと学習のたび毎回依存性に 沿った更新が行われることになる。これは現実的でない。 開発・本番以外にステージングというステータスを設けると、学習と デプロイを分割し、デプロイ時にだけチェックをかけられる。 実践(6/8) dev staging release release(deploy)を行うとき、依 存性のあるモデルのstagingが全 てそろっているかチェックして リリース 学習は何度も実行可能で、ヨシ となったらstagingに上げる。 モデルの使用先依存がある場合 (閾値など)は、相手先のstaging を参照して学習する。
44.
Copyright © 2017
TIS Inc. All rights reserved. 44 クラウドストレージ(GCS)上のファイルは、簡単に上書きされる。 学習時のソースも、学習モデルも・・・ 適切なネーミングルールで運用する必要がある。 ログは残るが、ログとモデルの結び付けは自前で行う必要がある 「このモデルの学習をしたJOBはどれだっけ?」「このモデルファ イルを作ったソースはどれだっけ?」 JOBIDをモデル名に含めるなどの工夫が必要 実践(7/8) コーディング以外に各種ファイルの運用ルールを決めて、コード上 でチェックするのがかなり重要。
45.
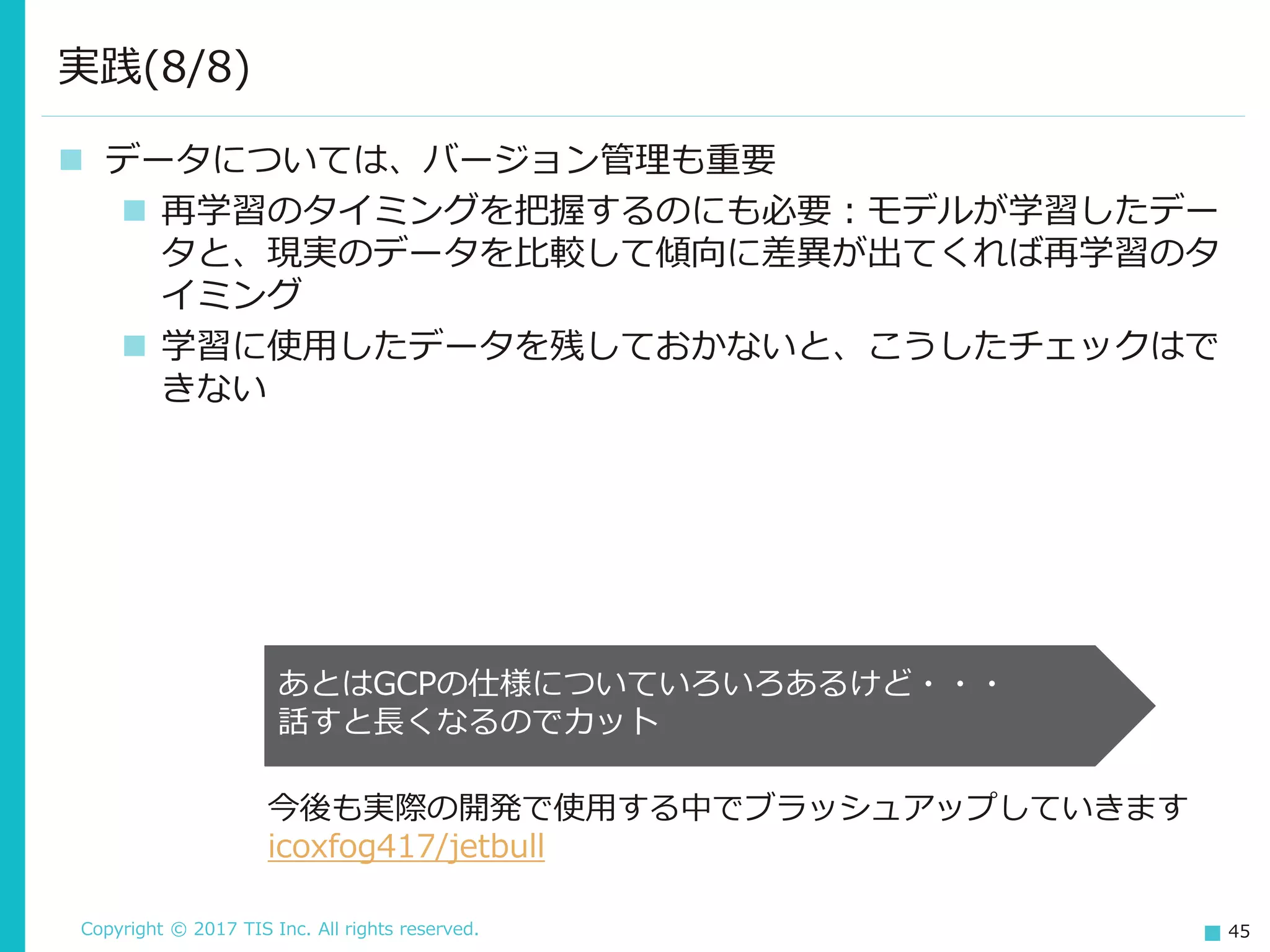
Copyright © 2017
TIS Inc. All rights reserved. 45 データについては、バージョン管理も重要 再学習のタイミングを把握するのにも必要:モデルが学習したデー タと、現実のデータを比較して傾向に差異が出てくれば再学習のタ イミング 学習に使用したデータを残しておかないと、こうしたチェックはで きない 実践(8/8) あとはGCPの仕様についていろいろあるけど・・・ 話すと長くなるのでカット 今後も実際の開発で使用する中でブラッシュアップしていきます icoxfog417/jetbull
46.
