Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Bhuridech Sudsee
2,857 views
เสี่ยวเอ้อสอน Spark
หนังสือสั้นๆ เกี่ยวกับ Spark
Software
◦
Related topics:
Apache Spark
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 72 times
1
/ 30
2
/ 30
3
/ 30
4
/ 30
5
/ 30
6
/ 30
7
/ 30
8
/ 30
9
/ 30
10
/ 30
11
/ 30
12
/ 30
13
/ 30
14
/ 30
15
/ 30
16
/ 30
17
/ 30
18
/ 30
19
/ 30
20
/ 30
21
/ 30
22
/ 30
23
/ 30
24
/ 30
25
/ 30
26
/ 30
27
/ 30
28
/ 30
29
/ 30
30
/ 30
More Related Content
PDF
Spark Compute as a Service at Paypal with Prabhu Kasinathan
by
Databricks
PDF
Efficient Data Storage for Analytics with Apache Parquet 2.0
by
Cloudera, Inc.
PPTX
Apache Tez - A New Chapter in Hadoop Data Processing
by
DataWorks Summit
PDF
Data Visualisation for Data Science
by
Christophe Bontemps
PDF
The Parquet Format and Performance Optimization Opportunities
by
Databricks
PPTX
Text Similarity
by
Abdul Baquee Muhammad Sharaf
PPTX
Building a modern data warehouse
by
James Serra
PPTX
Hadoop Training | Hadoop Training For Beginners | Hadoop Architecture | Hadoo...
by
Simplilearn
Spark Compute as a Service at Paypal with Prabhu Kasinathan
by
Databricks
Efficient Data Storage for Analytics with Apache Parquet 2.0
by
Cloudera, Inc.
Apache Tez - A New Chapter in Hadoop Data Processing
by
DataWorks Summit
Data Visualisation for Data Science
by
Christophe Bontemps
The Parquet Format and Performance Optimization Opportunities
by
Databricks
Text Similarity
by
Abdul Baquee Muhammad Sharaf
Building a modern data warehouse
by
James Serra
Hadoop Training | Hadoop Training For Beginners | Hadoop Architecture | Hadoo...
by
Simplilearn
What's hot
PDF
Graph Database Meetup in Korea #4. 그래프 이론을 적용한 그래프 데이터베이스 활용 사례
by
bitnineglobal
PDF
Learning to rank
by
Bruce Kuo
PDF
Nosql data models
by
Viet-Trung TRAN
PDF
Apache Spark Tutorial | Spark Tutorial for Beginners | Apache Spark Training ...
by
Edureka!
PPTX
Choosing technologies for a big data solution in the cloud
by
James Serra
PPTX
Introduction to Apache Spark
by
Rahul Jain
PPTX
How to become Data Analyst?
by
Intellipaat
PPTX
Apriori Algorithm
by
International School of Engineering
PPTX
Exploratory data analysis
by
Peter Reimann
PPTX
File Format Benchmarks - Avro, JSON, ORC, & Parquet
by
Owen O'Malley
PDF
Challenges in transfer learning in nlp
by
LaraOlmosCamarena
PDF
MLlib: Spark's Machine Learning Library
by
jeykottalam
PPTX
Learn Apache Spark: A Comprehensive Guide
by
Whizlabs
PDF
How Adobe Does 2 Million Records Per Second Using Apache Spark!
by
Databricks
PPTX
Oltp vs olap
by
Mr. Fmhyudin
PPTX
Tdm probabilistic models (part 2)
by
KU Leuven
PDF
Preprocessing with RapidMiner Studio 6
by
Big Data Engineering, Faculty of Engineering, Dhurakij Pundit University
PDF
หนังสือภาษาไทย Spark Internal
by
Bhuridech Sudsee
ODT
Text Mining - Data Mining
by
Boonlert Aroonpiboon
PPTX
03 data preprocessing
by
นนทวัฒน์ บุญบา
Graph Database Meetup in Korea #4. 그래프 이론을 적용한 그래프 데이터베이스 활용 사례
by
bitnineglobal
Learning to rank
by
Bruce Kuo
Nosql data models
by
Viet-Trung TRAN
Apache Spark Tutorial | Spark Tutorial for Beginners | Apache Spark Training ...
by
Edureka!
Choosing technologies for a big data solution in the cloud
by
James Serra
Introduction to Apache Spark
by
Rahul Jain
How to become Data Analyst?
by
Intellipaat
Apriori Algorithm
by
International School of Engineering
Exploratory data analysis
by
Peter Reimann
File Format Benchmarks - Avro, JSON, ORC, & Parquet
by
Owen O'Malley
Challenges in transfer learning in nlp
by
LaraOlmosCamarena
MLlib: Spark's Machine Learning Library
by
jeykottalam
Learn Apache Spark: A Comprehensive Guide
by
Whizlabs
How Adobe Does 2 Million Records Per Second Using Apache Spark!
by
Databricks
Oltp vs olap
by
Mr. Fmhyudin
Tdm probabilistic models (part 2)
by
KU Leuven
Preprocessing with RapidMiner Studio 6
by
Big Data Engineering, Faculty of Engineering, Dhurakij Pundit University
หนังสือภาษาไทย Spark Internal
by
Bhuridech Sudsee
Text Mining - Data Mining
by
Boonlert Aroonpiboon
03 data preprocessing
by
นนทวัฒน์ บุญบา
Similar to เสี่ยวเอ้อสอน Spark
PDF
Big data
by
Satra Eadtrong
PDF
Managing Big Data with Apache Hadoop.pdf
by
NETsolutions Asia: NSA – Thailand, Sripatum University: SPU
PDF
Tdc manual
by
Kosin Mechoosin
PDF
20100924 digital-standard
by
Boonlert Aroonpiboon
PPT
Unit10
by
pui003
PDF
หน่วยการเรียนรู้ที่ 2 p
by
Wareerut Suwannalop
PDF
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
by
hattayachuesomkiet
PDF
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
by
hattayachuesomkiet
PDF
05 demon-web of science
by
Suchitra Yodsaneha
PDF
Lesson 1
by
Thanchanok Phongchareon
PDF
Pqdt global 2014
by
maethaya
PDF
เครื่องมือเทคโนโลยีสารสนเทศฟรีที่น่าใช้
by
Kanda Runapongsa Saikaew
PDF
07
by
alachiscake
PDF
Meetup Big Data by THJUG
by
Peerapat Asoktummarungsri
PPT
Pqdt
by
Suntis Fusagul
PPT
Iel
by
Kittiya Suthiprapa
PPT
คู่มือ EndNoteX5
by
Dulyarat Gronsang
PPT
คู่มือ EndNoteX5
by
Dulyarat Gronsang
PPT
คู่มือ EndnoteX5
by
Dulyarat Gronsang
PDF
Big data 101
by
Somkiat Puisungnoen
Big data
by
Satra Eadtrong
Managing Big Data with Apache Hadoop.pdf
by
NETsolutions Asia: NSA – Thailand, Sripatum University: SPU
Tdc manual
by
Kosin Mechoosin
20100924 digital-standard
by
Boonlert Aroonpiboon
Unit10
by
pui003
หน่วยการเรียนรู้ที่ 2 p
by
Wareerut Suwannalop
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
by
hattayachuesomkiet
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
by
hattayachuesomkiet
05 demon-web of science
by
Suchitra Yodsaneha
Lesson 1
by
Thanchanok Phongchareon
Pqdt global 2014
by
maethaya
เครื่องมือเทคโนโลยีสารสนเทศฟรีที่น่าใช้
by
Kanda Runapongsa Saikaew
07
by
alachiscake
Meetup Big Data by THJUG
by
Peerapat Asoktummarungsri
Pqdt
by
Suntis Fusagul
Iel
by
Kittiya Suthiprapa
คู่มือ EndNoteX5
by
Dulyarat Gronsang
คู่มือ EndNoteX5
by
Dulyarat Gronsang
คู่มือ EndnoteX5
by
Dulyarat Gronsang
Big data 101
by
Somkiat Puisungnoen
More from Bhuridech Sudsee
PDF
Git ฉบับอนุบาล 2
by
Bhuridech Sudsee
PDF
18 ฝ่ามือพิชิต docker
by
Bhuridech Sudsee
PDF
The bounded buffer
by
Bhuridech Sudsee
PDF
Xss and sql injection
by
Bhuridech Sudsee
PDF
OPD System with ZK Grails
by
Bhuridech Sudsee
PDF
Kafka for developer
by
Bhuridech Sudsee
PDF
sample plot 3D form depth map using OpenCV
by
Bhuridech Sudsee
PPTX
Introduction to Quantum Computing
by
Bhuridech Sudsee
PDF
Websocket & HTML5
by
Bhuridech Sudsee
PDF
Networking section present
by
Bhuridech Sudsee
PDF
Jpa sa-60
by
Bhuridech Sudsee
PDF
illustrator & design workshop
by
Bhuridech Sudsee
PDF
Market management with ZK Grails
by
Bhuridech Sudsee
PDF
Phonegap book
by
Bhuridech Sudsee
PDF
Cloud computing
by
Bhuridech Sudsee
PDF
Breast Cancer data mining KDD
by
Bhuridech Sudsee
PDF
$ Spark start
by
Bhuridech Sudsee
PDF
Producer and Consumer problem
by
Bhuridech Sudsee
PDF
operating system
by
Bhuridech Sudsee
PDF
VBoxManage tutorial
by
Bhuridech Sudsee
Git ฉบับอนุบาล 2
by
Bhuridech Sudsee
18 ฝ่ามือพิชิต docker
by
Bhuridech Sudsee
The bounded buffer
by
Bhuridech Sudsee
Xss and sql injection
by
Bhuridech Sudsee
OPD System with ZK Grails
by
Bhuridech Sudsee
Kafka for developer
by
Bhuridech Sudsee
sample plot 3D form depth map using OpenCV
by
Bhuridech Sudsee
Introduction to Quantum Computing
by
Bhuridech Sudsee
Websocket & HTML5
by
Bhuridech Sudsee
Networking section present
by
Bhuridech Sudsee
Jpa sa-60
by
Bhuridech Sudsee
illustrator & design workshop
by
Bhuridech Sudsee
Market management with ZK Grails
by
Bhuridech Sudsee
Phonegap book
by
Bhuridech Sudsee
Cloud computing
by
Bhuridech Sudsee
Breast Cancer data mining KDD
by
Bhuridech Sudsee
$ Spark start
by
Bhuridech Sudsee
Producer and Consumer problem
by
Bhuridech Sudsee
operating system
by
Bhuridech Sudsee
VBoxManage tutorial
by
Bhuridech Sudsee
เสี่ยวเอ้อสอน Spark
2.
