Downloaded 16 times













![Attacking the Gap from
below:Auto-annotation
Lots of techniques proposed, using different descriptor
morphologies (global, region-based [segmented, salient, ...])
Co-occurrence of keywords and image features
Machine translation
Statistical, maximum entropy, ...
Probabilistic methods
Inference networks, density estimation, ...
Latent-spaces
Keyword propagation
Simple classifiers using low level features](https://image.slidesharecdn.com/ei2006presentation-150129143533-conversion-gate01/85/Mind-the-Gap-Another-look-at-the-problem-of-the-semantic-gap-in-image-retrieval-13-320.jpg)





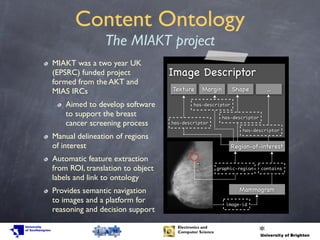


The document examines the semantic gap in image retrieval, which is the disconnect between automatic feature extraction from visual data and user interpretation. It discusses various approaches to bridge this gap, including auto-annotation and the use of ontologies, emphasizing the importance of user queries in retrieval systems. Future research directions are proposed, focusing on enhancing semantic spaces and incorporating ontology-based reasoning to improve image search methodologies.












































































