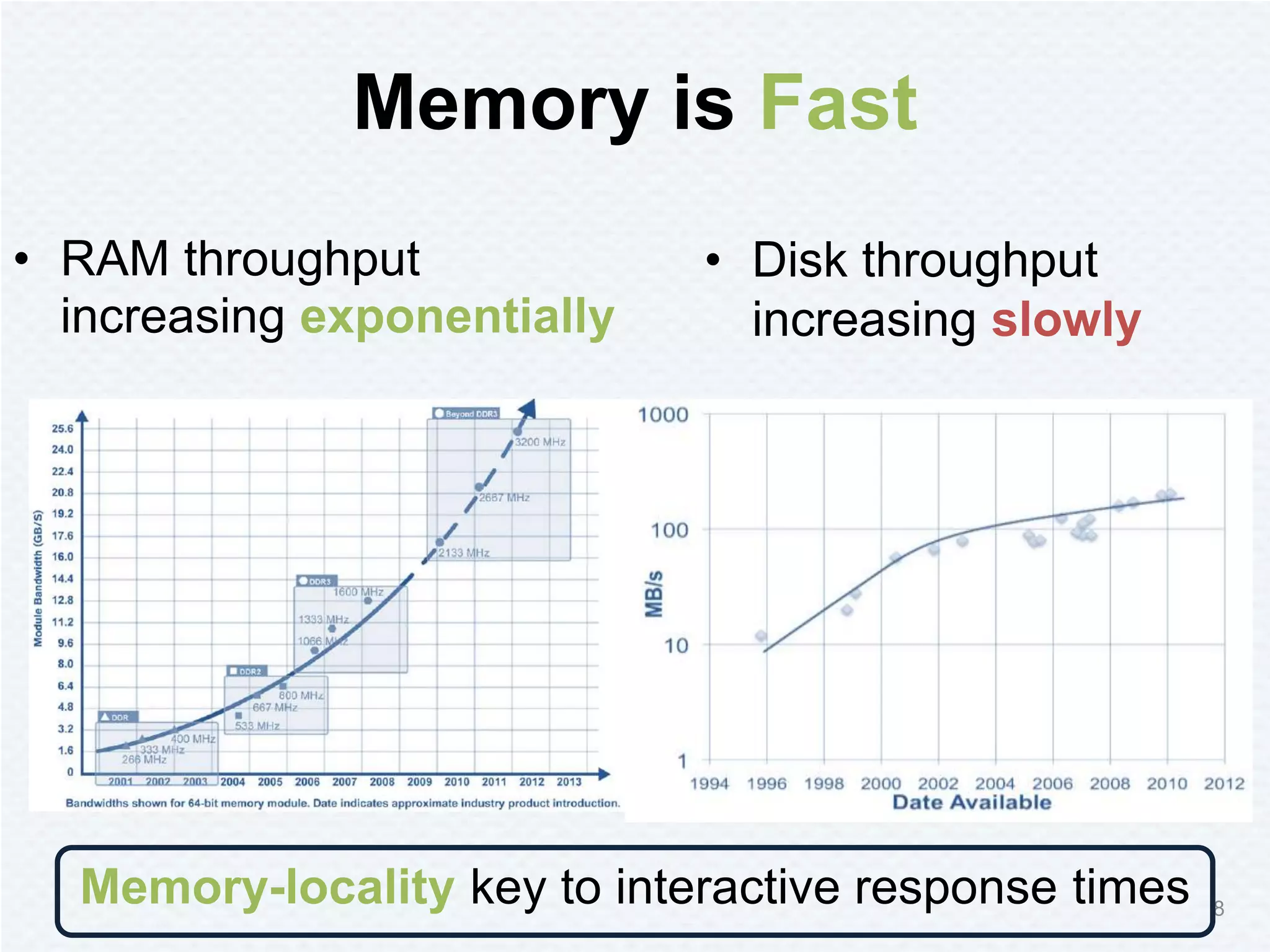
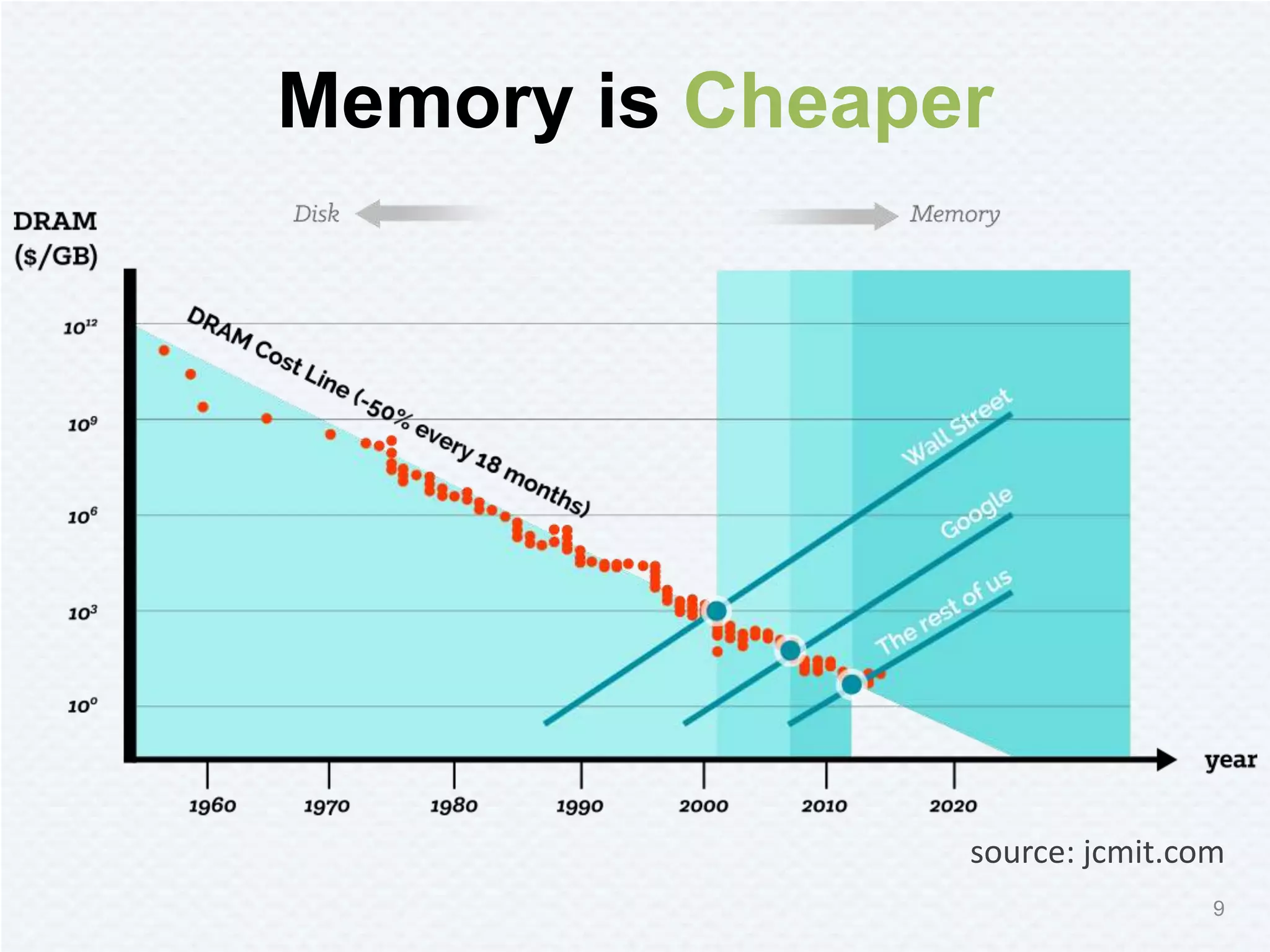
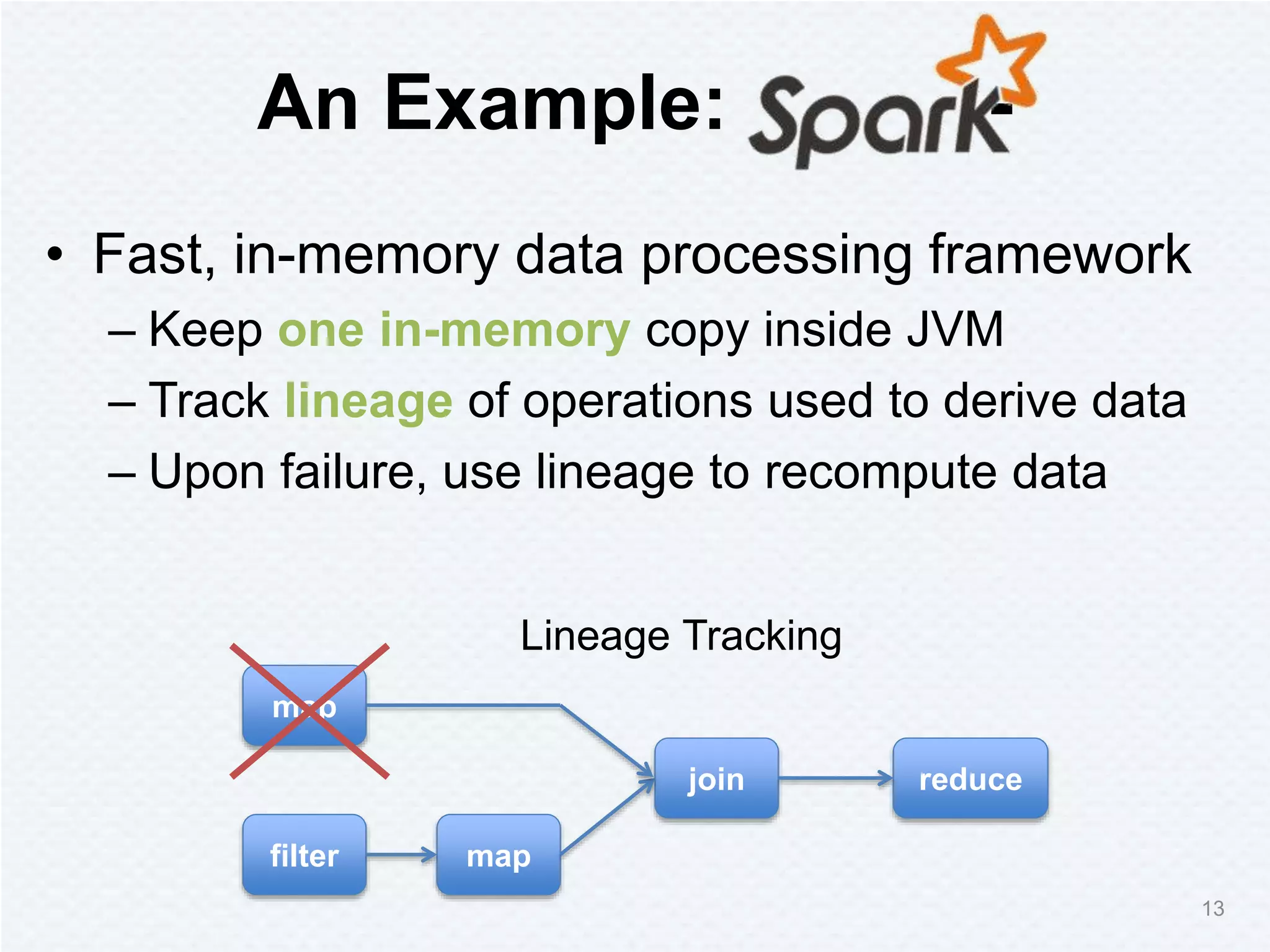