เสี่ยวเออสอน Spark ในยุทธจักรการประมวลผลแบบกระจายหรือ Distributed
computing นั้น หากผูใดไมรูจัก Apache Spark แลวหละก็ตองถือวาผูนั้นมิใชมือกระบี่แตเปนเพียงเสี่ยวเออบารีสตาตามโรงเตี๊ยมก็เพียงเทานั้น แตทาน กลาววาหากผูใดรูถึงเคล็ดวิชาแลวไซรแมรางกายเปนเพียงเสี่ยวเออ แตลมปรานพรุงพลานดั่งเซียนกระบี่สวรรค วิถีชีวิตเสี่ยวเออที่จักไดถายทอดวิชาในตําราลับเลมนี้ก็เพียงหวังวาจะไดเผยแพรวิทยายุทธใหเหลาเสี่ยวเออเอา ไวดูแลตนเองและอุปถัมภคํ้าชูยุทธภูมินี้สืบไป เรื่องเลาของชาวยุทธ “หนทางหมื่นลี้เริ่มที่กาวแรก” สุภาษิตจีนนี้ยอมใชไดกับความเกาของยุทธจักรที่จะไดมาเลาใหมใหสู กันฟง หายจะยอนจากจุดหมายปลายทางที่เราอยูกลับไปในอดีตก็จะทําใหเกิดความเขาใจในกาลปจจุบัน และ คาดเดาสิ่งที่จะเกิดขึ้นในอนาคตได ดังนั้นตําราเลมนี้จึงจักไดเลาถึงความเกาสักเล็กนอยพอไดอรรถรส เปดยุทธจักร Distributed computing หากจะศึกษาใหเปนขั้นเปนตอนสักเล็กนอยก็คงตองเอาความแตกตางกันระหวางคําที่มันความหมาย เกี่ยวของกันซะกอน โดยจักขอเริ่มที่คําวา Concurrency เสียกอน โดยความหมายของ Concurrency คือการ ที่เรามีงานสักงานหนีงแลวงานนั้นสามารถที่จะแบงซอยยอยๆ ไดเหมือนรัชดาซอย 3 สถานฑูตจีนถึง รัชดา ซอย 17 โพไซดอน ที่เราจะไปซอยไหนกอนก็ได (ลอเลน) จริงๆ แลวเรื่อง Concurrency นี่คุยวาเราสามารถ แบงงานเปนสวนๆ แลวคอยทําไดเชนหากเรามีนํ้าชาที่จะเสริฟแขกอยู มันตองอุนอยูตลอดเวลา แตถาหากวา เรามีเตาเดียวที่ตองนึ่งซาลาเปาไปดวย เราก็สามารถนึ่งซาลาเปาไปแพบหนึ่ง แลวก็สลับตมนํ้าชาแพบหนึ่ง พอ ทําแบบนี้แลวก็จะเห็นวาตอใหเถาแกมีแคเตาเดียวเราก็ยังสามารถทํางานไดสอบอยางอยูนะ แตอาจจะไมไดดี เทาไหรก็ตามมีตามเกิดไป ทีนี้ถาเปน Parallelism หละก็มันจะเหมือนเถาแกใจดีที่ทําเตาใหเราหลายเตา สมมุติวาที่รานมีเตา เพิ่มมาเปนสองเตา เราก็สามารถคางหมอนึ่งซาลาเปาไปพรอมๆ กับอุนชาไปไดพรอมๆ กัน แตถาเถาแกขยาย รานไปอีกโดยการเพิ่มหมอนึ่งเปน 2 และเพิ่มหมอตมชาเปน 2 แลวจะสลับกันใชเตาถานที่มีอยูเพียงสองเตา แบบ Concurrency คือนึ่งซาลาเปาสลับกับตมชาก็บใชปญหาแตอยางใด จะเห็นวาที่จริงแลว Parallelism กับ Concurrency ไมใชของอยางเดียวกันซะทีเดียว กลับมาถึงเรื่องของ Distributed กันบาง แมจะใชคําที่ใชปนกันจนหมุนอุยปุย แตถึงยังไงมันก็ยังไมใช ของอยางเดียวกันอยูนั่นเอง ซึ่ง Distributed มันมักจะถูกพูดถึงในแนของตําแหนงที่ตั้งของทรัพยากรมากกวา เชนสมมุติวาที่รานเถาแกเรามี 2 เตาแชรเตารวมกับรานอาซิ้มอีก 2 เตา แบบนี้ตําแหนงชองเตาอยูคนละที่กัน
3.
แตก็มีเปาหมายรวมกันคือการใหบริการลูกคา ซึ่งมันอาจจะถูกมองวาคลายๆ กับคลัสเตอร
(Cluster) แตก็แตก ตางกันอยูบาง เพราะโดยทั่วไปแลว มักจะถูกกลาวถึงในลักษณะของกลุมของที่ทํางานแบบเดียวกันซึ่งในกรณีนี้ ถาจะกลาววาเตาที่รานเถาแกสองเตานั้นเปนหนึ่งคลัสเตอรและเตาที่รานอาซิ้มก็เปนอีกคลัสเตอรหนึ่งที่ Distributed กันอยูก็คงจะไมผิดแตประการใด นี่ยังไมรวมถึง Cloud computing ที่พูดถึงเรื่องการใชทรัพยากรที่คนใชไมจําเปนตองสนใจ 4 หรือ 8 ใดๆ แคมีเงินจายก็พอ หรือ Grid computing ที่กลาวถึงการเอาทรัพยากรมาแชรกันตรงกลางระหวางหนวย งานตางๆ ตามนโยบายยุคกลางป ‘90s ที่บางทีขอใชงานไปแลวตั้งแต ป.ตรีจนจบ ป.เอก เพิ่งได Account เขา ใชที่ Install โปรแกรมใดๆ ไมได บนเครื่องที่แรงที่สุดในสมัยนั้นอยาง Pentium 4 (อสกข.) ในสวนนี้ยังมีราย ละเอียดปลีกยอยอีกเยอะไปอานเพิ่มดวยก็ดีนะ (เผื่อปรมาจารยมาอานทานจะบอกวามันบแมนๆ มันเปนแบบ อื่น พะนะ… ละเอียดกวานี้ก็หาอานเอาโลดสู) มุมมองของความขนาน เราจะเขาถึงศาสตรของการขนานไมไดเลย ถาเรายังไมเขาใจวาจะมองวามันขนานกันไดยังไง บังเอิญ ไปเจอตําราหนึ่งซึ่งมันดีมาก เลาถึงเรื่องวิธีคิดของการขนานกันซึ่งมีอยูสองสวนคือ การขนานกันของขอมูล (Data parallelism) ซึ่งเปนเรื่องที่บอกวาถาเรามีฟงกชั่นเดียวกันก็สงไปหลายๆ ที่ใหชวยกันประมวลผลไดนี่ หวาถาการประมวลผลของเรามีแคบวกเลข แบบนี้เราจะแบงกันบวกก็ไมผิดกติกาใดๆ เชน ชุดขอมูล A = A[1]+A[2] แบบนี้ถาแบงออกเปนชุดขอมูล B แลวก็แบง B = B[1]+B[2] ก็ยอมได เปรียบกับถาโรงเตี๊ยมของ เรามีสูตรการทําเสี่ยวหลงเปาและมีวัตถุดิบพอแลวหละก็เราจะสงไปใหพอครัวหลายๆ คนชวยกันทําก็ยิ่งจะ ทําใหอาหารที่ลูกคาสั่งเสร็จไดเร็วขึ้น แตก็ยังมีการขนานอีกรูปแบบหนึ่งคือ การขนานกันของฟงกชัน (Function parallelism) วากันถึง เรื่องการแบงสวนงานที่ไมเกี่ยวของกันออกจากกัน แลวคอยนําผลลัพธมาประกอบกันทีหลังได เชน F = (A*B) + (C*D) แบบนี้จะเห็นวาเอา A*B กับ C*D แยกกันทํางานก็ไมมีปญหาอะไร พอทั้งคูเสร็จแลวคอยเอามาบวก กันเพื่อไดผลลัพธสุดทาย เสมือนหนึ่งวาถาลูกคาสั่งนํ้าเตาหูปาทองโกแลวเสี่ยวเออผูนั้นก็สามารถใหเพื่อนสอง คนชวยโดยใหคนแรกไปเอานํ้าเตาหูจากเขาอากินะ อีกคนไปเอาปาทองโกจากเขาเหลียงซาน เสร็จแลวใสถาด เดียวกันเอามาเสริฟได cc :http://www.ku.ac.th/scc2009/SCC2009_advance.pdf วิทยายุทธ MapReduce จุดเริ่มตนเนื้อเรื่องอันวุนวายนี้เกิดจาก Google พรรคพี่ใหญในยุทธภพที่ตองการแสดงอานุภาพของ วิทยายุทธที่ใชภายในอยู ดวยการติพิมพเปเปอรเรื่อง MapReduce : Simplified Data Processing on Large Clusters เมื่อป ค.ศ. 2004 โดยปา Jeffrey Dean และ Sanjay Ghemawat โดยเนื้อหาจะมีใจความ วา MapReduce เปนโมเดลการแกปญหาแบบนี้ที่ถาเราแบงปญหาออกใหอยูในรูปแบบนี้แลวเราจะสามารถ
4.
