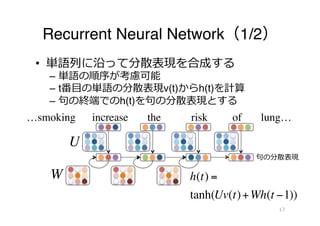
Recurrent Neural Networkの発展
• LSTM
– ゲート( )により履履歴・単語に応じた重みを付与可能
– 記憶領領域により⻑⾧長期の依存関係を扱える
• Lコンポーネント(パラメータ)が多すぎる
– 例例:数単語の句句を扱うために記憶領領域が必要か?
19
…smoking increase the risk of lung…
記憶領領域
句句の分散表現
3
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
for
for
ost
ds.
rity
n’s
28.
ee-
the
ell-
pre-
ach
sin-
ed-
im-
ep,
ons
ach
ers
ive
using a function, F(x1, ..., xT ), where F(.) is mod-
eled by a variant of recurrent neural network (RNN).
3.1 Baseline: Long Short-Term Memory
Long Short-Term Memory (LSTM) (Hochreiter and
Schmidhuber, 1997) is a variant of RNN that is
applied successfully to various NLP tasks includ-
ing word segmentation (Chen et al., 2015), depen-
dency parsing (Dyer et al., 2015), machine transla-
tion (Sutskever et al., 2014), and sentiment analy-
sis (Tai et al., 2015). LSTM computes the input gate
it ∈ Rd, forget gate ft ∈ Rd, output gate ot ∈ Rd,
memory cell ct ∈ Rd, and hidden state ht ∈ Rd for
a given embedding xt at position t5.
it = σ(Wixxt + Wihht−1) (1)
ft = σ(Wfxxt + Wfhht−1) (2)
ot = σ(Woxxt + Wohht−1) (3)
ct = ft ⊙ ct−1 + it ⊙ g(Wcxxt + Wchht−1) (4)
ht = ot ⊙ g(ct) (5)
5
We omitted peephole connections and bias terms in this
study. We set the number of dimensions of hidden states iden-
tical to that of word embeddings (d) so that we can adapt the
objective function of Skip-gram model (Section 3.3).
20.
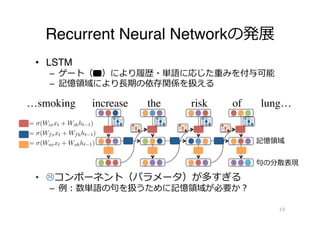
Gated Additive Composition(GAC) [Takase+ 16]
• ゲートにより履履歴・単語に応じた重みを付与可能
– 加法構成 + 単語の順序 + ゲート
• ⼊入⼒力力ゲート:
– 機能語(the, of)を無視,内容語(increase, risk)を⼊入⼒力力
• 忘却ゲート:
– 以前の分散表現をどの程度度無視する(忘れる)かを操作
20
…smoking increase the risk of lung…
句句の分散表現
4
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
ly apparent (Jozefowicz et al., 2015). We are un-
e whether LSTM is the optimal architecture for
odeling relational patterns.
For this reason, we simplified the LSTM archi-
ture as follows. We removed a memory cell by
placing ct with a hidden state ht because the prob-
m of exponential error decay (Hochreiter et al.,
01) might not be prominent for relational patterns.
e also removed matrices corresponding to Whh
d Whx because most relational patterns hold addi-
e composition. This simplification yields the ar-
tecture defined by Equations 6–8.
it = σ(Wixxt + Wihht−1) (6)
ft = σ(Wfxxt + Wfhht−1) (7)
ht = g(ft ⊙ ht−1 + it ⊙ xt) (8)
lp =
τ∈Cp
log σ(h⊤
p ˜xτ ) +
k=1
log σ(−h⊤
p ˜x˘τ )
(9)
In this formula: K denotes the number of negative
samples; hp ∈ Rd is the vector for the relational
pattern p computed by LSTM or GAC; ˜xτ ∈ Rd is
the context vector for the word wτ
6; x˘τ′ ∈ Rd is the
context vector for the word that were sampled from
6
The Skip-gram model has two kinds of vectors xt and
˜xt assigned for a word wt. Equation 2 of the original pa-
per (Mikolov et al., 2013) denotes xt (word vector) as v (in-
put vector) and ˜xt (context vector) as v′
(output vector). The
word2vec implementation does not write context (output) vec-
tors but only word (input) vectors to a model file. Therefore, we
modified the source code to save context vectors, and use them
in Equation 9. This modification ensures the consistency of the
entire model.
ゲートの値と⼊入⼒力力・履履歴
• GACの各ゲートが開く/閉じるときの⼊入⼒力力単語と
履履歴
27
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
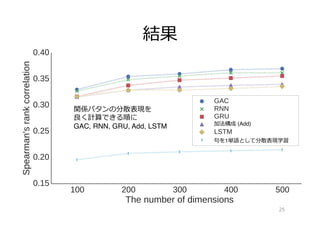
3 2,2720.234 0.386 0.344 0.370 0.
4 1,206 0.208 0.306 0.314 0.329 0.
> 5 423 0.278 0.315 0.369 0.384 0.
All 5,555 0.215 0.340 0.336 0.356 0.
Table 1: Spearman’s rank correlations on different pattern lengths (numb
wt wt+1 wt+2 ...
large it reimburse for
(input payable in
open) liable to
small it a charter member of
(input a valuable member of
close) be an avid reader of
large ft be eligible to participate in
(forget be require to submit
open) be request to submit
small ft coauthor of
(forget capital of
close) center of
Table 2: Prominent moments for input/forget
|it|2 or |ft|2 is small
to one) on the relatio
state that we compose
order (from the last t
‘author’, and ‘be’ in
vector of the relation
Table 2 displays t
tified using the proce
groups of tendencies.
gates close when scan
sition and the curren
these situations, GA
vector of the content
mantic vector of the p
gates close and forge





