Downloaded 17 times






![Technique: Semantic Spaces
• Based around the factorisation [-]= TD
• Calculated using truncated SVD
• Rows of T represent coordinates of the features
and words in a vector space
• Columns of D represent coordinates of images in
the same space
• Similar objects have similar locations in the space, so
it is possible to rank images on their distance to a
given word
F
W
Hare, J. S., Lewis, P. H., Enser, P. G. B., and Sandom, C. J., “A Linear-Algebraic Technique with an
Application in Semantic Image Retrieval,” in CIVR 2006, Sundaram, H., Naphade, M., Smith, J. R., and
Rui,Y., eds., LNCS 4071, 31–40, Springer (2006).](https://image.slidesharecdn.com/spie-ei2010-150129112134-conversion-gate02/85/Semantic-Retrieval-and-Automatic-Annotation-Linear-Transformations-Correlation-and-Semantic-Spaces-6-320.jpg)
![Technique: Correlation
• Pan et al defined four techniques for building
translation tables between visual terms and keywords
[i.e. the elements of the table/matrix represent
p(wi,fj)].
• The Corr method used WTF to build the table
• The Cos method used the cosine of wi and fj
• The SVDCorr and SVDCos methods filtered the
tables from the Corr and Cos methods reducing
the rank using the SVD
Pan, J.-Y.,Yang, H.-J., Duygulu, P., and Faloutsos, C., “Automatic image captioning,” IEEE International Conference
on Multimedia and Expo 2004 (ICME ’04). Vol.3 (27-30 June 2004).](https://image.slidesharecdn.com/spie-ei2010-150129112134-conversion-gate02/85/Semantic-Retrieval-and-Automatic-Annotation-Linear-Transformations-Correlation-and-Semantic-Spaces-7-320.jpg)
![Image Features
• Two types of visual-term feature considered:
• Segmented-blob based (using shape, colour, texture
descriptors) [500 terms]
• Quantised DCT-based [500 terms]](https://image.slidesharecdn.com/spie-ei2010-150129112134-conversion-gate02/85/Semantic-Retrieval-and-Automatic-Annotation-Linear-Transformations-Correlation-and-Semantic-Spaces-9-320.jpg)

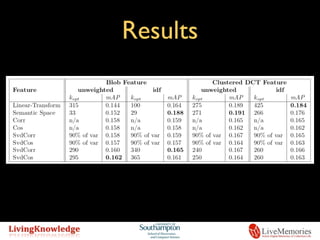



The document presents a new linear-transform based technique for automatic annotation and semantic retrieval of images, comparing it to various existing methods. It discusses the use of singular value decomposition (SVD) for noise reduction and outlines a systematic approach for relating visual-term occurrences to keyword occurrences. Although the performance is not state-of-the-art, the proposed methods are noted for their computational efficiency and determinism.
















































