ประมวลผลขอมูลที่มีขนาดใหญไดโดยงาย เพราะรูปแบบการเขียนโปรแกรมทําใหสามารถเกิดการประมวลผล แบบ Parallelism
ไดอัตไนมัติ ฟงดูยากเติบอยูแตเดี๋ยวอธิบายใหฟง แตเดี๋ยวใหดูรูปภาพรวมกอน จากภาพนี้จะเห็นวาหากเรามีหมูเห็ดเปดไกนํ้าตามรูปแลวหละก็ เราสามารถแยกออกเปนขอมูลสองสวน คือ สวนหนาเครื่องหมายคอมมา(,)และสวนหลังเครื่องหมายคอมมา (บอกเพื่อ?) นั่นแหละ จากนั้นเราก็จะสามารถ แปลงเปนอีกอยางได ถาตามตัวอยางจะเห็นวาในขั้นตอนแรกมี Input กองกันอยู จากนั้นเราจะนําเอา Input ไปเขาฟงกชัน Map ซึ่งเปนฟงกชันที่ทําหนาที่สราง Intermediate Key/Value pair พุนเด ชื่ออยางเทหจริงๆ ไมมีอะไรมัน ทําหนาที่สรางแมพของสวนหนาและสวนหลังจากที่ไมเคยมีอยู ถาเราดูภาพในสวน Input ที่อยูซายมือสุด Map คือการเอาสัตวแตละตัวไปเขาคูซึ่งสวนหนาเปนสัตวตัวนั้นๆ และสวนหลังเปนตัวเลข 1 จากนั้นกลไกของ เฟรมเวิรค MapReduce ก็จะทําการ Shuffle ซึ่งขั้นตอนนี้เปนการพยายามที่จะจัดกลุมของขอมูลเอาไวดวย กัน จากภาพจะเห็นวาเสือและหมูนั้นมีอยางละ 2 ตัว ดังนั้นพอพยายามเอามารวมกันแบบงายๆ เลยไดสวน หลังเปนอาเรยของเลข 1 และเพราะวาขอมูลเรามีไดแคสองสนคือสวนแรกและก็สวนหลัง ถาเก็บเปนอาเรยตอ ใหขางในมีหลายตัวในมุมมองของระบบก็จะมองวามันเก็แคอารเรยตัวเดียวโดยไมไดสนใจของขางในวามีกี่ตัว หลังจากนั้นก็จะเขาไปสูฟงกชันที่สองคือฟงกชัน Reduce ซึ่งเปนฟงกชันที่รับขอมูลมาจาก Intermediate Key/Value pair หลังจากผานกลไก Shuffle แลวเขามาเพื่อทําการลดรูปใหเปนอีกรูปหนึ่ง ซึ่ง ในรูปตัวอยางสัตวพวกนี้เปนการนับจํานวน ซึ่งหนาที่ของฟงกชัน Reduce คือเอาอาเรยตัวหลังมาบวกกันทุก ตัวทําใหรูวาสัตวแตละชนิดมีกี่ตัวและจะเห็นวาการแยกแบบนี้ทําใหสามารถประมวลผลขนานกันไปได เพราะ
5.
การประมวลผลนั้นไมจะเปนตองไปยุงเกี่ยวกับสวนอื่นเราเลยสามารถนับจํานวนหมูเห็ดเปดไกนํ้าเตาปูปลาได นั่นเอง เพื่อใหงงมากยิ่งขึ้นจักไดอธิบายเพิ่มเติมสักนิดหากโรงเตี๊ยมเราเปดเฟรนไซนขึ้นมามีหลายสาขาแลว เถาแกอยากรูวาคนที่ซื้อเยอะที่สุดนี่เขาซื้อกี่บาท เสี่ยวเออแบบเราๆ ก็จัดใหปาแกไดจากการคนตั๋วสั่งอาหาร จากนั้นเอามาลงบันทึกเรยงกันไดความแบบนี้ โรงเตี๊ยมแปะ
สาขาเขาเหลียงซาน, 32, 21/3/2018 18:00 โรงเตี๊ยมแปะ สาขาเขาเหลียงซาน, 102, 1/4/2018 20:00 โรงเตี๊ยมแปะ สาขาพรรคกระยาจก, 199, 1/4/2018 20:00 โรงเตี๊ยมแปะ สาขาบูตึ้ง, 500 ,5/5/2016 10:00 จากนั้นเราก็สราง Map โดยตัดคําที่เราไมตองใชออกจะไดของหนาตาประมาณนี้เปน Intermediate Key/Value pair (สาขาเขาเหลียงซาน, 32) (สาขาเขาเหลียงซาน, 102) (สาขาพรรคกระยาจก, 199) (สาขาบูตึ้ง, 500) เสร็จแลวระบบของ MapReduce ก็จะทําขั้นตอนการ Shuffle ไดหนาตาของ Intermediate Key/Value pair ประมาณนี้ (สาขาเขาเหลียงซาน, [32,102]) (สาขาพรรคกระยาจก, 199) (สาขาบูตึ้ง, 500) จากนั้นก็เอาไปเขาฟงกชัน Reduce ซึ่งฟงกชันนี้เรากําหนดใหหาตัวที่มากที่สุดเอาไว สุดทายก็จะไดหนาตา แบบนี้ออกมา (สาขาเขาเหลียงซาน, 102) (สาขาพรรคกระยาจก, 199) (สาขาบูตึ้ง, 500)
6.
อยางไรเสีย MapReduce ที่เราพูดกันตั้งแตตนถึงตอนนี้นั้นยังเปนแนวคิดการเขียนโปรแกรมซึ่งผูพัฒนาอาจจะ เลือกทําตาม
ไมทําตามหรือเพิ่มเติมในบางสวนได แตหลักใหญใจความก็ยังจะวนๆ ถึงการแยกขอมูลเปนคู Key กับ Value (หรือสวนหนากับสวนหลังนั่นแหละ) และหวัใจอีกอยางคือการที่มีฟงกชัน Map และฟงกชัน Reduce นั่นเอง กอกําเนิด Hadoop จะไมพูดถึง Apache Hadoop ก็ดูจะไมใหเกียรติกัน เพราะวาหลายๆ เจาตอนนี้ก็ยังรัน Hadoop กัน อยู ตัว Hadoop นั้นถือวาเปตตัวบุกเบิกการนํา MapReduce ไปใชงานในวงกวางเลยแหละ เนื่องจาก Google เปดเผยการใช GFS มาในเอกสาร The Google File System และ MapReduce มาในเอกสาร MapReduce : Simplified Data Processing on Large Clusters ก็จริงแตไมไดเปดตัวโคดมาใหดวย (Dafuq!!) ก็เลยมีจอมยุทธพอลูกออนชื่อวา Doug Cutting และเพื่อนรวมงาน Mike Cafarella จาก Yahoo ซึ่งแตกอนก็ทํา Apache Nutch (เปน Search-engine โปรเจกโดย Yahoo และเปนโปรเจกยอยของ Apache Lucene อีกทีหนึ่ง) ทํา Apache Nutch ไปๆ มาๆ ดังแลวเลยแยกวงเปน Apache Hadoop ใช โลโกเปนรูปชางสีเหลืองและชื่อ Hadoop นี่เองก็ไดไอเดียมาจากของเลนลูกของ Doug ซึ่งงายตอการออก เสียง เกร็ดเล็กนอยของการตั้งชื่อนี้ก็คือคําวา Googol ที่หมายถึงเลขจํานวนมหาศาล (ใชอธิบายความแตกตาง วามากมหาศาลกับความเปนอนันตนั้นไมเทากัน) คําวา Googol มันถูกนิยามวาเลข 1 แลวตามดวย 0 จํานวน 100 ตัว ซึ่งคํานี้มาจากหลานชายวัย 9 ขวบของนักคณิตศาสตร Edward Kasner ซึ่ง Larry Page จาก Google นั้นชื่นชมในตัวเขาจึงตองการใช Googol เปนชื่อโดเมน แต Sean Anderson เพื่อนของเขาพิมพผิด เปน Google.com แต Page ก็เห็นวาชื่อนี้วางอยู และเขาเองก็ชอบดวยเลยเลือกใชชื่อนี้ ตัว Hadoop ทั้ง Stack มีตัวประกอบหลักๆ คือ Hadoop Common เปน Library และพวกการทํางานพื้นฐานไวใหตัวอื่นเรียกใช Hadoop Distributed File System (HDFS) เปนระบบไฟลแบบกระจายเก็บขอมูลไวบนหลายๆเครื่อง
7.