Copyright © 2017
TIS Inc. All rights reserved. 46 今後の機械学習の活用領域
47.
Copyright © 2017
TIS Inc. All rights reserved. 47 本日のTL;DR 機械学習の活用では、予測を行うAPIだけでなく、その予測を扱う側の 設定(閾値)も重要。そのため使用先の把握が必要。 データは生き物なので時々で傾向は異なる。そのため、機械学習モデ ルの作成時期によって判断傾向が割れることがある。判断の同期をと るには、データソースを同じくするモデルの把握が必要。 こうした依存性の管理には、開発・運用の両面からアプローチできる。 併用も可能。 こうしたケースは再学習が割と頻繁にあるケースを想定している。 ある判断だけに特化したモデル(閾値との関係が常に1:1)、またデータの 傾向がほぼ変わらないような場合は、こうした問題は顕在化しない。 現在の機械学習の活用領域(1/6)
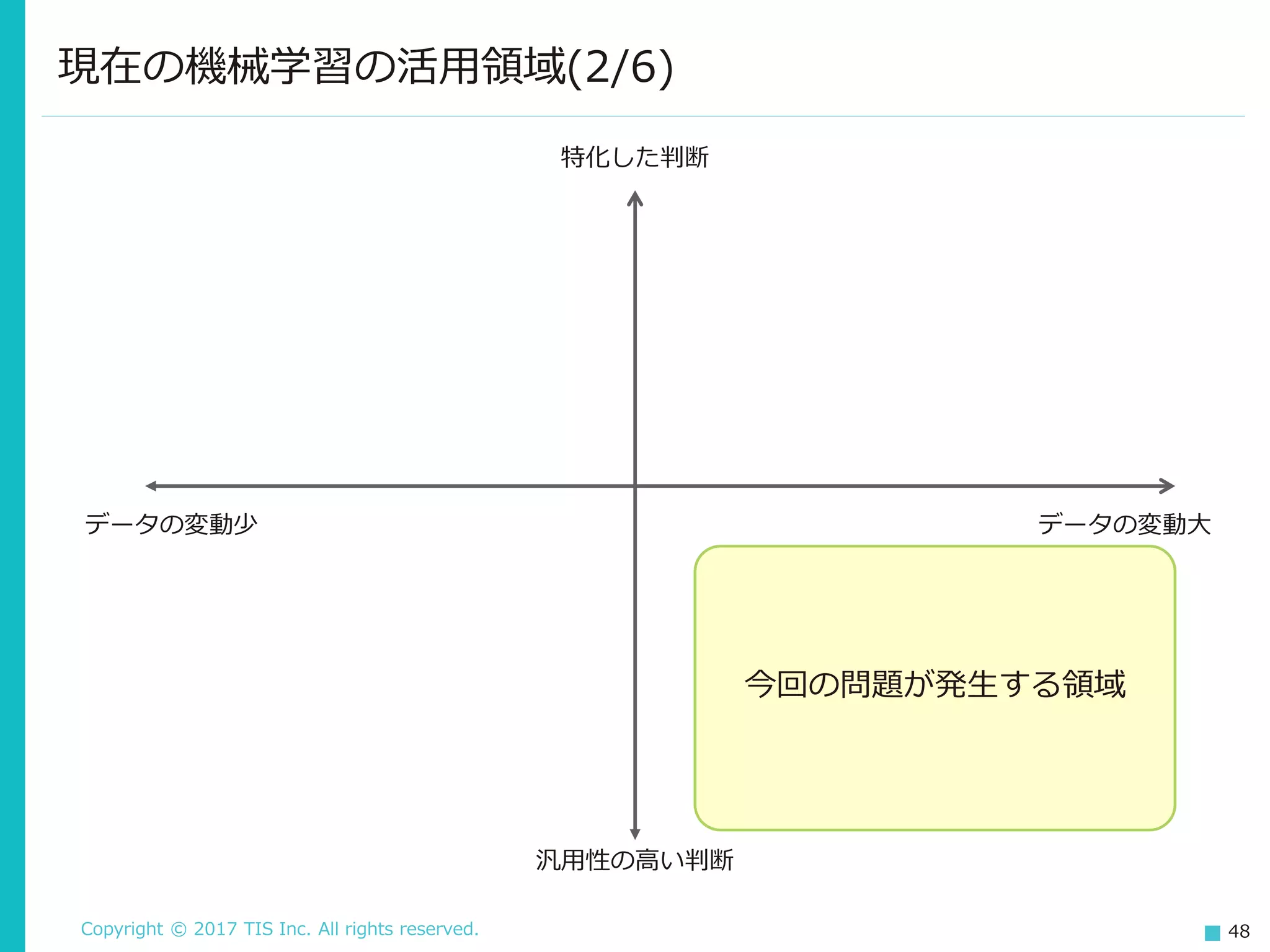
48.
