Download as PDF, PPTX





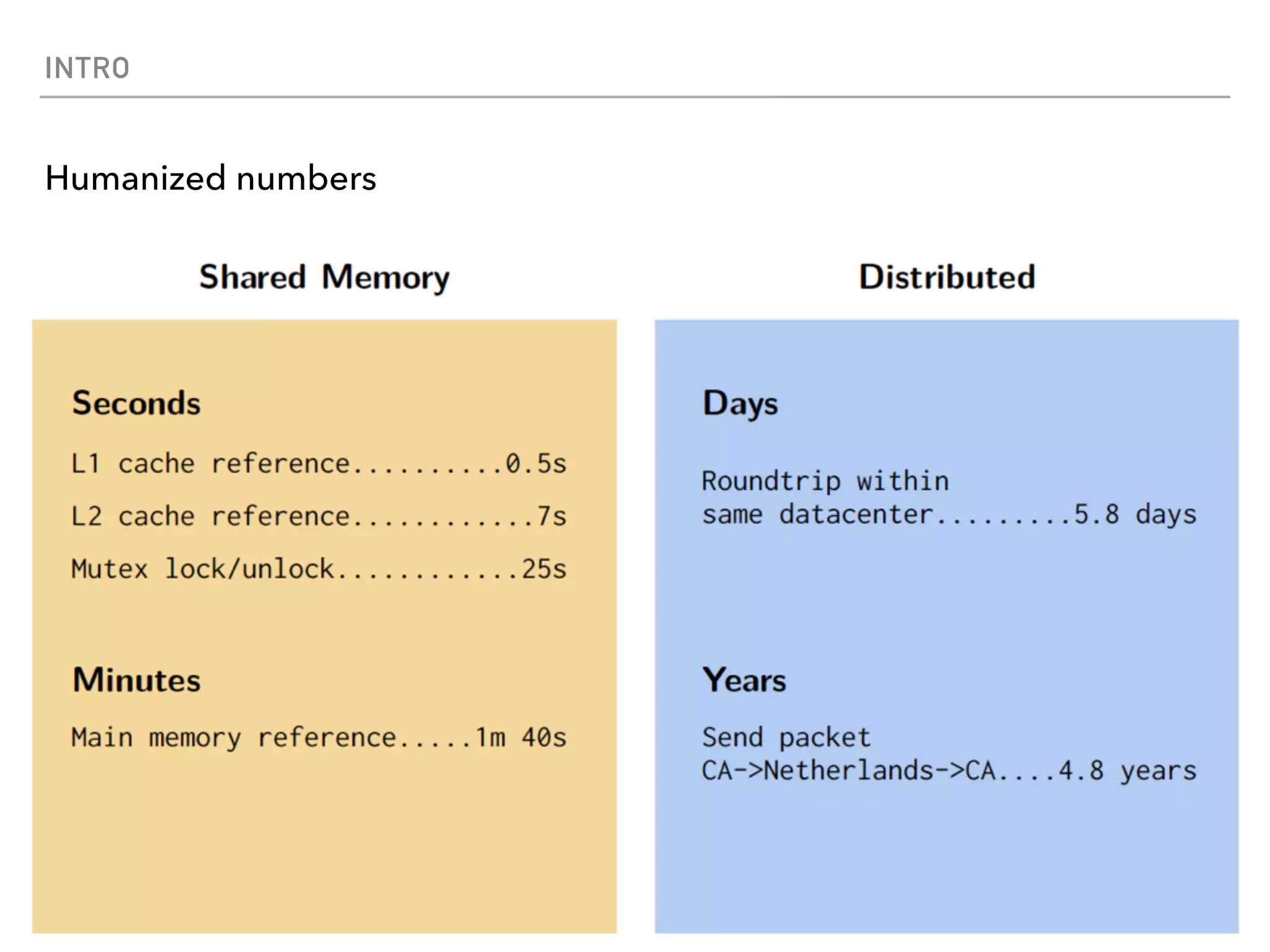
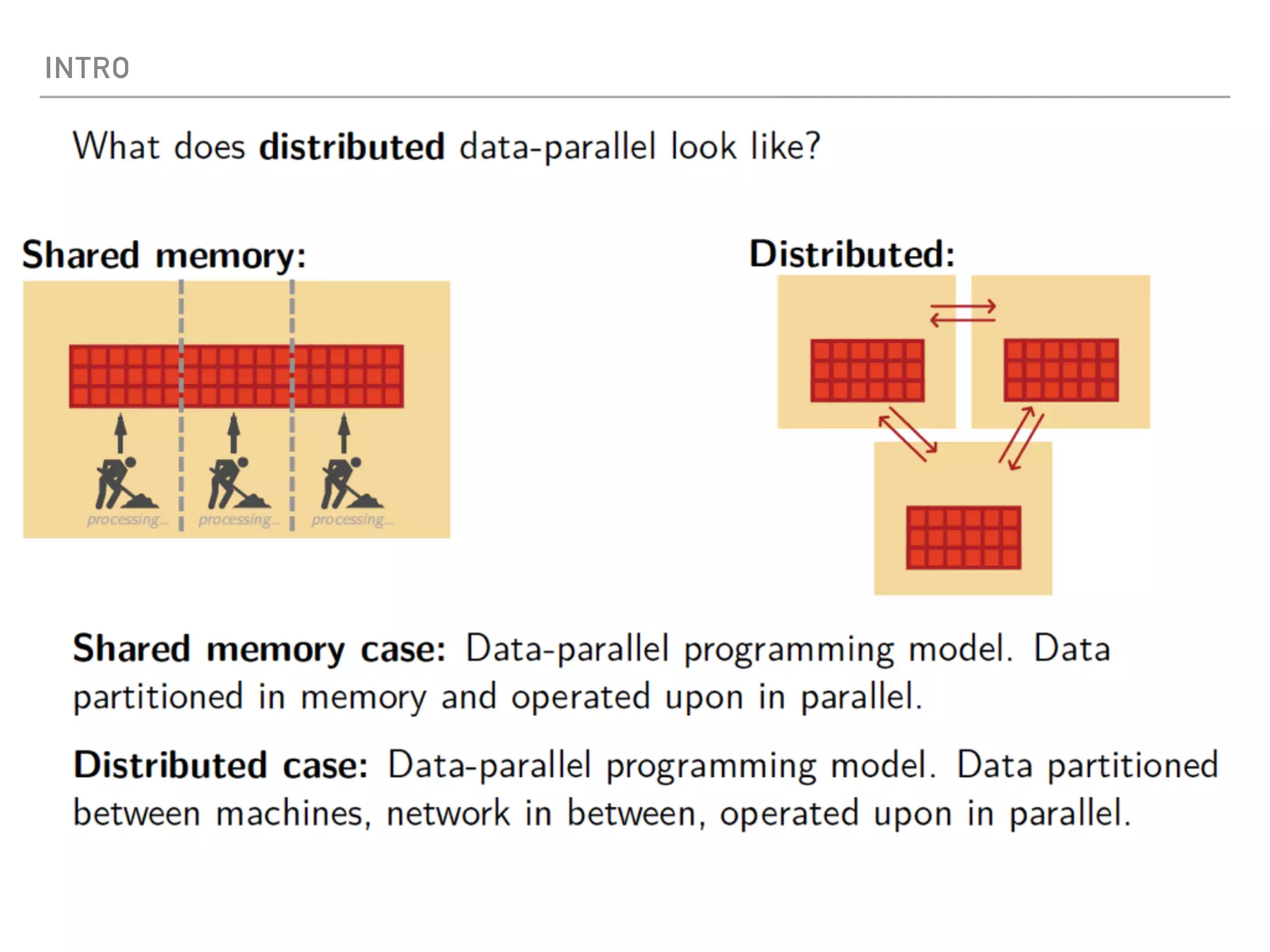