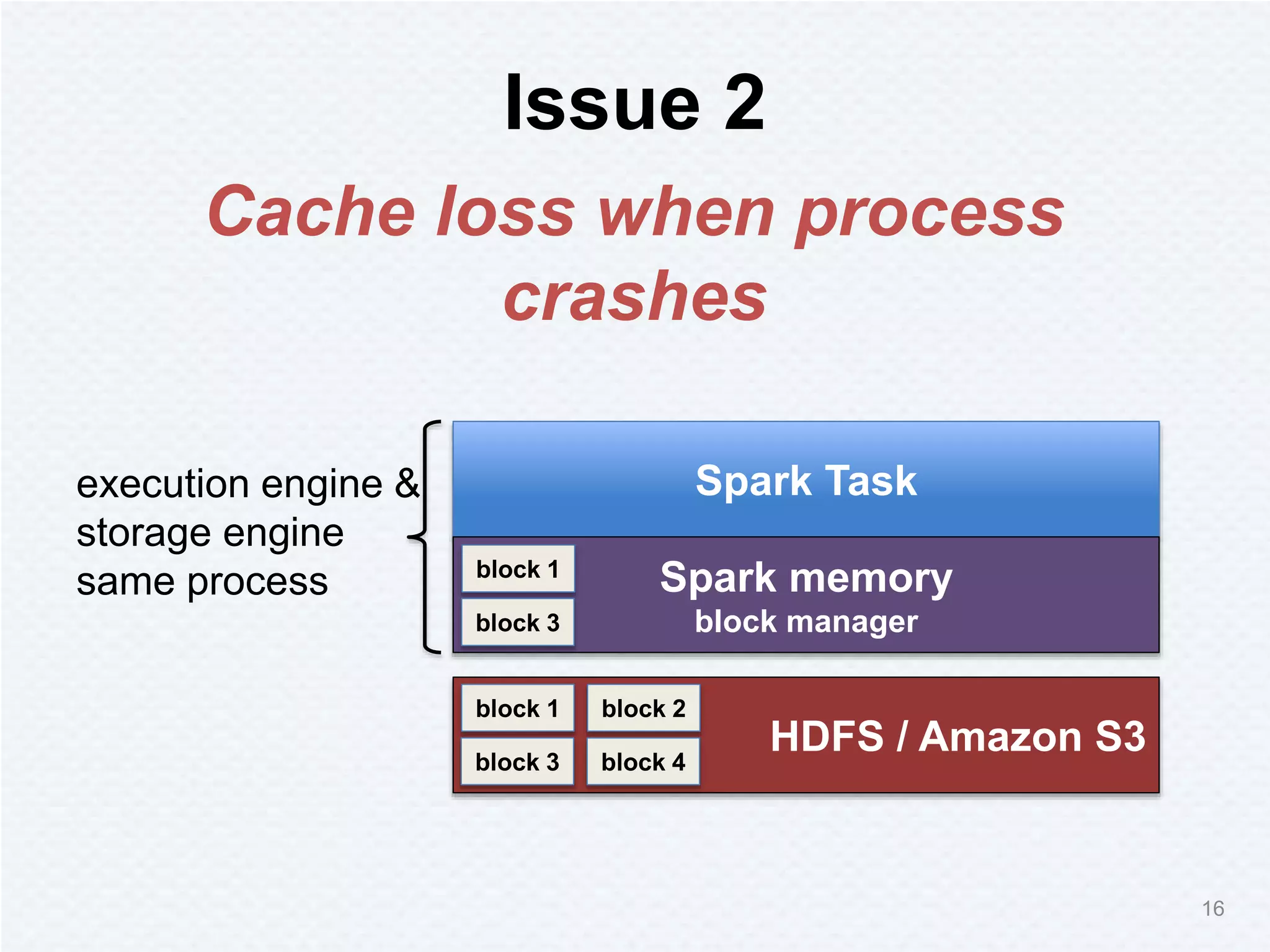
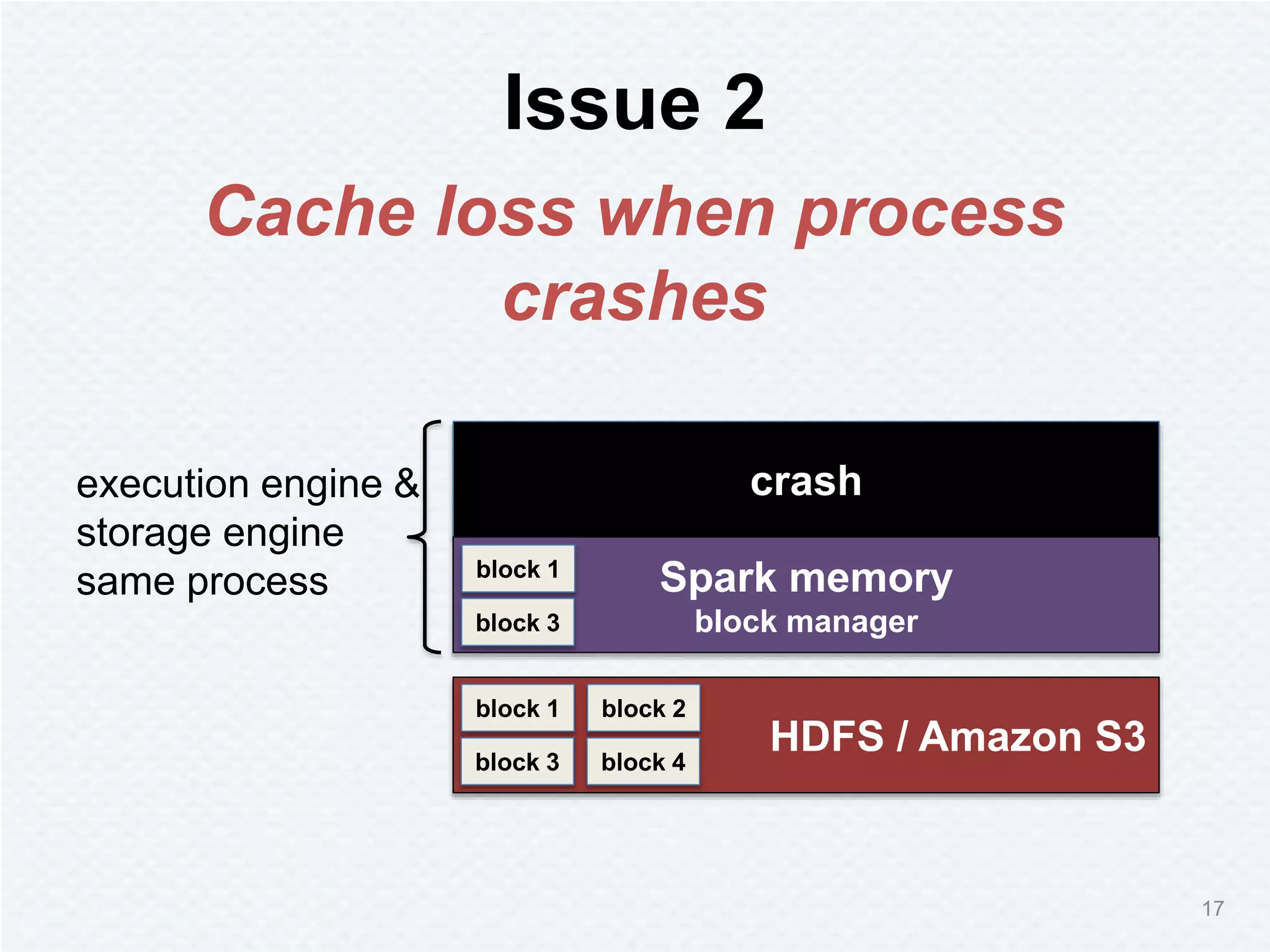
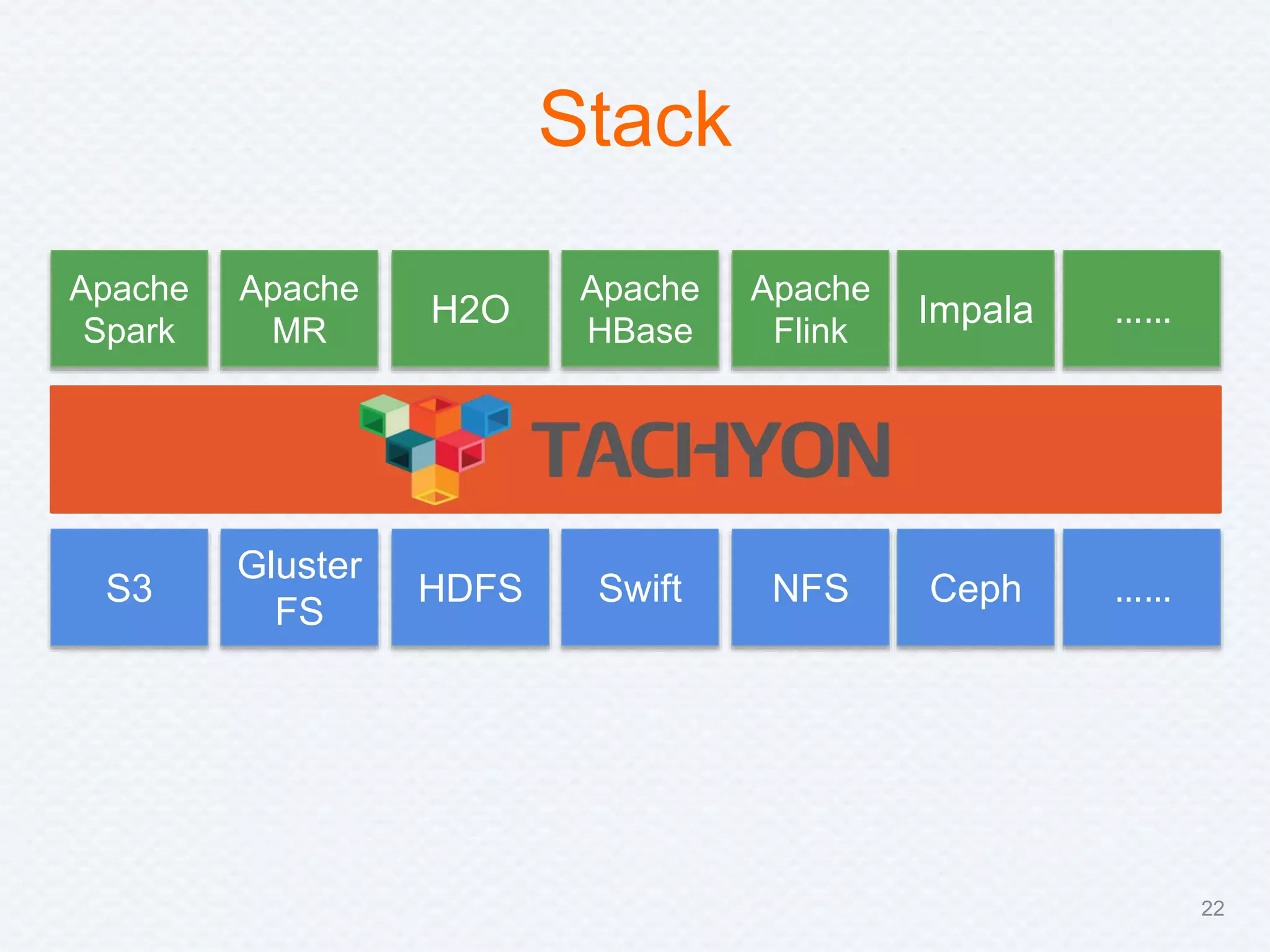