Copyright © 2017
TIS Inc. All rights reserved. 48 現在の機械学習の活用領域(2/6) データの変動少 データの変動大 特化した判断 汎用性の高い判断 今回の問題が発生する領域
49.
Copyright © 2017
TIS Inc. All rights reserved. 49 現在の機械学習の活用領域(3/6) 特化した判断 汎用性の高い判断 データの変動少 データの変動大 今回の問題が発生する領域 現在機械学習が 活躍している領域
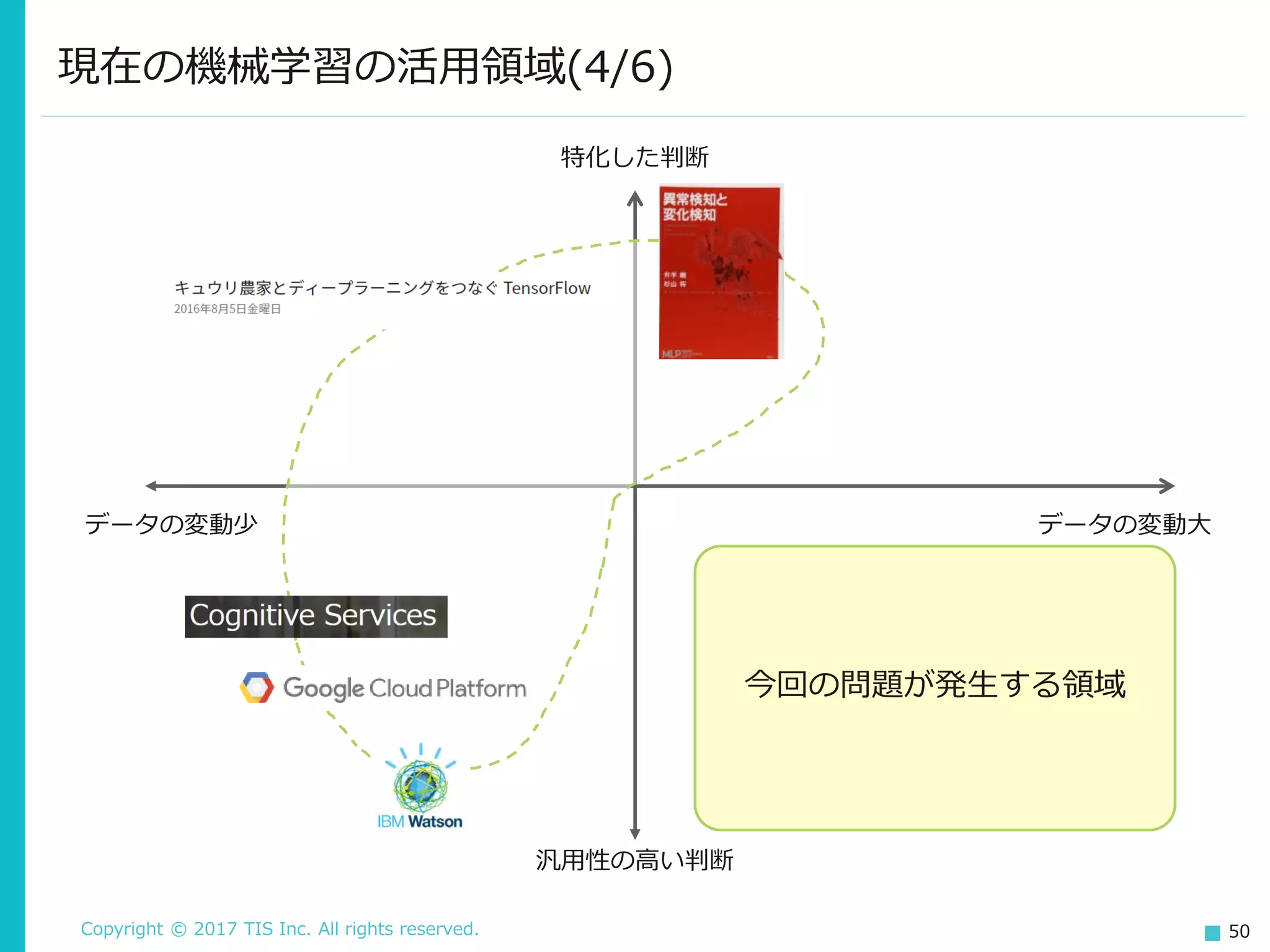
50.
Copyright © 2017
TIS Inc. All rights reserved. 50 現在の機械学習の活用領域(4/6) 特化した判断 汎用性の高い判断 データの変動少 データの変動大 今回の問題が発生する領域
51.
Copyright © 2017
TIS Inc. All rights reserved. 51 現在の機械学習の活用領域(5/6) 現在は、データの変動がそれほど大きくない領域での活用事例が多い。 ただ、機械学習が扱える様々なフレームワークやサービスが登場するなか で、いずれは機械学習の知識を要求しないレベルのサービスやライブラリ が登場する。その際、こうした領域は真っ先にそうしたサービスに代替さ れる可能性がある。 もう登場しとる
52.
Copyright © 2017
TIS Inc. All rights reserved. 52 現在の機械学習の活用領域(6/6) 特化した判断 汎用性の高い判断 データの変動少 データの変動大 画像:ファイナルファンタジーⅥより 機械学習エンジニアが AIにとってかわられる (可能性がある)領域
53.
