Retrofitting Word Vectorsto
Semantic Lexicons
Manaal Faruqui, Jese Dodge, Sujay K. Jauhar,
Chris Dyer, Eduard Hovy, Noah A. Smith
NACL 2015
読む人:高瀬翔
知識獲得研究会2015/4/21
1
提案手法
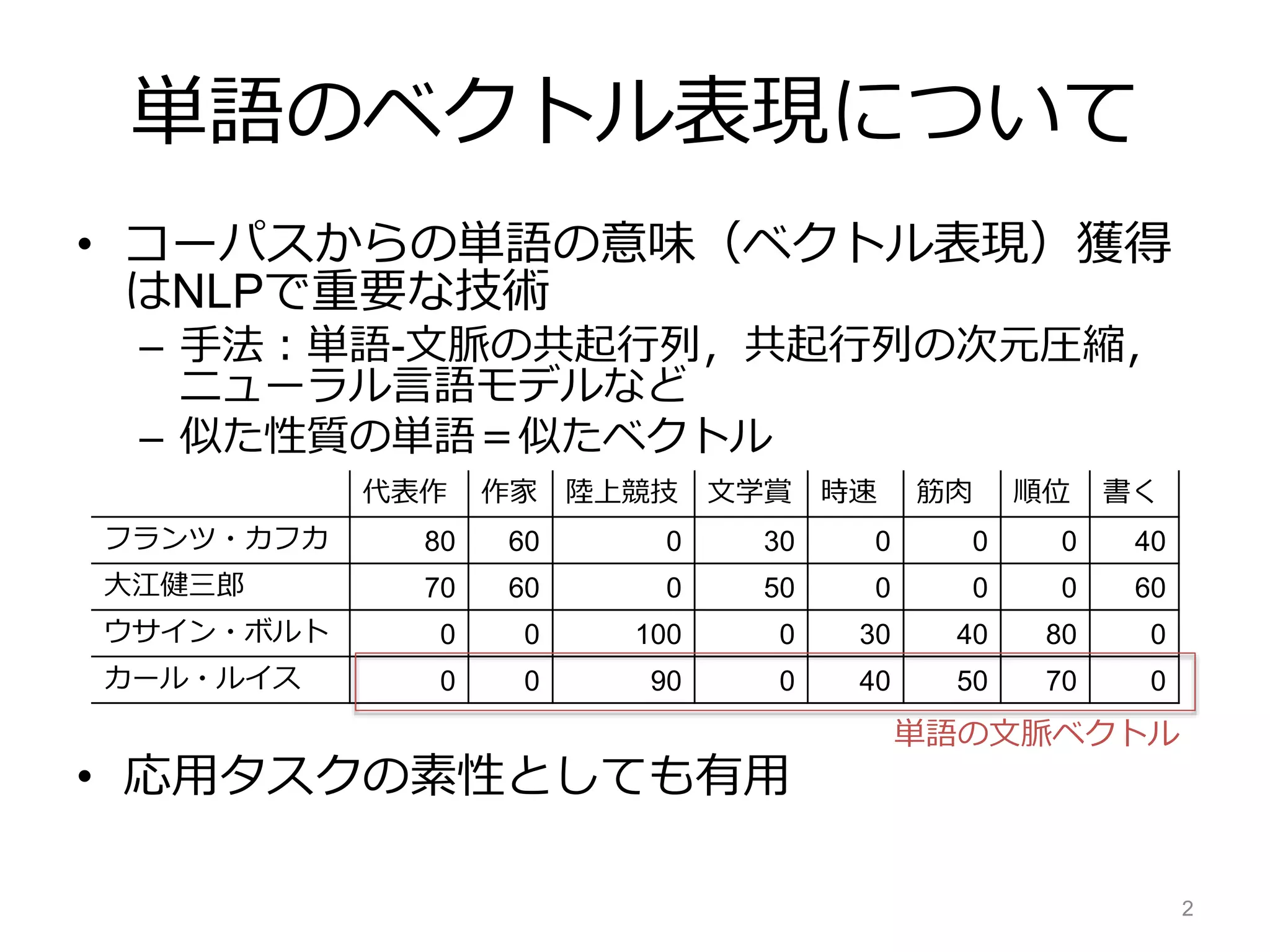
• やりたいことは2つ
– コーパスから得たベクトル(入力)と似たベクトルとする
–外部知識上で関連する単語は似たベクトルとする
• 関連:同義語,上位下位語,言い換え
• 目的関数
– 似せたいベクトル間のユークリッド距離を最小化
• 一項目:コーパスの情報(入力ベクトルに近づける)
• 二項目:外部知識(外部知識上での関連語に近づける)
– E:外部知識上で関連している単語間に張ったエッジの集合
– α,β:ハイパーパラメータ(α=1,β=1 / エッジの次数)
5
en related words
inferred (white)
method works
ord vector mod-
tors to beretrofitted (and correspond to V⌦); shaded
nodes are labeled with the corresponding vectors in
ˆQ, which areobserved. Thegraph can beinterpreted
as a Markov random field (Kindermann and Snell,
1980).