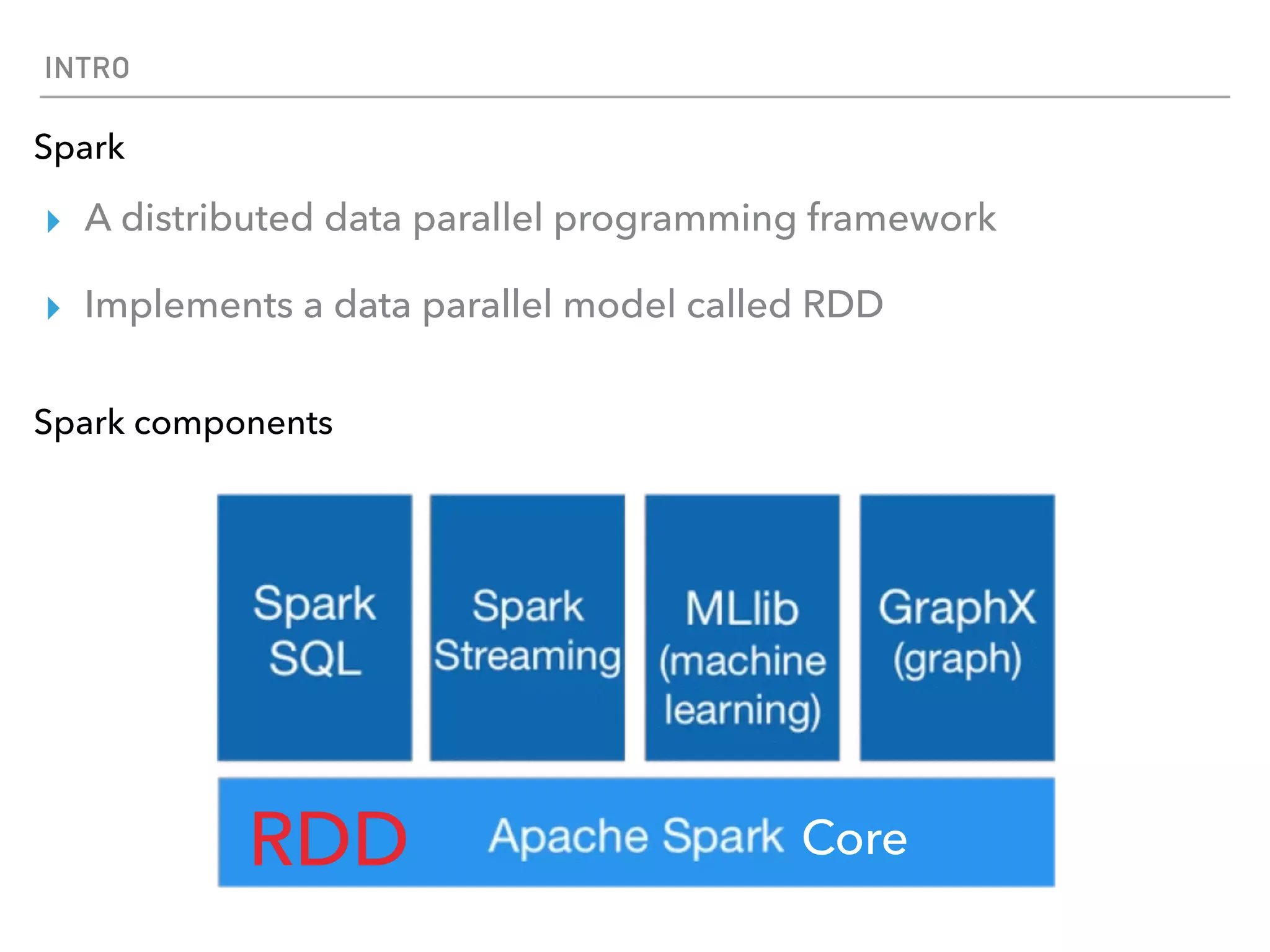






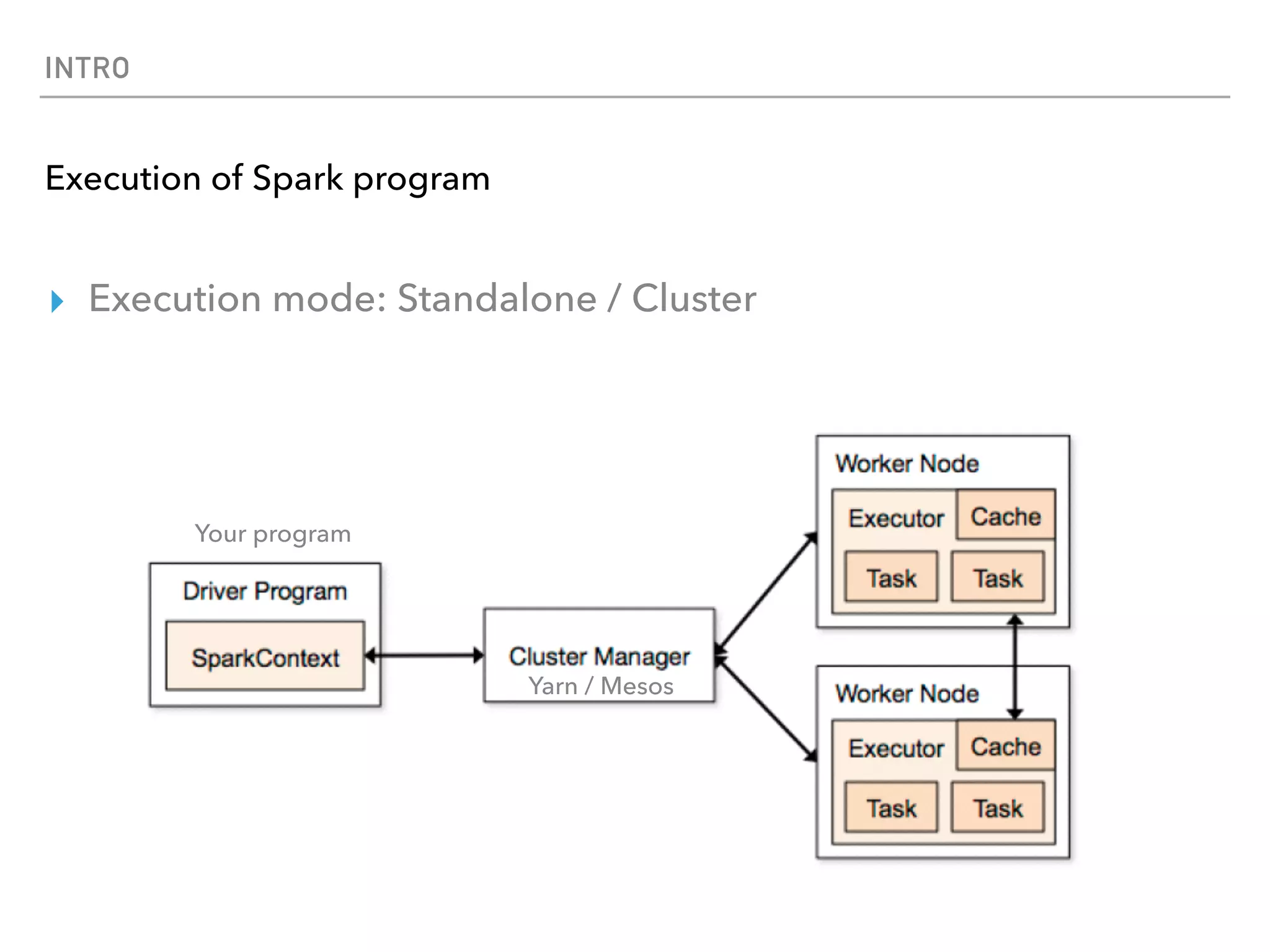

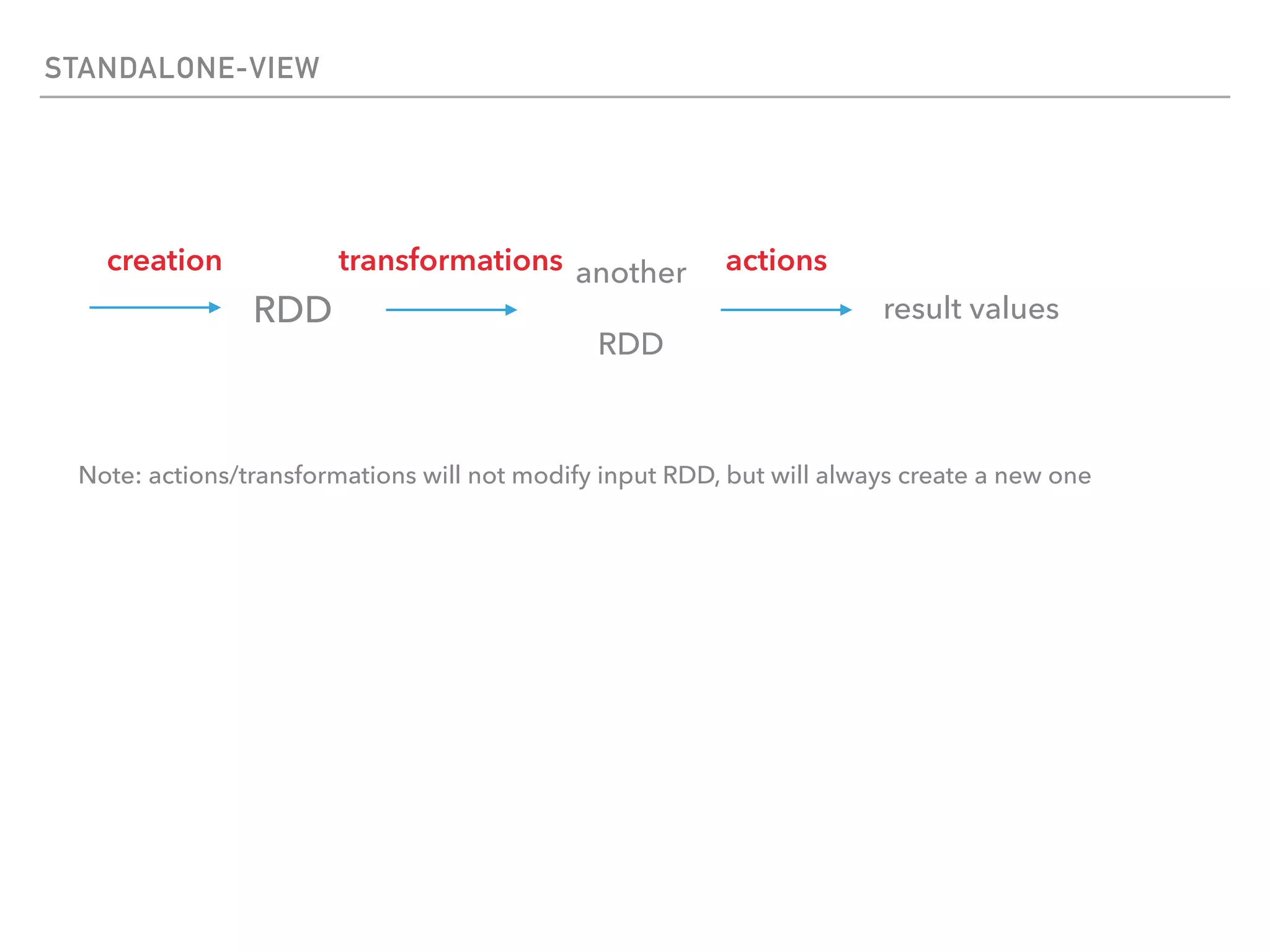