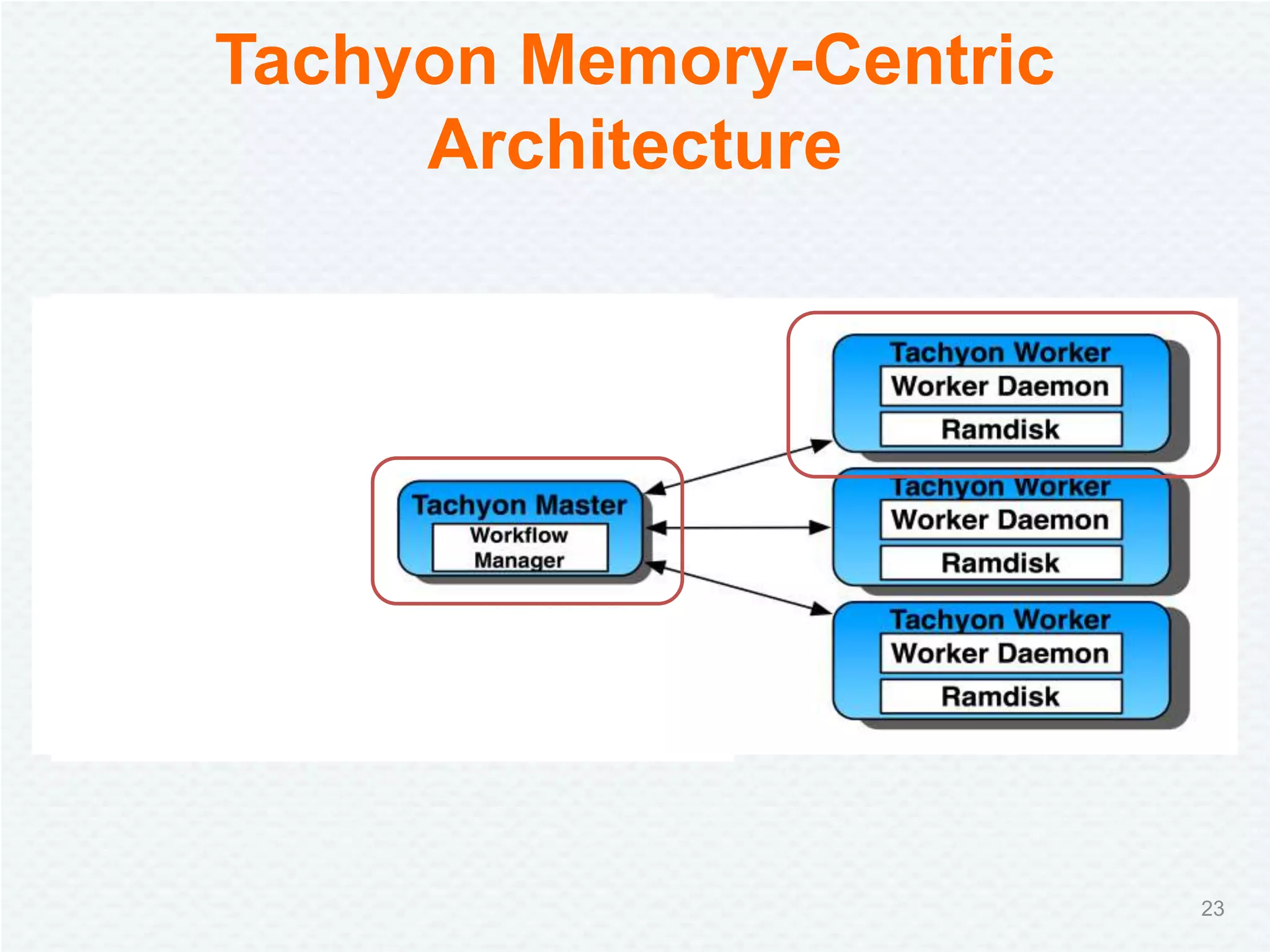
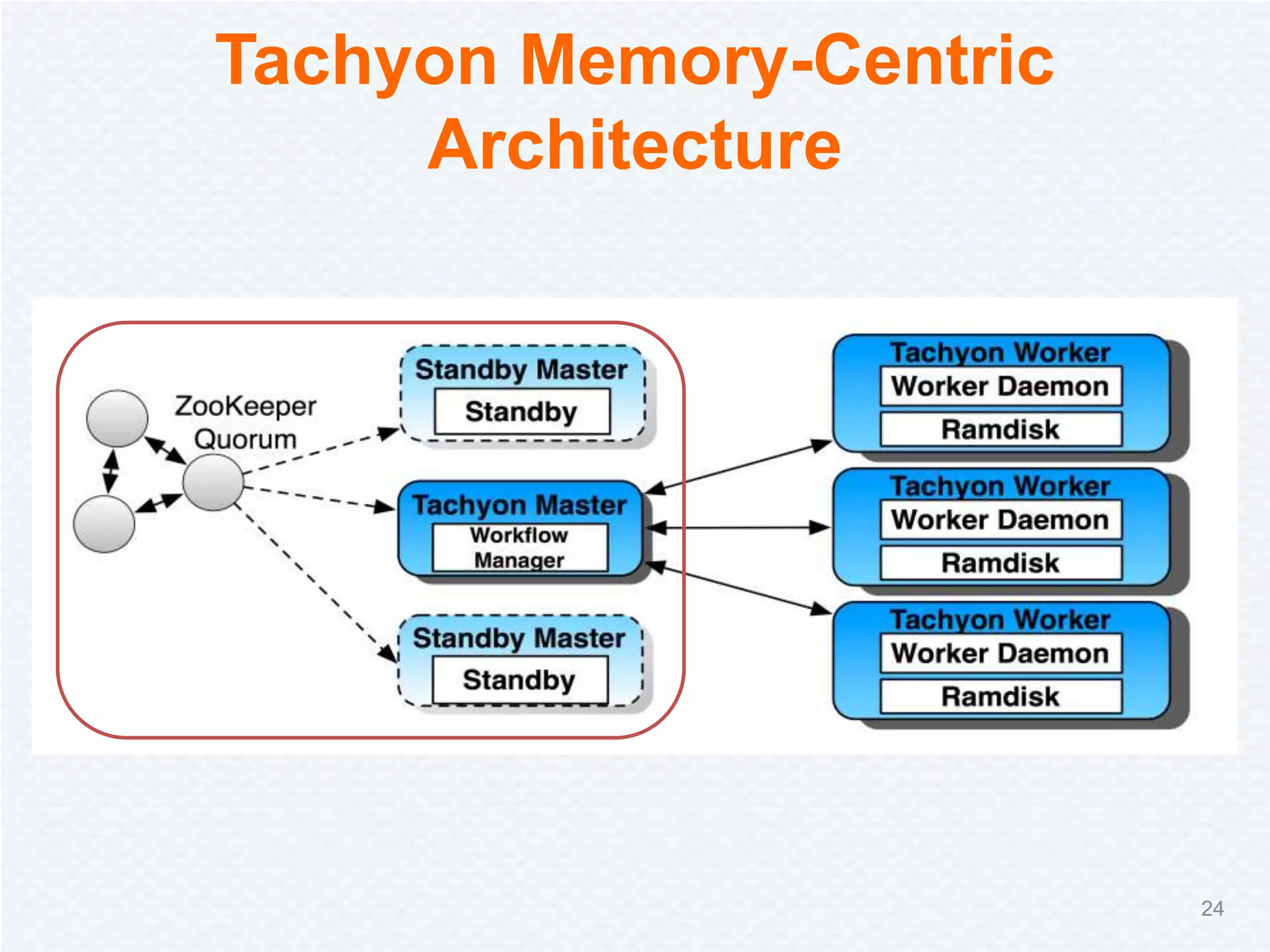
Tachyon is a memory-centric distributed storage system aimed at improving data sharing speed in analytics pipelines, overcoming bottlenecks associated with traditional disk storage. The project started at UC Berkeley's AMPLab and has received significant investment, with numerous companies deploying its technology. Tachyon's architecture supports lineage tracking for fault tolerance and minimizes data duplication, allowing for faster data processing across various computational frameworks.













































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