![基本は分布仮説 [Harris, 64]
• 似た⽂文脈で出現する単語は似た意味を持つ
– ⽂文脈(周辺に出現する単語)の分布をベクトルとする
– 単語間の意味的類似度度を⽂文脈ベクトルの類似度度で計算
• SGNSは単語-⽂文脈PMI⾏行行列列の⾏行行列列分解 [Levy+ 2014]
• Gloveは単語-⽂文脈の対数共起頻度度を学習
4
have
drink
eat
bottle
roast
essay
read
work
…
beer
48 72 28 57 30 1 8 11 …
wine
108 92 24 86 29 2 2 23 …
mutton 309 31 105 13 48 0 0 17 …
novelist 12 4 8 0 0 103 186 134 …
writer
31 3 10 0 0 132 238 84 …
単語
⽂文脈
単語-⽂文脈
の共起頻度度⾏行行列列](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-4-320.jpg)


![句句の分散表現計算⼿手法
• 加法構成 [Mikolov+ 13, Pham+ 15]
• 単語列列を⼊入⼒力力とする⼿手法
– Recurrent NN
– Gated Recurrent Unit (GRU) [Cho+ 14]
– Long-Short Term Memory (LSTM) [Hochreiter+ 97]
• 構⽂文⽊木を⼊入⼒力力とする⼿手法 ← 今⽇日は除外
– Recursive NN [Socher+ 11]
– Matrix-Vector Recursive NN [Socher+ 12]
– Recursive Neural Tensor Network [Socher+ 13]
– Tree-LSTM [Tai+ 15]
7](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-7-320.jpg)
![おまけ:構⽂文⽊木を⼊入⼒力力とする⼿手法
除外の理理由
• Recurrent NN系のモデルの⽅方が流流⾏行行ってるから
• 構⽂文⽊木を⼊入⼒力力とする⼿手法はバッチ化に難
– GPUの計算⼒力力をあまり活かせない
• 性能⾯面での⼤大きな向上もない
8
ntiment
|✓|
315,840
315,840
318,720
318,720
316,800
315,840
mposition
STM vari-
dard bina-
vided for
Method Fine-grained Binary
RAE (Socher et al., 2013) 43.2 82.4
MV-RNN (Socher et al., 2013) 44.4 82.9
RNTN (Socher et al., 2013) 45.7 85.4
DCNN (Blunsom et al., 2014) 48.5 86.8
Paragraph-Vec (Le and Mikolov, 2014) 48.7 87.8
CNN-non-static (Kim, 2014) 48.0 87.2
CNN-multichannel (Kim, 2014) 47.4 88.1
DRNN (Irsoy and Cardie, 2014) 49.8 86.6
LSTM 46.4 (1.1) 84.9 (0.6)
Bidirectional LSTM 49.1 (1.0) 87.5 (0.5)
2-layer LSTM 46.0 (1.3) 86.3 (0.6)
2-layer Bidirectional LSTM 48.5 (1.0) 87.2 (1.0)
Dependency Tree-LSTM 48.4 (0.4) 85.7 (0.4)
Constituency Tree-LSTM
– randomly initialized vectors 43.9 (0.6) 82.0 (0.5)
– Glove vectors, fixed 49.7 (0.4) 87.5 (0.8)
– Glove vectors, tuned 51.0 (0.5) 88.0 (0.3)
Fine-grained Binary
Stanford Sentiment Treebankでのテスト結果 [Tai+ 15]](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-8-320.jpg)
![おまけ:構⽂文⽊木 vs. 単語列列
• 4種のタスクで構⽂文⽊木を⼊入⼒力力とする⼿手法と
単語列列を⼊入⼒力力とする⼿手法を⽐比較 [Li+ 2015]
– Bi-directional LSTM > Tree-LSTM
• Sentiment analysis, QA, Discourse parsing
– Tree-LSTM > Bi-directional LSTM
• Relation classification
• 余談:ちなみにSOTAはdependency + CNN
– 単語列列を⼊入⼒力力とする⼿手法でもかなり強い
9](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-9-320.jpg)
![句句の分散表現計算⼿手法
• 加法構成 [Mikolov+ 13, Pham+ 15]
• 単語列列を⼊入⼒力力とする⼿手法
– Recurrent NN
– Gated Recurrent Unit (GRU) [Cho+ 14]
– Long-Short Term Memory (LSTM) [Hochreiter+ 97]
• 構⽂文⽊木を⼊入⼒力力とする⼿手法 ← 今⽇日は除外
– Recursive NN [Socher+ 11]
– Matrix-Vector Recursive NN [Socher+ 12]
– Recursive Neural Tensor Network [Socher+ 13]
