Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Wareerut Suwannalop
205 views
หน่วยการเรียนรู้ที่ 2 p
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 10
2
/ 10
3
/ 10
4
/ 10
5
/ 10
6
/ 10
7
/ 10
8
/ 10
9
/ 10
10
/ 10
More Related Content
PDF
Dataandit
by
Praphaphun Kaewmuan
PDF
แบบทดสอบก่อนเรียน หน่วย3-ม2
by
Ko Kung
PDF
work3
by
babyykw
PDF
การจัดเอกสาร
by
koratswpark
PDF
Introducation to database system
by
ChulalakB2ST
DOC
ใบความรู้ที่ 5 เรื่อง ข้อมูล สารสนเทศ และการประมวลผล
by
เทวัญ ภูพานทอง
PDF
การเขียนผังงาน(Flowchart)
by
Kroopop Su
DOC
ใบความรู้ที่ 6 เรื่อง การประมวลผลข้อมูล
by
เทวัญ ภูพานทอง
Dataandit
by
Praphaphun Kaewmuan
แบบทดสอบก่อนเรียน หน่วย3-ม2
by
Ko Kung
work3
by
babyykw
การจัดเอกสาร
by
koratswpark
Introducation to database system
by
ChulalakB2ST
ใบความรู้ที่ 5 เรื่อง ข้อมูล สารสนเทศ และการประมวลผล
by
เทวัญ ภูพานทอง
การเขียนผังงาน(Flowchart)
by
Kroopop Su
ใบความรู้ที่ 6 เรื่อง การประมวลผลข้อมูล
by
เทวัญ ภูพานทอง
What's hot
PPSX
การจัดเก็บข้อมูลสารสนเทศ
by
นพณัฐกานต์ ศุภสินทินภัทร
PPT
E office1
by
Prachyanun Nilsook
PPT
Unit6
by
Jinda Charoenphol
PPT
Eoffice1
by
Prachyanun Nilsook
PDF
4 ลักษณะของสารสนเทศที่ดี (ใบความรู้)
by
phatrinn555
PPTX
B5
by
Nu Mai Praphatson
PPT
Myun dao22
by
MyunDao
PDF
ใบความรู้ การจัดเก็บข้อมูลสารสนเทศ ม.2 14 กันยายน 58
by
สุเมธ แก้วระดี
DOC
ใบความรู้เรื่อง ข้อมูลและสารสนเทศ
by
Praphaphun Kaewmuan
PPT
ตอนที่+1+..
by
Noopy S'bell
DOC
บทที่ 1 ความรู้พื้นฐานเกี่ยวกับสารสนเทศ
by
chushi1991
PPTX
หน่วยที่1
by
Prakaywan Tumsangwan
PDF
เทคโนโลยีการสื่อสาร (พัชรา P)
by
Patchara Wioon
PDF
ระบบสารสนเทศ
by
nprave
PPTX
Powerpoint3กระบวนการทางธุรกิจระบบสารสนเทศ
by
Nawaponch
PPT
Maliบรรยาย มข111
by
darika chu
PDF
โครงงาน คอม เชต
by
Thanasak Inchai
การจัดเก็บข้อมูลสารสนเทศ
by
นพณัฐกานต์ ศุภสินทินภัทร
E office1
by
Prachyanun Nilsook
Unit6
by
Jinda Charoenphol
Eoffice1
by
Prachyanun Nilsook
4 ลักษณะของสารสนเทศที่ดี (ใบความรู้)
by
phatrinn555
B5
by
Nu Mai Praphatson
Myun dao22
by
MyunDao
ใบความรู้ การจัดเก็บข้อมูลสารสนเทศ ม.2 14 กันยายน 58
by
สุเมธ แก้วระดี
ใบความรู้เรื่อง ข้อมูลและสารสนเทศ
by
Praphaphun Kaewmuan
ตอนที่+1+..
