Big Data 101
#BugDay2013
@somkiat
-- สยามชํานาญกิจ --
2.
Gartner Identify TopTechnology
2013
● Big Data
● Modern Information Infrastructure
● Semantic Technology
● The Logical Data Warehouse
● NoSQL DBMS
● In-Memory Computing
● Information *
http://www.gartner.com/newsroom/id/2359715
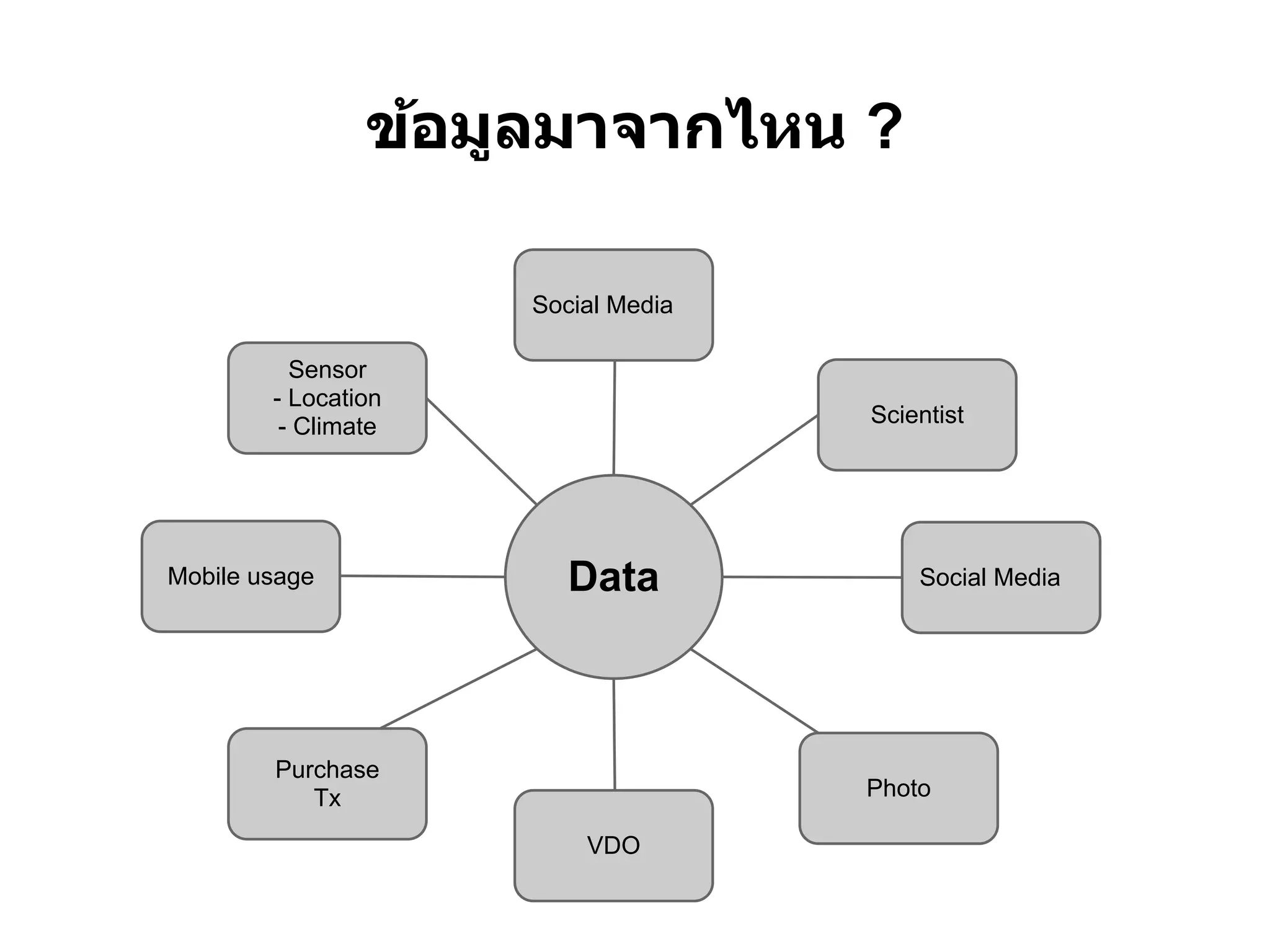
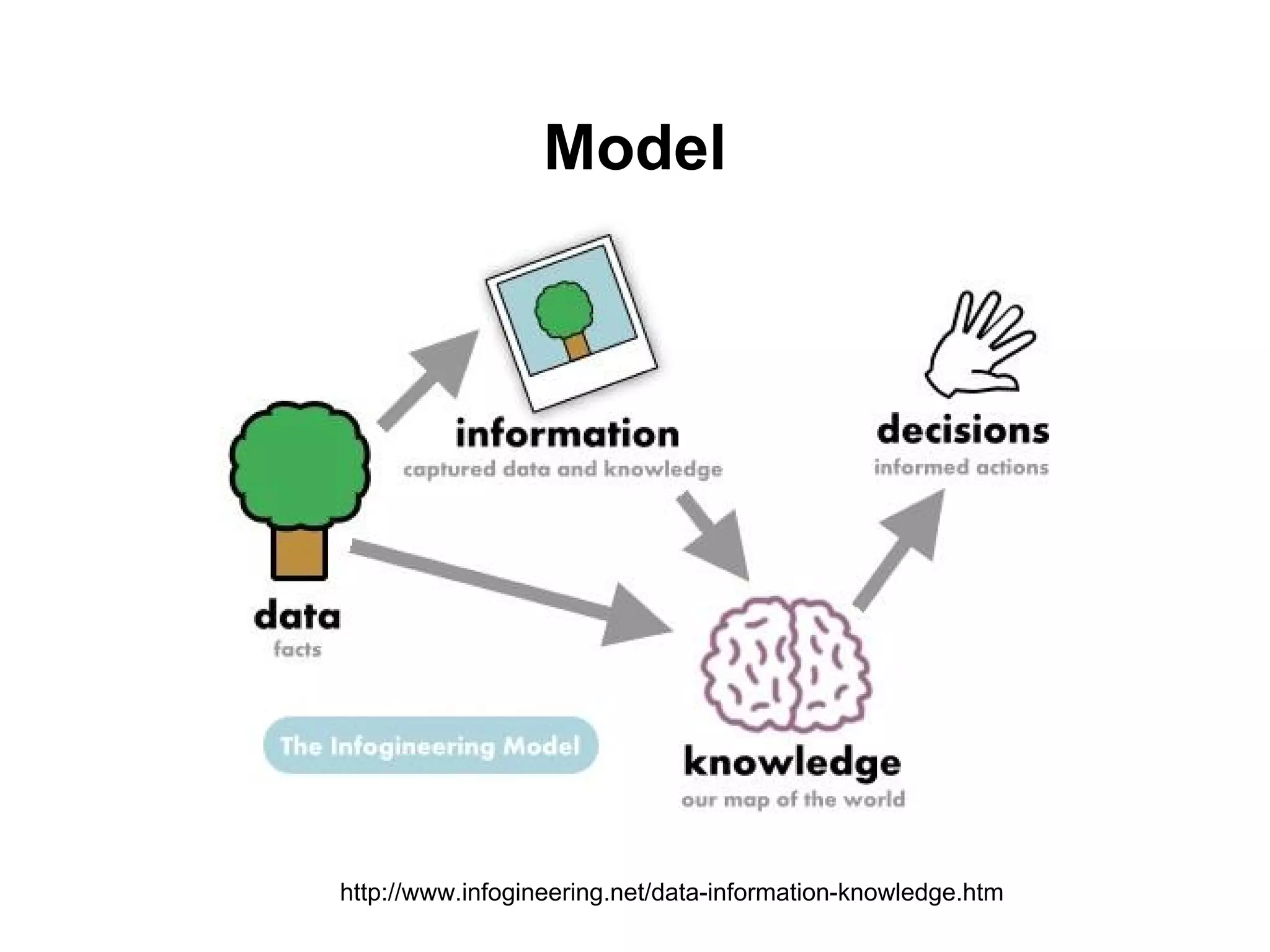
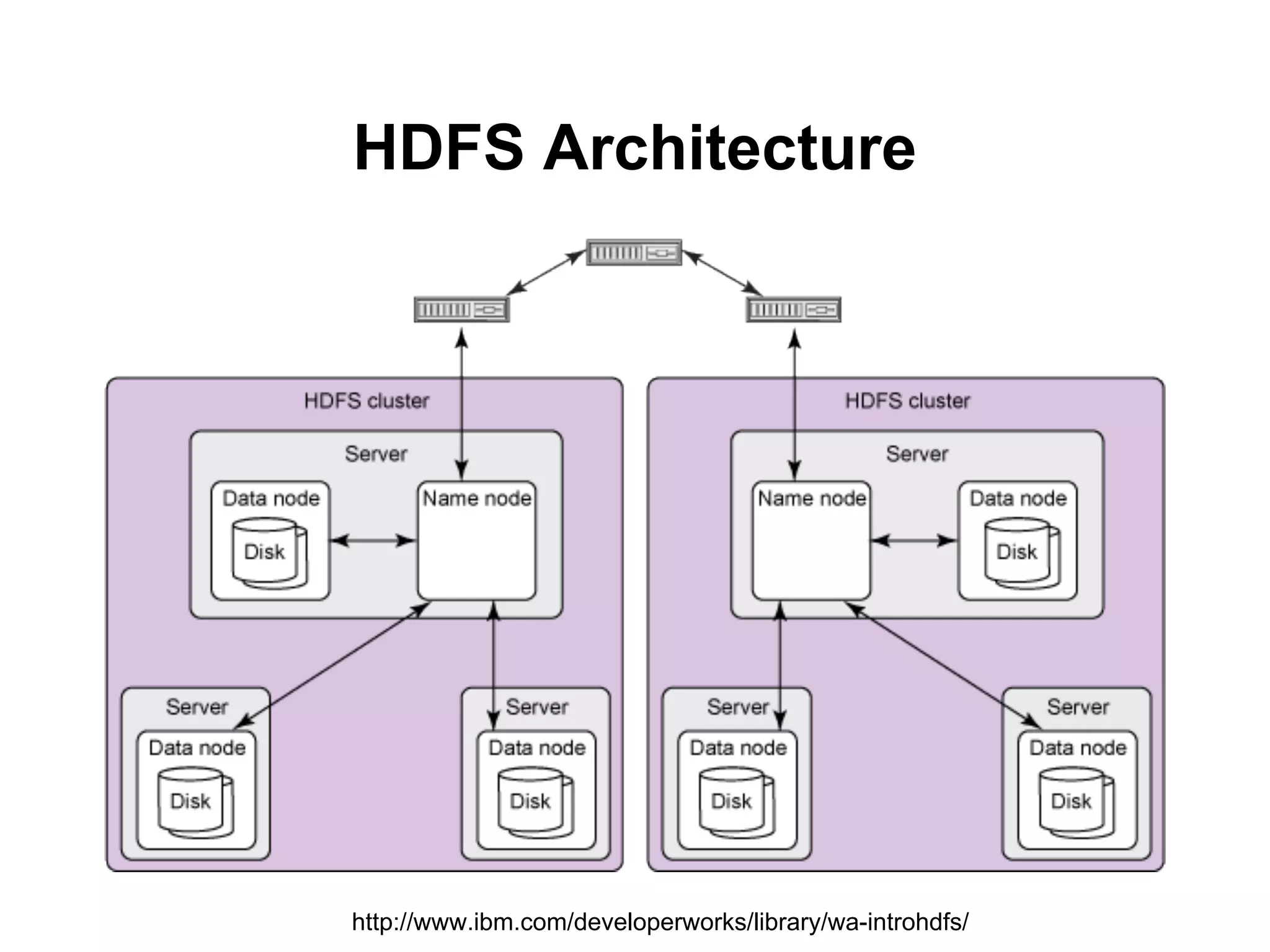