The distance between a pair of vectors is defined
to be the Euclidean distance. Since we want the
inferred word vector to be close to the observed
value ˆqi and close to its neighbors qj , 8j such that
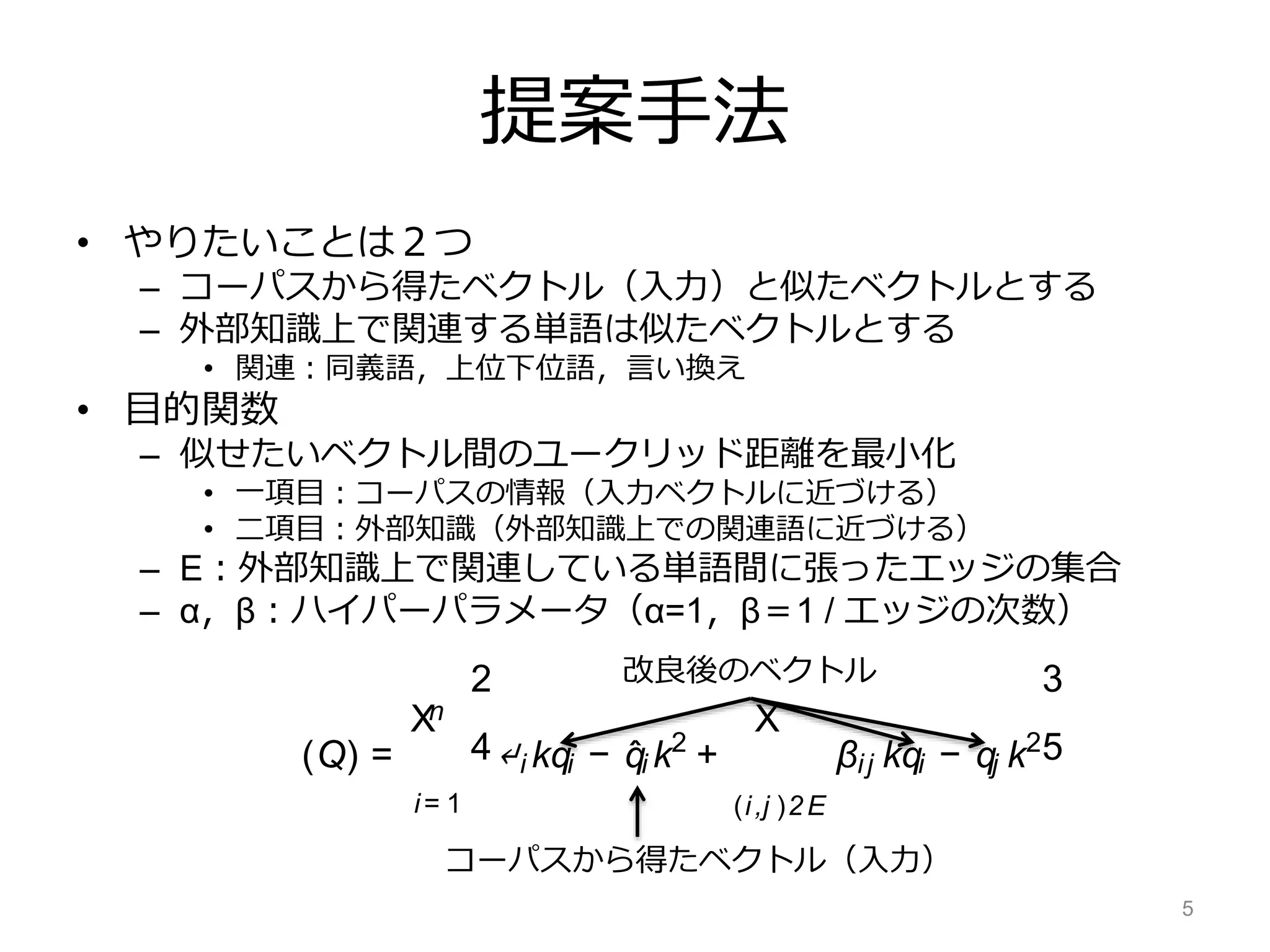
(i, j ) 2 E, theobjectiveto beminimized becomes:
(Q) =
nX
i= 1
2
4↵i kqi − ˆqi k2
+
X
(i,j )2E
βij kqi − qj k2
3
5
where ↵ and β values control the relative strengths
of associations (moredetails in §6.1).