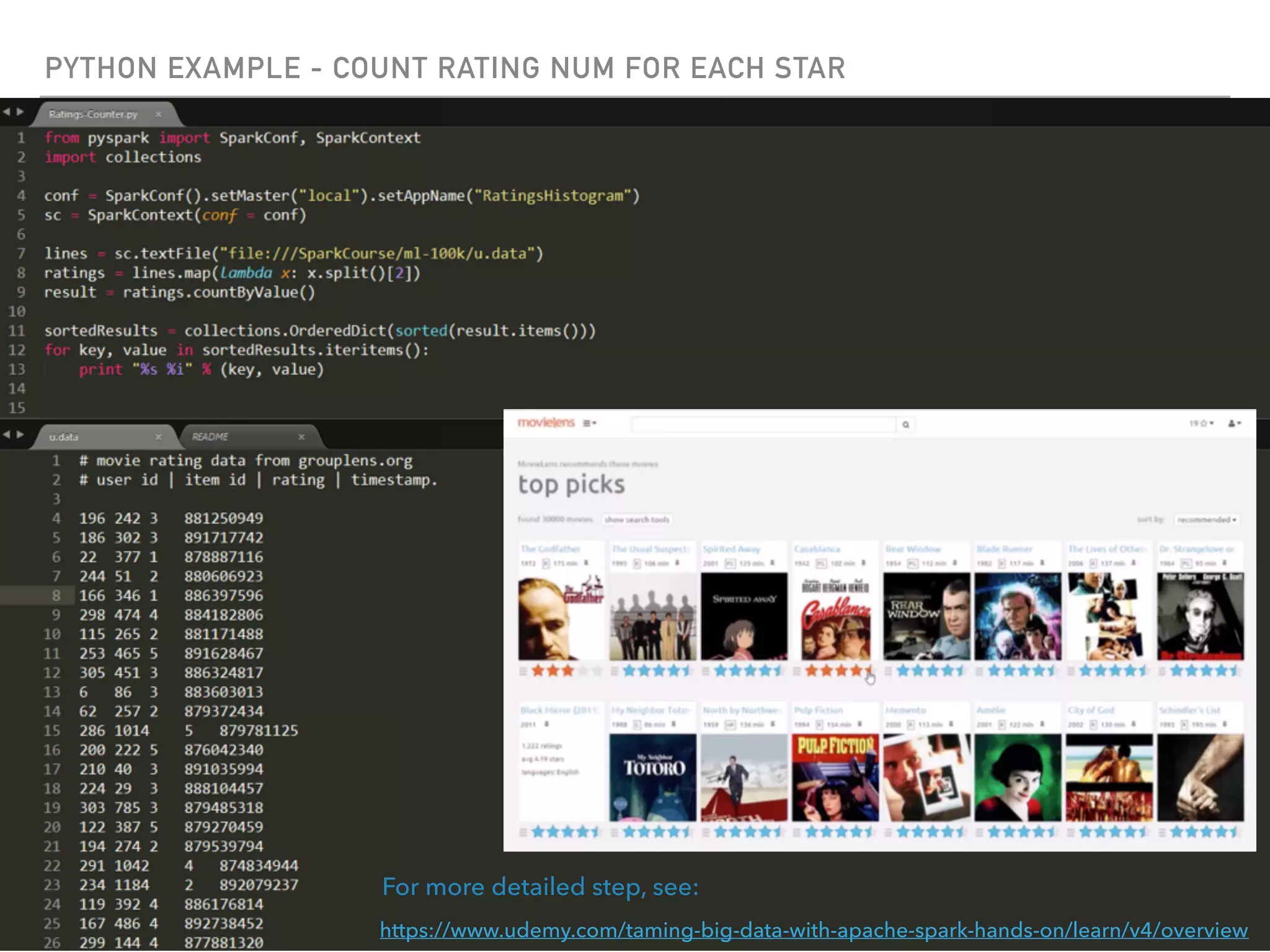

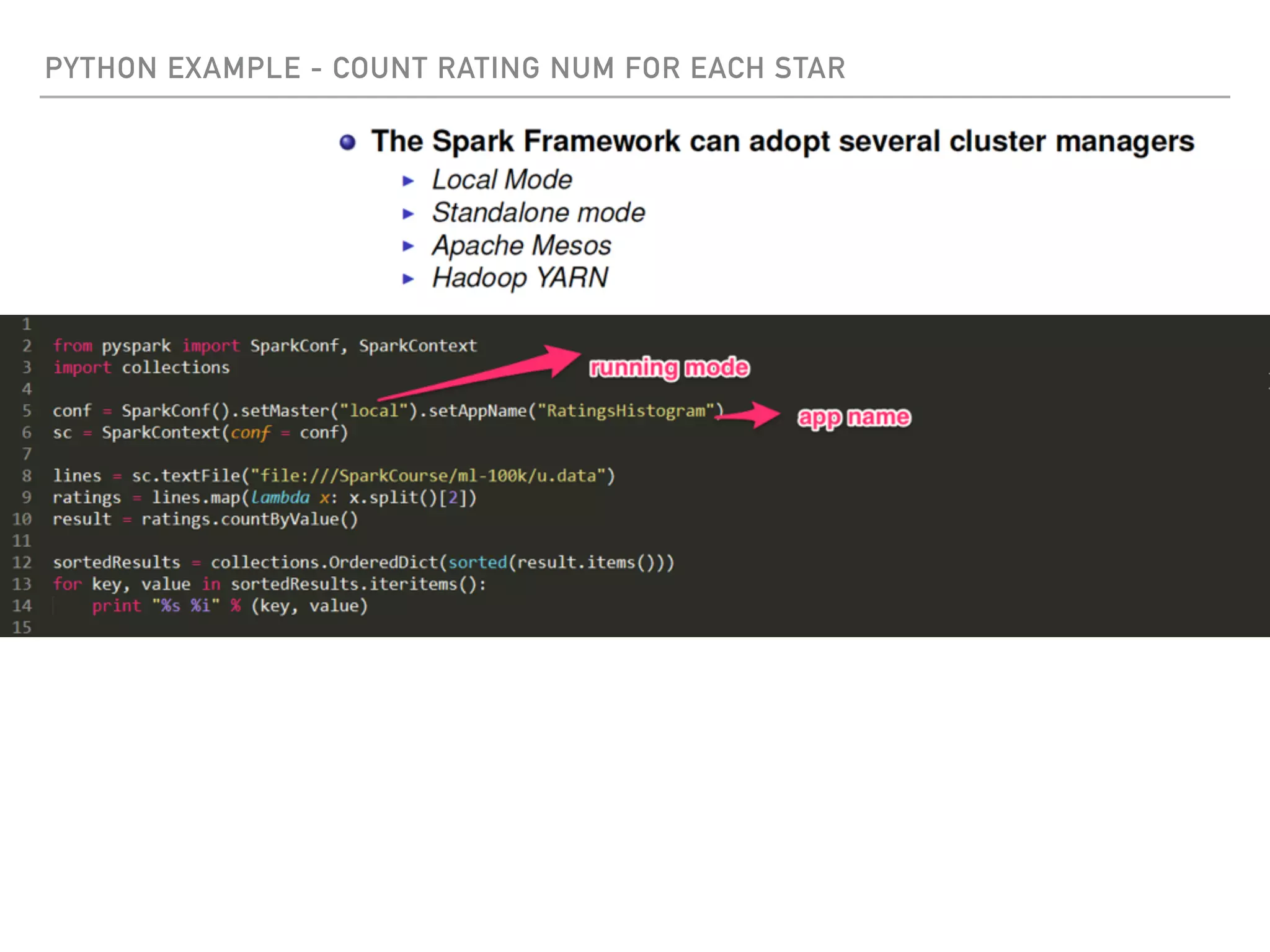


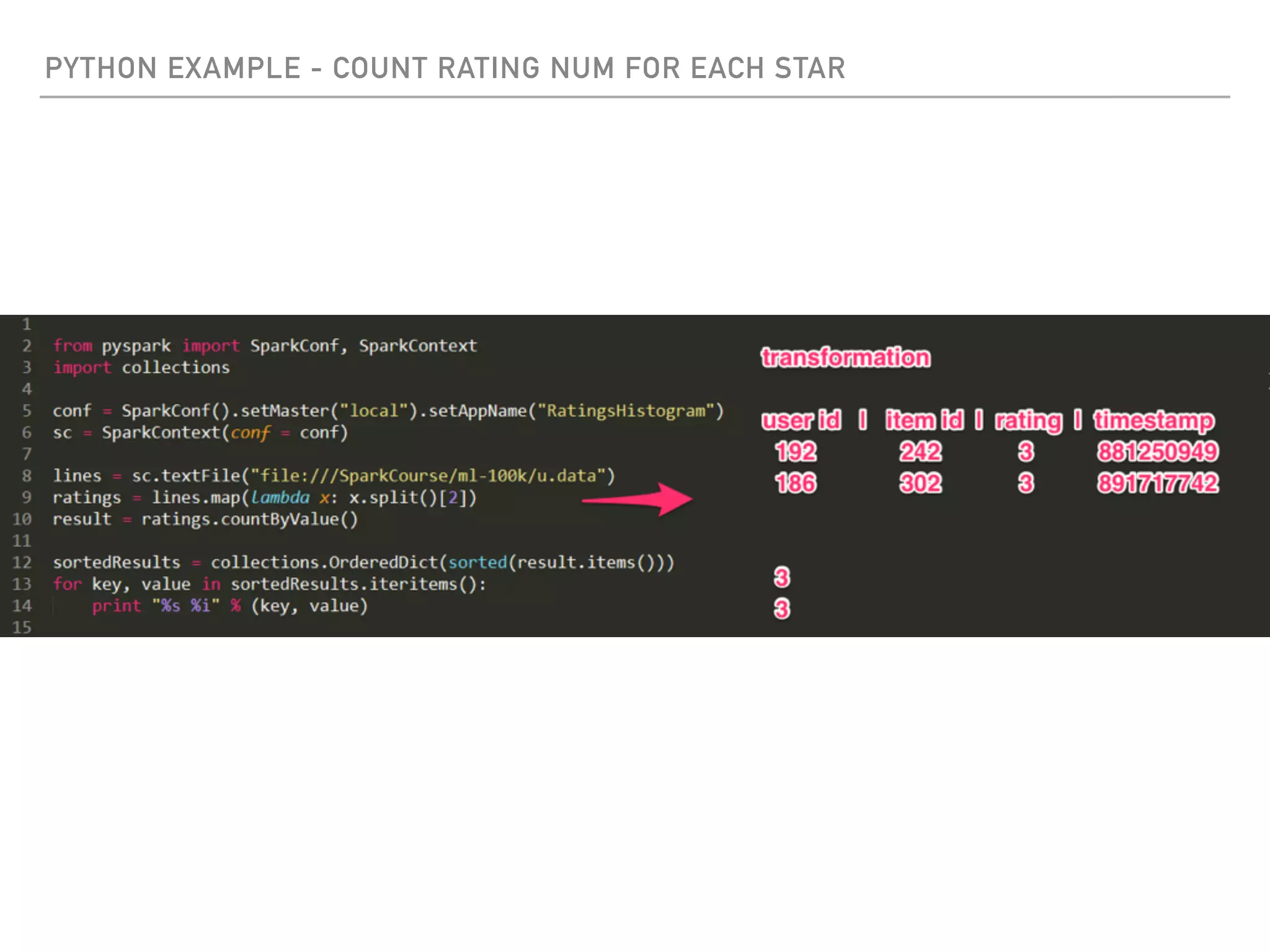
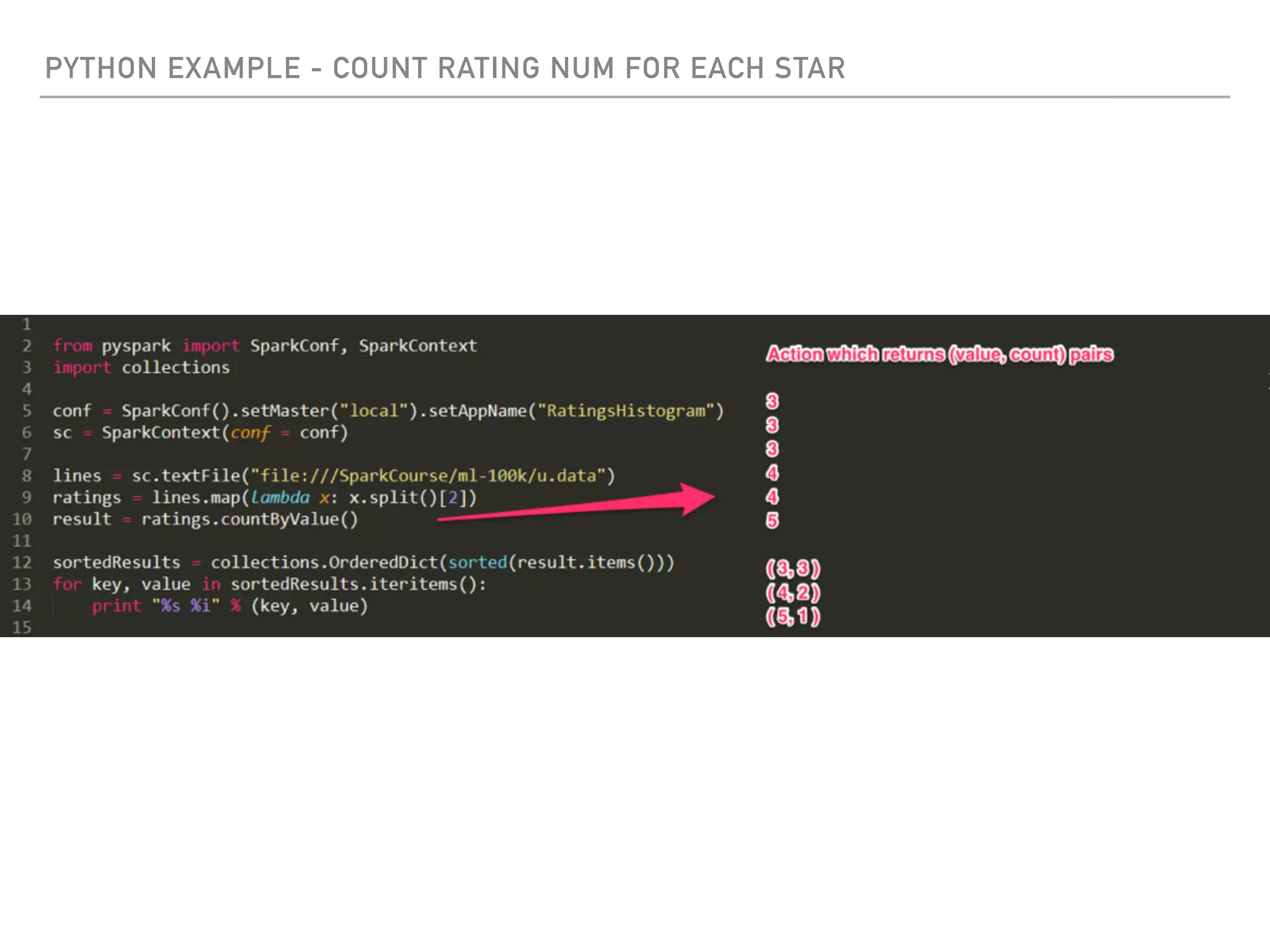