Hadoop YARN เปนตัวจัดวางงาน Hadoop
MapReduce ตัวที่ใชประมวลผลขอมูลแบบ MapReduce เปดตํานาน Apache Spark หากจะเรียนรูเคล็ดวิชาใหถึงรากถึงแกนนั้นประวัติที่มาของเคล็ดวิชาก็มิ อาจมองขามไปดวยเห็นวาเปลาประโยนชเสียทีเดียว สําหรับเคล็ดวิชา Apache Spark นี้ก็ตองขอเลายอนไปถึงประวัติการกอกําเนิดวาเริ่มตั้งแตป ค.ศ. 2009 โดย RAD Lab ซึ่งภายหลังเปลี่ยนเปนชื่อ AMPLab ซึ่งเปนหนวยงานในสังกัด ของมหาลัย UC Berkeley เคล็ดวิชานี้ไดเริ่มประสานลมปรานโดยจอมยุทธ นามวา Matei Zaharia ถัดมาหนึ่งปคือ ค.ศ. 2010 ก็ไดเปดเปนโอเพนซอส ภายใตสัญญาอนุญาตแบบ BSD จากนั้นชวงเดือนมิถุนา ค.ศ. 2013 ไดบริจาคใหกับมูลนิธิซอฟตแวร Apache (ASF) ทําใหเวลาเรียกขานสามารถใชไดทั้ง Apache Spark หรือ Spark เฉยๆ ก็ได จะเห็นวาการเรียก ซอฟตแวรมี Apache นําหนานี้ก็เนื่องมาจากเปนซอฟตแวรที่อยูภายใชการดูแลขององคกรแลวนั่นเอง ลักษณะ การประมวลผลแบบ MapReduce ของ Spark นั้นจะใกลเคียงกับ Hadoop อยางมาก แตก็มีบางสวนที่ Spark ชวยใหการประมวลผลมีประสิทธิภาพมากขึ้น โดยที่ตัว Spark เองนั้นใชหนวยความจําเปนหลักแตใน สวนของ Hadoop นั้นมุงเนนไปที่ฮารดดิสกเปนหลัก ตัว Spark เองนั้นสรางมาจากภาษา Scala ซึ่งเปนภาษา ที่การทํางานนั้นรันอยูบน Java Virtual Machine หรือ JVM เชนเดียวกันกับ Java ทําใหสามารถใช Java เชื่อมตอได นอกจากนี้ Spark เองยังรองรับการเชื่อมตอผานทางภาษา Python อีกดวย ออๆ ประวัติคนสราง นี่ก็ไมธรรมดานะ ไอหมอนี่เคยไดรางวัลที่ 3 การแขง ACM-ICPC ระดับโลกเมื่อป ค.ศ. 2005 มาแลว และ นอกจากจะเปนคนสราง Spark แลวอัลกอริทึมจัดการงานของ Hadoop เองก็เปนฝมือของเขา ออๆ เขาเปน หนึ่งในคนสราง Apache Mesos ดวยนะ รวบรวมลมปราน วากันในหมูชาวยุทธวาหากจะเขาใจถึงแกนของสิ่งใดนั้นตองประกอบกันทั้งบูและบุน ทําใหวรยุทธกับ ลมปรานรวมเปนหนึ่งจึงใชพลังนั้นไดอยางแทจริง ในการเรียนรูการศึกษากับการปฏิบัตินั้นหากไดทําคูกันแลว ทานวาจะเกิดอานุภาพของการเรียนรูไดเต็มที่ ตําราเลมนี้จึงมีสวนที่เปนทั้งบูคือการปฏิบัติและทฤษฎีที่มี เนื้อหาเลาอธิบาย เปรียบดังการขับจักรยานที่เราไมสามารถขับไดโดยอานเพียงตําราไมไดหัดซอม และเราจัก เสี่ยงอันตรายหากหัดขับโทยไมศึกษาวิธี เคล็ดวิชา Apache Spark คืออะไร ?
8.
ซอฟตแวร Apache Spark
เปนเฟรมเวิรคแบบโอเพนซอสที่ใชประมวลผลขอมูลแบบกระจายที่มี ลักษณะการประมวลผลแบบทั่วไป พอแปลตรงๆ แลวฟงดูแปลกๆ แตใหเขาใจวามันไมไดถูกออกแบบมาเพื่อ งานใดโดยเฉพาะ มันจึงสามารถถูกปรับใชไดกับงานหลายๆ อยาง ซึ่งโดยปกติแลวคาเริ่มตนของมันถูกกําหนด ใหประมวลผลบนหนวยความจํา และหนวยความจําที่กลาวถึงตอไปก็จะเปนพวก RAM อะนะ (เดี๋ยวโดนวา หนวยความจํามีหลายแบบ บลาๆๆ) เอาตอ! ทีนี้ Spark เองก็สนับสนุนใหเกิดพวก ETL หรือ Extract - Transform - Load นะ ซึ่ง Extract คือขั้นตอนการเอาขอมูลจากแหลงอื่นที่อาจจะมีรูปแบบการเก็บแตตาง กัน มา Transform ใหเปนรูปแบบที่เราอยากได จากนั้น Load เขาไปเก็บใน Data warehouse ซึ่งตัว Spark เองก็สามารถทํากลไก ETL ที่กลาวไปนี้ได หรือจะทําการวิเคราะหขอมูล การทํา Machine learning รวมทั้ง การประมวลผลแบบกราฟ ซึ่งทั้งตัว Batch บนขอมูลที่ถูกเก็บอยูแลวและตัว Streaming บนขอมูลที่มีการ เปลี่ยนแปลงตามเวลาเปน Time series ไดดวย จากภาพจะขอโฟกัสไปที่ตัวขนมชั้นที่อยูตรงกลางคือชั้นที่เปนของ Spark Core ซึ่งเปนหัวใจของเคล็ดวิชาซึ่ง เกือบทั้งหมดของตําราเลมนี้ก็จะวากันดวยเรื่อง Spark Core นี่เอง จากนั้นขอใหยายหางตาไปเหลือบมองดาน บนที่เปนสวน เสร็จแลวจึงจะเหลาดานลางตอไป Spark Core สวนนี้เรียกไดวาเปนหัวใจของ Spark เลยก็วาไดเนื่องจากวาเปนตัวที่ใชเอาใหใหสวนอื่นๆ ที่เปน สวนประกอบยอยที่เปนไลบรารี่ เชน Spark SQL หรือ MLlib เขามาติดตอเพื่อใชงาน หรือเราจะใชวิธีเขียน โคดเพื่อเชื่อมตอกับ Spark เขาไปตรงๆ ก็ไดเหมือนกัน โดยที่กลไกการจัดการเชน Scheduler ที่เอาไวจัดการ งาน รวมทั้งกลไกการจัดการหนวยความจํา กลไกกูคืนขอผิดพลาดลวนแตอยูในสวนนี้ทั้งสิ้น
9.
Spark SQL กระบวนทานี้ใชสําหรับจอมยุทธทานใดที่อยากใช
SQL หรือ HQL (Hive Query Language) เรียกใชขอมูลก็แสนจะสะดวกสบาย แตก็มีขอแมนะวาขอมูลที่จะเอามาประมวลผลจะตองเปนขอมูลที่อยูในรูป แบบมีโครงสราง ดังนั้นจึงใชไดกับตัวแปรพวก DataFrame หรือ DataSet ซึ่งจะไดอธิบายตอไป นอกจากนี้ แลว Spark SQL ยังใชวิธีนําเขาขอมูลแบบเดียวกันไดไมวาจะเปนรูปแบบขอมูล Hive, Avro, Parquet. ORC, JSON หรือกระทั้ง JDBC และนอกจากนี้ตัวมันยังมีโหมดที่สามารถใหเครื่องมือที่เปน Business Intelligence (BI) เชื่อมตอเขามาผานทาง JDBC หรือ ODBC เพื่อประมวลผลขอมูลไดอีกตะหาก Spark Streaming ปกติการประมวลผลของ Spark นั้นก็จะทํางาน Workload ที่เแ็นลักษณะของ Batch job คืองานที่เปนงานประมวลผลกับขอมูลนิ่งๆ โดยประมวลผลเปนรอบๆ แตถาเราตองการประมวลผลขอมูล ที่ไมนิ่งเชนเราอยากวิเคราะห Log ของเซอรเวอรเพื่อนนําเสนอโปรโมชั่นใหลูกคาแบบ Real time นี่เราก็ ตองการเอาขอมูลมาวิเคราะหทันทีเลย ดังนั้น Spark Streaming จึงถูกออกแบบมาให Spark สามารถ ประมวลผลขอมูลแบบ Real time ได โดยที่ Operation คุณสมบัตรคงทนตอความลมเหลวที่ทําไดบน Batch ก็เรียกไดวา Streaming มีเหมือนกันเกือบทั้งหมด ละยังสามารถเชื่อมตอกับพวก HDFS, Flume, Twitter, RabbitMQ หรือ Kafka ได MLlib ใชประมวลผล Machine learning โดยที่ตัวไลบรารี่เองก็มีอัลกอริทึมบางตัวใหเลือกใชไดอยางสะดวก ไมวาจะเปนพวก Regression, Classification, Clustering หรือ Collaborative filtering ซึ่งการประมวลผล เหลานี้สามารถเอาเขาไปประมวลผลที่คลัสเตอรของ Spark ได GraphX ตัวนี้เปนไลบรารี่ที่ใชในการประมวลผลขอมูลแบบกราฟ ทําใหเราสามารถจัดการกับขอมูลแบบกราฟ มีทิศทางได เราสามารถใชกับอัลกอริทึมบางประเภทไดเชน Triangle counting หรืออัลกอริทึมยอดนิยมที่เคย ใชใน Seach engine ของ Google และตั้งชื่อตาม Larry Page วา PageRank ซึ่งเปนลักษณะการใหนํ้าหนัก ขอมูลตามลักษณะของกราฟนั่นเอง Cluster managers (Standalone | YARN | Mesos) ตัว Spark เองนั้นสามารถรันแบบ Local mode คือรันบนเครื่ืองของเราอยางเดียวไมเกี่ยวกับใครได แตวาถาจะใหดีการประมวลผลนั้นควรใชเครื่องหลายๆ โหนดชวยกันประมวลผล แตการจะทําแบบนั้นไดตองมีตัวจัดการระบบคลัสเตอร ซึ่งสามารถใชไดหลายแบบ แตถาจะใชตัวที่มีมาใหกับ Spark เลยก็เปนตัว Standalone ทั้งหมดที่กลาวมานั้นแมขาจะไมไดรูเรื่องและทดลองทุกกระบวนทา แตถาจับหลักไดแลวก็พอจะไปตอ ไดไมยากนัก ในเนื้อหาสวนนี้สรุปความไดวาจะตองใชตรงไหนอยางไรคราวๆ อยางนอยถาไมรูอะไรอยากให จับใจความของ Spark Core ใหไดกอน และเนื่องจากการประมวลผลของ Spark นั้นมักจะประมวลผลขอมูล
10.