by
Noopy S'bell
บทที่ 1 ความรู้พื้นฐานเกี่ยวกับสารสนเทศ
by
chushi1991
หน่วยที่1
by
Prakaywan Tumsangwan
เทคโนโลยีการสื่อสาร (พัชรา P)
by
Patchara Wioon
ระบบสารสนเทศ
by
nprave
Powerpoint3กระบวนการทางธุรกิจระบบสารสนเทศ
by
Nawaponch
Maliบรรยาย มข111
by
darika chu
โครงงาน คอม เชต
by
Thanasak Inchai
Viewers also liked
PPTX
Resim yorumlama
by
aleynatuzcuoglu
PPT
Question 3 Evaluation
by
partyboy_14
PDF
Community Media 2012
by
ATPD
PPTX
Tachas contra la designacion de miembros de mesa
by
Escuela Electoral y de Gobernabilidad
PDF
Albeitar.
by
guestb91ac9
ZIP
Memoria fotografica
by
guadanevada
PDF
Fidelz sexta
by
MonicaArzua
PPTX
ZZG bielany wroclawskie
by
Związek Pracodawców Ochrony Zdrowia Dolnego Śląska
PDF
Portada de libro
by
Richard Pasquel Sartre
PPT
111012 서울3차모임소식
by
iamgreens
PDF
Interview Sandra Kensen en Henk Gossink over 3 decentralisaties
by
Henk Gossink
PPTX
Tipologias De La Multimedia
by
liliana ramirez
PPTX
Oraciones simples y compuestas
by
reinabocanegra
PPTX
Pasowanie na przedszkolaka 2012 - Mokronosek
by
Niepubliczne Przedszkole Integracyjne MOKRONOSEK
PPTX
Deel 7 les 1 (introductie en motivatie)
by
svencerulus
PDF
duotono
by
Daniielitho AtOrrante
PPTX
Eskimo introduction(Chinese)
by
lowdemin
PPTX
Sustaining the vision: Leader succession
by
Linda Howard
PPTX
Chamarras Hacky
by
Jorge Badillo Martínez
DOCX
Práctica utilizando los operadores de búsqueda 2
by
Gisella Chamaidan
Resim yorumlama
by
aleynatuzcuoglu
Question 3 Evaluation
by
partyboy_14
Community Media 2012
by
ATPD
Tachas contra la designacion de miembros de mesa
by
Escuela Electoral y de Gobernabilidad
Albeitar.
by
guestb91ac9
Memoria fotografica
by
guadanevada
Fidelz sexta
by
MonicaArzua
ZZG bielany wroclawskie
by
Związek Pracodawców Ochrony Zdrowia Dolnego Śląska
Portada de libro
by
Richard Pasquel Sartre
111012 서울3차모임소식
by
iamgreens
Interview Sandra Kensen en Henk Gossink over 3 decentralisaties
by
Henk Gossink
Tipologias De La Multimedia
by
liliana ramirez
Oraciones simples y compuestas
by
reinabocanegra
Pasowanie na przedszkolaka 2012 - Mokronosek
by
Niepubliczne Przedszkole Integracyjne MOKRONOSEK
Deel 7 les 1 (introductie en motivatie)
by
svencerulus
duotono
by
Daniielitho AtOrrante
Eskimo introduction(Chinese)
by
lowdemin
Sustaining the vision: Leader succession
by
Linda Howard
Chamarras Hacky
by
Jorge Badillo Martínez
Práctica utilizando los operadores de búsqueda 2
by
Gisella Chamaidan
Similar to หน่วยการเรียนรู้ที่ 2 p
PDF
09 การจัดการข้อมูล
by
teaw-sirinapa
PDF
สถาปัตยกรรมฐานข้อมูล
by
skiats
PDF
Database
by
paween
PDF
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
by