Copyright © 2017
TIS Inc. All rights reserved. 53 機械学習エンジニアの果たす役割(1/8) 機械学習モデルの自動構築・チューニングは現在最も研究が盛んな領域の 一つであり、進歩も著しい。 Efficient Neural Architecture Search via Parameter Sharing ネットワークの自動構築に関する論文で、今まではGPUで 数百時間というのもざらだったが、16時間以内で画像で も言語モデルでも高い精度を記録する(CIFAR-10はエラー 率2.89%、Penn Treebankはperplexity 55.8でSOTA)。 自動構築が可能なため、データが変動した場合でも対応を行うことができ る。そのため、精度的にも、柔軟性的にも、高いレベルに達する可能性が ある。
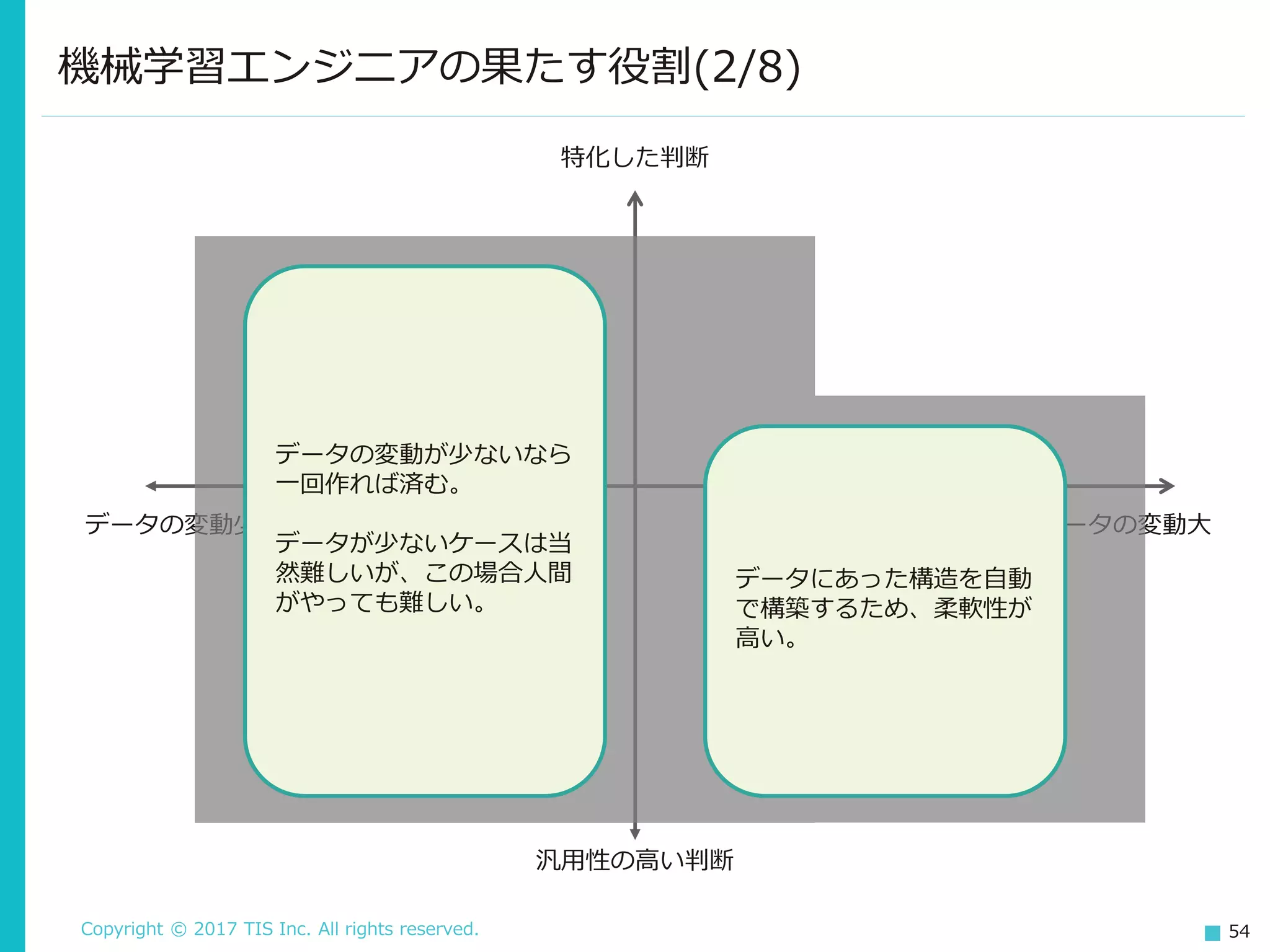
54.
Copyright © 2017
TIS Inc. All rights reserved. 54 機械学習エンジニアの果たす役割(2/8) 特化した判断 汎用性の高い判断 データの変動少 データの変動大 データの変動が少ないなら 一回作れば済む。 データが少ないケースは当 然難しいが、この場合人間 がやっても難しい。 データにあった構造を自動 で構築するため、柔軟性が 高い。
55.
