Download as PDF, PPTX














![Lowering memory access latency
by using local memory
Unoptimized Optimized
__kernel EP(...) { __kernel local_EP(...) {
... ...
for (i = 0; i < NK; i++) lq[] = q[];
{ for (i = 0; i < NK; i++) {
... ...
q[l] = q[l] + 1.0; lq[l] = lq[l] + 1.0;
// array q[] fits into // array q[] fits into
local memory local memory
... Hot ...
} spot }
q[] = lq[];
} }](https://image.slidesharecdn.com/npbep-110824115535-phpapp01/85/NAS-EP-Algorithm-15-320.jpg)
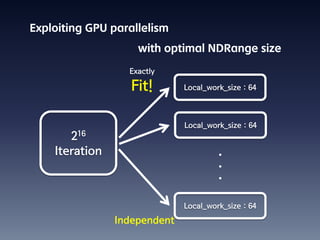

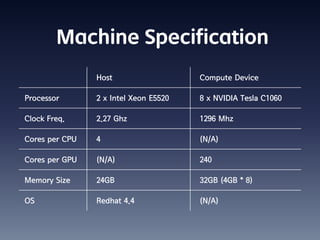
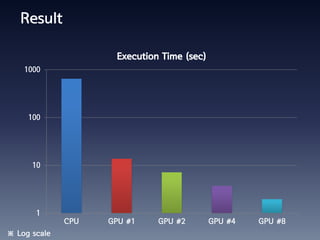
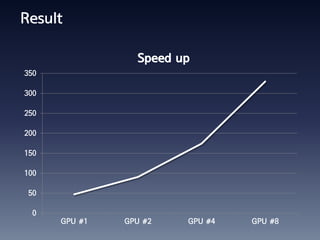


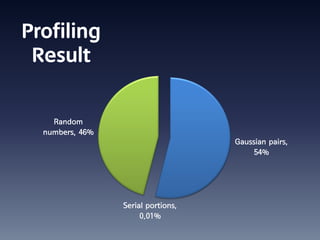
This document summarizes random number generation using OpenCL. It discusses the Marsaglia polar method for generating random numbers and Gaussian pairs. It presents pseudocode for the Gaussian pair generation algorithm. Profiling results show that 54% of time is spent generating Gaussian pairs while 46% is for random numbers. The document also discusses optimization techniques like using local memory, coalesced global memory access, and choosing an optimal work group size. Performance results show near linear speedup from 1 to 8 GPUs.












































![[Harvard CS264] 16 - Managing Dynamic Parallelism on GPUs: A Case Study of Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/managingdynamicparallelism-110430142356-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