Big Data คืออะไร
Wikipedia
Bigdata usually includes data sets with sizes
beyond the ability of commonly used software
tools to capture, curate, manage, and process
the data within a tolerable elapsed time.
17.
Big Data คืออะไร
●ข ้อมูลคืออะไร ( What )
● จัดการมันอย่างไร ( How )
● เพือเปิ ดให ้รู ้ว่าข ้อมูลมันเกียวกับอะไร ( What with )
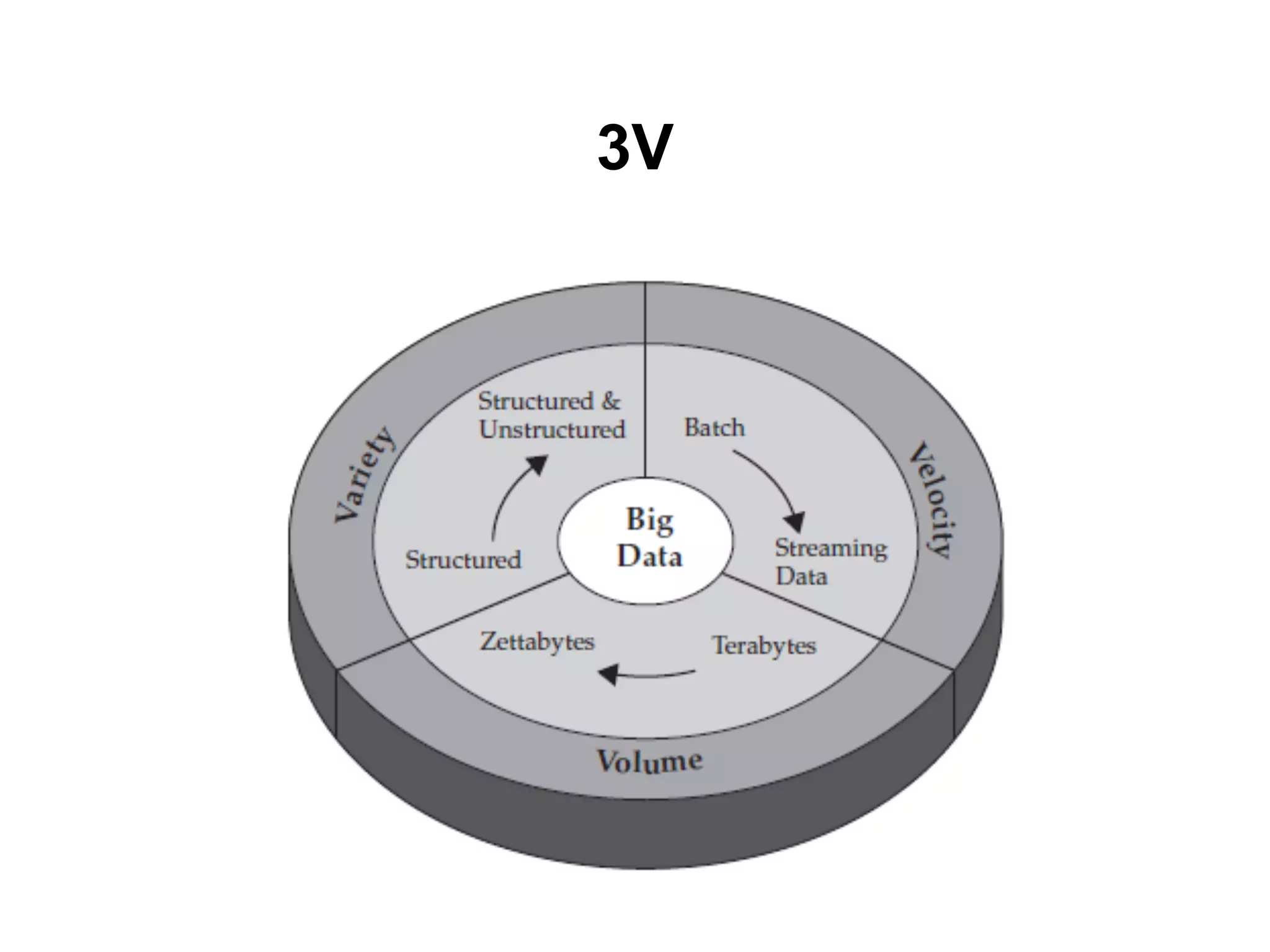