Copyright © 2017
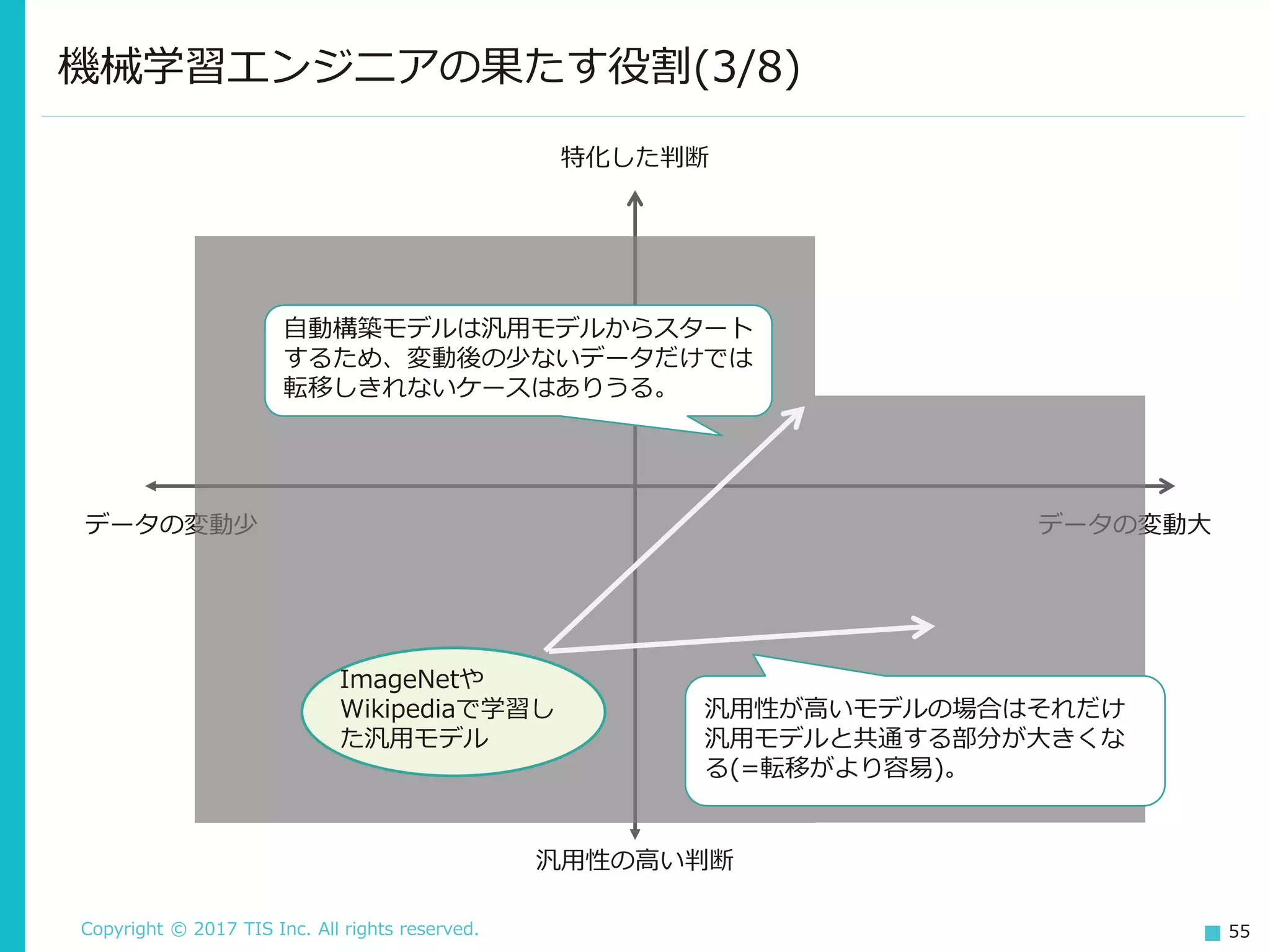
TIS Inc. All rights reserved. 55 機械学習エンジニアの果たす役割(3/8) 特化した判断 汎用性の高い判断 データの変動少 データの変動大 自動構築モデルは汎用モデルからスタート するため、変動後の少ないデータだけでは 転移しきれないケースはありうる。 ImageNetや Wikipediaで学習し た汎用モデル 汎用性が高いモデルの場合はそれだけ 汎用モデルと共通する部分が大きくな る(=転移がより容易)。
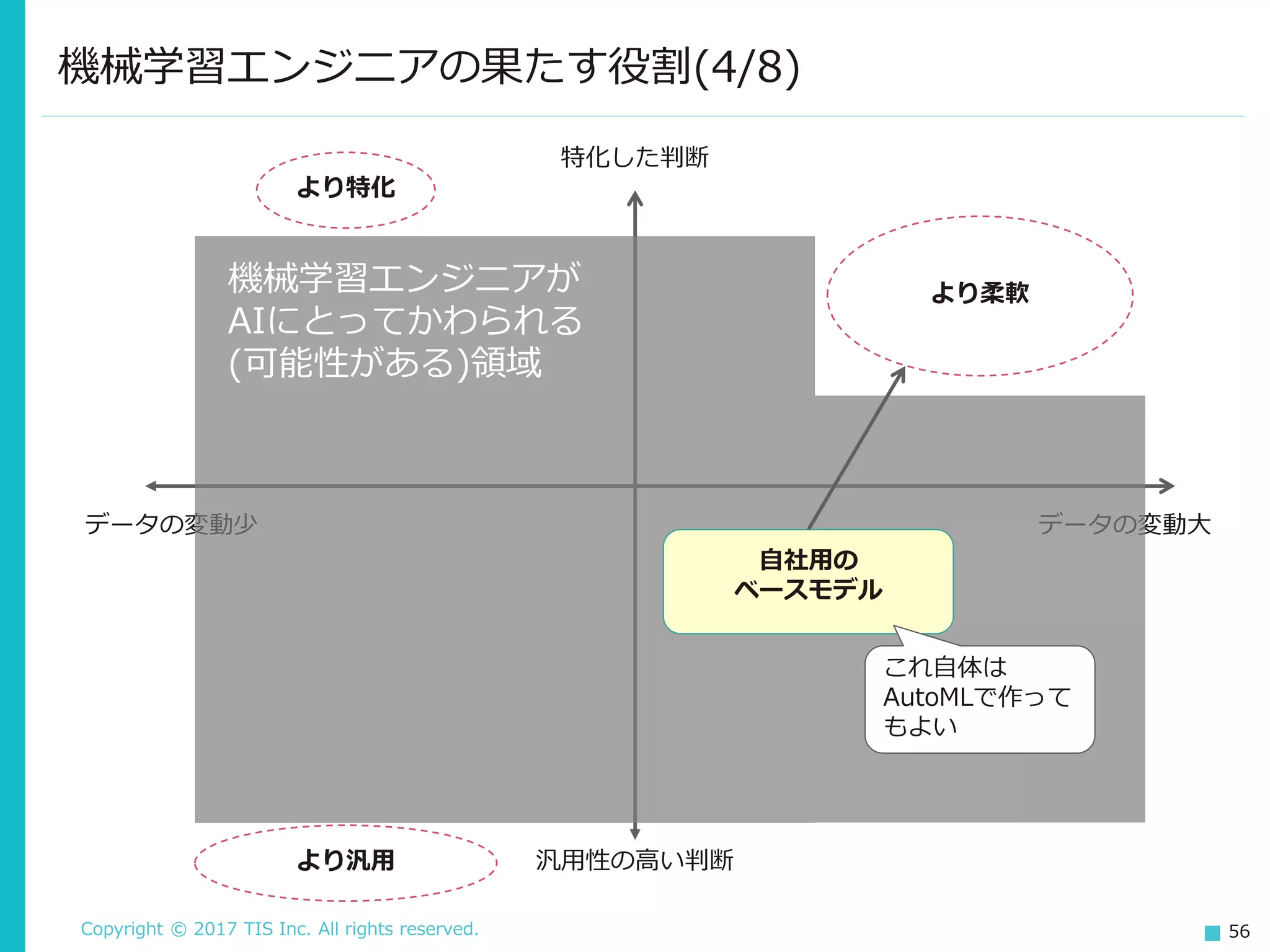
56.
Copyright © 2017
TIS Inc. All rights reserved. 56 より柔軟 機械学習エンジニアの果たす役割(4/8) 特化した判断 汎用性の高い判断 データの変動少 データの変動大 機械学習エンジニアが AIにとってかわられる (可能性がある)領域 より特化 より汎用 自社用の ベースモデル これ自体は AutoMLで作って もよい
