Downloaded 26 times



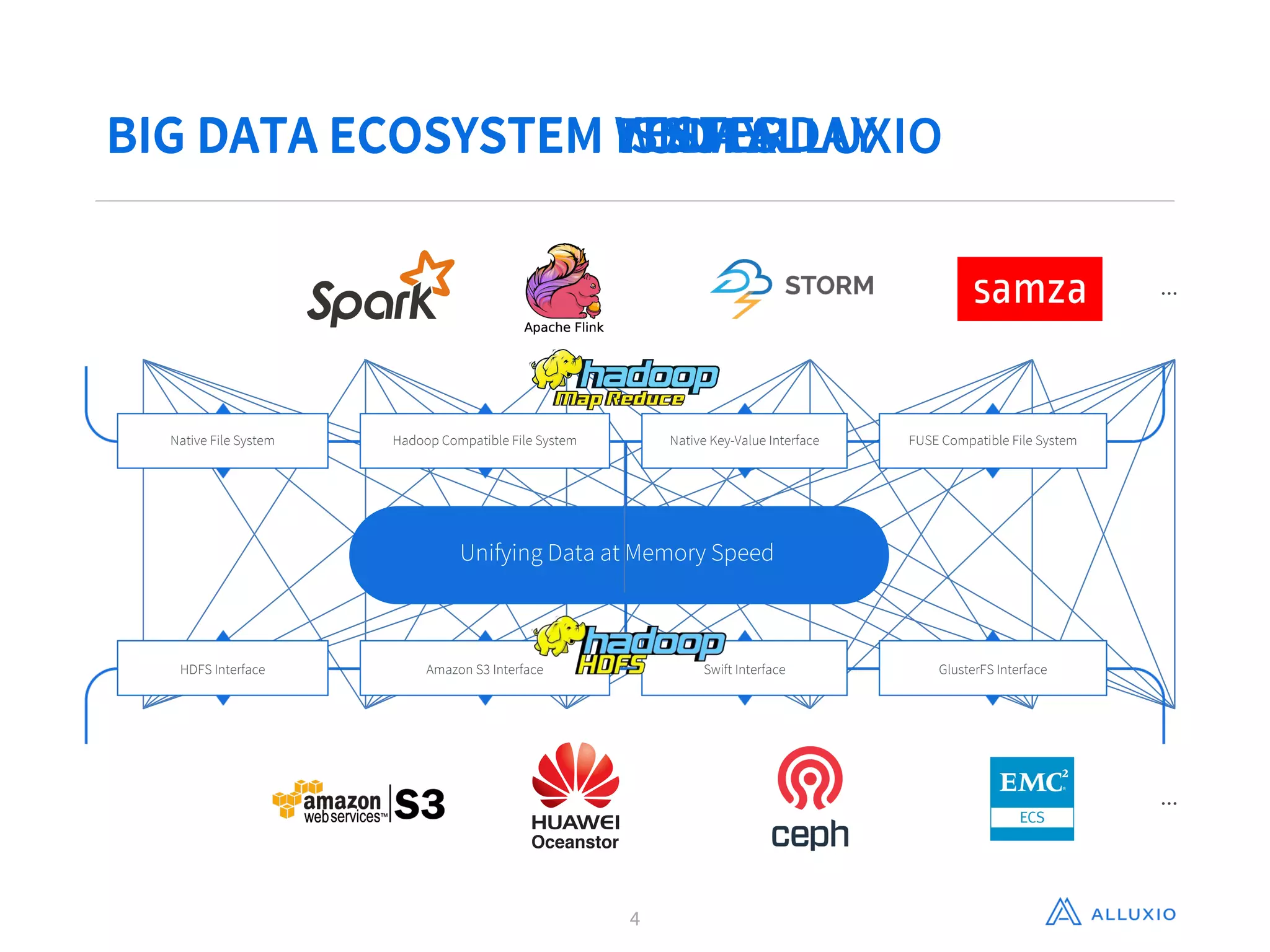
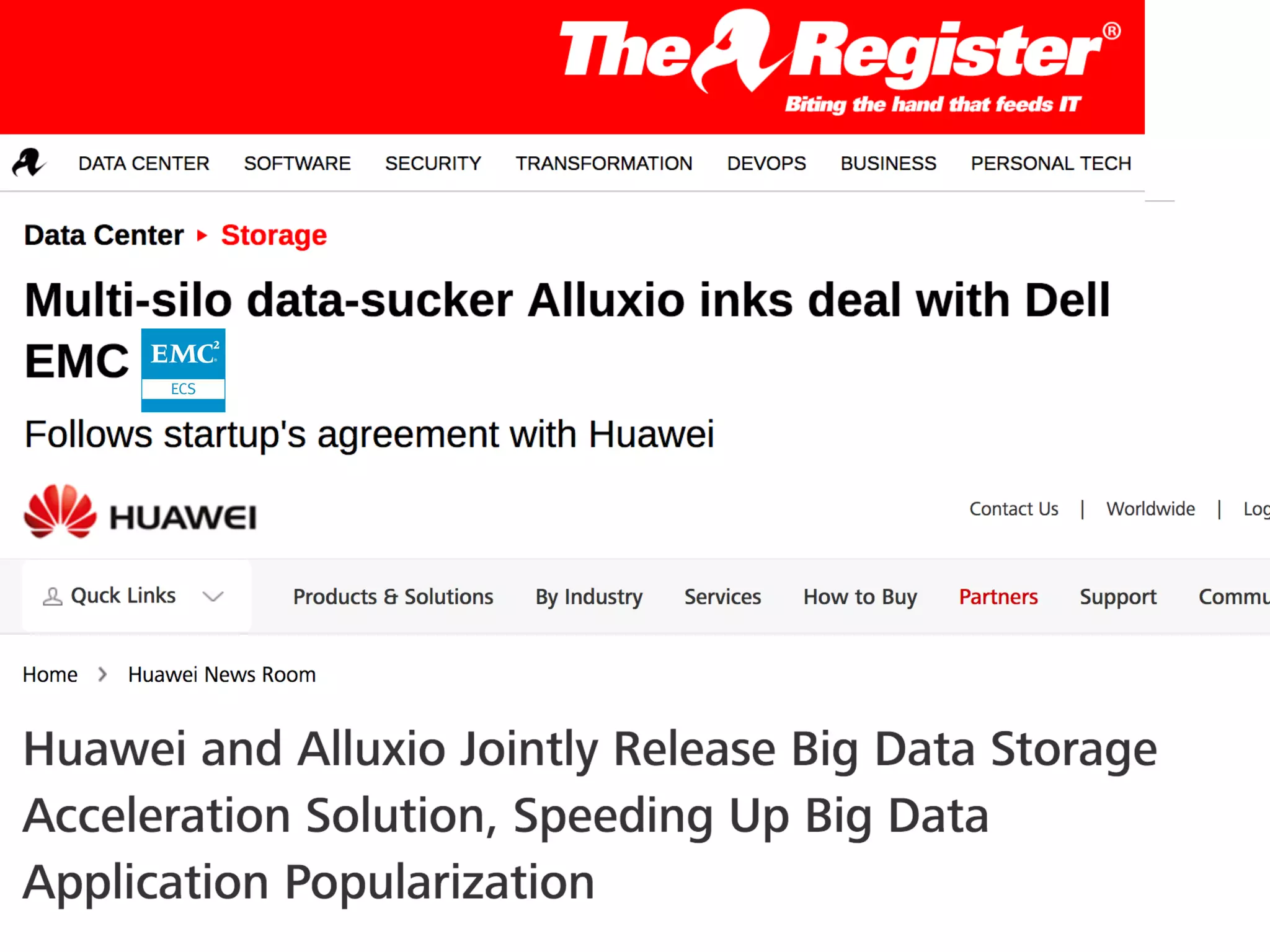
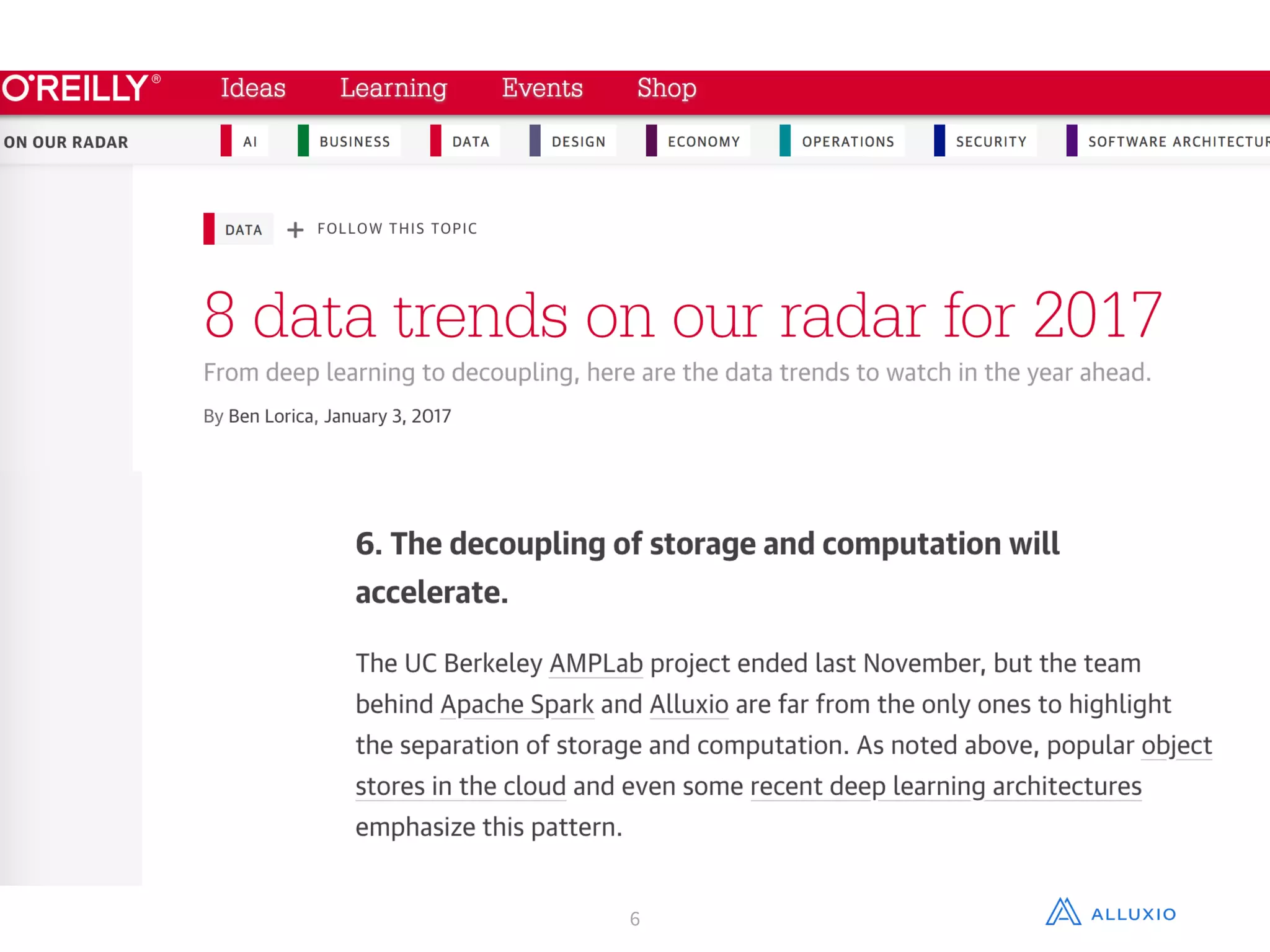
