Download to read offline



![Unannotated Imagery
An Example
Kennel club image collection.
relatively small (~60,000 images)
~7000 of those digitised.
~3000 of those have subject metadata (mostly
keywords), remainder have little/no information.
Each year, after the Crufts dog show they expect
to receive additional (digital) images [of the order
of a few 1000] with little, if any metadata, other
than date/time (and only then if the camera is set-
up correctly).](https://image.slidesharecdn.com/brightonsirjh-150129112133-conversion-gate01/85/Spot-the-Dog-An-overview-of-semantic-retrieval-of-unannotated-images-in-the-Semantic-Gap-project-4-320.jpg)



![Visual Term Representations
Bag-of-Terms
For indexing purposes, we often discount order/arrangement
of terms and just count number of occurrences.
The quick
brown fox
jumped over
the lazy dog
brown dog fox jumped lazy over quick the
1 1 1 1 1 1 1 2[ ]1[ 2 0 0 6 ]](https://image.slidesharecdn.com/brightonsirjh-150129112133-conversion-gate01/85/Spot-the-Dog-An-overview-of-semantic-retrieval-of-unannotated-images-in-the-Semantic-Gap-project-8-320.jpg)














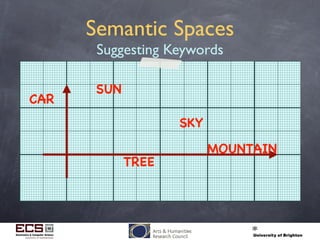
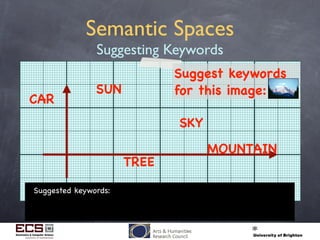
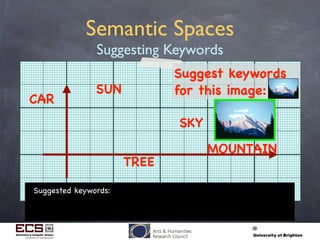
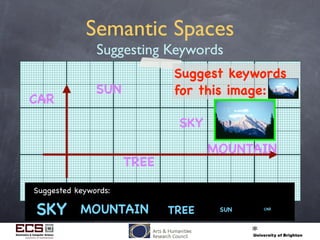








This document discusses using computational techniques to semantically retrieve unannotated images by enabling textual search of imagery without metadata. It describes: 1) Using exemplar image/metadata pairs to learn relationships between visual features and metadata, then projecting this to retrieve unannotated images. 2) Representing images as "visual terms" like words in text. 3) Creating a multidimensional "semantic space" where related images, terms and keywords are placed closely together based on training. This allows retrieving unannotated images that lie near descriptive keywords. 4) Experimental retrieval results on a Corel dataset, showing the approach works better for keywords associated with colors than others. The approach takes progress but significant challenges remain.

























































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)








