Download to read offline




![Creating Pair RDD
Pair RDDs can be created by running a map() function that returns
key or value pairs
The procedure to build the key-value RDDs differs by language.
In Python language, for the functions on key data to work we need to
return an RDD composed of tuples
Creating a pair RDD using the first word as the key in Python
programming language.
pairs = lines.map(lambda x: (x.split(” “)[0], x))
Spark and Scala](https://image.slidesharecdn.com/04-spark-pairrdd-rddpersistence-181117061814/85/04-spark-pair-rdd-rdd-persistence-5-320.jpg)

![Creating Pair RDD (Java)
Creating a pair RDD using the first word as the key word in Java
program.
PairFunction<String, String, String> keyData =
new PairFunction<String, String, String>() {
public Tuple2<String, String> call(String x) {
return new Tuple2(x.split(” “)[0], x);
}
};
JavaPairRDD<String, String> pairs = lines.mapToPair(keyData);
Spark and Scala](https://image.slidesharecdn.com/04-spark-pairrdd-rddpersistence-181117061814/85/04-spark-pair-rdd-rdd-persistence-7-320.jpg)


![PairRDD Transformations (Grouping)
With key data is a common type of use case in grouping our data sets
is used with respect to predefined key value
For example, viewing all of a customer’s orders together in one file.
If our data is already keyed in the way we want to implement,
groupByKey() will group our data using the key value using our RDD.
On an RDD consisting of keys of type K and values of type V, we get
back an RDD operation of type [K, Iterable[V]]
Spark and Scala](https://image.slidesharecdn.com/04-spark-pairrdd-rddpersistence-181117061814/85/04-spark-pair-rdd-rdd-persistence-10-320.jpg)


![PairRDD Transformations
Transformations Description
groupByKey([numTasks]
)
When called on a dataset of (K, V) pairs, returns a dataset of (K,
Iterable<V>) pairs. Note: If you are grouping in order to perform an
aggregation (such as a sum or average) over each key, using
reduceByKey or aggregateByKey will yield much better performance.
Note: By default, the level of parallelism in the output depends on the
number of partitions of the parent RDD.
You can pass an optional numTasks argument to set a different
number of tasks.
reduceByKey(func,
[numTasks])
When called on a dataset of (K, V) pairs, returns a dataset of (K, V)
pairs where the values for each key are aggregated using the given
reduce function func, which must be of type (V,V) => V. Like in
groupByKey, the number of reduce tasks is configurable through an
optional second argument
sortByKey([ascending],
[numTasks])
When called on a dataset of (K, V) pairs where K implements Ordered,
returns a dataset of (K, V) pairs sorted by keys in ascending or
descending order, as specified in the Boolean ascending argument.
Spark and Scala](https://image.slidesharecdn.com/04-spark-pairrdd-rddpersistence-181117061814/85/04-spark-pair-rdd-rdd-persistence-13-320.jpg)
 =>
C,
mergeCombiners: (C,
C) => C): RDD[(K, C)]
1st Argument : createCombiner is called when a key(in the RDD
element) is found for the first time in a given Partition. This method
creates an initial value for the accumulator for that key
2nd Argument : mergeValue is called when the key already has an
accumulator
3rd Argument : mergeCombiners is called when more that one
partition has accumulator for the same key
mapvalues When called on a dataset of (K, V) pairs, returns a dataset of (K, V)
pairs where the values for each key are aggregated using the given
reduce function func, which must be of type (V,V) => V. Like in
groupByKey, the number of reduce tasks is configurable through an
optional second argument
Keys/values When called on a dataset of (K, V) pairs where K implements Ordered,
returns a dataset of (K, V) pairs sorted by keys in ascending or
descending order, as specified in the boolean ascending argument.
Spark and Scala](https://image.slidesharecdn.com/04-spark-pairrdd-rddpersistence-181117061814/85/04-spark-pair-rdd-rdd-persistence-14-320.jpg)
![PairRDD Transformations
Transformations Description
aggregateByKey(zeroVal
ue)(seqOp, combOp,
[numTasks])
When called on a dataset of (K, V) pairs, returns a dataset of (K, U)
pairs where the values for each key are aggregated using the given
combine functions and a neutral "zero" value. Allows an aggregated
value type that is different than the input value type, while avoiding
unnecessary allocations. Like in groupByKey, the number of reduce
tasks is configurable through an optional second argument.
join(otherDataset,
[numTasks])
When called on datasets of type (K, V) and (K, W), returns a dataset of
(K, (V, W)) pairs with all pairs of elements for each key. Outer joins are
supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin
cogroup(otherDataset,
[numTasks])
When called on datasets of type (K, V) and (K, W), returns a dataset of
(K, (Iterable<V>, Iterable<W>)) tuples. This operation is also called
groupWith
Spark and Scala](https://image.slidesharecdn.com/04-spark-pairrdd-rddpersistence-181117061814/85/04-spark-pair-rdd-rdd-persistence-15-320.jpg)





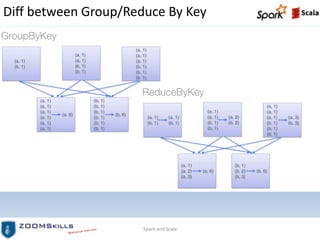












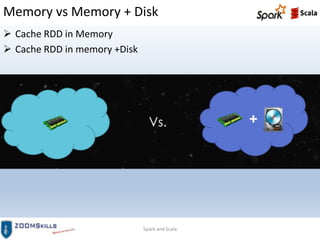




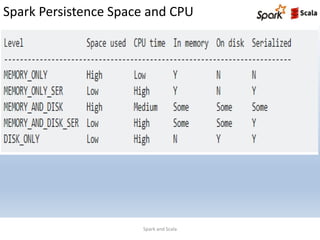






This document provides an overview of Spark Pair RDDs and persistence. It defines Pair RDDs as RDDs of key-value pairs that enable aggregations. It describes how to create Pair RDDs in Scala, Python, and Java and covers common Pair RDD transformations like groupByKey, reduceByKey, aggregateByKey, combineByKey, joins, sorting by key, and actions. It also discusses the differences between groupByKey and reduceByKey and demonstrates various Pair RDD functions and persistence levels.



































