– Tree-LSTM [Tai+ 15]
10](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-10-320.jpg)
![加法構成
• 分散表現の⾜足し引きで意味計算
– vking + vwoman - vman ≈ vqueen
• 意外と⾼高い性能 [Muraoka+ 14]
11
…smoking increase the risk of lung…
構成単語の
分散表現の総和](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-11-320.jpg)

![加法構成の理理論論 [Tian+ 2016]
• ⼤大きさ無限のコーパスを考える
– 単語-⽂文脈について真の値を得られる
• このとき,句句の⽂文脈ベクトル(vXY)と加法構成に
よるベクトル((vX+vY)/2)の差を考える
• 単語-⽂文脈の共起情報がある尺度度のとき,Bに上界
が存在
– 加法構成で句句の⽂文脈を近似できる
13
B = kvXY
1
2
(vX + vY )k](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-13-320.jpg)


![加法構成のまとめ
• 分散表現の⾜足し引きで意味計算
• J理理論論的な背景が存在 [Tian+ 16]
• J計算が楽
• L単語の順序を考慮していない
– help to stop = stop to help
16](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-16-320.jpg)

![Gated Additive Composition (GAC) [Takase+ 16]
• ゲートにより履履歴・単語に応じた重みを付与可能
– 加法構成 + 単語の順序 + ゲート
• ⼊入⼒力力ゲート:
– 機能語(the, of)を無視,内容語(increase, risk)を⼊入⼒力力
• 忘却ゲート:
– 以前の分散表現をどの程度度無視する(忘れる)かを操作
20
…smoking increase the risk of lung…
句句の分散表現
4
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
ly apparent (Jozefowicz et al., 2015). We are un-
e whether LSTM is the optimal architecture for
odeling relational patterns.
For this reason, we simplified the LSTM archi-
ture as follows. We removed a memory cell by
placing ct with a hidden state ht because the prob-
m of exponential error decay (Hochreiter et al.,
01) might not be prominent for relational patterns.
e also removed matrices corresponding to Whh
d Whx because most relational patterns hold addi-
e composition. This simplification yields the ar-
tecture defined by Equations 6–8.
it = σ(Wixxt + Wihht−1) (6)
ft = σ(Wfxxt + Wfhht−1) (7)
ht = g(ft ⊙ ht−1 + it ⊙ xt) (8)
lp =
τ∈Cp
log σ(h⊤
p ˜xτ ) +
k=1
log σ(−h⊤
p ˜x˘τ )
(9)
In this formula: K denotes the number of negative
samples; hp ∈ Rd is the vector for the relational
pattern p computed by LSTM or GAC; ˜xτ ∈ Rd is
the context vector for the word wτ
6; x˘τ′ ∈ Rd is the
context vector for the word that were sampled from
6
The Skip-gram model has two kinds of vectors xt and
˜xt assigned for a word wt. Equation 2 of the original pa-
per (Mikolov et al., 2013) denotes xt (word vector) as v (in-
put vector) and ˜xt (context vector) as v′
(output vector). The
word2vec implementation does not write context (output) vec-
tors but only word (input) vectors to a model file. Therefore, we
modified the source code to save context vectors, and use them
in Equation 9. This modification ensures the consistency of the
entire model.](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-20-320.jpg)