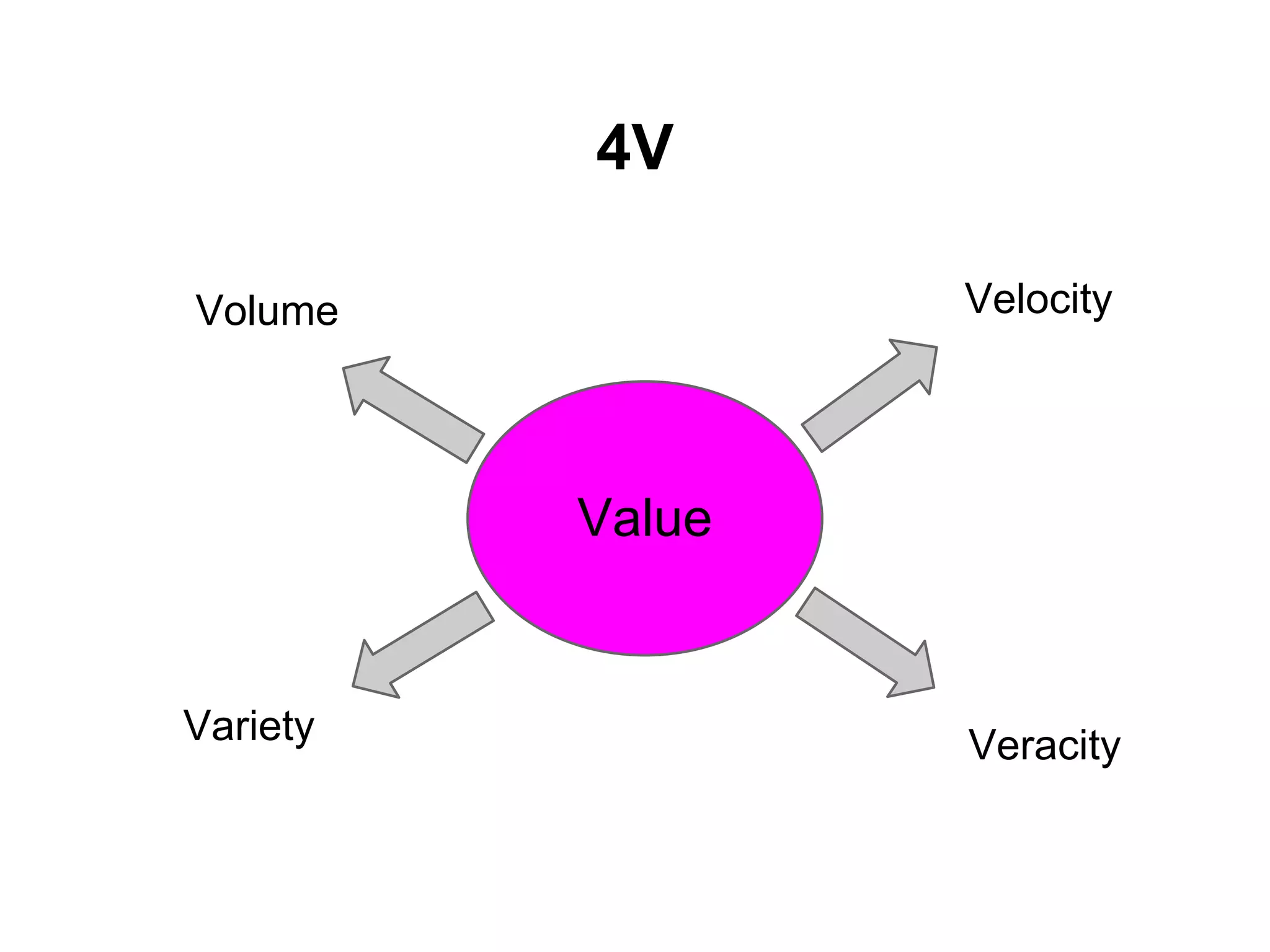
คุณล ักษณะของ BigData
● Variety
○ รูปแบบข ้อมูลทีหลายหลาย
■ Structured
■ Unstructured
■ Semistructured
○ มีวธการนํ ามาใช ้งานอย่างไร
ิ ี
○ VDO, Photo, Audio, Document, Text
