

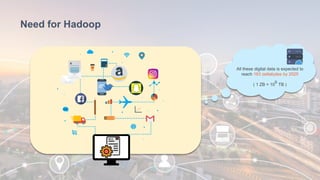
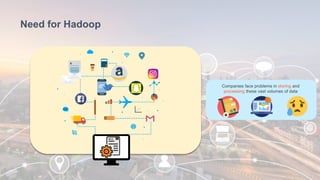
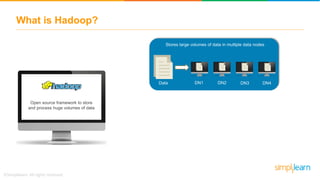
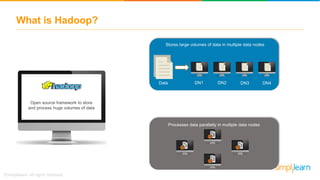
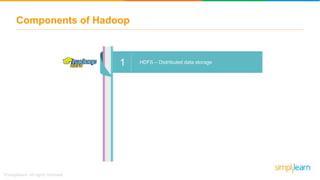
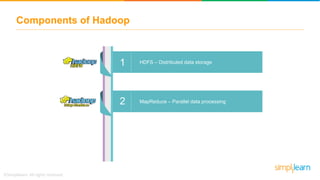
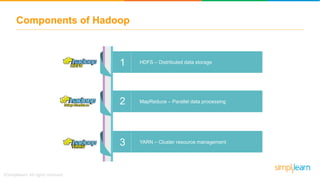
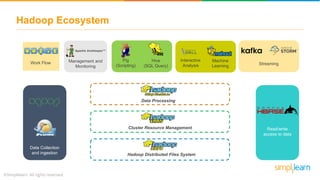

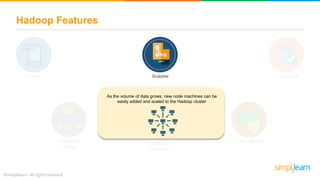
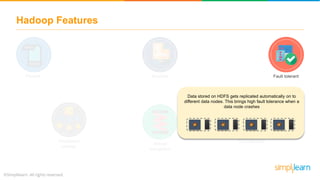
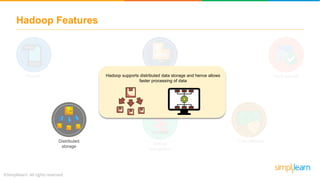

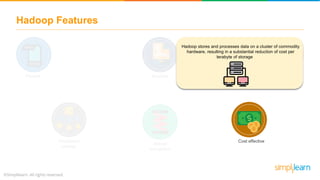
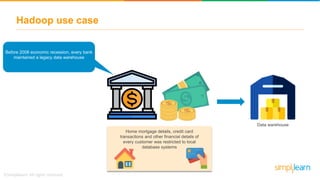
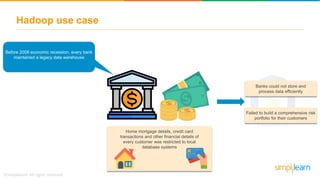
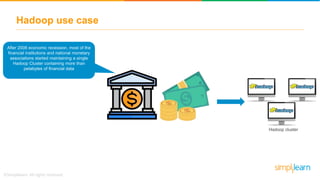
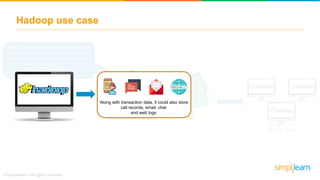
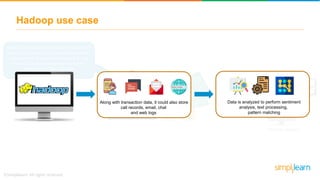