ขนาดใหญหรือ Big Data
ดังนั้นขาจะขอกลาวถึงเล็กนอยพอเปนพิธีรีตอง Big Data นั้นกลาวกันวาเปนขอมูล ที่มีขนาดใหญจนไมสามารถประมวลผลไดบนเครื่องเดียว (มันเลยตองประมวลผลหลายเครื่องอันเปนที่มาของ ระบบ Spark ที่สามารถทําเปนคลัสเตอรได) โดยทั่วไปเราจะจัดกลุมมันเปน Big Data นั้นมีเงือนไข 3V ราวๆ นี้ คือ - Volume บอกวามันมีขนาดใหญ ตรงนี้มันก็ไมไดมีขอกําหนดอะไรที่ชัดเจนวาเทาไหรถึงจะ ใหญพอชวงแรกๆ เขาใจวา 19 GB นี่ก็ถือวาเยอะกันมากๆ แลว - Velocity คือขอมูลที่เราจะเอามาประมวลผลนั้นมันมีอัตราการเกิดขึ้นไดอยางรวดเร็ว กลาว คือบางทีแตกอนเราเก็บแคขอมูลการซื้อ ถาอยากทําใหเปน Big Data นั้นอาจจะเก็บขอมูล ทั้งหมดที่เขาเขามาไมวาจะเปนแหลงพี่พาเขาเขามาที่เปบเรา เขาเปรียบเทียบขอมูลตรงไหน บาง เขาเปรียบเทียบอะไรกับอะไรบาง ซึ่งขอมูลเหลานี้จะกอใหเกิดคุณคามหาศาลไดใน อนาคต เชนการนําเสนอโปรโมชั่นหรือใชทําการตลาดตอ - Variety ขอมูลที่ไดมานั้นมีรูปแบบหลากหลายอาจจะเปนขอมูล Logging จาก Web server ขอมูล Mouse focus ตางๆ เหลานี้อาจจะมีรูปแบบของขอมูลที่ไดมานั้นมีความหลากหลาย ตามไปดวย ทั่ง 3V เหลานี้ขาอยากใหพวกเราเสี่ยวเออนั้นมองตาเบลอๆ ก็พอ อยาไปจริงจังกับมันนั้น อยาลืมวา หนาที่เราคือเอาขอมูลออกมาประมวลผลเพื่อปรับปรุงโรงเตี๊ยมใหทันสมัยตอบโจทยจอมยุทธวัยโจไดอยางมี ประสิทธิภาพก็เทานั้น เพราะถึงเทคโนโลยีจะกาวไปไกลแคไหนผูคนในยุทธภพก็ยังมีความตองการคลายๆ เดิม อยูนั่นเอง และสําหรับเสี่ยวเออผูใดที่ยังลังเลสงสัยวาควรจะใช Spark ประมวลผล หรือเปลา ขอมูลเราเปน Big Data หรือไมนั้น ในยุกที่ผูคนสราง Data กันวันละหลาย GB ตอคน ก็ตองบอกไดเลยวา “ถาขอมูลมันยังไมใหญพอ ก็ทําใหมันใหญพอดิหวะ” เริ่มตนคนหากระบี่ ทุกปรมาจารยลวนมาจากเด็กฝกหัดฉันใด ทุกเซียนกระบี่ก็ลวน มาจากมือกระบี่ฝกหัดฉันนั้น ดังนั้นอยาไดเนียมอายหากเจาไปเจอจอม ยุทธที่มีวรยุทธมากมาย เขาก็อาจเคยเปนเสี่ยวเออมากอนเหมือนกัน แต ถาไมมีเจาอาจจะไดเปนคนแรกใหกินเนสบุคเรคอรดไดนะ ซึ่งในบทนี้จะ นําเสนอวิธีติดตั้ง Apache Spark โดยที่จะใชงานบน Cloud ของ
11.
Nipa.cloud ซึ่งสนับสนุน Cloud
มาใหลองเลน จึงขอโอกาสซูฮกมา ณ ที่นี้ดวยขอรับ 1) เขารวมยุทธภพ เพื่อไมใหเปนการตอความยาว สาวความยืด ขอเริ่มที่หลังจากสมัครเลยแลวกัน หลังจากที่เขามาให ลองสรางเครื่องกอนโดยไปที่เมนู Create ดานบนขวา ซึ่งวิธีการที่ลองเลนนี้เปนวิธีที่พยายามทําใหงาย อาจจะ ไมใชวิธีที่ดีที่สุด ดังนั้นถาพอจะมีเพลงกระบี่ติดตัวมาบางก็สามารถขามขั้นตอนไปไดตามอัธยาศัย
12.
หลังจากรอไมถึงนาทีเครื่องเราก็พรอมใชงานแลว เตรียมกระบี่ไมไผ หลังจากที่เราไดเครื่องเรียบรอยแลวก็สามารถเขาไปวิ่งเลนบนเครื่องซึ่งถาใครใช Windows ก็ตองติด ตั้งโปรแกรมที่สามารถเชื่อมตอผานทาง
SSH ไดเชน Putty แตถาใครใช Mac หรือ Linux อยูแลวก็โซโลไดเลย สิ่งที่ตองใชในการนี้ก็คือ JDK ซึ่งเปนตัวชุดพัฒนาซอฟตแวรของ Java, ตัว Scala ซึ่งเปนภาษาที่ใชในการ พัฒนา Spark เราเลยจําเปนตองติดตั้ง และสุดทายก็ตัวของ Spark เองที่ตองดาวนโหลดจากเว็บไซต
13.
กอนอื่นขอแนะนําใหใชคําสั่ง $ sudo
apt-get update เพื่ออัพเดทขอมูลของ Package สักรอบหนึ่ง กอน จากนั้นติดตั้ง JDK Version 8 โดยใชคําสั่ง (เนื่องจากขอจํากัดบางประการ Spark อาจจะเกิดปญหาหาก ใชกับ Java Version อื่นซึ่งอาจจะสรางปญหาใหกับมือใหมจึงขอใชเวอรชั่นที่ไมมีปญหานี้ไปกอน) $ sudo apt-get install openjdk-8-jdk แลวก็ติดตั้ง Scala
14.
$ sudo apt-get
install scala จากนั้นไปที่เว็บไซต Spark เพื่อดาวนโหลดไดที่ https://spark.apache.org/downloads.html กดตรงที่วงไววาเอาลิงคมา Download
15.
กด Copy Link
Address จากนั้นเอาลิงคนี้มาดาวนโหลด $ wget http://www-eu.apache.org/dist/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2. 7.tgz จากนั้นแตกไฟลสั่ง $ tar xf spark-2.3.2-bin-hadoop2.7.tgz จากนั้น cd เขาไปใน spark ที่แตกไฟลออกมา แลวลองสั่งรัน Spark ใช $ ./bin/spark-shell
16.
ถาเห็นหนาจอแบบนี้ก็เปนอันวาใชได ซึ่ง Spark
ก็มีมอนิเตอรใหเราแบบแกะกลองจากโรงงานดวย เราสามารถ เขาถึงไดผานทาง IP ของเครื่องนั้นบนพอรต 4040 ขอรับ ลวดลายกระบี่
17.
เมื่อเราไดกระบี่ไมไผมาสแลว เราก็สามารถซอมกระบี่ไดตามลวดลายตางๆ ซึ่งจะไดกลาวถึงตอไป
แต กอนอื่นขอแนะนําลักษะการใช ซึ่งจะคลายกับการใชงาน Lambda ใน Java นั่นเอง ชากอนพอหนุม !?! มันไมไดงายขนาดนั้น ขออธิบายยอนกลับไปนิดหนึ่งถามีแตคําสั่งสองคําสั่งนี้คืออานไฟล README.md แลวก็สั่งนับเลย val textFile = spark.read.textFile("README.md") textFile.count()
18.
