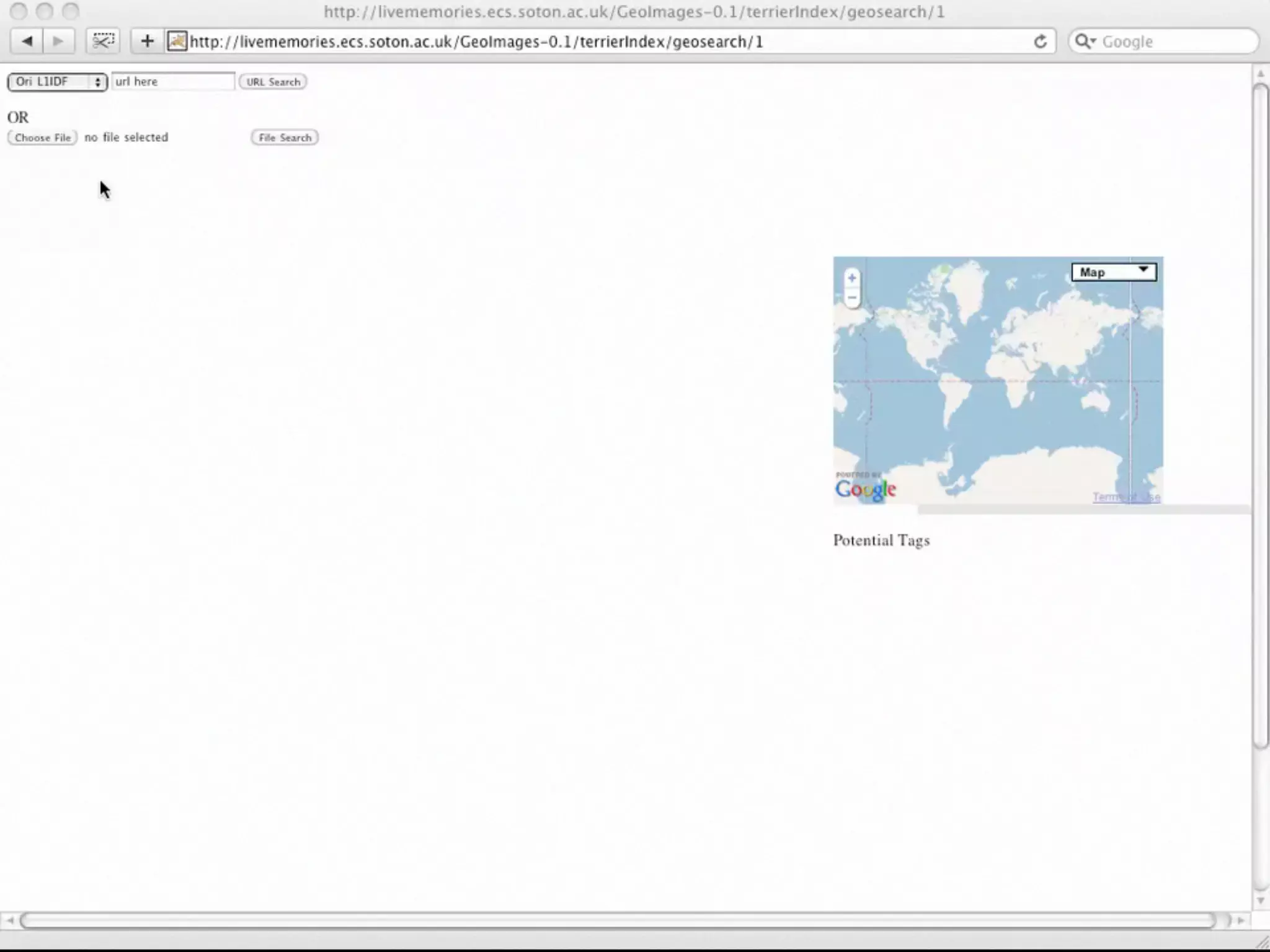
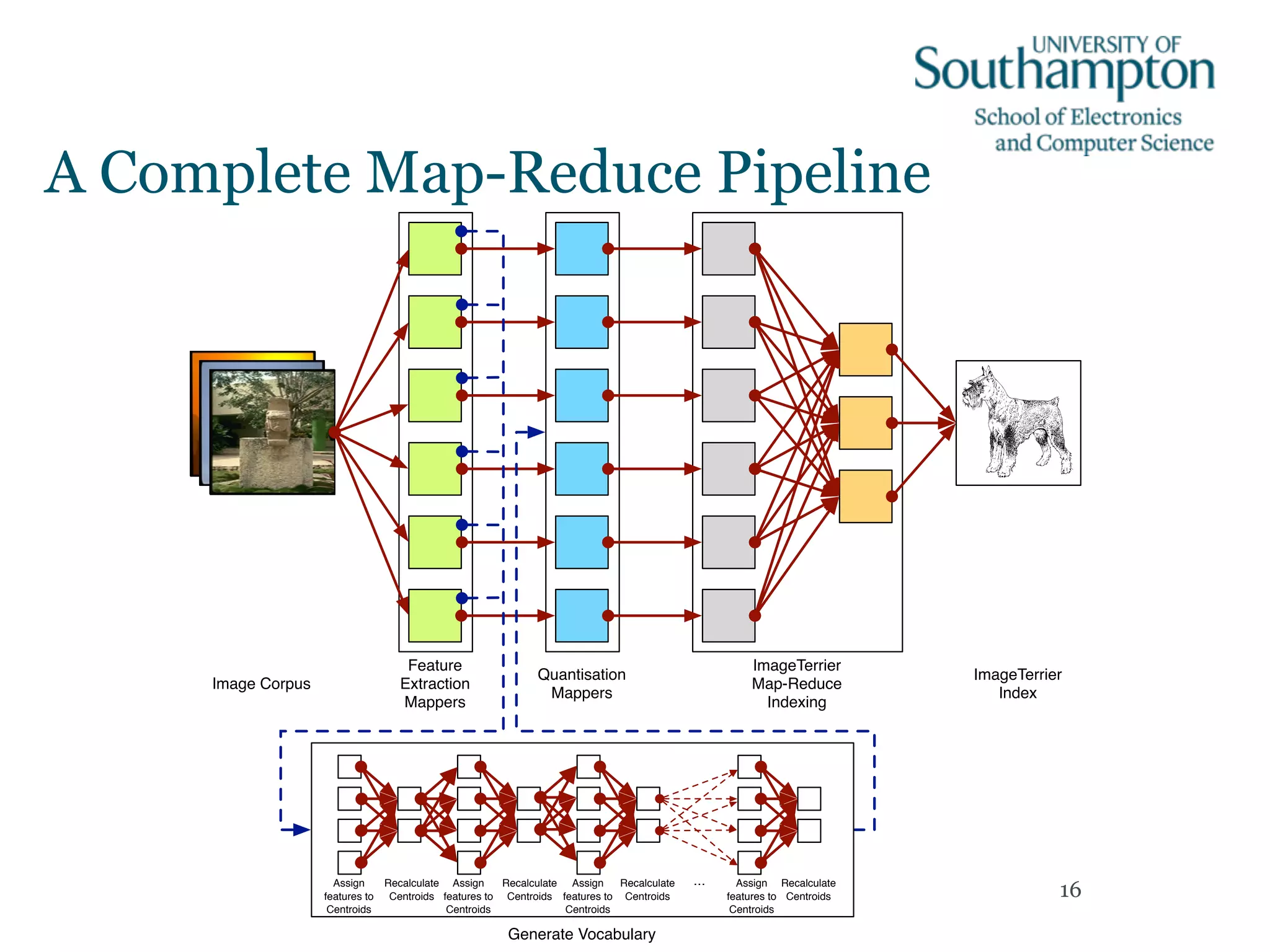