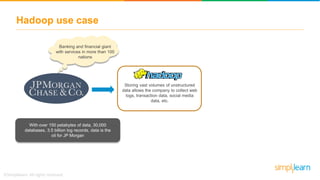
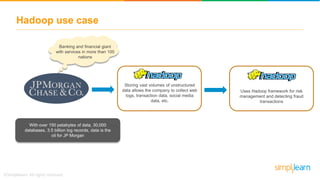
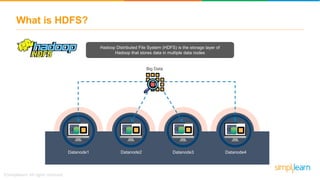
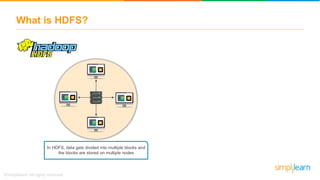
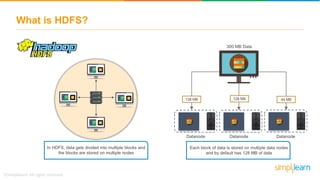
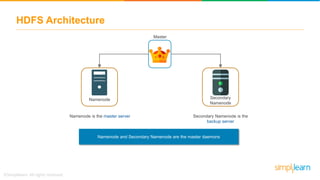
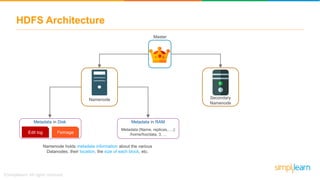
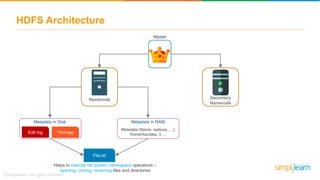
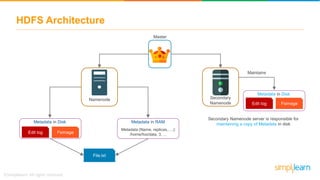
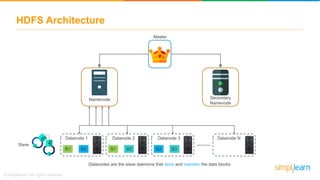
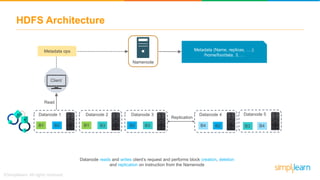
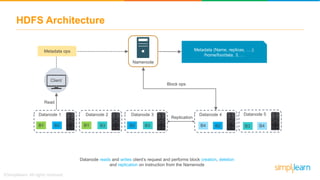
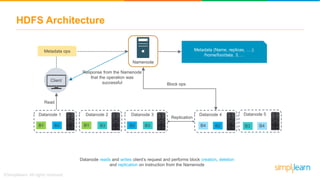
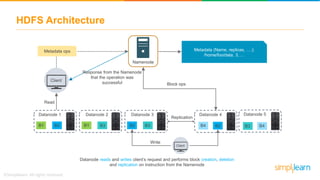
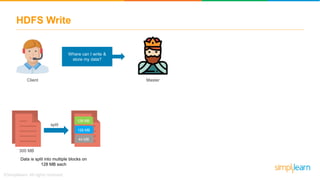
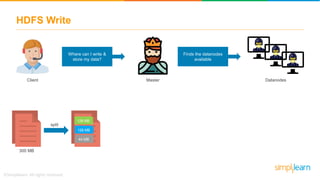
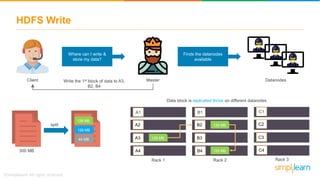
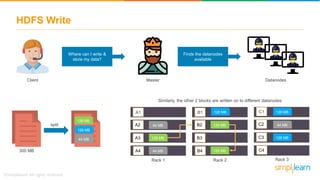
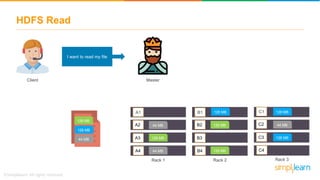
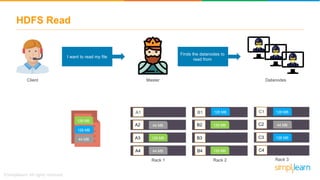
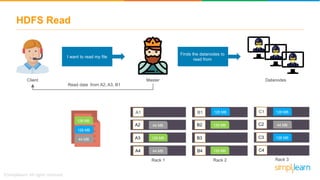
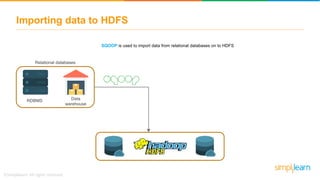
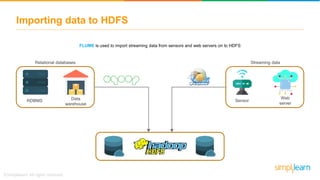
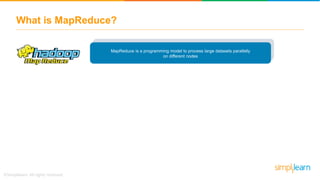
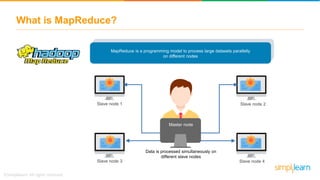