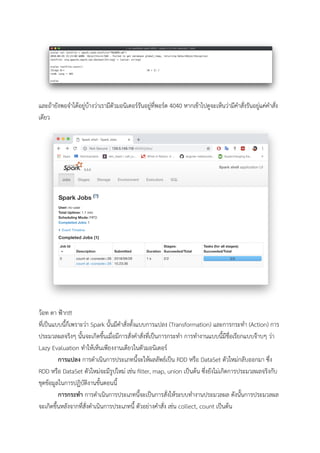
และถายังพอจําไดอยูบางวาเรามีตัวมอนิเตอรรันอยูที่พอรต 4040 หากเขาไปดูจะเห็นวามีคําสั่งรันอยูแคคําสั่ง เดียว วอท
ดา ฟาก!!! ที่เปนแบบนี้ก็เพราะวา Spark นั้นมีคําสั่งทั้งแบบการแปลง (Transformation) และการกระทํา (Action) การ ประมวลผลจริงๆ นั้นจะเกิดขึ้นเมื่อมีการสั่งคําสั่งที่เปนการกระทํา การทํางานแบบนี้มีชื่อเรียกแบบจาบๆ วา Lazy Evaluation ทําใหเห็นเพียงงานเดียวในตัวมอนิเตอร การแปลง การดําเนินการประเภทนี้จะใหผลลัพธเปน RDD หรือ DataSet ตัวใหมกลับออกมา ซึ่ง RDD หรือ DataSet ตัวใหมจะมีรูปใหม เชน filter, map, union เปนตน ซึ่งยังไมเกิดการประมวลผลจริงกับ ชุดขอมูลในการปฏิบัติงานขั้นตอนนี้ การกระทํา การดําเนินการประเภทนี้จะเปนการสั่งใหระบบทํางานประมวลผล ดังนั้นการประมวลผล จะเกิดขึ้นหลังจากที่สั่งดําเนินการประเภทนี้ ตัวอยางคําสั่ง เชน collect, count เปนตน
19.
โอเค ถึงตอนนี้ขาจักไดอธิบายถึงตัวมอนิเตอร ซึ่งไมใชจะมองผานไปเฉยๆ
ได เพราะตัวมอนิเตอรเองก็ มีสถานะหลายๆ อยางที่นาสนใจอยูเหมือนกัน มากเรามองดูที่งาน count ที่สั่งไป เมื่อกดดูดานใน จะเห็นขอมูลเปน Timeline ของการประมวลผลโดยในตอนแรกมีการเพิ่ม Executor เพื่อเขา มาทํางานใหเรา ตอนนี้เราทราบเพียงวา Executor เปนตัวประมวลผลใหเราก็พอ สวนใน Stage 0 และ Stage 1 ก็แสดงเวลาที่ใชในการประมวลผลแตาละ Stage นั่นเอง
20.
จะพบวามี 2 Stage
หากเลือกดูแตละ Stage กํบจะเห็นไดวามีอะไรไมรูอยูขางใน ซึ่งจะขอใหทําตาเบลอๆ เอา ไวกอนเพราะมันยังไมจะเปนตองเลาถึงนั่นเอง 1) Wordcount โปรแกรมนับคําเปนเสมือน Hello, world สําหรับวงเกรียน Map Reduce เลยก็วาไดโดยที่การ ทํางานของโปรแกรมก็มีราวๆ นี้ขอรับ
21.
2) Pi Estimation การประมาณคาพาย
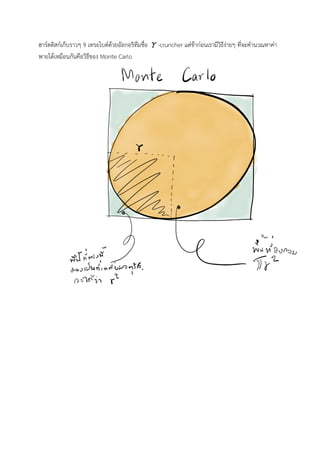
(Pi) เปนงานที่เปนลักษณะหนักไปทางประมวลผล ซึ่งงานหาคาพายเปนงานที่ ยอดฮิตมาหลายสมัยเทาที่ทราบลาสุดเราสามารถหาคาพายได 22 ลานลานตําแหนง (ไมไดเขียนผิด) ซึ่งตองใช
22.
ฮารดดิสกเก็บราวๆ 9 เทระไบตดวยอัลกอริทึมชื่อ
γ-cruncher แตชากอนเรามีวิธีงายๆ ที่จะคํานวณหาคา พายไดเหมือนกันคือวิธีของ Monte Carlo
23.
import scala.math.random
24.
val n =
Int.MaxValue val count = sc.parallelize(1 to n).filter { _ => val x = math.random val y = math.random x*x + y*y <= 1 }.count() println(s"Pi is roughly ${4.0 * count / n}") (*** ถาวางโคดหลายบรรทัดไมไดลองสั่ง :paste กอน ***) ถัดมาลองดูคาผลลัพธ กําลังภายใน หลังจากที่ฝกหัดเบื้องตนไปแลว ในบทนี้จะไดกลาวถึงกําลังภายในที่กอตัวเปน Spark ซึ่งเนื้อหาบทนี้ จะคอนขางยากดังนั้นอาจจะตองใชการศึกษาขอมูลเพิ่มเติมจากแหลงอื่น และตองใชเวลาทําความเขาใจพอ สมควรไมเชนนั้นหากวูวามไปธาตุไฟอาจจะเขาแทรกได หากจะกลาววา RDD เปนแกนแทของ Spark เลยก็คงไมใชการกลาวเกิดจริงเนื่องจากระบบภายใน ของ Spark ยึดโยงอยูกับ RDD นี้เอง ตัว RDD ยอมาจาก Resilient Distributed Dataset กลาวคือ Resilient คือมีความยืดหยุนทําใหคงทนตอการประมวลผลผิดพลาด ทําใหระบบสามารถกูคืนขอผิด พลาดได Distributed ทําใหสามารถกระจายการประมวลผลไปยังเครื่องหลายๆ เครื่อง Dataset เปนความสามารถของ RDD ที่จะจัดการขอมูลขนาดใหญหรือพารทิชันขอมูลได ดวยคุณสมบัติแหลานี้ทําให RDD นั้นสามารถที่จะประมวลผลแบบขนานไดนอกจากนี้ยังมัคุณสมบัติที่ นาสนใจบางประการเชน RDD นั้นมี Type หรือชนิดของตัวแปร, การประมวลผลของ RDD นั้นเปนแบบ Immutable, RDD พยายามเก็บขอมูลลงบนหนวยความจําเทาที่จะเปนไปได, RDD มีคุณสมบัติที่จะวางขอมูล ขนโหนดที่มันคิดวาจะประมวลผลไดเร็วที่สุด และลักษณะการประมวลผลแบบ Lazy Evaluation ที่การ ประมวลผลจริงจะเกิดเมื่อมีคําสั่งการกระทํา ดวยคุณสมบัติเหลานี้จึงทําใหการประมวลผลแบบกระจายของ Spark เปนไปได กอนจะไปเคล็ดวิชาถัดไป จักไดเลาถึง DataFrame กับ DataSet ซึ่งเปน API ที่เอาไวใชงานเปนรูป แบบคลายกับการใชงาน RDD นั่นเอง ซึ่ง DataFrame นั้นตั้งอยูบนพี้นฐานของ RDD และ DataSet เองก็อยู
25.
บนพื้นฐานของ DataFrame อีกที
(ดูภาพปลากรอบได) ดังนั้นมารนอยทั้ง 3 นั้นจึงมีขอดีขอเสียแตกตางกันไป โดยที่ RDD นั้นสามารถควบคุมในระดับลางไดสะดวกกวา กลาวคือมันสามารถทํางานที่ตองใชความละเอียดได ดีและยังสามารถใชจัดการขอมูลแบบไมมีโครงสรางได ซึ่งจะแตกตางกับ DataFrame และ DataSet ที่จะถูก ใชจัดการกับขอมูลที่มีโครงสรางแนนอนและจัดอยูในรูปแบบคอลัมภได อยางไงเสีย DataFrame กับ DataSet นั้นเปนของที่ใกลเคียงกันมาก แต DataFrame นั้นไมมีชนิดตัวแปรโดยตัวของมันเอง ในทาวซอฟตแวรการ ไมมีชนิดตัวแปรนี้ทําใหเกิดความงายในการเขียนโปรแกรมเพราะไมตองสนใจวามันเปนตัวแปรอะไร แตยากใน การจัดการขอผิดพลาดเพราะการที่ไมรูวาชนิดขอมูลเปนแบบไหน มันก็จะไมสามารถเช็คความผิดพลาดตั้งแต ตอนคอมไพน หรือ Compile time ไดนั่นเอง แตในอีกมุมหนึ่งหากเราใชขอมูลของ DataFrame ในมุมของ DataSet เราก็จะสามารถมองไดวา DataFrame มันคือ DataSet ของ Row หรือ DataSet[Row] นั่นเอง ถายังจําไดที่ขาไดเลาไปวาการทํางานของ Spark นั้นเกิดขึ้นจริงๆ ก็เมื่อมีการใชงานคําสั่งที่เปนพวก การกระทํา เชน count() นั่นก็เปนเพราะวา Spark จะสราง Spark job ที่จะเอาไปประมวลผลจริงๆ ก็ตอนนี้ นี่เอง ซึ่งขั้นตอนการประมวลผลของมันก็คือสมมติวาเราเรียก count() แลวจากนั้น จะเกิด Job และ Job นั้น ก็จะถูกสงไปยัง DAGScheduler ซึ่งจะทําหนาที่เปลี่ยน Logical Execution Plan ซึ่งเปนชื่อแบบจาบๆ ของ RDD lineage หรือสายการประมวลผลของ RDD นั้นไปสู Physical Execution Plan ซึ่งเปนแผนการ ประมวลผลที่จะเกิดขึ้นจริงภายในระบบของ Spark โดย DAGScheduler จะงานออกเปน Stage เพื่อ ประมวลผลซึ่งในแตละ Job อาจจะมีหลาย Stage และในแตหละ Stage อาจจะมีไดหลายๆ Task ซึ่ง Tasl นัี้ เองก็เกิดจาก Partition ของขอมูลที่ RDD นั้นแบงออกเปนสวนๆ เพื่อแยกกันใหเกิดการประมวลผลที่สามารถ
26.