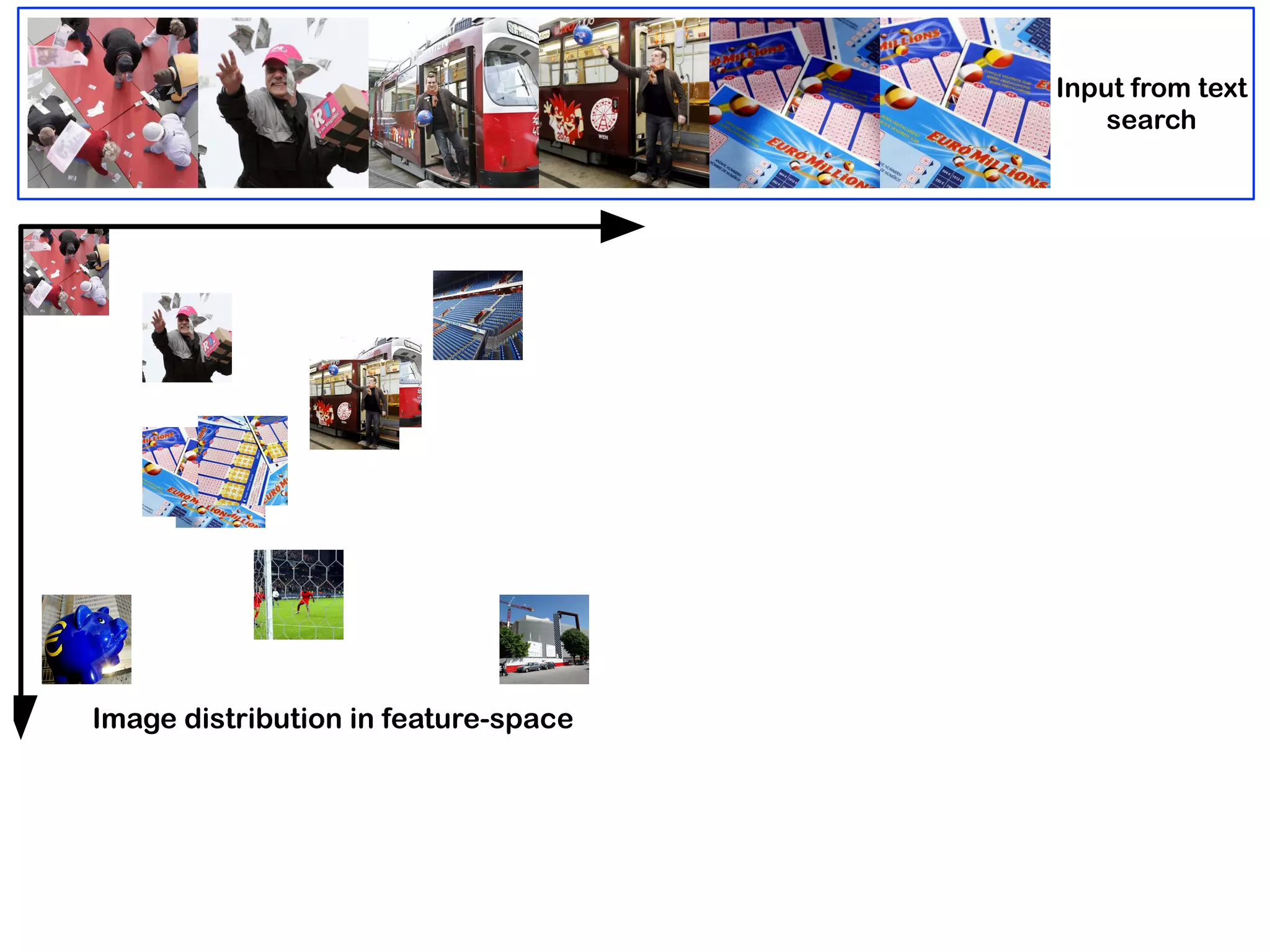
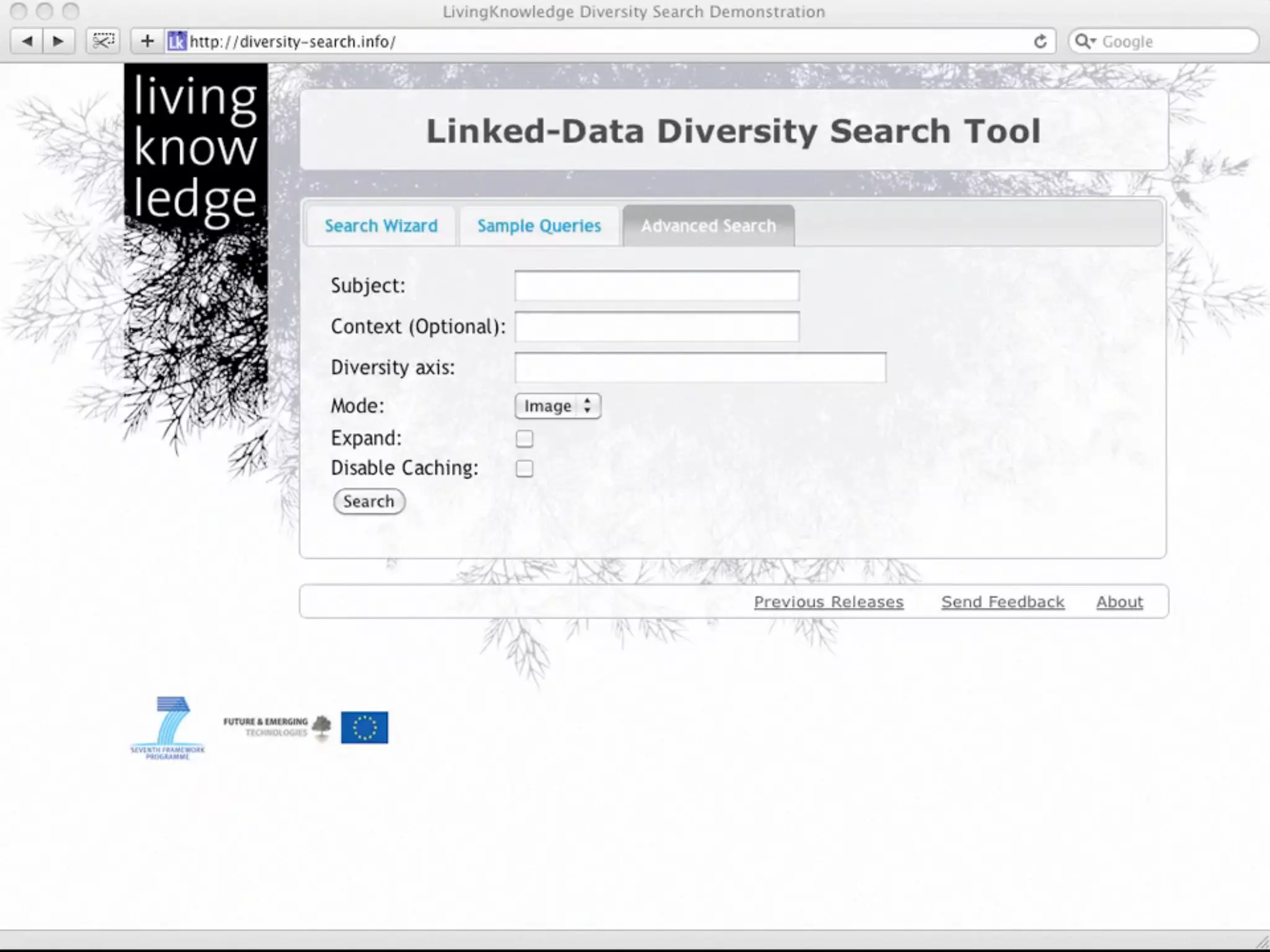
Downloaded 15 times




![Bags-of-visual words
In the computer vision community over recent years it has
become popular to model the content of an image in a
similar way to a “bag-of-terms” in textual document
analysis.