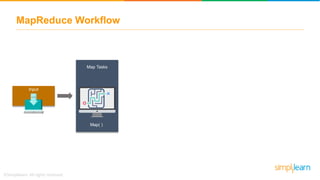
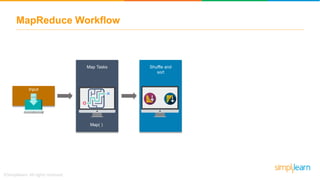
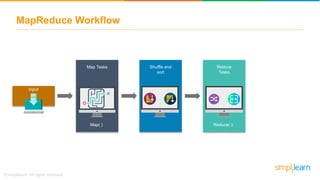
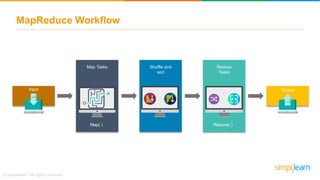

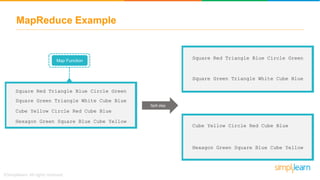
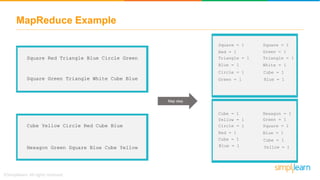
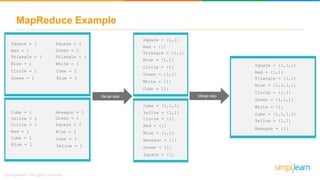
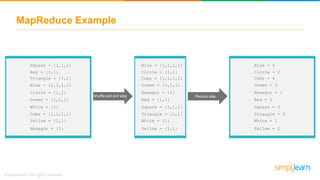




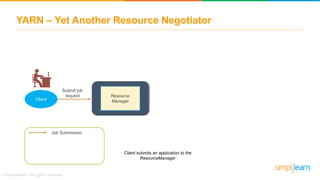
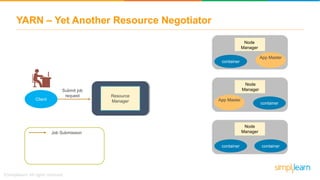
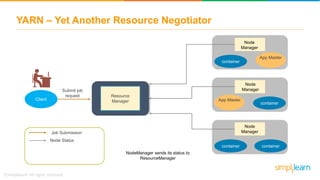
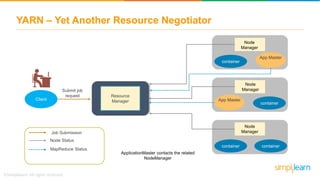
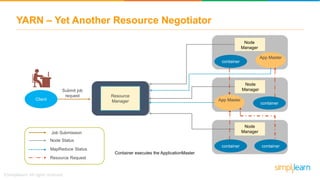
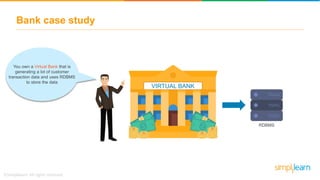
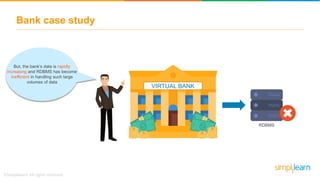







The document provides information about Hadoop training. It discusses the need for Hadoop in today's data-heavy world. It then describes what Hadoop is, its ecosystem including HDFS for storage and MapReduce for processing. It also discusses YARN and provides a bank use case. It further explains the architecture and working of HDFS and MapReduce in processing large datasets in parallel across clusters.























































