○ Log, Monitoring
○ Stock reacord, Transaction
○ Need pre-processing and data cleaning
23.
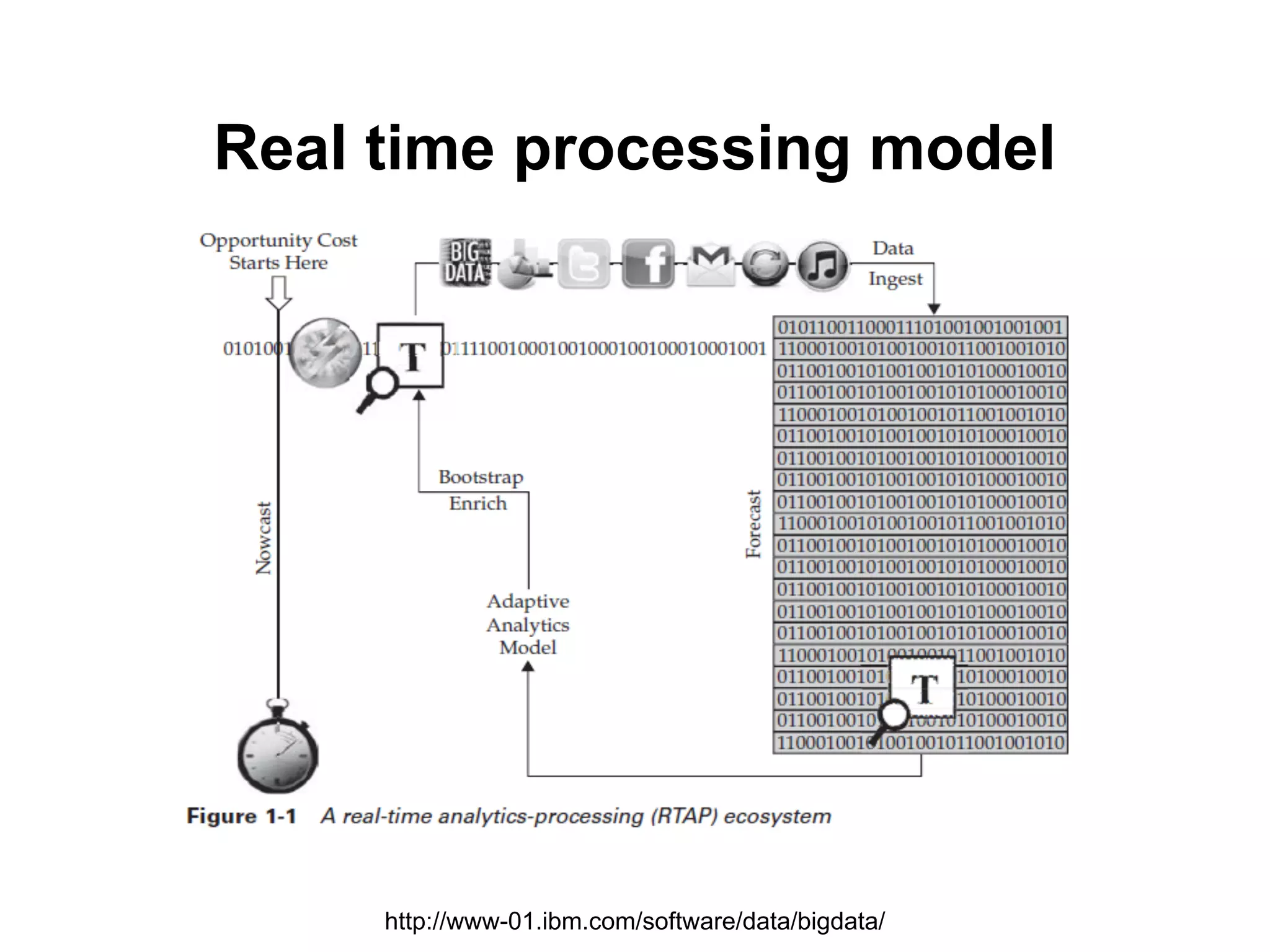
คุณล ักษณะของ BigData
● Velocity
○ ความรวดเร็วในการประมวลผล วิเคราะห์