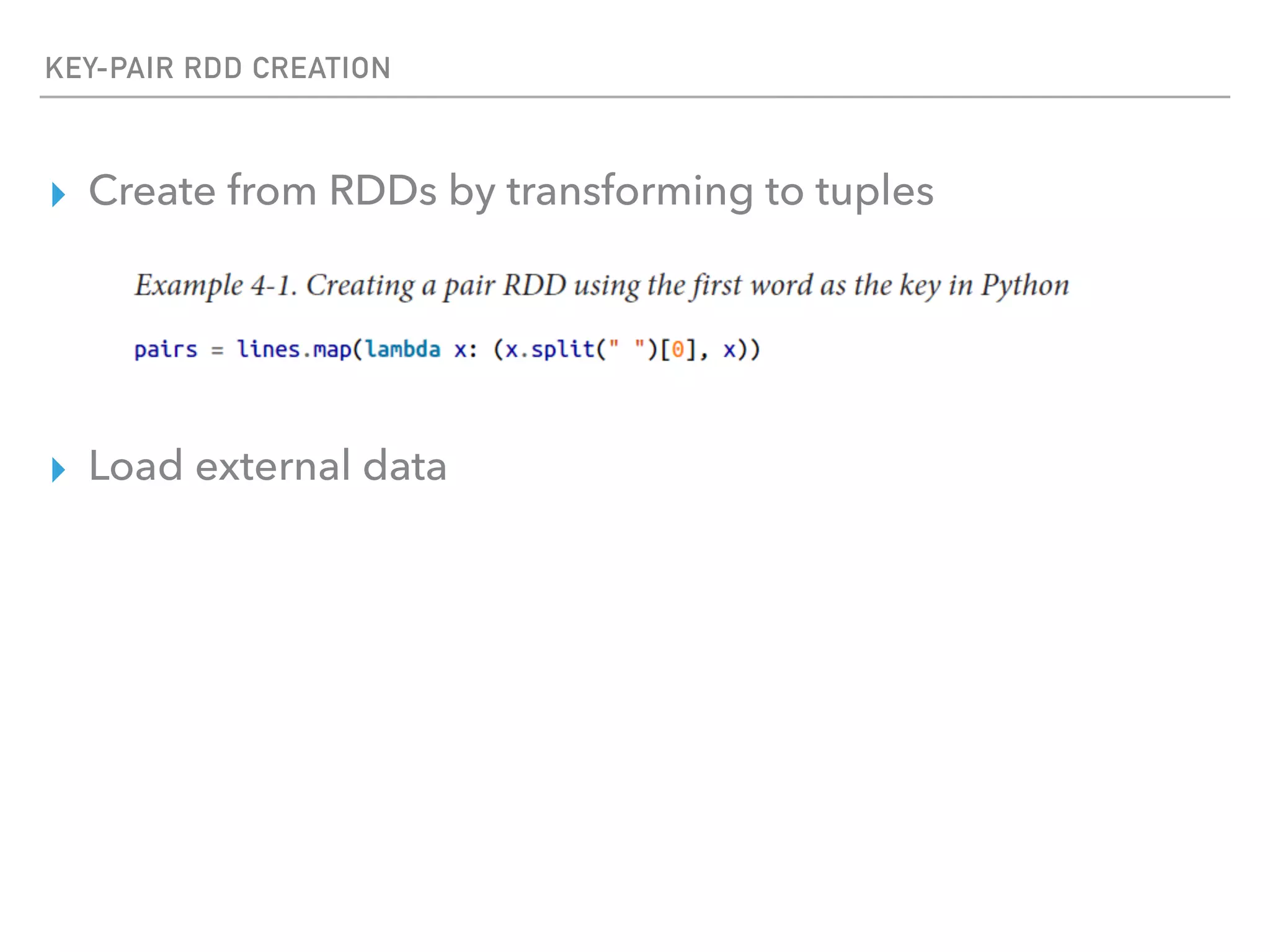





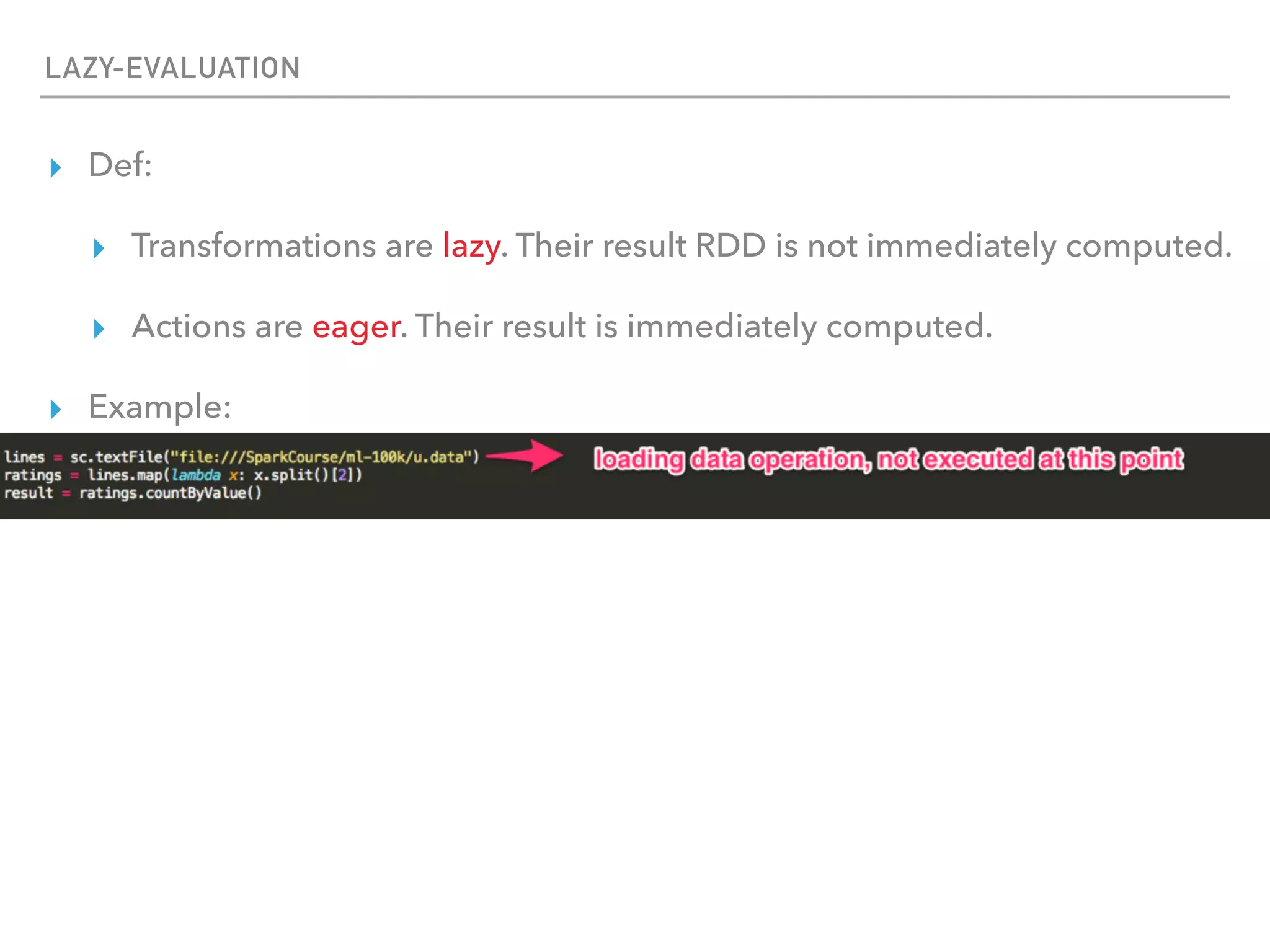