The quick brown
fox jumped over
the lazy dog!
Tokenisation
Stemming/Lemmatisation
Count Occurrences
Local Feature Extraction
Feature Quantization
Count Occurrences
brown dog fox jumped lazy over quick the
1 1 1 1 1 1 1 2[ ] 1[ 2 0 0 6 ]
The quick brown
fox jumped over
the lazy dog!](https://image.slidesharecdn.com/glasgowseminar20110221-150129120247-conversion-gate01/75/Searching-Images-Recent-research-at-Southampton-5-2048.jpg)

![Clustering features into
vocabularies
• A typical image may have a few thousand local features.
• For indexing images, the number of discrete visual terms is
large (i.e. around 1 million terms).
–Smaller vocabularies are typically used in classification
tasks.
–Building vocabularies using k-means is hard:
• i.e. 1M clusters, 128-dimensional vectors, >>>10M
samples.
• Special k-means variants developed to deal with this
(perhaps! - see next slide) [i.e. AKM (Philbin et al, 2007),
HKM (Nistér and Stewénius, 2006)].
• Other tricks can also be applied by exploiting the shape of
the space in the vectors can lie. 7](https://image.slidesharecdn.com/glasgowseminar20110221-150129120247-conversion-gate01/75/Searching-Images-Recent-research-at-Southampton-7-2048.jpg)



























![Positive
GCH
NegativePositive
LCH
NegativePositive
SIFT
Negative
Figure 4: Images classified as positive and negative based on the three features: GCH, LCH, an
discover image features that are most correlated with sen-
timents. For each feature, we computed the MI value with
features appear to be biased away from the far
image plane.
SW 294,559 199,370 493,929
SWN-avg-0.00 316,089 238,388 554,477
SWN-avg-0.10 260,225 190,012 450,237
SWN-avg-0.20 194,700 149,096 343,796
RND 293,456 292,812 586,268
able 1: Statistics on labeled images in the dataset
0.5
0.6
0.7
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Precision
Recall
Precision at Recall (SW)
0.5
0.6
0.7
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Precision
Recall
Precision at Recall (SWN-avg-0.20)
SIFT
GCH
LCH
GCH+LCH
GCH+SIFT
LCH+SIFT
RND
5
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
Precision at Recall (SWN-avg-0.20)
SIFT
GCH
LCH
GCH+LCH
GCH+SIFT
LCH+SIFT
RND
Classification results for sentiment assign-
W and SWN-avg- with = 0.20 for training
00 photos per category
an SVM model on these labeled data and tested
maining labeled data. For testing, we chose an
ber of positive and negative test images, with at
0 of each kind. We used the SVMlight [17] imple-
of linear support vector machines (SVMs) with
arameterization in our experiments, as this has
Classification Experiments
30
Binary classification experiments
using a linear SVM.
100,000 training images (50:50).
35,000 test images.](https://image.slidesharecdn.com/glasgowseminar20110221-150129120247-conversion-gate01/75/Searching-Images-Recent-research-at-Southampton-40-2048.jpg)



The document discusses recent advancements in content-based image searching undertaken by researchers at Southampton, particularly addressing image feature representation, scalability through map-reduce techniques, and diversification in search results. It highlights the development of 'imageterrier', a search engine built on Terrier, which improves indexing and searching capabilities for large datasets of geo-tagged images. Additionally, it explores classifying images by sentiment to enhance search results and user experience.

























































![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)