○ Batch, Near real time
○ Stream processing
○ Need real time
○ Online VDO, Location tracking, AR
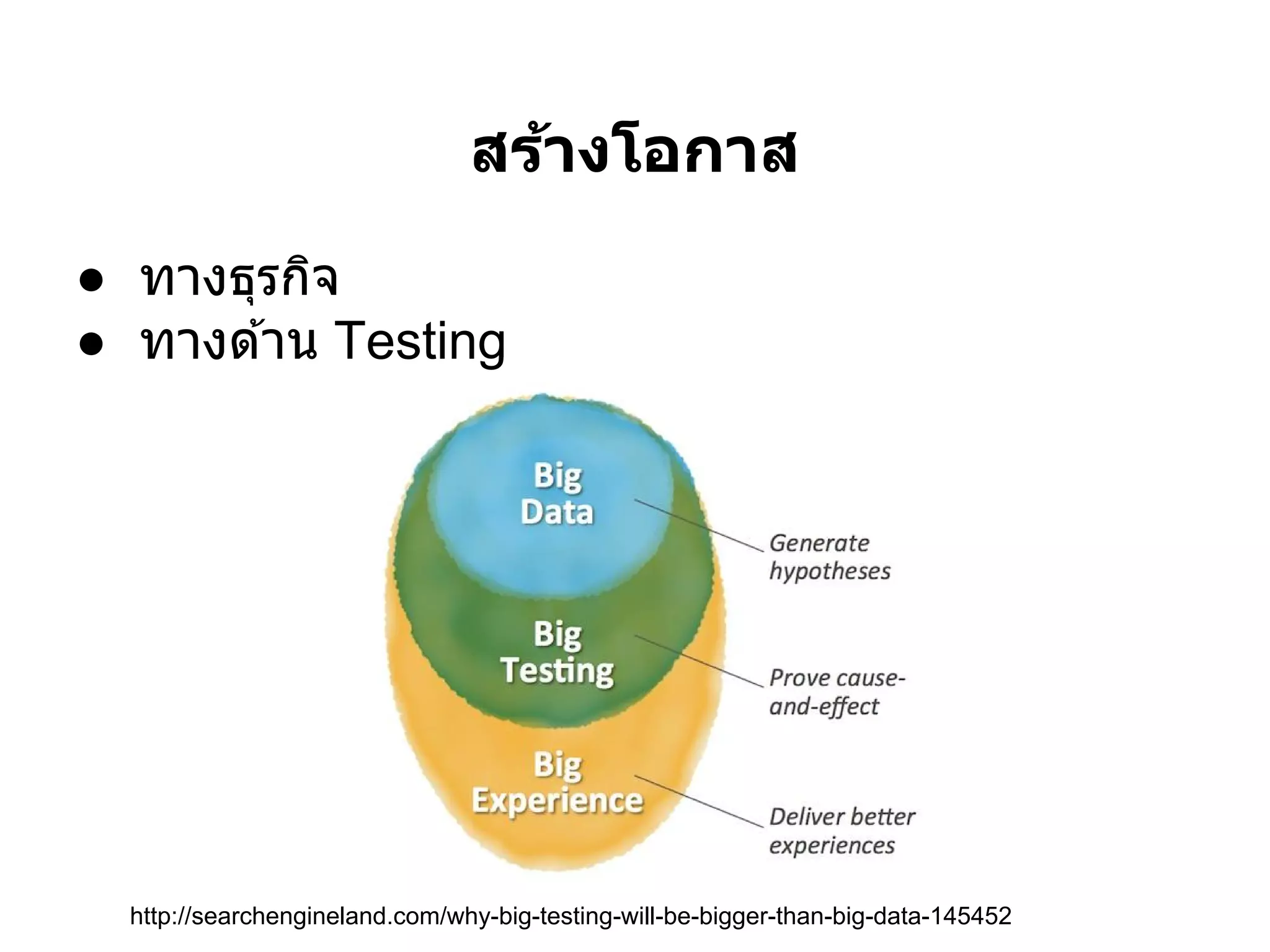
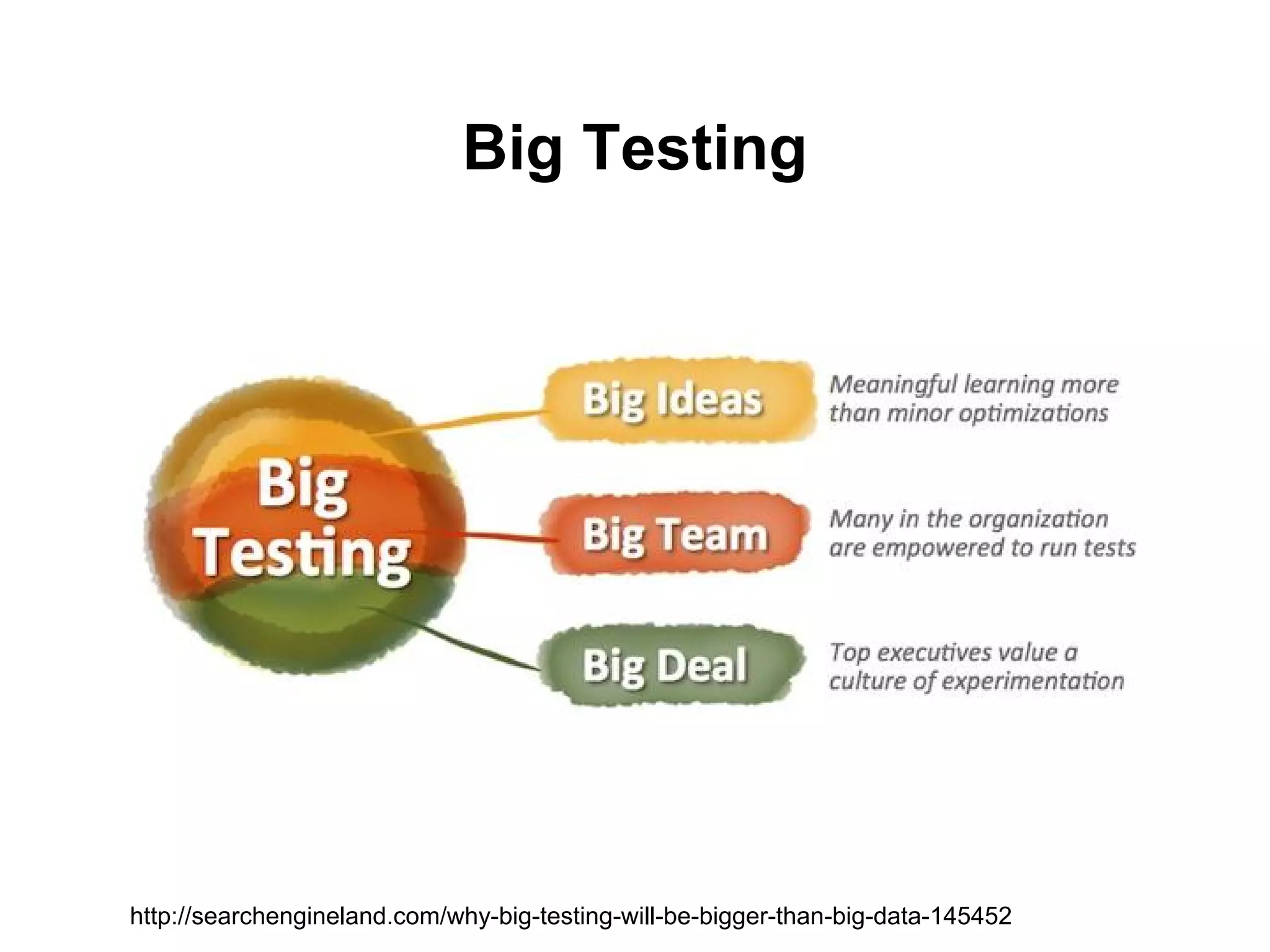