コーパスから得たベクトル(入力)
改良後のベクトル
6.
解き方
• 反復更新で解を求める
– 各qi について,目的関数を最小化する値への更
新を繰り返す
– qi は入力ベクトルで初期化
• 経験的には10回の反復で近づけたいベクトル
間のユークリッド距離は0.01未満になる
6
orma-
o mul-
gives
valua-
engths
ect of
fitting
com/
s
heset
desse-
resent
ex for
V ⇥ V
lution can be found by solving a system of linear
equations. To do so, we use an efficient iterative
updating method (Bengio et al., 2006; Subramanya
et al., 2010; Das and Petrov, 2011; Das and Smith,
2011). The vectors in Q are initialized to be equal
to thevectorsin ˆQ. Wetakethefirst derivativeof
with respect to one qi vector, and by equating it to
zero arriveat thefollowing onlineupdate:
qi =
P
j :(i,j )2E βij qj + ↵i ˆqi
P
j :(i,j )2E βij + ↵i
(1)
In practice, running this procedure for 10 iterations
converges to changes in Euclidean distance of ad-
jacent vertices of less than 10− 2. The retrofitting
approach described above is modular; it can be ap-
plied to word vector representations obtained from
更新式:

![ベクトル表現への外部知識導入
と先行研究の問題点
• 外部知識利用でベクトル表現の質が向上[Yu+ 14,
Chang+ 13]
– 外部知識:WordNet,FrameNetなど
• 問題点:ベクトルの構成手法が限定的
– コーパスと外部知識の利用を統合してしまっている
– 与えられたベクトルに外部知識を組み込む改良が
できない(新たな学習手法などに対応できない)
• 例[Yu+ 14]:目的関数に外部知識の項がある
3
文脈 外部知識](https://image.slidesharecdn.com/20150421forupdate-150424043332-conversion-gate02/75/Retrofitting-Word-Vectors-to-Semantic-Lexicons-3-2048.jpg)


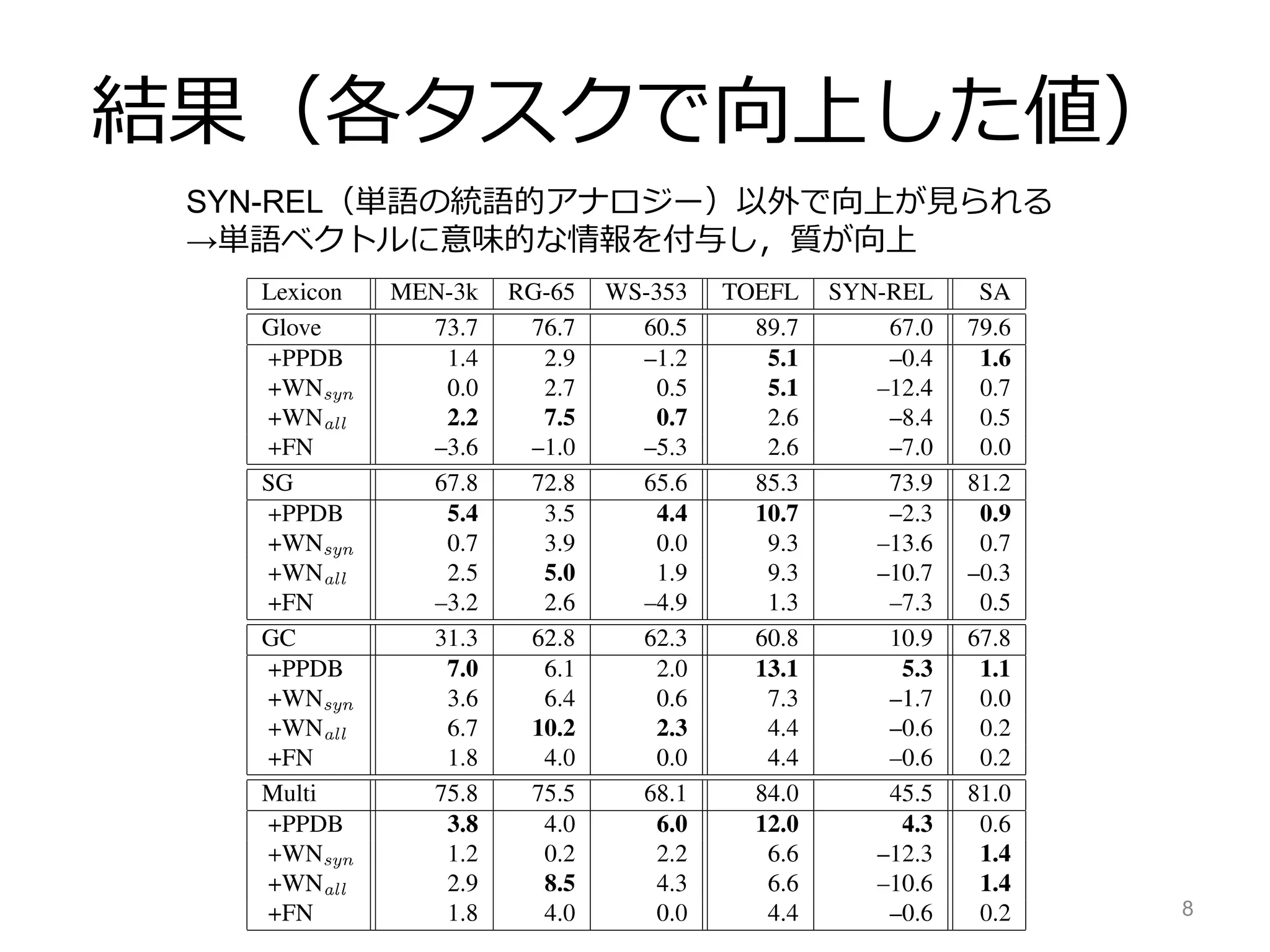
![実験
• 様々な公開されているベクトルを入力とし
– Glove[Pennington+ 14]:共起情報をベクトルでモデル化
– SG[Mikolov+ 13]:周囲の単語を予測できるよう学習
– GC[Huang+ 12]:ローカルと文書レベルの文脈を組み合わせて学習
– Multi[Faruqui+ 14]:異なる言語間で単語ベクトルにCCA
• 様々な外部知識を利用して
– PPDB:翻訳すると同じ語になる単語を言い換えとして収集したDB
– WordNet:人手の辞書(同義語のみ(syn) or 同義+上位下位(all))
– FrameNet:フレーム辞書,同一のフレームを持つ単語にエッジを張る