hattayachuesomkiet
PDF
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
by
hattayachuesomkiet
PPTX
บทที่ 8
by
noonnn
PDF
Database
by
sa
PDF
งานนำเสนอ การจัดการฐานข้อมุล
by
chanoot29
PDF
Lecture1 การประมวลผลข้อมูล และฐานข้อมูล
by
skiats
PDF
องค์ประกอบของระบบคอมพิวเตอร์
by
Thanawut Rattanadon
PDF
Database1
by
kruninkppk
PDF
บทที่ 1
by
Rungnapa Rungnapa
PDF
บทที่ 1 แนวคิดทั่วไปเกี่ยวกับฐานข้อมูล
by
Rungnapa Rungnapa
PDF
บทที่ 1 แนวคิดทั่วไปเกี่ยวกับฐานข้อมูล
by
Rungnapa Rungnapa
PDF
ความรู้ทั่วไปเกี่ยวกับระบบฐานข้อมูล
by
Watuka Wannarun
PDF
11
by
Meaw Sukee
PPT
Myun dao22
by
MyunDao
PDF
นวลลออ ถาวรโรจน์เสถียร เลขที่20 ม.5
by
Nuanlaor Nuan
PPTX
Life-in-the-Degital-and-Technology-Era-chapter2
by
ssuserc03f9c
PPT
ธันยพร นกศิริ ม409 เลขที่2
by
Hitsuji12
09 การจัดการข้อมูล
by
teaw-sirinapa
สถาปัตยกรรมฐานข้อมูล
by
skiats
Database
by
paween
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
by
hattayachuesomkiet
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
by
hattayachuesomkiet
บทที่ 8
by
noonnn
Database
by
sa
งานนำเสนอ การจัดการฐานข้อมุล
by
chanoot29
Lecture1 การประมวลผลข้อมูล และฐานข้อมูล
by
skiats
องค์ประกอบของระบบคอมพิวเตอร์
by
Thanawut Rattanadon
Database1
by
kruninkppk
บทที่ 1
by
Rungnapa Rungnapa
บทที่ 1 แนวคิดทั่วไปเกี่ยวกับฐานข้อมูล
by
Rungnapa Rungnapa
บทที่ 1 แนวคิดทั่วไปเกี่ยวกับฐานข้อมูล
by
Rungnapa Rungnapa
ความรู้ทั่วไปเกี่ยวกับระบบฐานข้อมูล
by
Watuka Wannarun
11
by
Meaw Sukee
Myun dao22
by
MyunDao
นวลลออ ถาวรโรจน์เสถียร เลขที่20 ม.5
by
Nuanlaor Nuan
Life-in-the-Degital-and-Technology-Era-chapter2
by
ssuserc03f9c
ธันยพร นกศิริ ม409 เลขที่2
by
Hitsuji12
More from Wareerut Suwannalop
PDF
หน่วยการเรียนรู้ที่ 1 p
by
Wareerut Suwannalop
PPTX
หน่วยการเรียนรู้ที่ 2
by
Wareerut Suwannalop
PPTX
หน่วยการเรียนรู้ที่ 1
by
Wareerut Suwannalop
PDF
หน่วยการเรียนรู้ที่ 1 เทคโนโลยีการสื่อสาร
by
Wareerut Suwannalop
PDF
หน่วยการเรียนรู้ที่ 1 เทคโนโลยีการสื่อสาร
by
Wareerut Suwannalop
DOCX
หน่วยการเรียนรู้ที่ 2 โครงสร้างข้อมูล
by
Wareerut Suwannalop
PPTX
หน่วยการเรียนรู้ที่ 2
by
Wareerut Suwannalop
DOCX
หน่วยการเรียนรู้ที่ 1 เทคโนโลยีการสื่อสาร
by
Wareerut Suwannalop
หน่วยการเรียนรู้ที่ 1 p
by
Wareerut Suwannalop
หน่วยการเรียนรู้ที่ 2
by
Wareerut Suwannalop
หน่วยการเรียนรู้ที่ 1
by
Wareerut Suwannalop
หน่วยการเรียนรู้ที่ 1 เทคโนโลยีการสื่อสาร
by
Wareerut Suwannalop
หน่วยการเรียนรู้ที่ 1 เทคโนโลยีการสื่อสาร
by
Wareerut Suwannalop
หน่วยการเรียนรู้ที่ 2 โครงสร้างข้อมูล
by
Wareerut Suwannalop
หน่วยการเรียนรู้ที่ 2
by
Wareerut Suwannalop
หน่วยการเรียนรู้ที่ 1 เทคโนโลยีการสื่อสาร
by
Wareerut Suwannalop
หน่วยการเรียนรู้ที่ 2 p
1.
หนวยการเรียนรูที่ 2 โครงสรางขอมูล
2.
