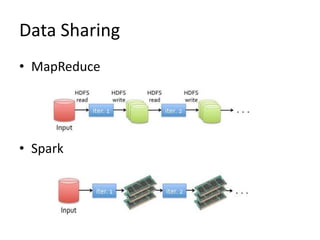
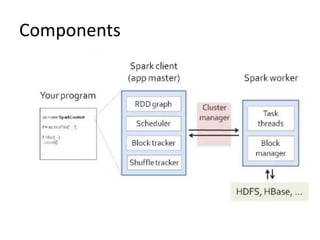
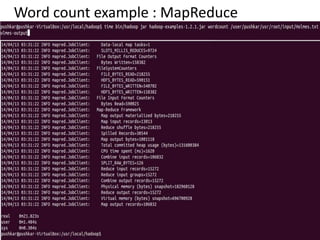
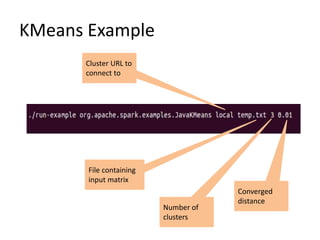
This document discusses Apache Spark, a fast and general engine for large-scale data processing. It introduces Spark's Resilient Distributed Datasets (RDDs) and its programming model using transformations and actions. It provides instructions for installing Spark and launching it on Amazon EC2. It includes an example word count program in Spark and compares its performance to MapReduce. Finally, it briefly describes MLlib, Spark's machine learning library, and provides an example of the k-means clustering algorithm.