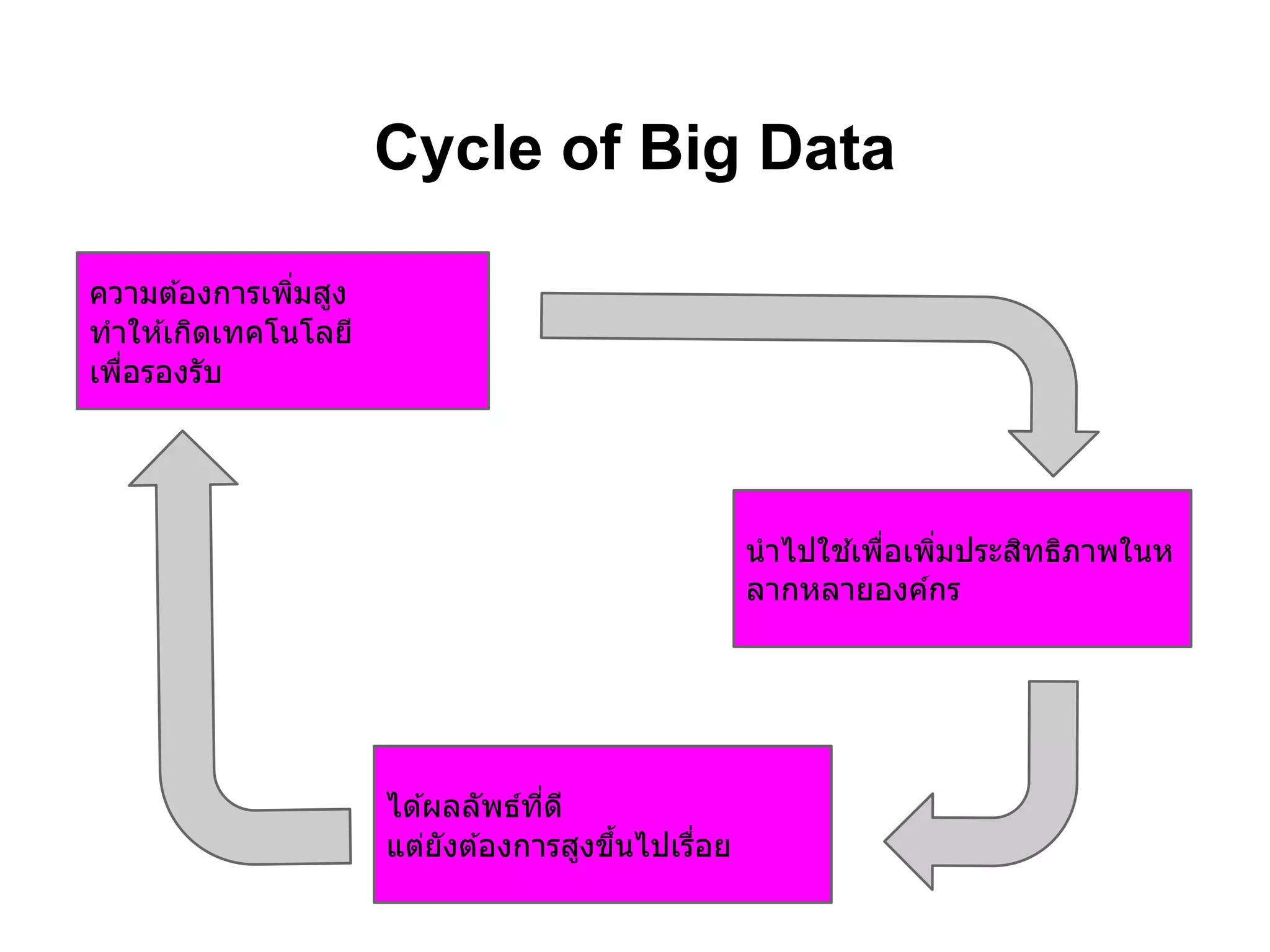
สร้างความท้าทาย
● Visualization
● Big Data application
● แนวทางการวิเคราะห์ข ้อมูล
● ศึกษาพฤติกรรมของผู ้บริโภค
● Public data
● New information และ Data service