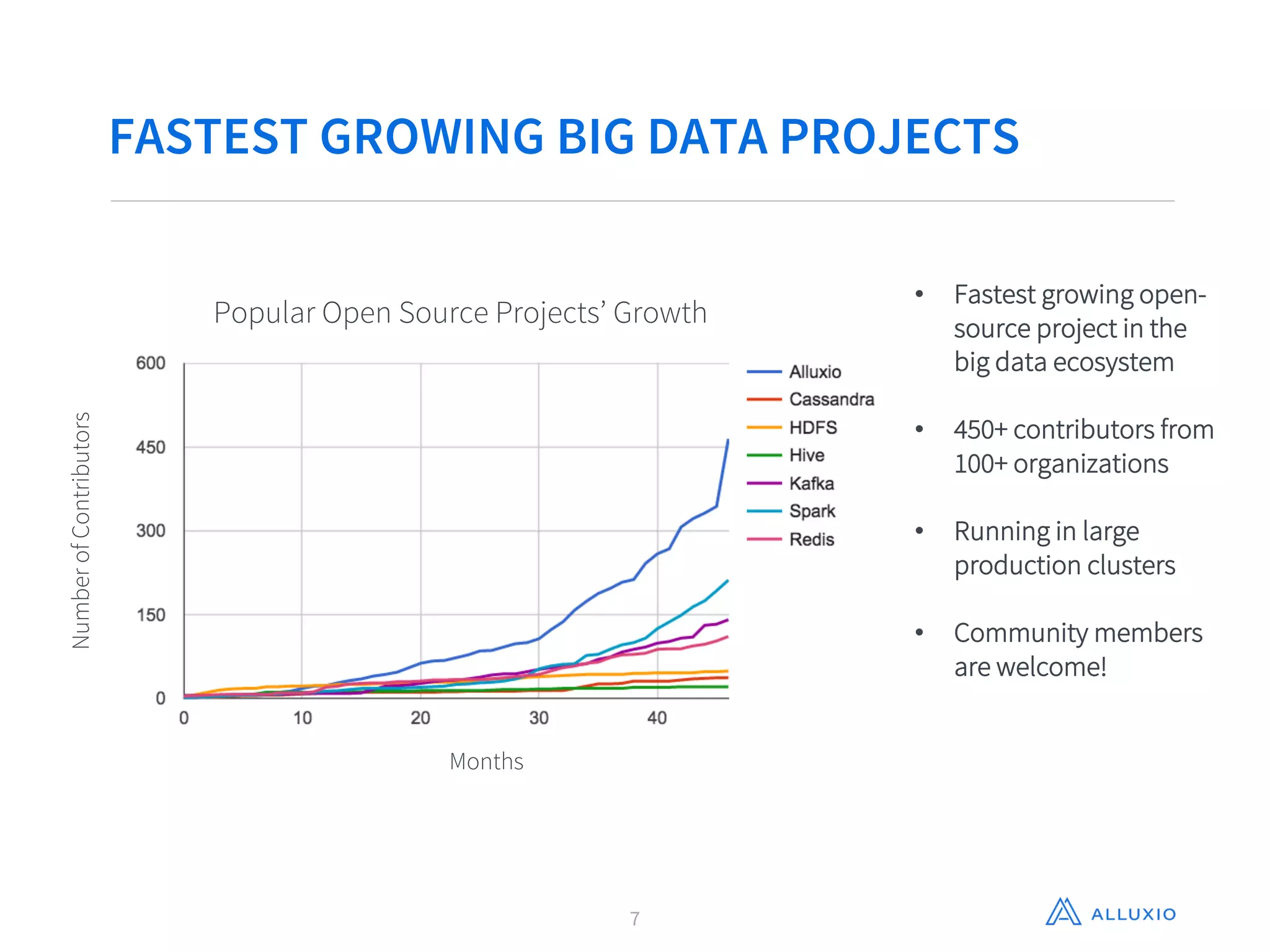


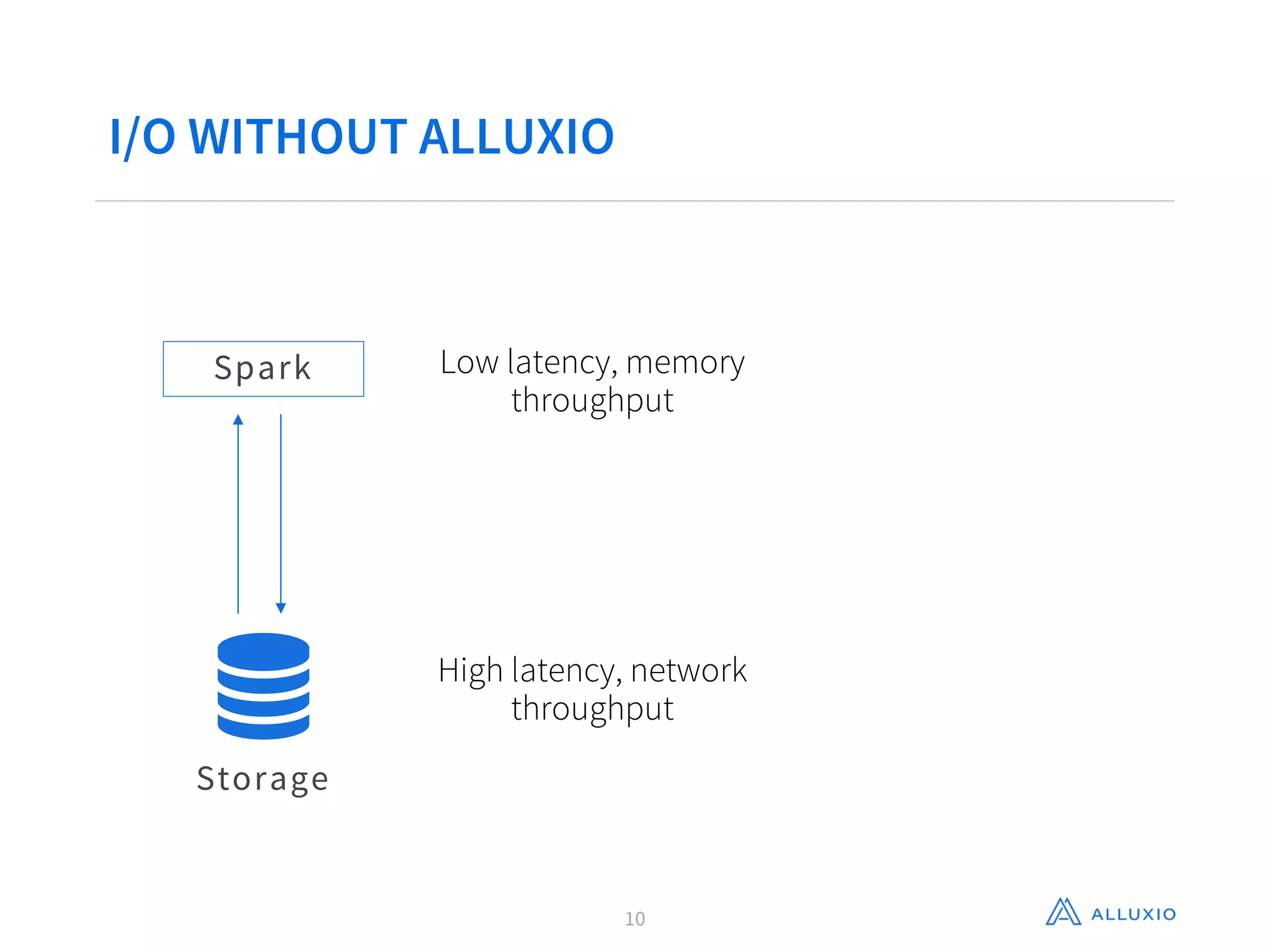
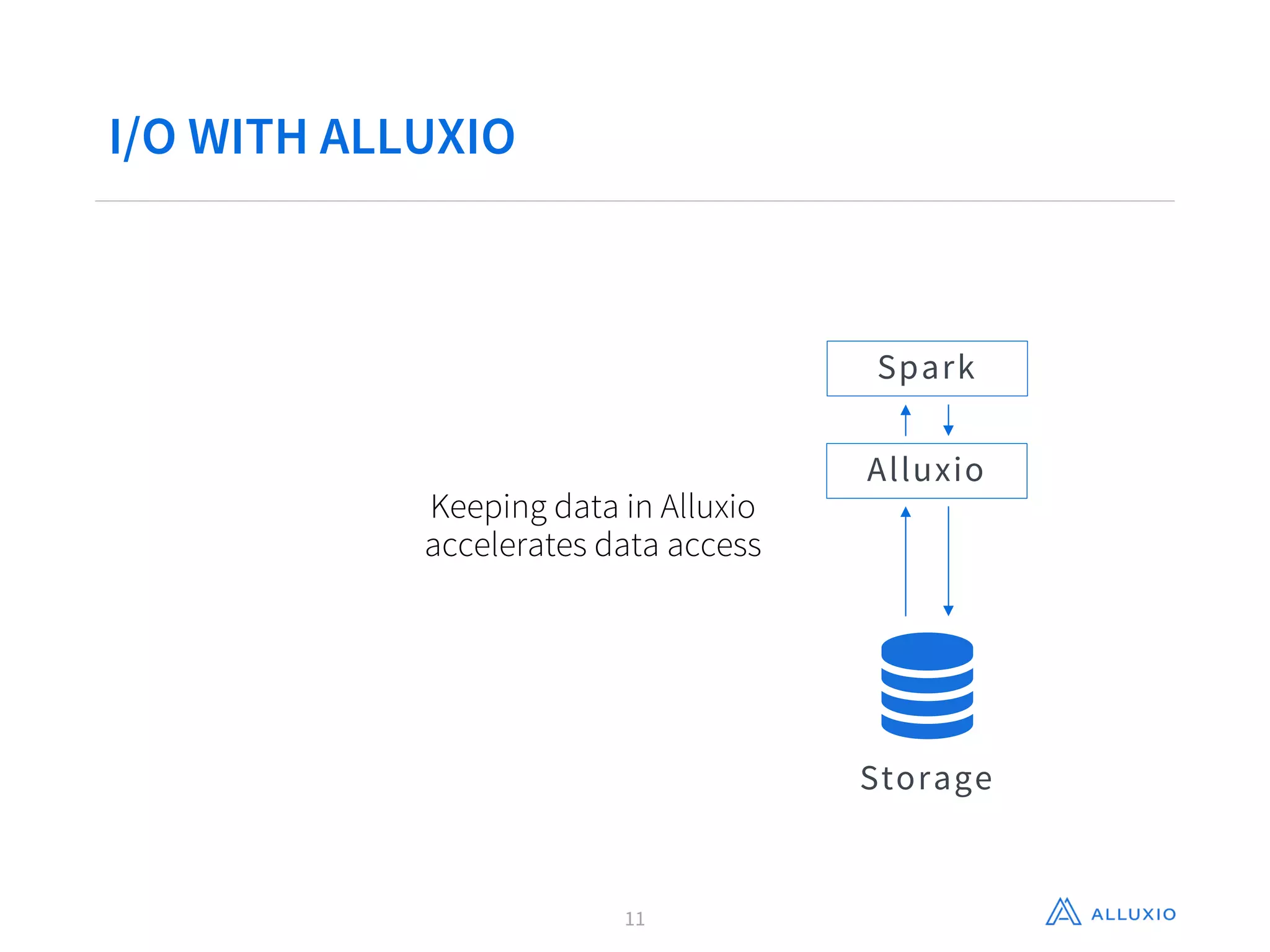


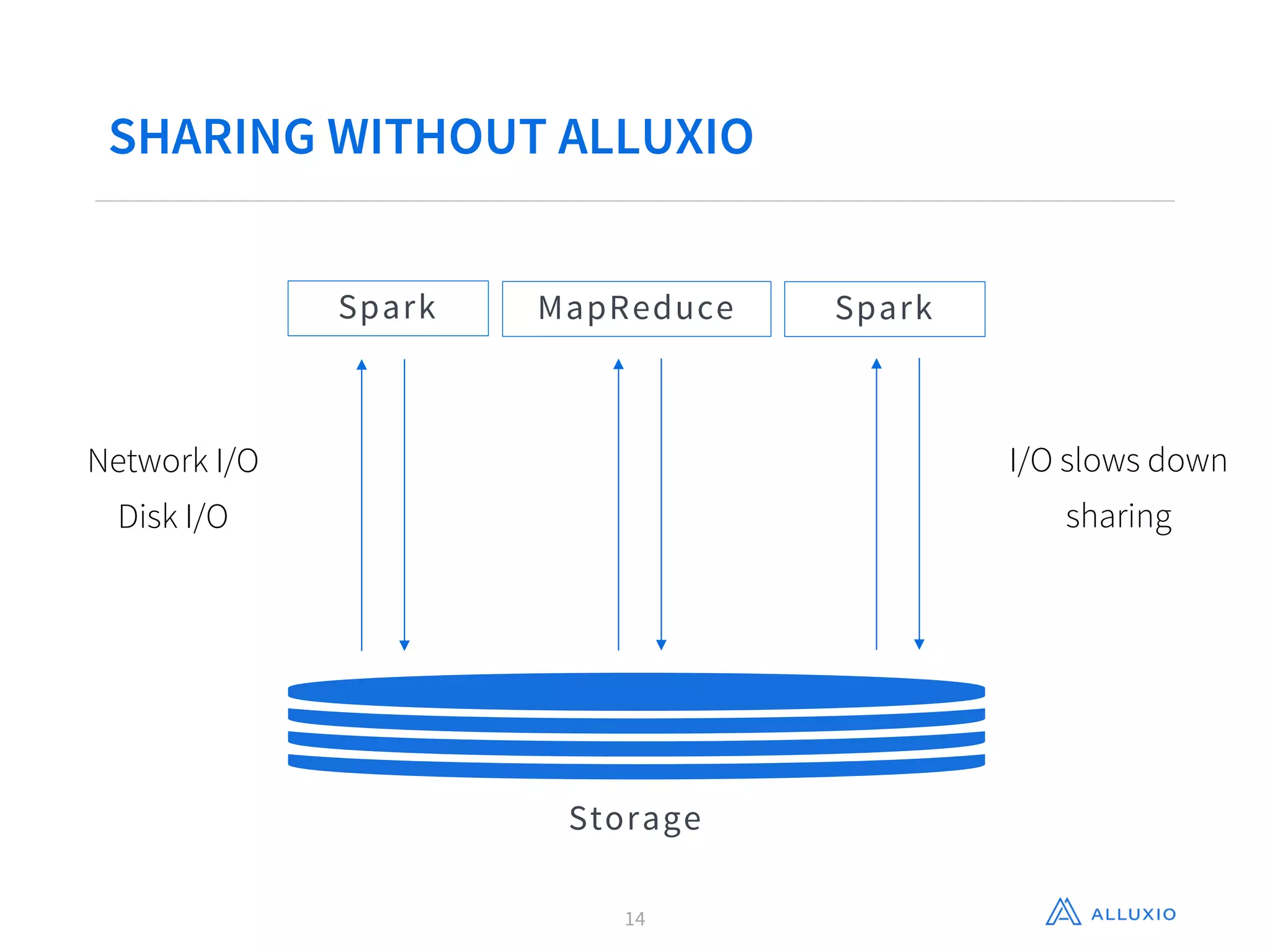
