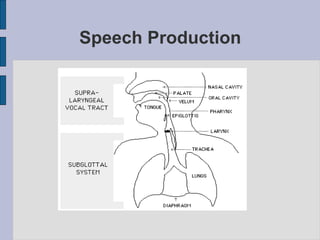
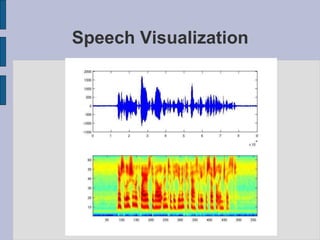
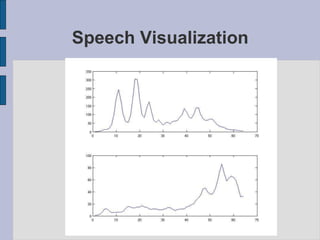
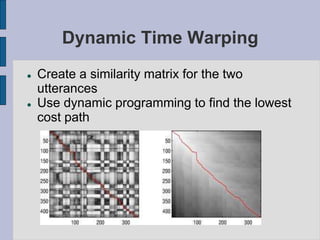
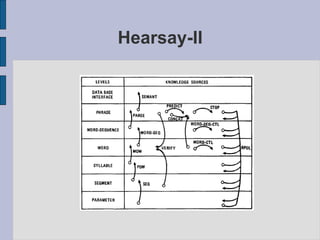
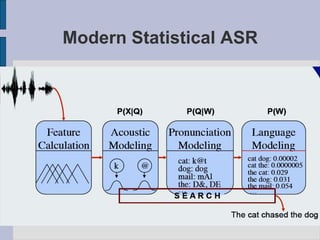
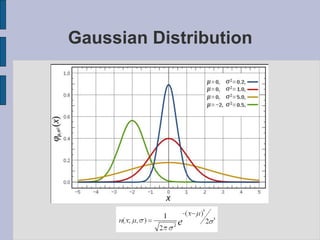
This document provides an introduction to automatic speech recognition (ASR). It begins by defining the ASR problem and factors that influence it, such as microphones, noise, speakers and languages. It then discusses how speech is produced and represented with features. The document reviews early ASR systems and modern statistical approaches using Hidden Markov Models, acoustic models, pronunciation and language models. It concludes by noting the current capabilities and limitations of ASR technology and potential areas of future work.