![実験1: 関係パタンの分散表現計算
• 関係パタン:単語間の意味的関係を⽰示す
表現
• 関係パタンは抽出器で事前に抽出
– Reverb [Fader+ 12] を利利⽤用
– コーパスはukWaC(約20億単語)
22
Cephalexin reduce the risk of the bacteria
Cephalexin prevent the bacteria
Inhibit(Cephalexin, bacteria)](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-22-320.jpg)
![パラメータの学習
• ⽬目的関数:SGNS [Mikolov+ 13] を利利⽤用
– 関係パタンの分散表現から周辺単語の分散表現を予測
• 誤差逆伝播でパラメータを学習
23
…smoking increase the risk of lung…
logP(wt+j | wt ) ≈ logσ (vwt
⋅uwt+j
)+ Εz~Pn (w)
i=1
k
∑ [logσ (−vwt
⋅uz )]
負例例単語 z を k 回サンプリング
周辺単語を予測 vwt
uwt+1
uw−1
これ→
を最⼤大化](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-23-320.jpg)





![評価⼿手法
• ⼈人⼿手で付与した類似度度と各⼿手法から算出した
類似度度の相関を測る
– [Wieting+ 15] のデータセットを使⽤用
• JN,NN,VNそれぞれ108ペア
• [Mitchell+ 10] のデータに対し,⾔言い換え関係かどうか
の観点で再アノテーション
31
Adj-Noun1 Adj-Noun2 ⼈人⼿手で付与した類
似度度(5段階)
bigram間の
コサイン類似度度
vast amount large quantity 5.0 0.9
small house little room 2.0 0.6
better job good place 3.0 0.6
……
スピアマンの順位相関係数を計算](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-31-320.jpg)
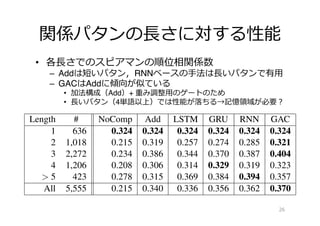
![結果
• 各⼿手法は拮抗しているように思える
– GRU,Recursive NN,GACが強い
32
⼿手法 JN NN VN Avrage
Add 0.50 0.29 0.58 0.46
Recursive NN [Wieting+ 15] 0.57 0.44 0.55 0.52
Recurrent NN 0.58 0.43 0.46 0.49
GRU 0.62 0.40 0.53 0.53
LSTM 0.57 0.44 0.49 0.49
CNN 0.58 0.48 0.50 0.50
GAC 0.56 0.43 0.52 0.52
Human 0.87 0.64 0.73 0.75](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-32-320.jpg)

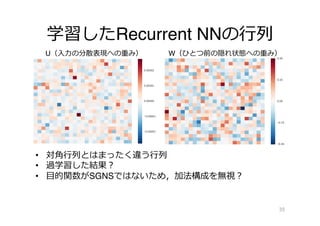
![結果
• GAC, CNNが強い
• 疑問:LSTM, GRUは何故低い?
– 現状では不不明
– 単に過学習ということで良良いのか?
34
⼿手法 Spearman’s rank correlation
Add 0.32
Recursive NN [Wieting+ 15] 0.40
Recurrent NN 0.25
GRU 0.33
LSTM 0.32
CNN 0.45
GAC 0.47](https://image.slidesharecdn.com/nlpdl4forup-160621235941/85/4thNLPDL-34-320.jpg)













































![[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...](https://cdn.slidesharecdn.com/ss_thumbnails/acl2018reading-181029052106-thumbnail.jpg?width=640&height=640&fit=bounds)








