Downloaded 71 times



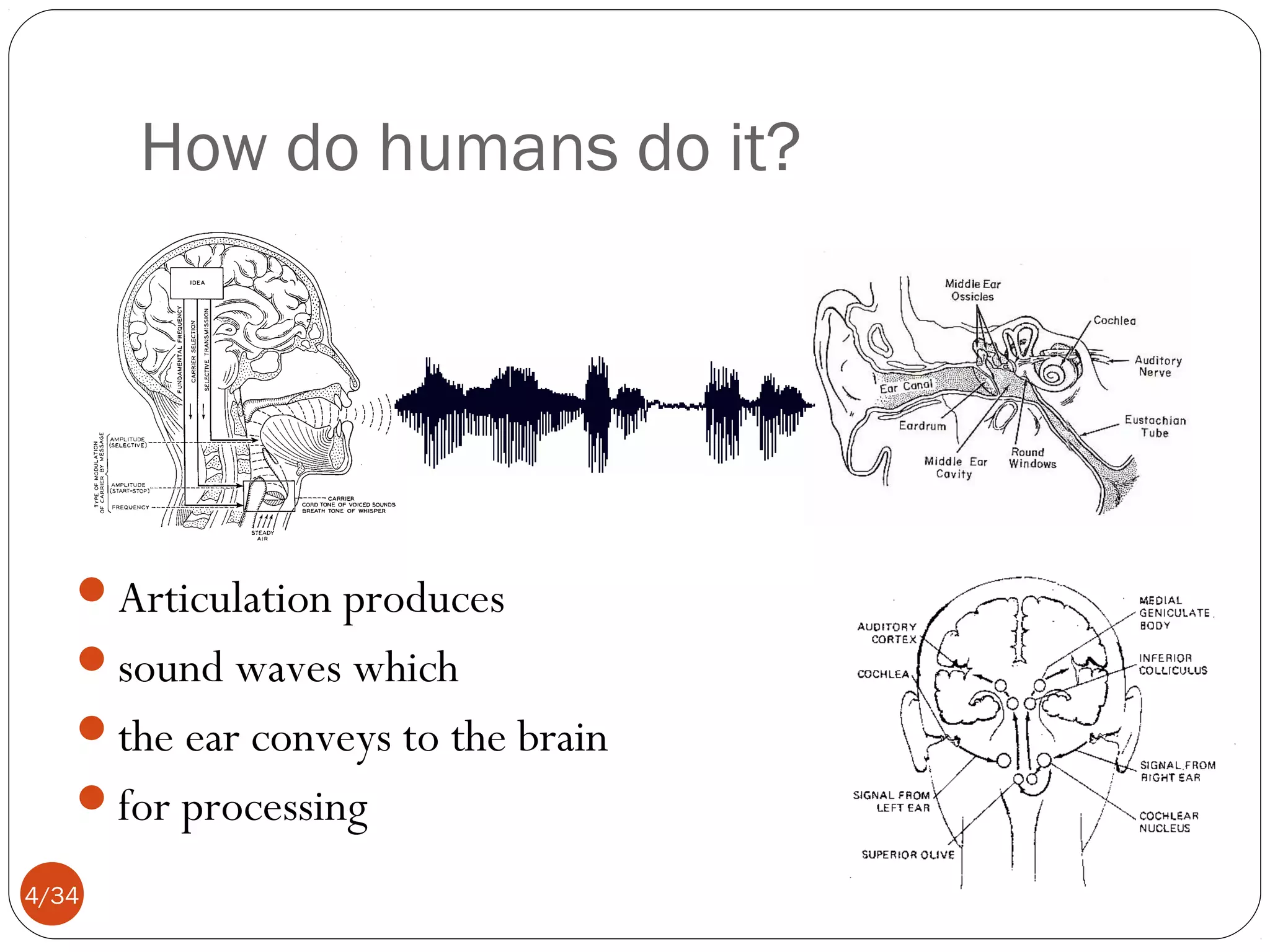























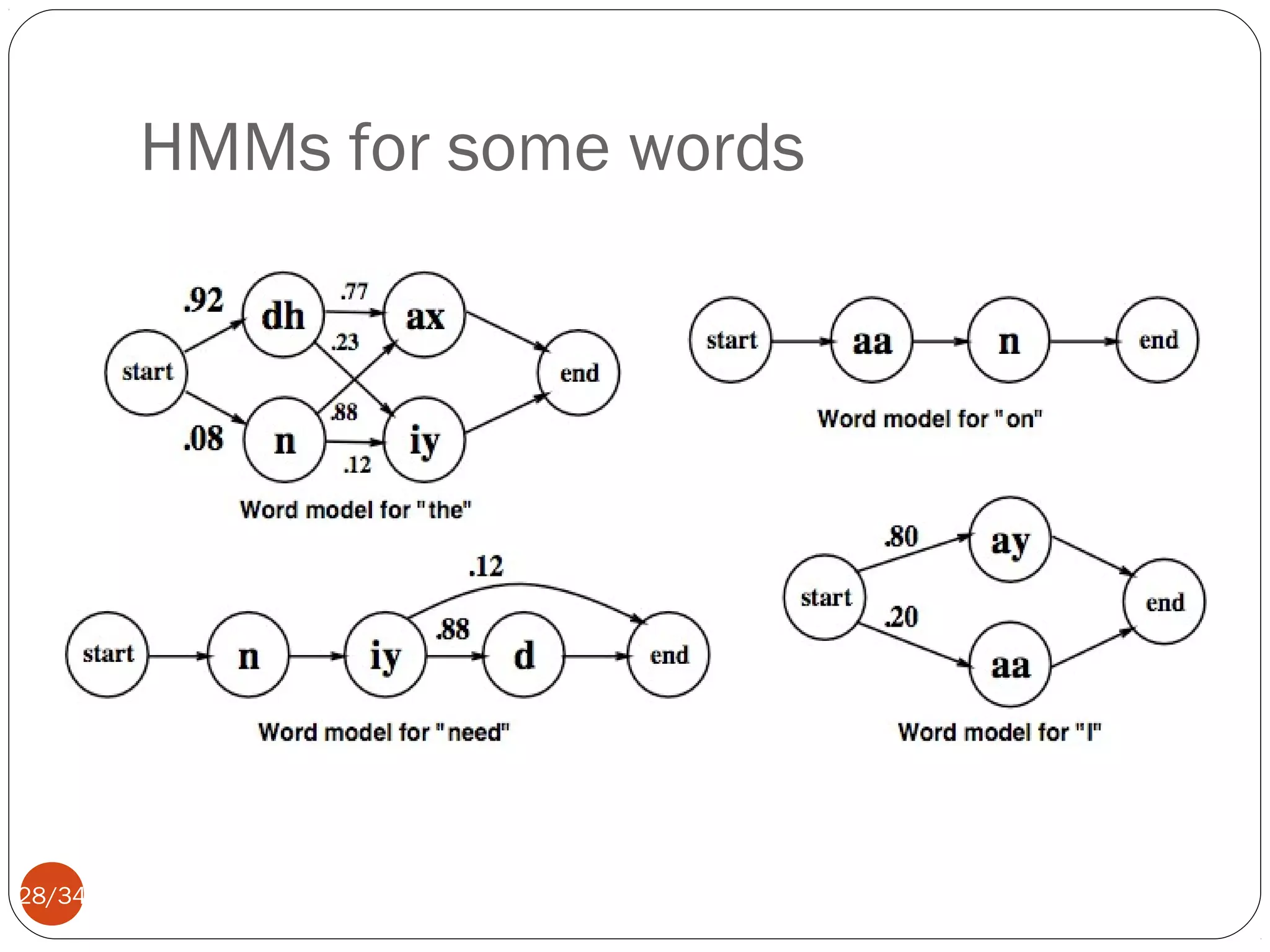

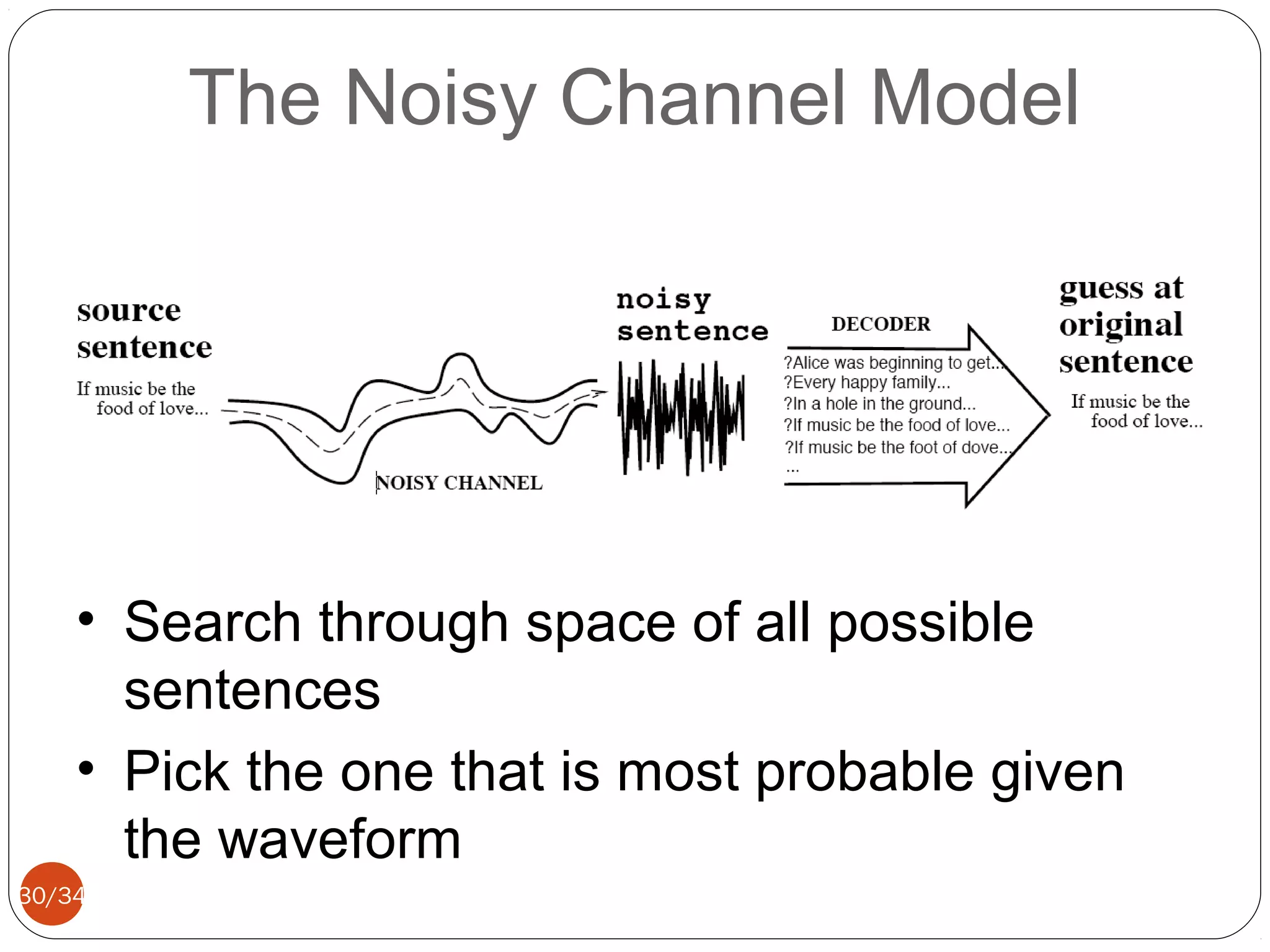





This document discusses automatic speech recognition, including defining the task, the main challenges, and common approaches. The key difficulties identified are digitizing speech, separating speech from noise, dealing with variability between individuals, identifying phonemes, disambiguating homophones, handling continuous speech, and interpreting prosodic features. Common approaches are template matching, rule-based systems, and statistical/machine learning methods like hidden Markov models. Remaining challenges include robustness, adaptability, language modeling, and handling spontaneous speech.























































