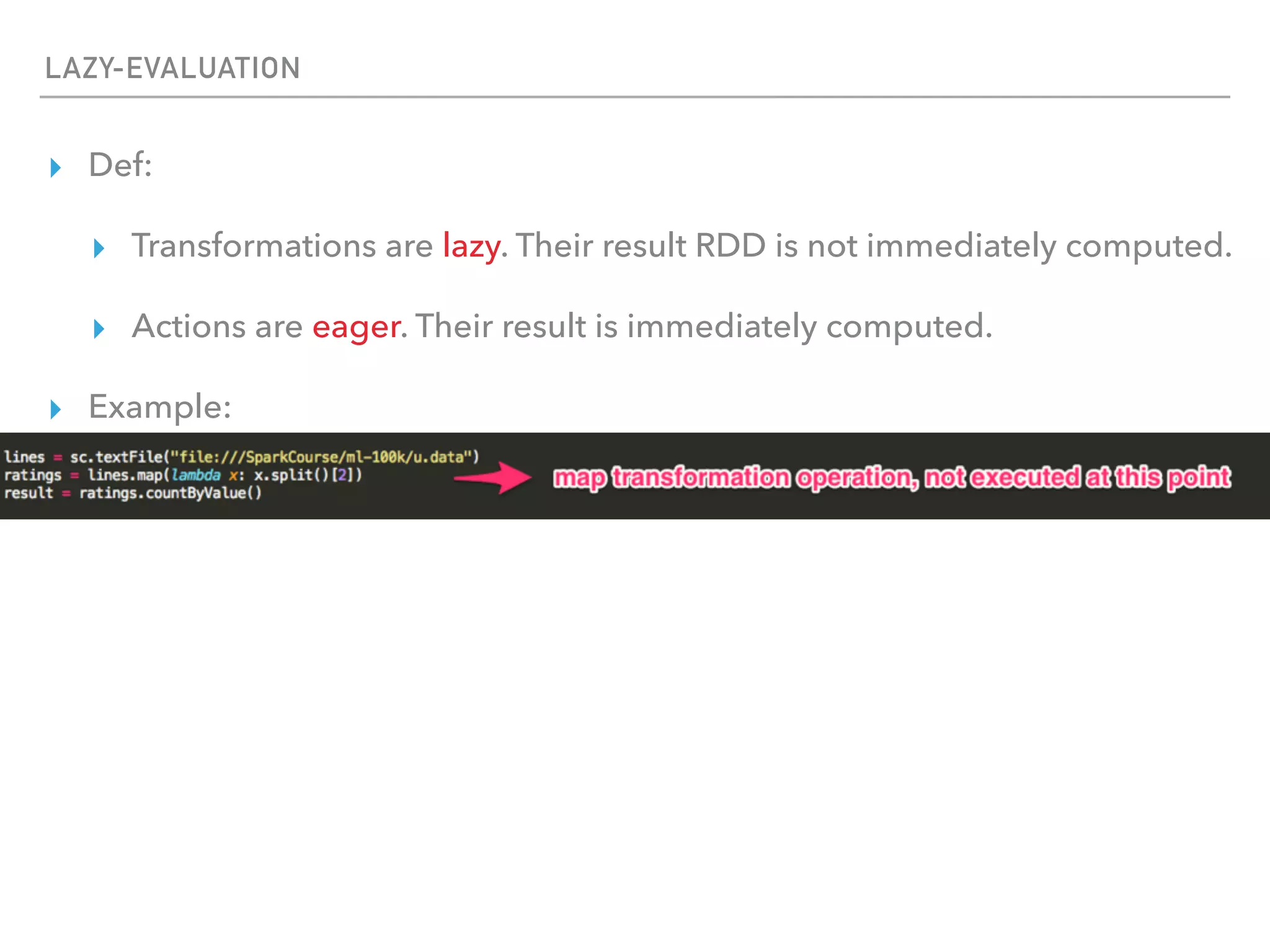
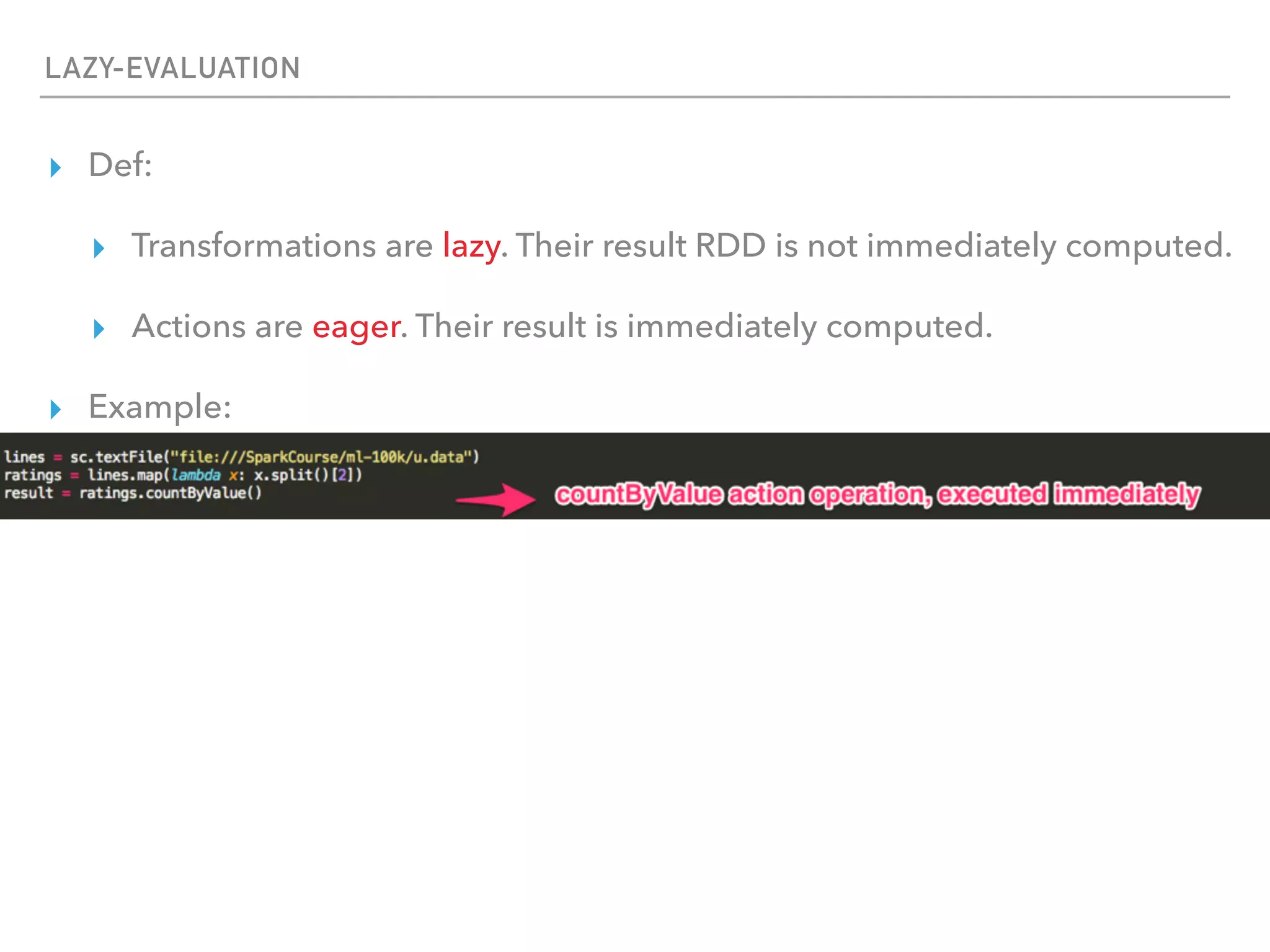
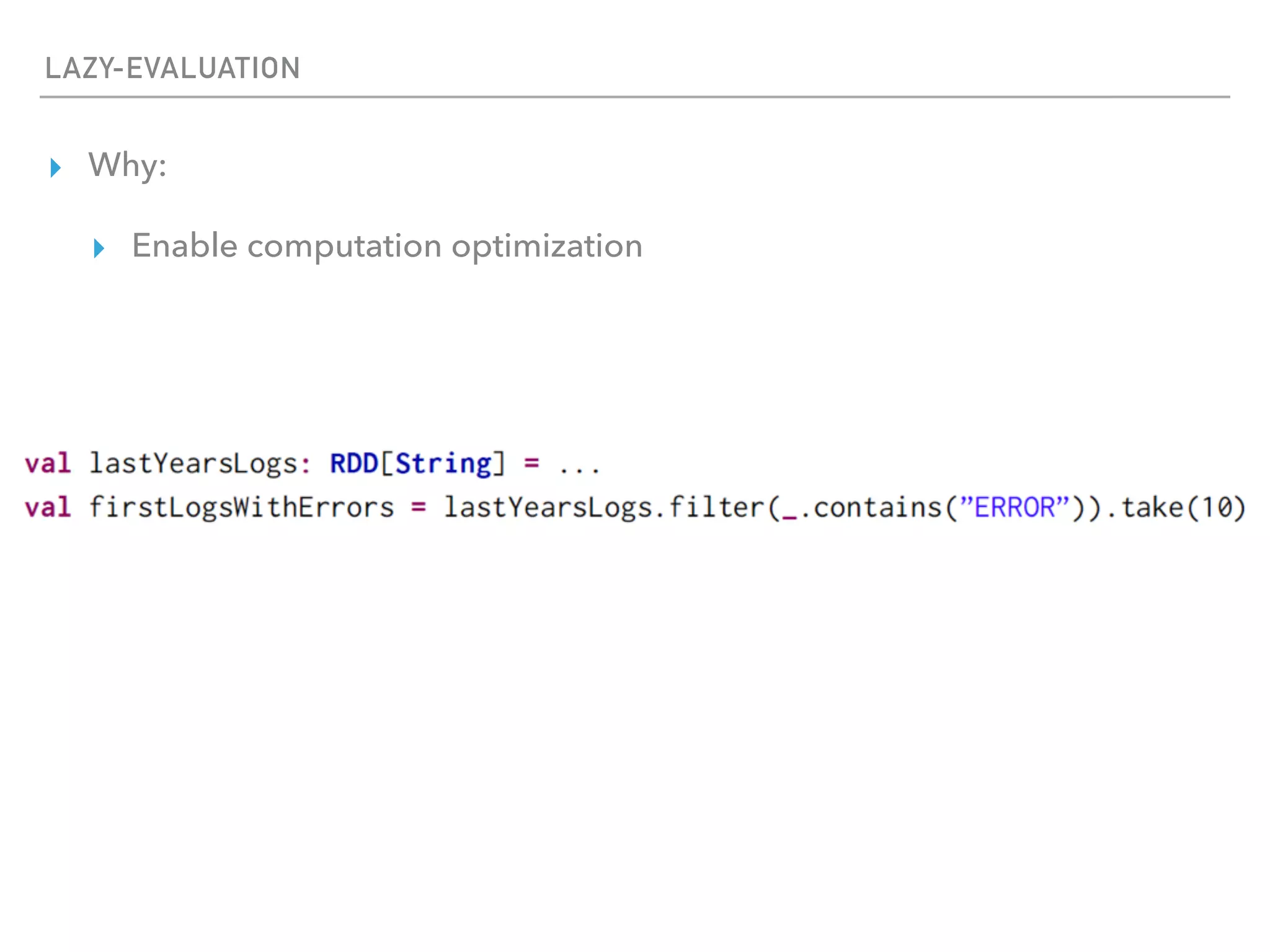