• 様々なタスクでの性能向上を検証
– 単語の類似度タスク
– TOFEL:与えられた単語と同じ意味の単語を選択肢から選ぶ
– 単語の統語的アナロジータスク
– Sentiment analysis:文内の単語のベクトルの平均を素性に分類器構築
7](https://image.slidesharecdn.com/20150421forupdate-150424043332-conversion-gate02/75/Retrofitting-Word-Vectors-to-Semantic-Lexicons-7-2048.jpg)

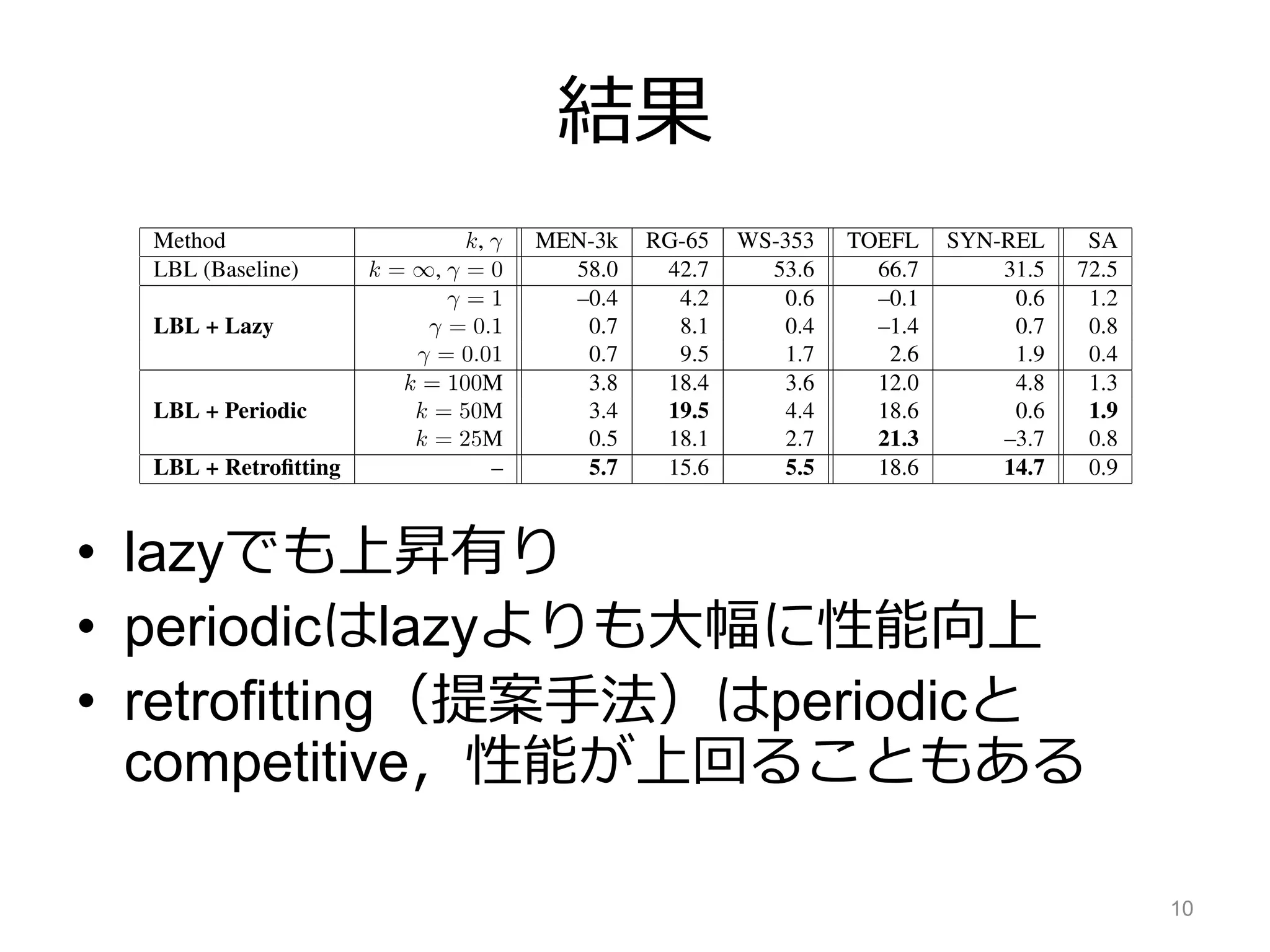
![先行研究との比較
• [Yu+ 14]との比較では全てのタスクで性能
向上
• [Xu+ 14]との比較でもほぼ全てのタスクで
性能向上
11](https://image.slidesharecdn.com/20150421forupdate-150424043332-conversion-gate02/75/Retrofitting-Word-Vectors-to-Semantic-Lexicons-11-2048.jpg)









![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Making Sense of Vision and Touch: Self-Supervised Learning of Multimod...](https://cdn.slidesharecdn.com/ss_thumbnails/20190802dl-190808102241-thumbnail.jpg?width=640&height=640&fit=bounds)











