57.
Copyright © 2017
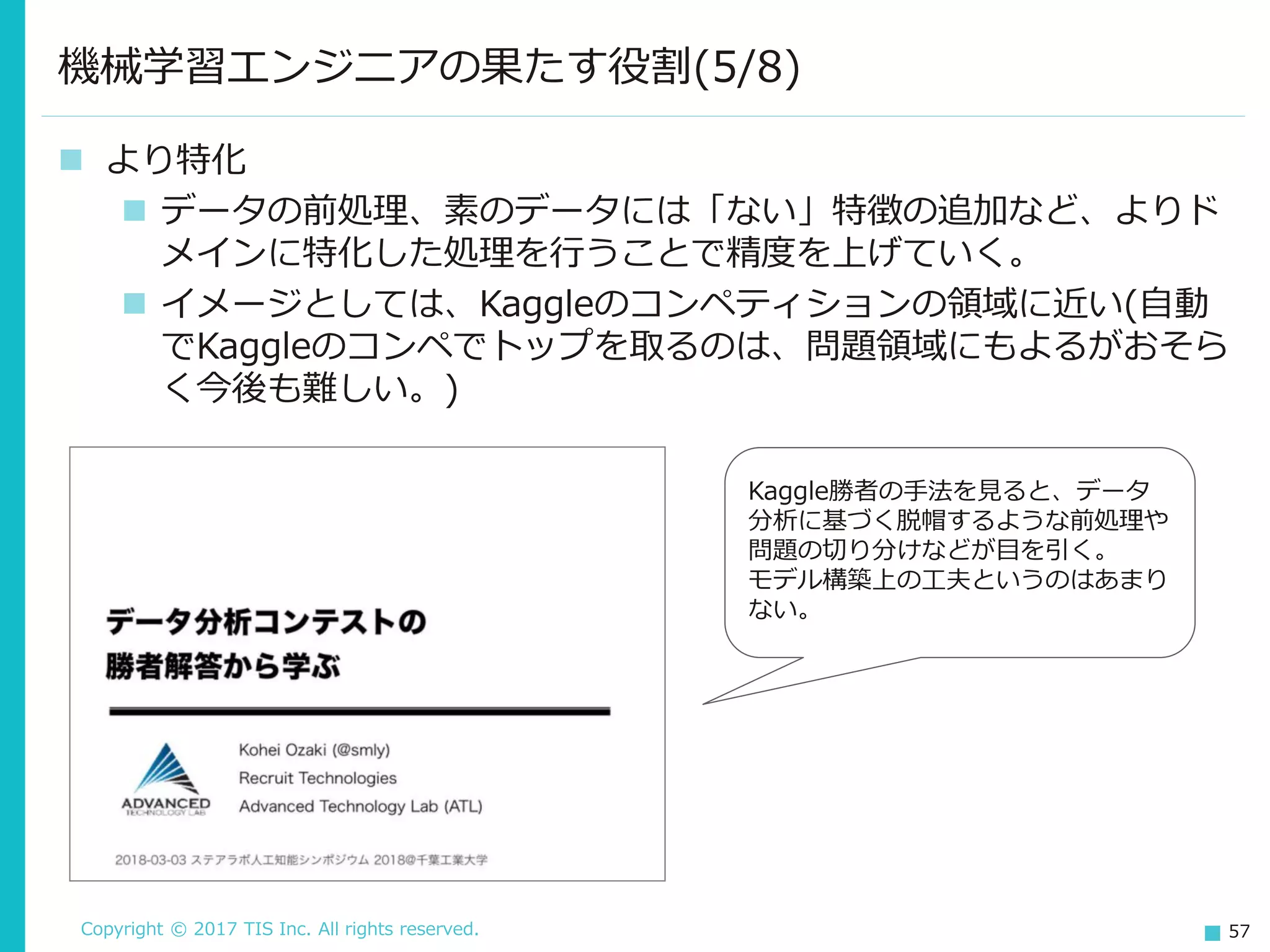
TIS Inc. All rights reserved. 57 より特化 データの前処理、素のデータには「ない」特徴の追加など、よりド メインに特化した処理を行うことで精度を上げていく。 イメージとしては、Kaggleのコンペティションの領域に近い(自動 でKaggleのコンペでトップを取るのは、問題領域にもよるがおそら く今後も難しい。) 機械学習エンジニアの果たす役割(5/8) Kaggle勝者の手法を見ると、データ 分析に基づく脱帽するような前処理や 問題の切り分けなどが目を引く。 モデル構築上の工夫というのはあまり ない。
58.
Copyright © 2017
TIS Inc. All rights reserved. 58 より汎用 より細かいカテゴリを持つモデルや、言語ではクロスリンガルなモ デルなど。これは研究テーマとしても注目されている。 汎用性の高いモデルは、柔軟性にもつながる(汎用的なほど色々な 状況に対応できるため)。 より柔軟 事前学習済みモデル(転移学習)を活用し、少ないデータしかない状 況(何かしらのビジネス変化が起きた直後など)でも対応する 画像はもちろん、自然言語の分野でも盛んに研究が行われている。 機械学習エンジニアの果たす役割(6/8)
59.
Copyright © 2017
TIS Inc. All rights reserved. 59 機械学習エンジニアの果たす役割(7/8) 現実には、ビジネス環境の変化によりデータに大きな変化が起こることが 多い。 質問回答システム 法令が変更された、新しい機種が出た 画像からの異常検知モデル 点検する場所が増えた・時間帯が変わった 売上予測モデル 近くに競合店ができた、今年からお祭りが中止になった 変更発生直後のデータは量がそれほどないため、おのずと既存のモデルを ベースに学習する、転移学習などの技術が必要になってくる。 「柔軟性」は、変化が多い分野にも機械学習の活躍の場を広げるという面 でも重要。
60.
