Download as PDF, PPTX








val messages = KafkaUtils.createStream[String, String, StringDecoder,
StringDecoder]
(
sc,
kafkaParams,
Map(topic -> threadsPerTopic),
storageLevel = StorageLevel.MEMORY_ONLY_SER
)
val revenue = messages.filter(m => m.contains(“[PURCHASE]”))
.map(p => p.split(“t”)(4)).reduceByKey(_ + _)
Mini-batch](https://image.slidesharecdn.com/spark-150605080255-lva1-app6892/85/Introduction-to-Apache-Spark-Ecosystem-11-320.jpg)




![Using the Shell
Launching:
Modes:
MASTER=local ./spark-shell # local, 1 thread
MASTER=local[2] ./spark-shell # local, 2 threads
MASTER=spark://host:port ./spark-shell # cluster
spark-shell
pyspark (IPYTHON=1)](https://image.slidesharecdn.com/spark-150605080255-lva1-app6892/85/Introduction-to-Apache-Spark-Ecosystem-18-320.jpg)








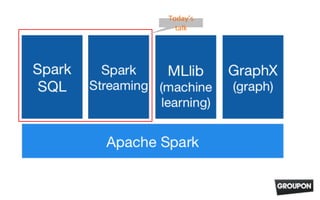
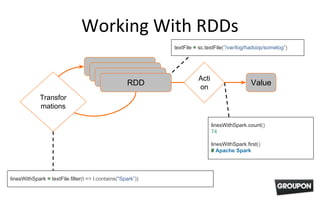
This document introduces Apache Spark, an open-source cluster computing system that provides fast, general execution engines for large-scale data processing. It summarizes key Spark concepts including resilient distributed datasets (RDDs) that let users spread data across a cluster, transformations that operate on RDDs, and actions that return values to the driver program. Examples demonstrate how to load data from files, filter and transform it using RDDs, and run Spark programs on a local or cluster environment.



































