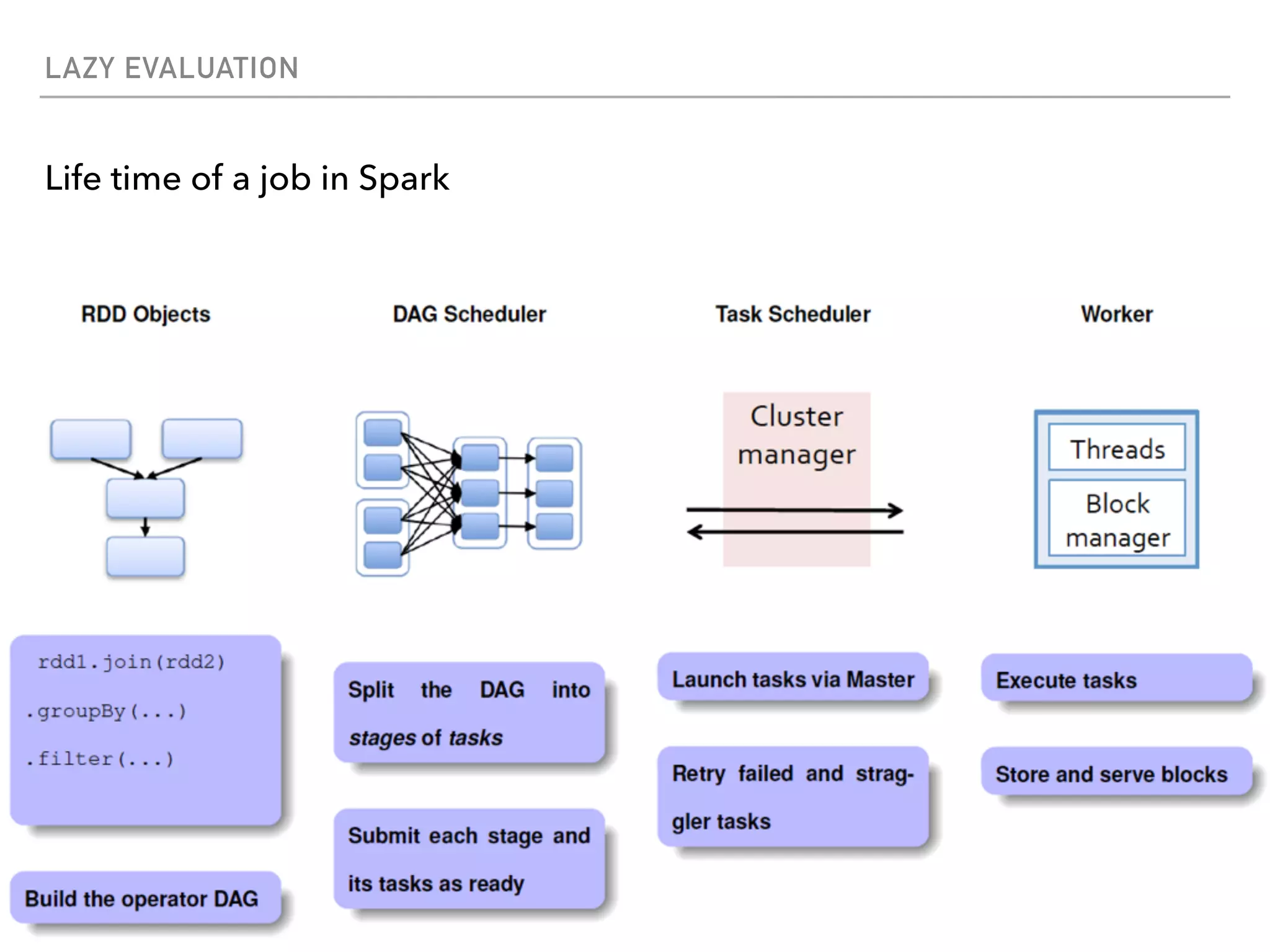


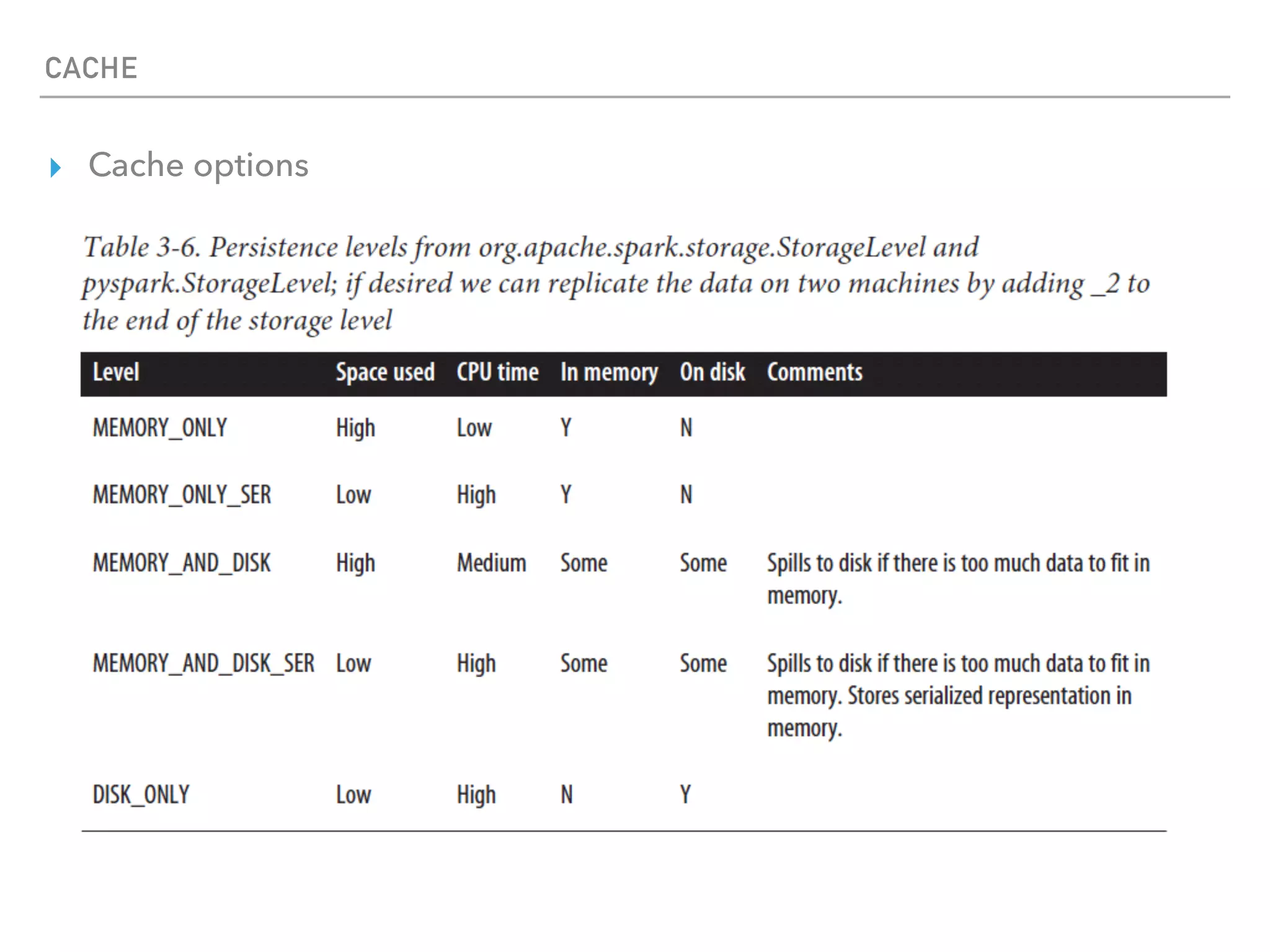