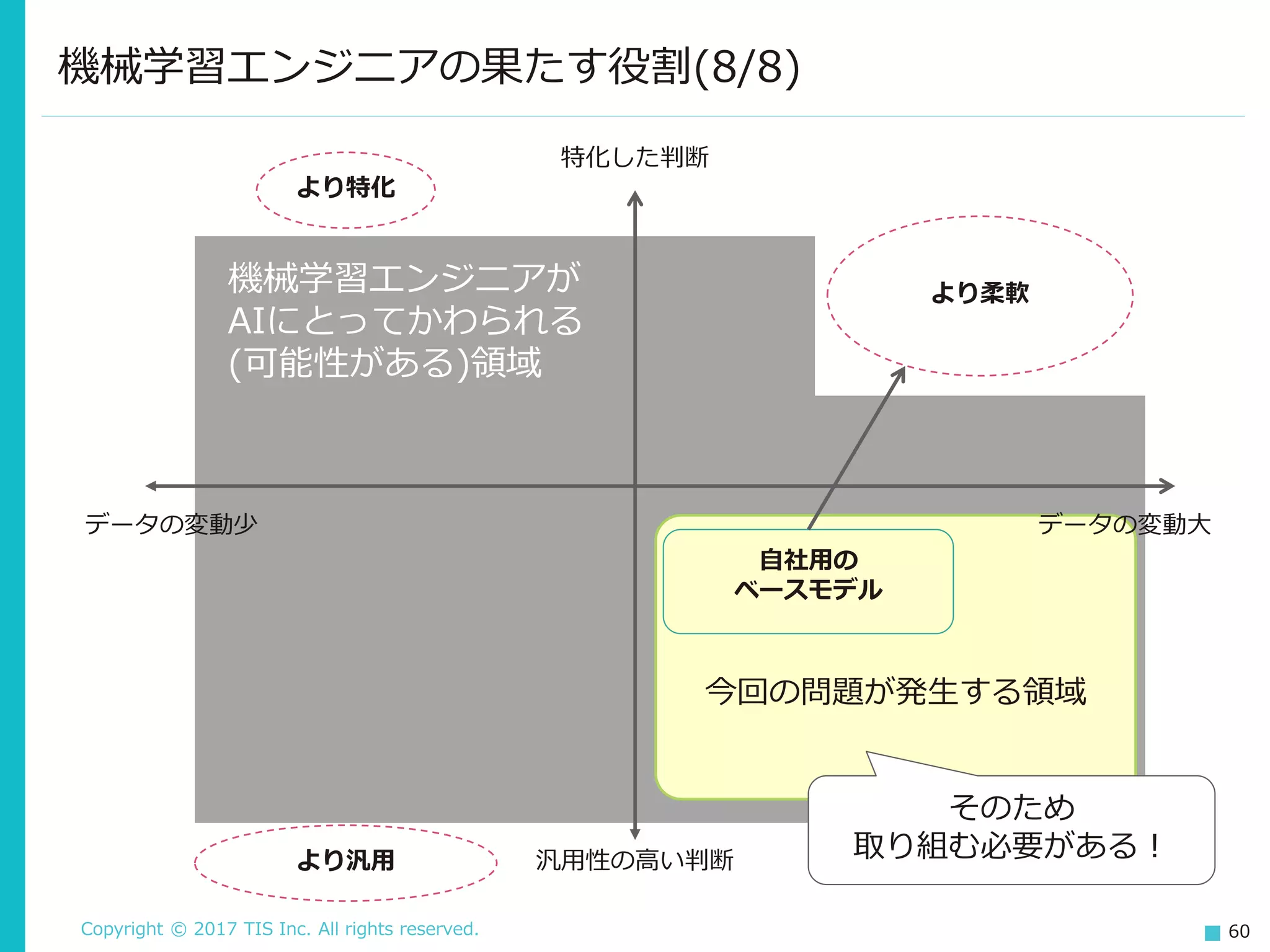
Copyright © 2017
TIS Inc. All rights reserved. 60 今回の問題が発生する領域 より柔軟 機械学習エンジニアの果たす役割(8/8) 特化した判断 汎用性の高い判断 データの変動少 データの変動大 機械学習エンジニアが AIにとってかわられる (可能性がある)領域 より特化 より汎用 自社用の ベースモデル そのため 取り組む必要がある!
61.
Copyright © 2017
TIS Inc. All rights reserved. 61 機械学習活用の次のステップへ(1/2) 機械学習自体の自動化が進む中で、機械学習エンジニアという人間が 取り組むべき問題はどんどん変化してきている。 より特化 より汎用 より柔軟 これは強制スクロール型の進行なので、拒否権はない。 画像:ヨッシーアイランドより
62.
Copyright © 2017
TIS Inc. All rights reserved. 62 機械学習活用の次のステップへ(2/2) 逆に考えれば、すでに解決された問題については自動的に処理してくれる ありがたい状況とみることもできる。 データがなければ力が出ない、という特性上データが十分ある(確保で きる)領域が主戦場だったが、学習済みモデルの活用によりその前提は 崩れつつある。 変化が大きい領域での活躍は、ビジネス的にも有用であるのと同時に、 研究面でも挑戦的なテーマ。 そして、その際には依存性の問題が立ちはだかる。これは研究上の問 題というよりは、設計/開発/運用といったエンジニアリング面の問題。 機械学習の活用を次のステップに進めるためには、 研究面だけでなくエンジニアリング面での進化も必要
63.
THANK YOU
Download










![Copyright © 2017 TIS Inc. All rights reserved. 17
ギャップを埋める処理による影響(2/3)
if model.predict(user).prob[“kiken”] > 0.81394:
user.account.stop()
よく考えられた閾値
これが機械学習モデルの力を引き出すコードだ!
画像:MMR:マガジンミステリー調査班より
※(さすがに)閾値については、固定値ではなくバリデーションデータを使って自動調整する
手法がある。
Detecting Adversarial Advertisements in the Wild](https://image.slidesharecdn.com/mlinsystematmanabiya-180323063531/75/slide-17-2048.jpg)



















































![[DLHacks]Comet ML -機械学習のためのGitHub-](https://cdn.slidesharecdn.com/ss_thumbnails/180625dlhacksltcometml-180629052128-thumbnail.jpg?width=640&height=640&fit=bounds)








