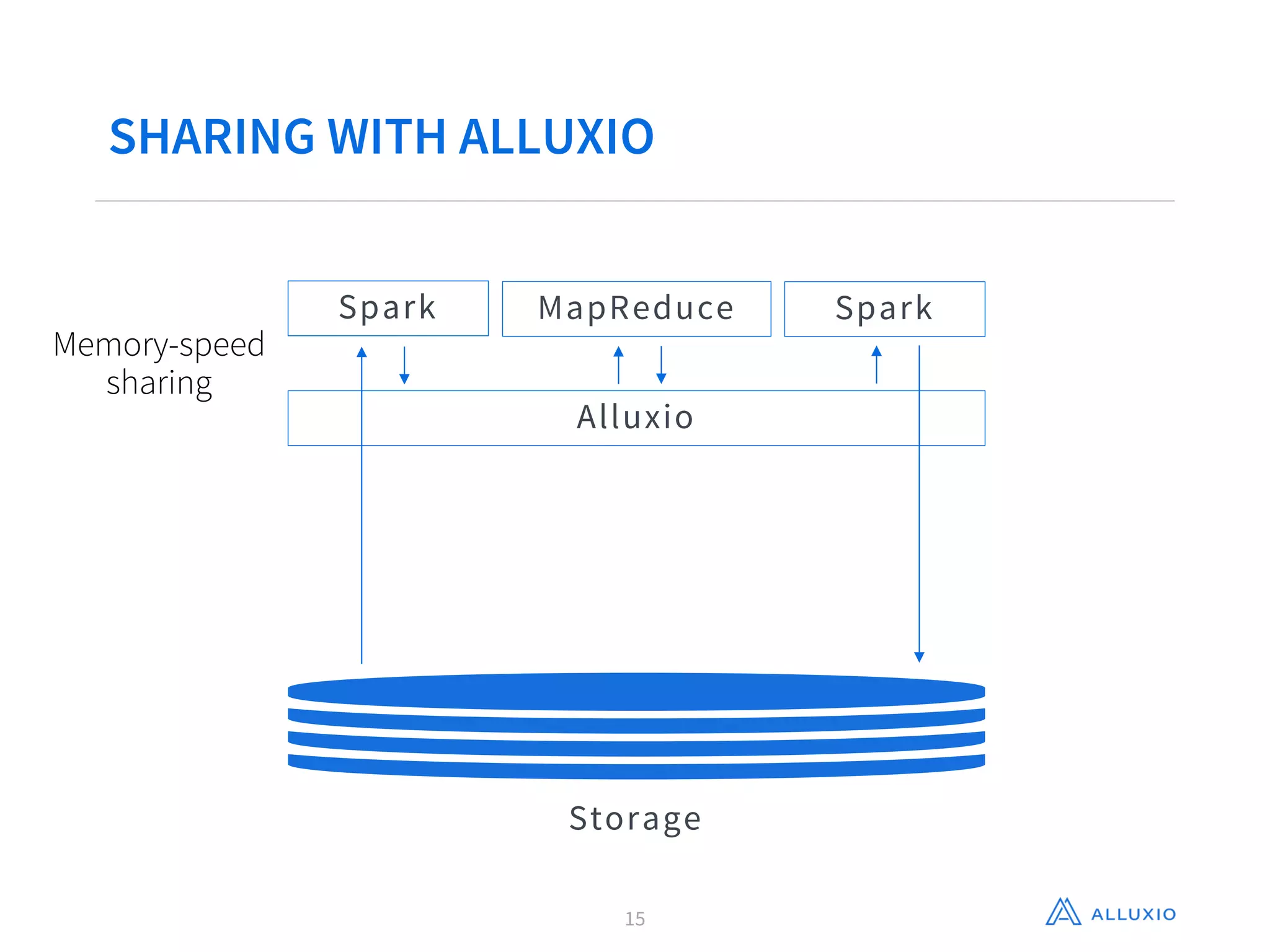


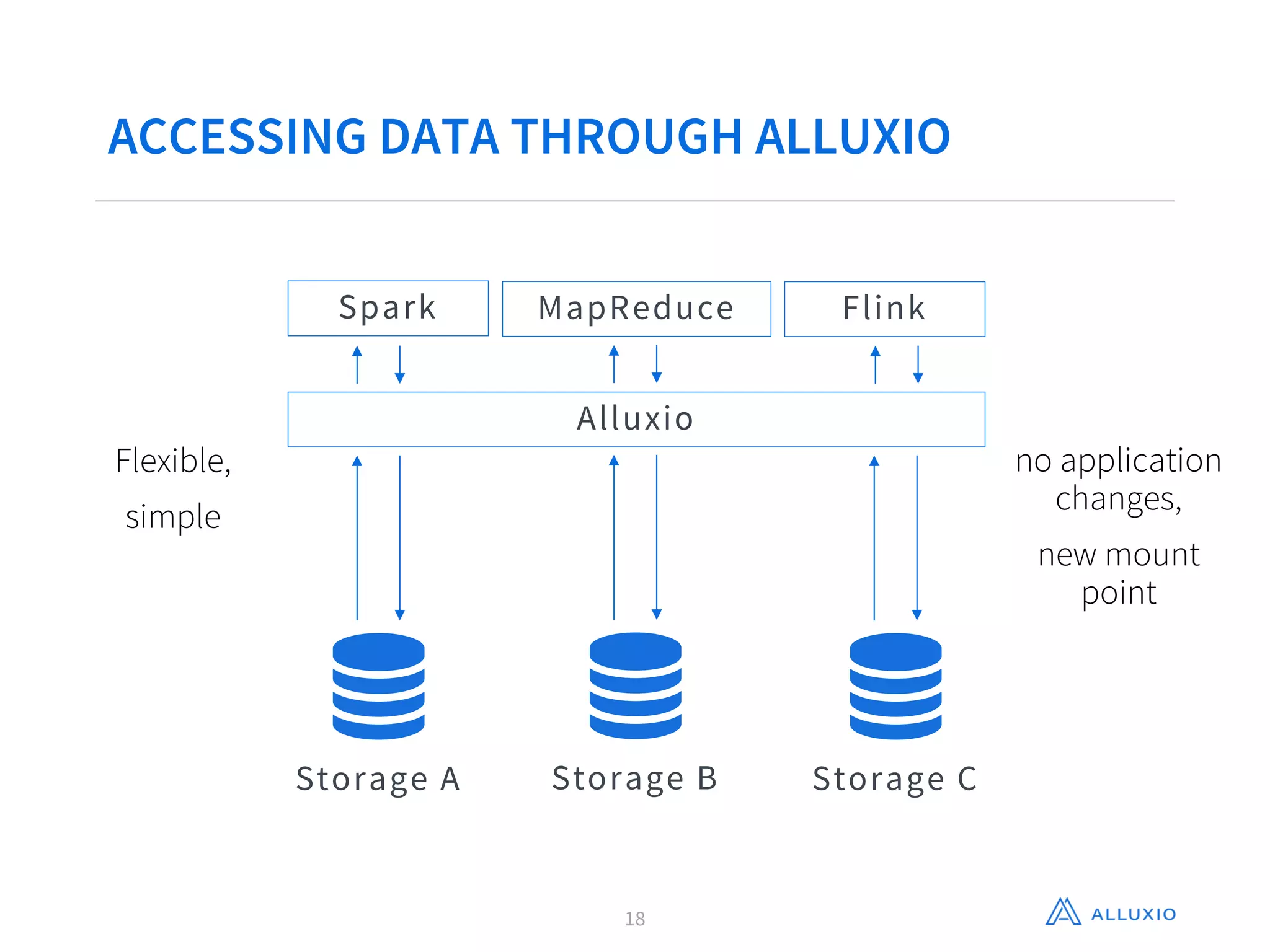


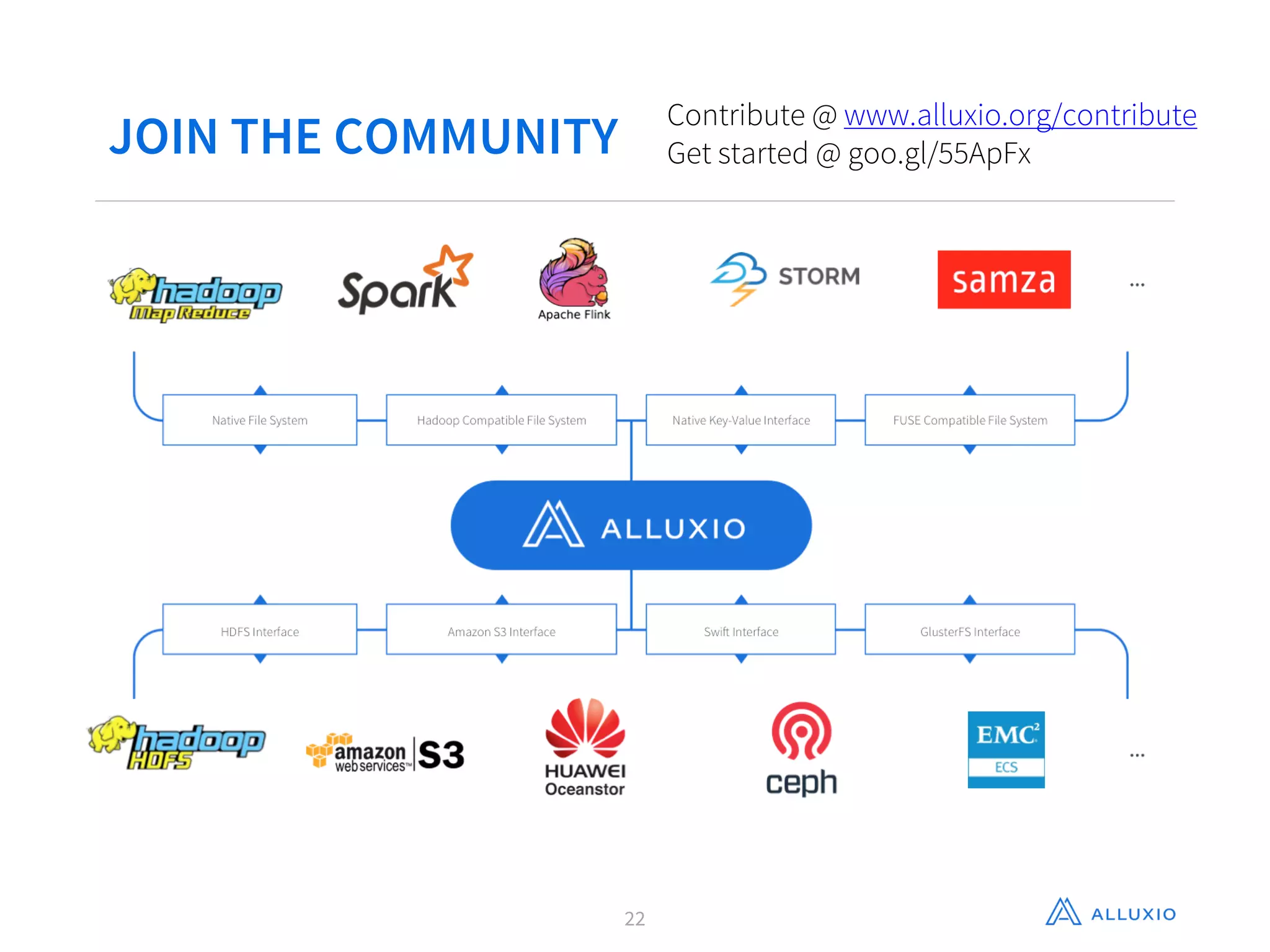

Gene Pang of Alluxio, Inc presented on Alluxio, an open source project that provides unified access to data across storage systems at memory speed. Alluxio allows data to be accessed locally or from remote Alluxio nodes, accelerating data access by up to 30x for companies like Baidu. It also enables data sharing between jobs and applications at memory speed instead of disk speed, reducing Barclays' workflow iteration time from hours to seconds. Additionally, Alluxio provides a unified namespace to access data from multiple storage systems like S3, HDFS and NFS through a single interface without changing applications. This feature has improved performance by 15x-300x for companies like Qunar.









































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