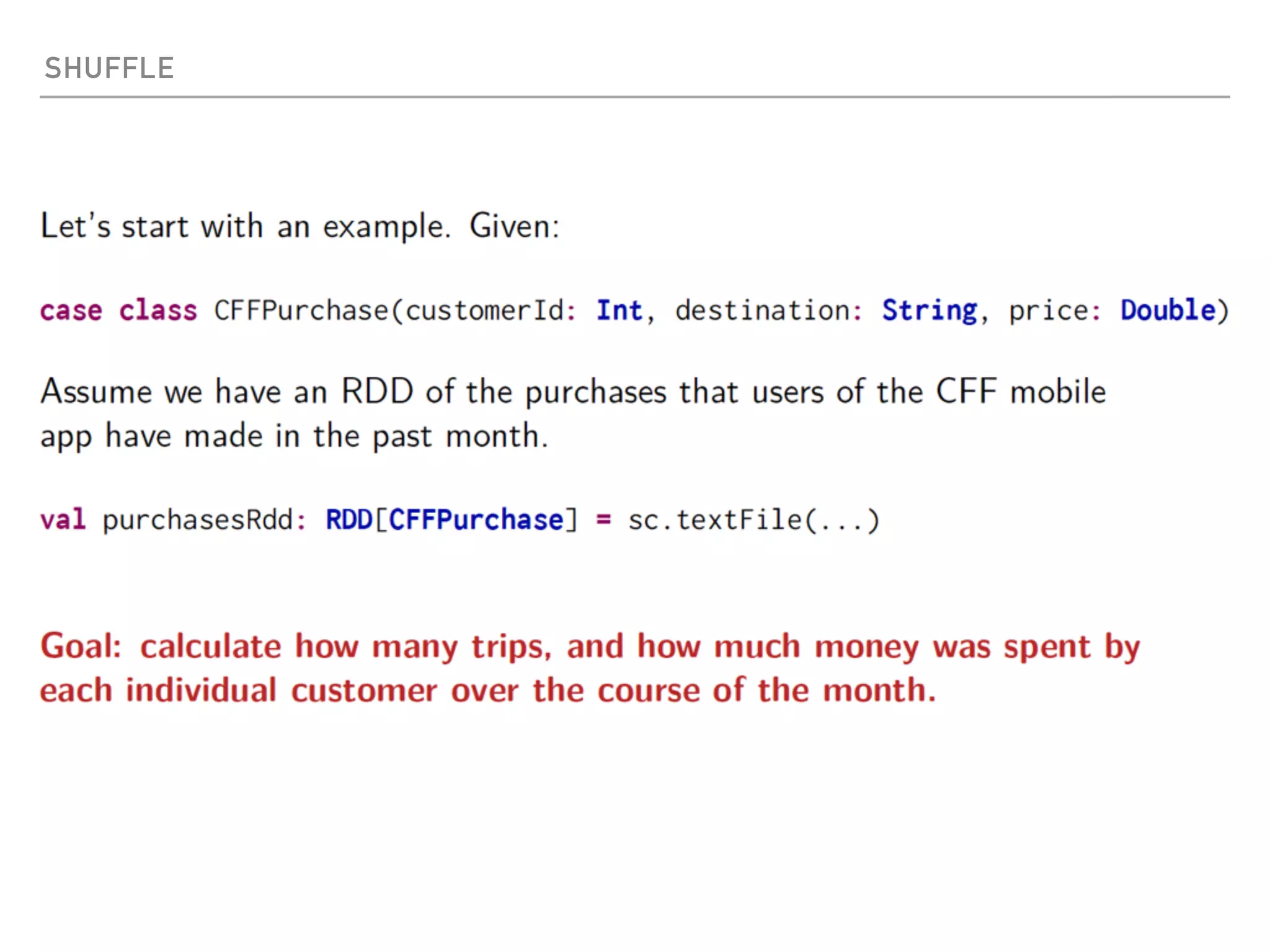
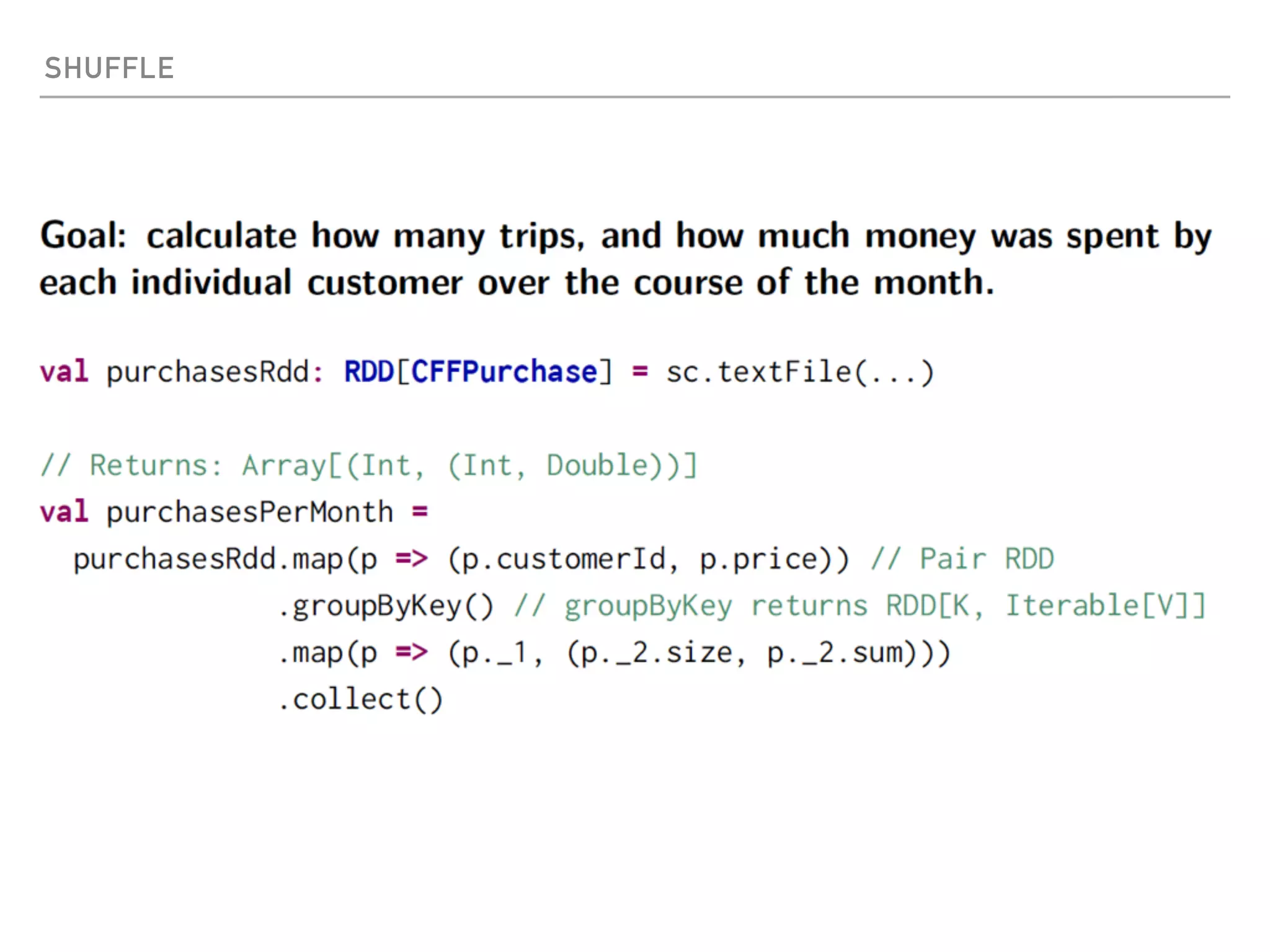
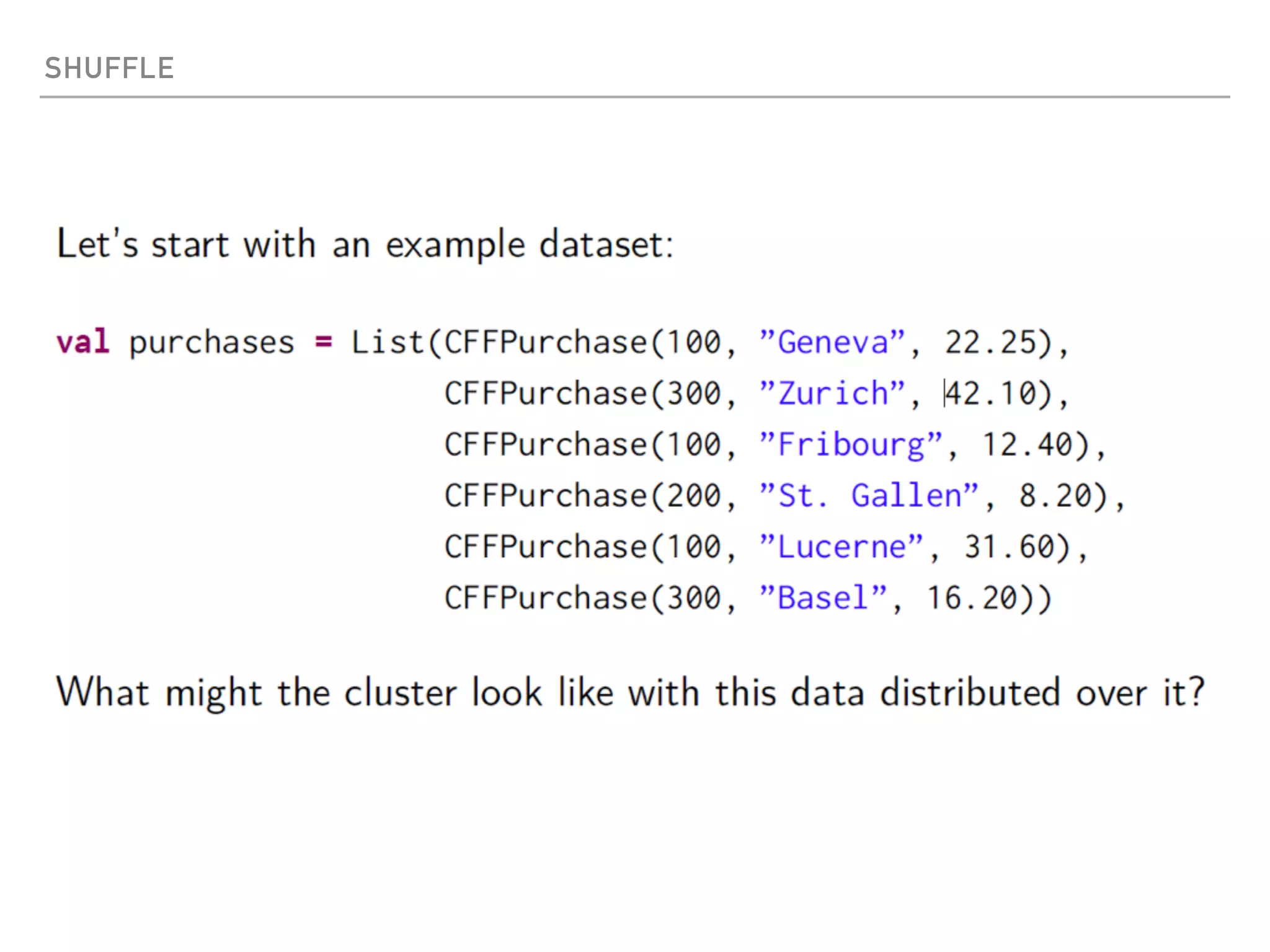