ขนานกันได โดยทั่วไปแลว Stage
ของ Spark นั้นมี 2 แบบคือ ShuffleMapStage และ ResultStage ซึ่ง เนื้อหาสวนนี้อาจจะซับซอนและไมจะเปนเกินไปที่จะกลาวถึง แตขอใหเขาใจหลักการทํางานของมันคือ พยายามที่จะแปลงใหขอมูลแตละสวนแยกประมวลผลกันได ซึ่ง Task กับ Partition ซึ่งมีความสัมพันธกัน นั่นเอง ตอไปเพื่อใหเกิดการประมวลผลเปนคลัสเตอรไดเราจึงตองทําความเขาใจถึง Spark Driver ซึ่งเแ็นสวน ที่ใชในการควบคุมทั้งหมดของการประมวลผลของ Spark เลยทีเดียว ตัว Driver เองอาจจะอยูดานนอก หรือ ในคลัสเตอรก็ได ความสําคัญของ Driver คือมันเปนคนที่สราง SparkContext และเก็บขอมูลในการติดตอ ของโปรแกรมที่เราเขียนกับการประมวลผลในสวนตางๆ ของระบบ ดังนั้นทางที่ดีตัว Driver ควรอยูใน คลัสเตอรเพื่อที่จะเชื่อมตอกันกับโหนดอื่นๆ ไดรวดเร็วดวย ไมงั้นการประมวลผลจะชาตามไปดวยนั่นเอง ซึ่ง Architecute ของระบบทั้งตอนที่เปนคลัสเตอรและแบบที่เปน local คอนขางจะคลายกันเพียงแตถาเปน local ก็เหมือนกันวาโหนดนั้นทําหนาที่เปนทุกๆ อยางใหเธอแลวนั่นเอง
27.
ประสานพลัง เมื่อเราเรียนรูเกี่ยวกับวิธีการประมวลผลแลว ก็จะพบวาการที่เอาของหลายๆ สวนพวกนี้ไปรวมไว เครื่องเดียวกันมันอาจจะไมเวิรคก็ไดเปนไดและการประมวลผลก็อาจจะชานะ
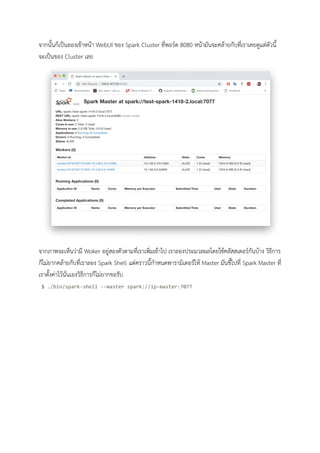
พอถึงจุดหนึ่งการประมวลผล ขอมูลขนาดใหญก็ตองมีการ Scale Out ซึ่งเปนหลายๆ เครื่องชวนกันแทนการ Scale Up ที่ใชการเพิ่ม RAM เพิ่ม Disk อาจจะไมพอหรือไมคุม ในบทนี้จะไดกลาวถึงการเชื่อมตอกันเปนคลัสเตอรของ Spark ถาเราไมไดใ Cloud เราก็ตองไปติดตั้ง Spark ใหกับทุกเครื่องซึ่งวิธีก็ไมยาก ยอนกลับไปอานวิธีติดตั้ง ได สวนถาใครใช Cloud อยูแลวปกติก็จะมีใหเลือก Clone จาก Snapshot อยูแลวก็สามารถใชตัวนั้นได เชน ของ Nipa ทีขาใชอยู ซึ่งวิธีการจัดการ Cluster แบบที่จะเลาตอไปนี้เปนแบบ Spark Standalone Cluster อยาลืมเลือก Cloud Firewall เปน Allow All Port ดวยหละ พอกดสรางทีนี้เราก็จะมีเครื่องอยู 3 เครื่องแลว วิธีการสราง Cluster ก็งายมาก คือเขาไปใน Directory Spark ของเครื่องสักเครื่องหนึ่ง จากนั้นก็สั่ง $ ./sbin/start-master.sh เสร็จแลวสําหรับ Master หะ งายสัส!!! ตอไปเปนคิวของ Worker ที่เราอยากใหเปน $ ./sbin/start-slave.sh spark://ip-master:7077
28.
จากนั้นก็เปนลองเขาหนา WebUI ของ
Spark Cluster ที่พอรต 8080 หนามันจะคลายกับที่เราเคยดูแตตัวนี้ จะเปนของ Cluster เลย จากภาพจะเห็นวามี Woker อยูสองตัวตามที่เราเพิ่มเขาไป เราลองประมวลผลโดยใชคลัสสเตอรกันบาง วิธีการ ก็ไมยากคลายกับที่เราลอง Spark Shell แตคราวนี้กําหนดพารามิเตอรให Master มันชี้ไปที่ Spark Master ที่ เราตั้งคาไวนั่นเองวิธีการก็ไมยากขอรับ $ ./bin/spark-shell --master spark://ip-master:7077
29.
จากนั้นลองรันโปรแรมนับคําดู แลวเราลองดูที่ WebUI จะเห็นวามีโปรแกรมรันอยู
ตัวนี้ถาเปน Spark Shell ไมตองตกใจวาทําไมมันไมอยูในสถานะ Complete Application เนื่องจาก Shell มันจะยังไมจบงานจนกวาจะออกจาก Shell นั้นเอง *** พึงระลึกวาการที่จะให Worker ทํางานไดนั้น Worker ก็ตองอานไฟลนั้นไดดวย และตัวอยางมันเปนไฟล README ที่มีอยูทุกเครื่องอยูแลวมันจึงไมมีปญหา *** เนื้อหาในสวนนี้ลองสราง Spark Standalone เทานั้นแตยังมีคลัสเตอรแบบอื่นใหลองสรางถาอยาก ลองแตหากไมจําเปนตองเปลี่ยนอะไร Standalone ก็ทํางานไดดีเชนกัน แสวงพาย ถาทานอานมาถึงจุดนี้แลว ขาคิดวามันเปนจุดที่เกินกําลังจะเขียนอธิบายกันไดแลว หากเปรียบ เปนการหัดจักรยานแลวหละก็ ทานไดเรียนรูวิธีขี่เรียบรอยแลว หากตองการขี่จักรยานเปนก็มีเพียงแคตอง ฝกฝนดวยตัวเองแลว สุดทายนี้ขอใหทานคนพบเคล็ดมีชาที่ไมมีอยูในตํารานี้ และหวังหวาจะไดพบกันใหม และ ในโอกาสนี้ขอซูฮกใหกับ
30.
