Downloaded 128 times



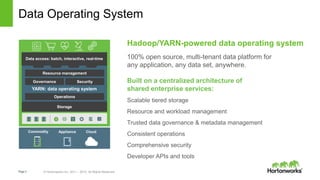
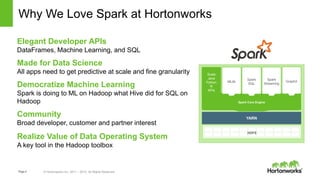


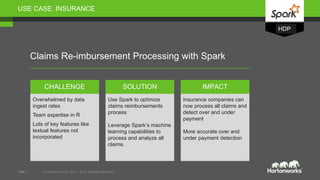
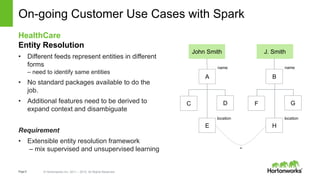


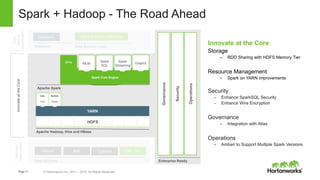
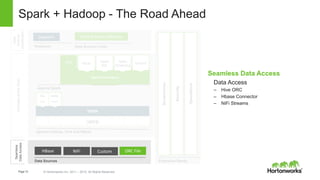
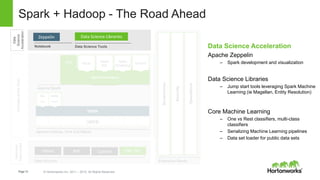







Spark and Hadoop are perfectly together. Spark is a key tool in Hadoop's toolbox that provides elegant developer APIs and accelerates data science and machine learning. It can process streaming data in real-time for applications like web analytics and insurance claims processing. The future of Spark and Hadoop includes innovating the core technologies, providing seamless data access across data platforms, and further accelerating data science tools and libraries.






















































