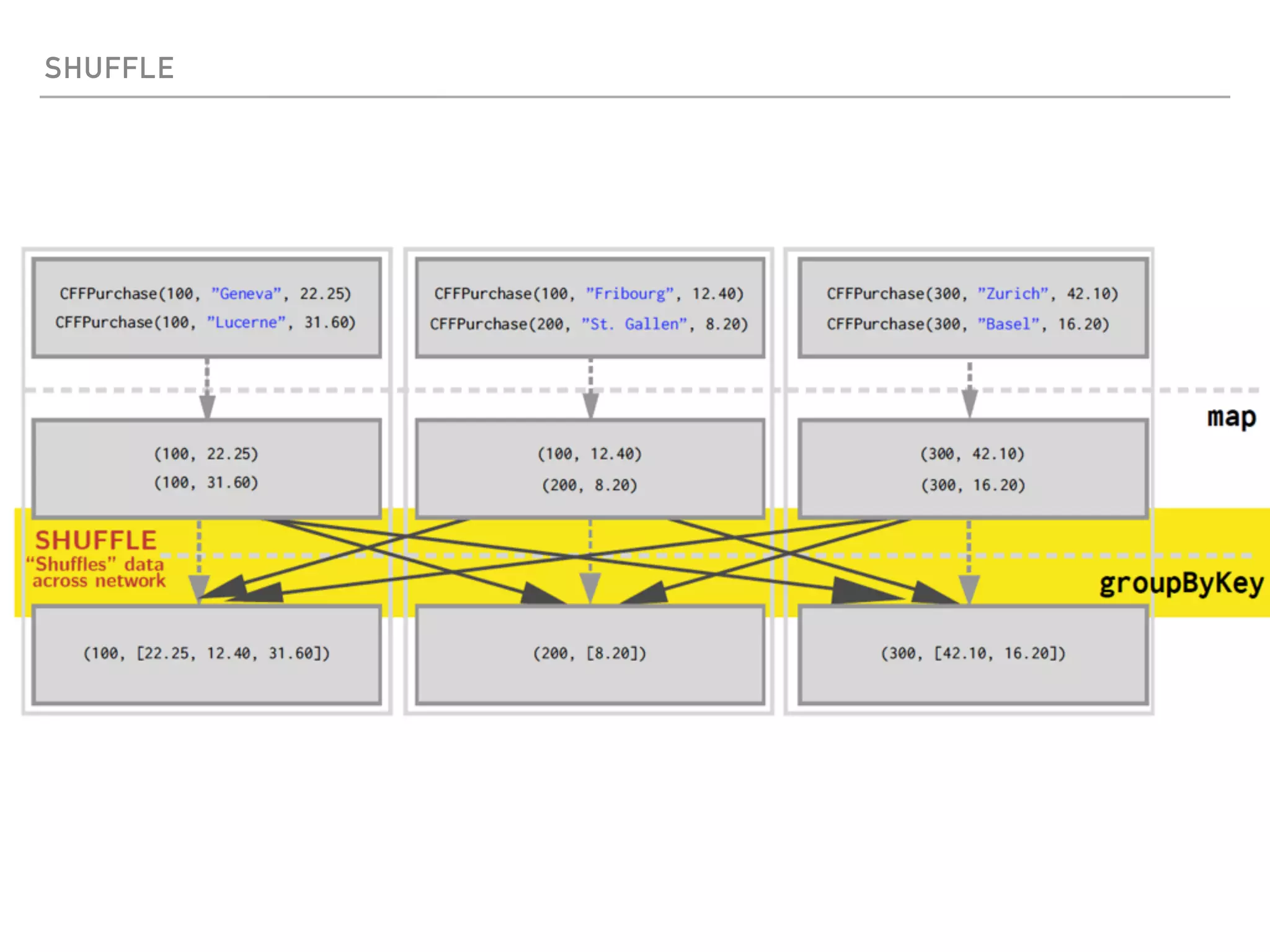

















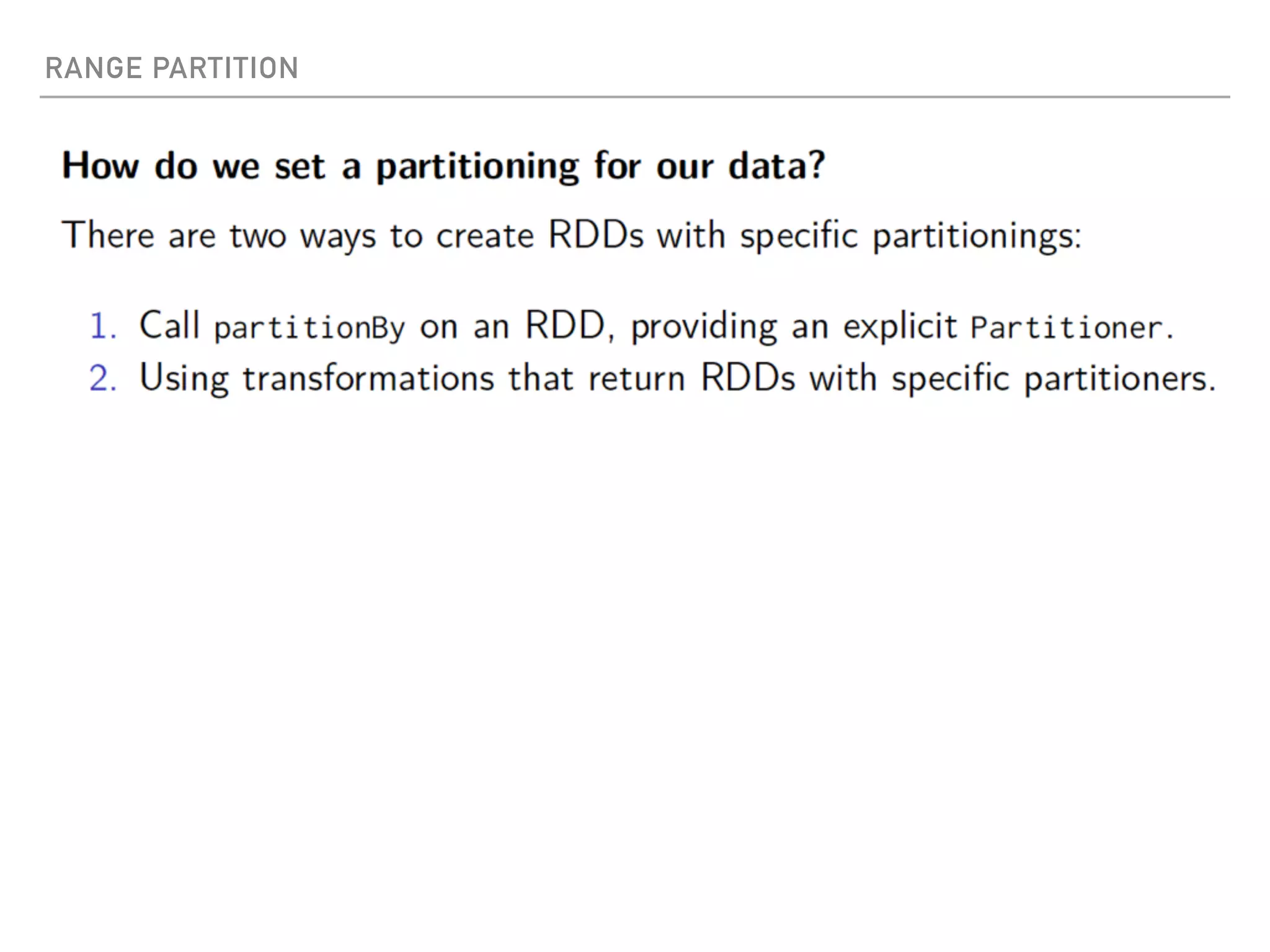






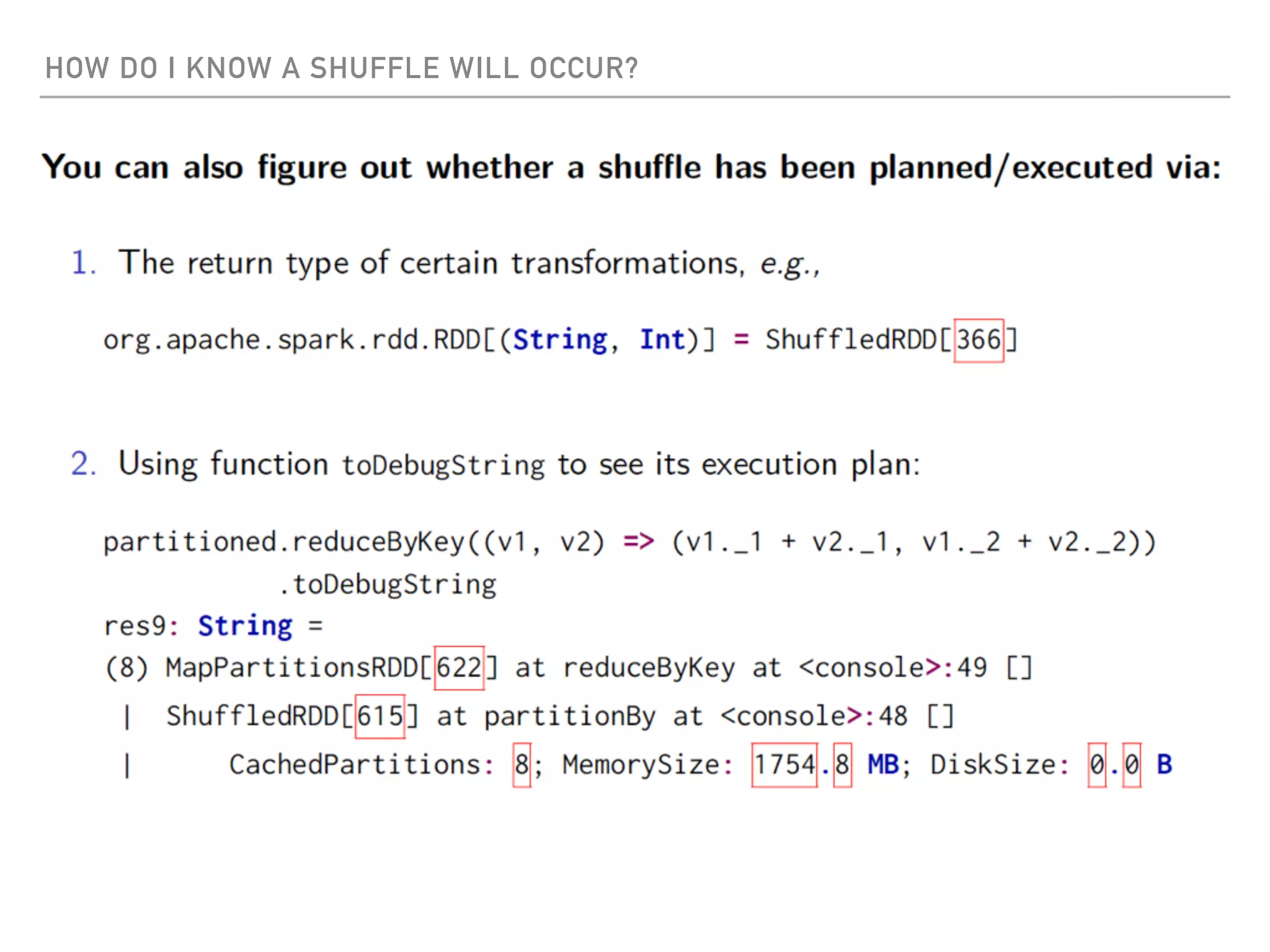
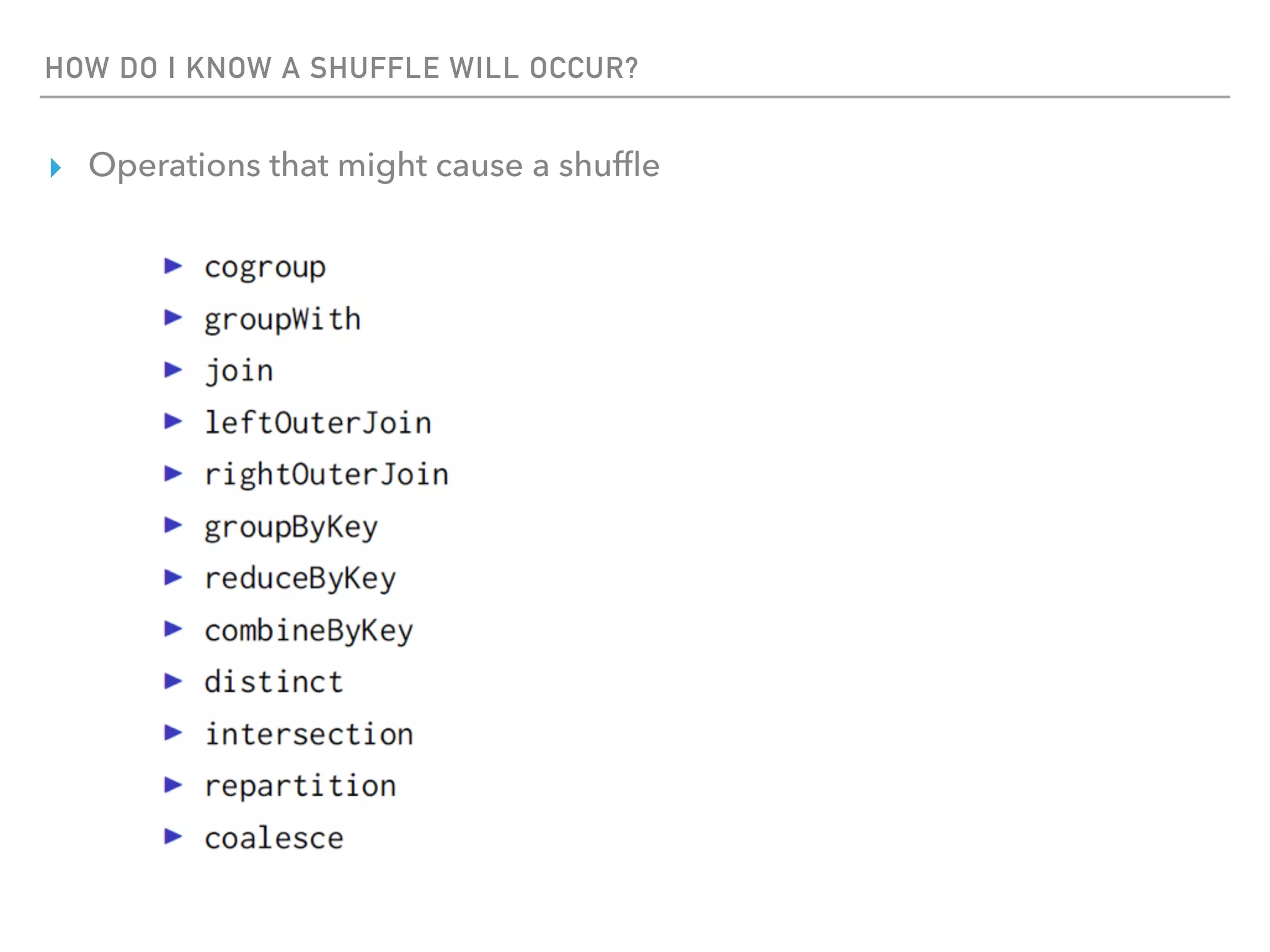









Spark is a distributed data processing framework that uses RDDs (Resilient Distributed Datasets) to represent data distributed across a cluster. RDDs support transformations like map, filter, and actions like reduce to operate on the distributed data in a parallel and fault-tolerant manner. Key concepts include lazy evaluation of transformations, caching of RDDs, and use of broadcast variables and accumulators for sharing data across nodes.























































