คลาวดจาก Nipa.cloud ที่ใหเอามาลองใชสําหรับทําเอกสารเลมนี้
ละ ODDS ทีมทําซอฟตแวรที่เชื่อวาการทํา ซอฟตแวรตองสนุกซึ่งก็เปอยางนั้นจริงๆ และที่ขาดไมไดเลยคือแลป SUT Aiyara Cluster ที่ทําใหไดเรียนรู เรื่อง Spark และใชคลัสเตอรในชวงที่เรียน ป.โท อยู
Download



![แตก็มีเปาหมายรวมกันคือการใหบริการลูกคา ซึ่งมันอาจจะถูกมองวาคลายๆ กับคลัสเตอร (Cluster) แตก็แตก
ตางกันอยูบาง เพราะโดยทั่วไปแลว มักจะถูกกลาวถึงในลักษณะของกลุมของที่ทํางานแบบเดียวกันซึ่งในกรณีนี้
ถาจะกลาววาเตาที่รานเถาแกสองเตานั้นเปนหนึ่งคลัสเตอรและเตาที่รานอาซิ้มก็เปนอีกคลัสเตอรหนึ่งที่
Distributed กันอยูก็คงจะไมผิดแตประการใด
นี่ยังไมรวมถึง Cloud computing ที่พูดถึงเรื่องการใชทรัพยากรที่คนใชไมจําเปนตองสนใจ 4 หรือ 8
ใดๆ แคมีเงินจายก็พอ หรือ Grid computing ที่กลาวถึงการเอาทรัพยากรมาแชรกันตรงกลางระหวางหนวย
งานตางๆ ตามนโยบายยุคกลางป ‘90s ที่บางทีขอใชงานไปแลวตั้งแต ป.ตรีจนจบ ป.เอก เพิ่งได Account เขา
ใชที่ Install โปรแกรมใดๆ ไมได บนเครื่องที่แรงที่สุดในสมัยนั้นอยาง Pentium 4 (อสกข.) ในสวนนี้ยังมีราย
ละเอียดปลีกยอยอีกเยอะไปอานเพิ่มดวยก็ดีนะ (เผื่อปรมาจารยมาอานทานจะบอกวามันบแมนๆ มันเปนแบบ
อื่น พะนะ… ละเอียดกวานี้ก็หาอานเอาโลดสู)
มุมมองของความขนาน
เราจะเขาถึงศาสตรของการขนานไมไดเลย ถาเรายังไมเขาใจวาจะมองวามันขนานกันไดยังไง บังเอิญ
ไปเจอตําราหนึ่งซึ่งมันดีมาก เลาถึงเรื่องวิธีคิดของการขนานกันซึ่งมีอยูสองสวนคือ การขนานกันของขอมูล
(Data parallelism) ซึ่งเปนเรื่องที่บอกวาถาเรามีฟงกชั่นเดียวกันก็สงไปหลายๆ ที่ใหชวยกันประมวลผลไดนี่
หวาถาการประมวลผลของเรามีแคบวกเลข แบบนี้เราจะแบงกันบวกก็ไมผิดกติกาใดๆ เชน ชุดขอมูล A =
A[1]+A[2] แบบนี้ถาแบงออกเปนชุดขอมูล B แลวก็แบง B = B[1]+B[2] ก็ยอมได เปรียบกับถาโรงเตี๊ยมของ
เรามีสูตรการทําเสี่ยวหลงเปาและมีวัตถุดิบพอแลวหละก็เราจะสงไปใหพอครัวหลายๆ คนชวยกันทําก็ยิ่งจะ
ทําใหอาหารที่ลูกคาสั่งเสร็จไดเร็วขึ้น
แตก็ยังมีการขนานอีกรูปแบบหนึ่งคือ การขนานกันของฟงกชัน (Function parallelism) วากันถึง
เรื่องการแบงสวนงานที่ไมเกี่ยวของกันออกจากกัน แลวคอยนําผลลัพธมาประกอบกันทีหลังได เชน F = (A*B)
+ (C*D) แบบนี้จะเห็นวาเอา A*B กับ C*D แยกกันทํางานก็ไมมีปญหาอะไร พอทั้งคูเสร็จแลวคอยเอามาบวก
กันเพื่อไดผลลัพธสุดทาย เสมือนหนึ่งวาถาลูกคาสั่งนํ้าเตาหูปาทองโกแลวเสี่ยวเออผูนั้นก็สามารถใหเพื่อนสอง
คนชวยโดยใหคนแรกไปเอานํ้าเตาหูจากเขาอากินะ อีกคนไปเอาปาทองโกจากเขาเหลียงซาน เสร็จแลวใสถาด
เดียวกันเอามาเสริฟได
cc :http://www.ku.ac.th/scc2009/SCC2009_advance.pdf
วิทยายุทธ MapReduce
จุดเริ่มตนเนื้อเรื่องอันวุนวายนี้เกิดจาก Google พรรคพี่ใหญในยุทธภพที่ตองการแสดงอานุภาพของ
วิทยายุทธที่ใชภายในอยู ดวยการติพิมพเปเปอรเรื่อง MapReduce : Simplified Data Processing on
Large Clusters เมื่อป ค.ศ. 2004 โดยปา Jeffrey Dean และ Sanjay Ghemawat โดยเนื้อหาจะมีใจความ
วา MapReduce เปนโมเดลการแกปญหาแบบนี้ที่ถาเราแบงปญหาออกใหอยูในรูปแบบนี้แลวเราจะสามารถ](https://image.slidesharecdn.com/xiaow-or-spark-181007095608/85/Spark-3-320.jpg)

![การประมวลผลนั้นไมจะเปนตองไปยุงเกี่ยวกับสวนอื่นเราเลยสามารถนับจํานวนหมูเห็ดเปดไกนํ้าเตาปูปลาได
นั่นเอง
เพื่อใหงงมากยิ่งขึ้นจักไดอธิบายเพิ่มเติมสักนิดหากโรงเตี๊ยมเราเปดเฟรนไซนขึ้นมามีหลายสาขาแลว
เถาแกอยากรูวาคนที่ซื้อเยอะที่สุดนี่เขาซื้อกี่บาท เสี่ยวเออแบบเราๆ ก็จัดใหปาแกไดจากการคนตั๋วสั่งอาหาร
จากนั้นเอามาลงบันทึกเรยงกันไดความแบบนี้
โรงเตี๊ยมแปะ สาขาเขาเหลียงซาน, 32, 21/3/2018 18:00
โรงเตี๊ยมแปะ สาขาเขาเหลียงซาน, 102, 1/4/2018 20:00
โรงเตี๊ยมแปะ สาขาพรรคกระยาจก, 199, 1/4/2018 20:00
โรงเตี๊ยมแปะ สาขาบูตึ้ง, 500 ,5/5/2016 10:00
จากนั้นเราก็สราง Map โดยตัดคําที่เราไมตองใชออกจะไดของหนาตาประมาณนี้เปน Intermediate
Key/Value pair
(สาขาเขาเหลียงซาน, 32)
(สาขาเขาเหลียงซาน, 102)
(สาขาพรรคกระยาจก, 199)
(สาขาบูตึ้ง, 500)
เสร็จแลวระบบของ MapReduce ก็จะทําขั้นตอนการ Shuffle ไดหนาตาของ Intermediate Key/Value
pair ประมาณนี้
(สาขาเขาเหลียงซาน, [32,102])
(สาขาพรรคกระยาจก, 199)
(สาขาบูตึ้ง, 500)
จากนั้นก็เอาไปเขาฟงกชัน Reduce ซึ่งฟงกชันนี้เรากําหนดใหหาตัวที่มากที่สุดเอาไว สุดทายก็จะไดหนาตา
แบบนี้ออกมา
(สาขาเขาเหลียงซาน, 102)
(สาขาพรรคกระยาจก, 199)
(สาขาบูตึ้ง, 500)](https://image.slidesharecdn.com/xiaow-or-spark-181007095608/85/Spark-5-320.jpg)

















![บนพื้นฐานของ DataFrame อีกที (ดูภาพปลากรอบได) ดังนั้นมารนอยทั้ง 3 นั้นจึงมีขอดีขอเสียแตกตางกันไป
โดยที่ RDD นั้นสามารถควบคุมในระดับลางไดสะดวกกวา กลาวคือมันสามารถทํางานที่ตองใชความละเอียดได
ดีและยังสามารถใชจัดการขอมูลแบบไมมีโครงสรางได ซึ่งจะแตกตางกับ DataFrame และ DataSet ที่จะถูก
ใชจัดการกับขอมูลที่มีโครงสรางแนนอนและจัดอยูในรูปแบบคอลัมภได อยางไงเสีย DataFrame กับ DataSet
นั้นเปนของที่ใกลเคียงกันมาก แต DataFrame นั้นไมมีชนิดตัวแปรโดยตัวของมันเอง ในทาวซอฟตแวรการ
ไมมีชนิดตัวแปรนี้ทําใหเกิดความงายในการเขียนโปรแกรมเพราะไมตองสนใจวามันเปนตัวแปรอะไร แตยากใน
การจัดการขอผิดพลาดเพราะการที่ไมรูวาชนิดขอมูลเปนแบบไหน มันก็จะไมสามารถเช็คความผิดพลาดตั้งแต
ตอนคอมไพน หรือ Compile time ไดนั่นเอง แตในอีกมุมหนึ่งหากเราใชขอมูลของ DataFrame ในมุมของ
DataSet เราก็จะสามารถมองไดวา DataFrame มันคือ DataSet ของ Row หรือ DataSet[Row] นั่นเอง
ถายังจําไดที่ขาไดเลาไปวาการทํางานของ Spark นั้นเกิดขึ้นจริงๆ ก็เมื่อมีการใชงานคําสั่งที่เปนพวก
การกระทํา เชน count() นั่นก็เปนเพราะวา Spark จะสราง Spark job ที่จะเอาไปประมวลผลจริงๆ ก็ตอนนี้
นี่เอง ซึ่งขั้นตอนการประมวลผลของมันก็คือสมมติวาเราเรียก count() แลวจากนั้น จะเกิด Job และ Job นั้น
ก็จะถูกสงไปยัง DAGScheduler ซึ่งจะทําหนาที่เปลี่ยน Logical Execution Plan ซึ่งเปนชื่อแบบจาบๆ ของ
RDD lineage หรือสายการประมวลผลของ RDD นั้นไปสู Physical Execution Plan ซึ่งเปนแผนการ
ประมวลผลที่จะเกิดขึ้นจริงภายในระบบของ Spark โดย DAGScheduler จะงานออกเปน Stage เพื่อ
ประมวลผลซึ่งในแตละ Job อาจจะมีหลาย Stage และในแตหละ Stage อาจจะมีไดหลายๆ Task ซึ่ง Tasl นัี้
เองก็เกิดจาก Partition ของขอมูลที่ RDD นั้นแบงออกเปนสวนๆ เพื่อแยกกันใหเกิดการประมวลผลที่สามารถ](https://image.slidesharecdn.com/xiaow-or-spark-181007095608/85/Spark-25-320.jpg)