- เปนวิธีจัดเก็บขอมูลในคอมพิวเตอร เพื่อให สามารถนํามาใชไดอยางมีประสิทธิภาพ -
การใชงานโครงสรางขอมูล ตองมีขนตอนวิธีที่ ั้ เหมาะสม จึงจะสามารถใชงานไดอยางมี ประสิทธิภาพ - การออกแบบโครงสรางขอมูลที่ดีจะชวยลดเวลา ในการกระทําการและลดการใชงานในพื้นที่ ความจําดวย
3.
ชนิดของโครงสรางขอมูล
1.โครงสรางขอมูลเบื้องตน (Primitive Data Structure) เปนชนิดขอมูลที่ไมมีโครงสรางขอมูลอื่นมาเปน สวนประกอย เมื่อตองการเก็บคาสามารถเรียกใชงานไดทันที บางครั้งเรียกวาชนิดขอมูลพื้นฐาน(Base Type)หรือสรางมาให ใชดวยภาษานั้นๆ สวนโครงสรางขอมูลแบบอื่น ๆ จะมีโครงสรางขอมูลอื่น เปนสวนประกอบ เมื่อตองการใชจะตองกําหนดรูปแบบ รายละเอียดโครงสรางขึ้นมากอนเรียกวาขอมูลชนิดผูใชกําหนด (Uses-definedType)ดังนี้
4.
1. โครงสรางขอมูลแบบเรียบงาย (Simple
Data Structure) จะมีสมาชิกที่เปนโครงสรางขอมูลอื่นเปนสวนประกอบมี รูปแบบงายๆไมซับซอนสามารถทําความเขาใจและสรางขึ้นมาใชงานได งาย 2.โครงสรางขอมูลเชิงเสน (Linear Data Structure) เปน โครงสรางที่ความซับซอนมากขึ้น ประกอบดวยสมาชิกที่เปนโครงสราง ขอมูลอื่นจัดเรียงตอกันเปนแนวเสน 3.โครงสรางขอมูลไมเปนเชิงเสน (Nonlinear Data Structure) เปนโครงสรางที่มีความซับซอนเชนกัน ประกอบดวย สมาชิกที่เปนโครงสรางขอมูลอื่นจัดเรียงกันในรูปแบบไบนารี่ที่จัดเรียง สมาชิกมีการแยกออกเปนสองทาง และแบบ N- อารเรย ที่จัดเรียง สมาชิกมีการแยกออกไดหลายทางหลายรูปแบบไมแนนอน
5.
4.โครงสรางการจัดการแฟมขอมูล (FileOrganization) เปน โครงสรางสําหรับนําขอมูลเก็บไวในหนวยความจําสํารองโดยขอมูลจะ อยูในรูปแบบโครงสรางขอมูลอื่นและมีวิธีการจัดการโดยการนํา โครงสรางขอมูลอื่นๆมาชวย
โครงสรางขอมูลตางๆที่กลาวมาอาจตอง มีการควบคุมการทํางานทีเกี่ยวของกับขอมูลและสวนที่มาเกี่ยวของ ่ ใหเปนไปตามที่ตองการเรียกวา โครงสรางขอมูลนามธรรม ลักษณะ โครงสรางจะแบงออกเปน 2 สวน คือ สวนขอมูลและสวนปฏิบติการ ั โดนภายในจะมีรายลเอียดการทํางานตาง ๆ ประกอบดวยโครงสราง การจัดเก็บขอมูลและอัลกอริทมเมื่อใดที่เรียกใชงานโครงสราง ึ นามธรรมในสวนรายละเอียดการทํางานจะไมถูกเกี่ยวของหรือมี ผลกระทบโดยถูกปดบังไวจะเห็นวาโครงสรางขอมูลซับซอนจะเปน โครงสรางขอมูลนามธรรมที่ตองมีสวนการจัดเก็บขอมูลและสวน ปฏิบัติการ
6.
ลักษณะของขอมูล
ขอมูลที่มีความถูกตองและเชื่อถือได (accuracy) ขอมูลจะมีความถูก ตองและเชื่อถืไดมากนอยเพียงใดนั้น ขึ้นกับวิธีการที่ใชในการควบคุมขอมูล นําเขา และการควบคุมการประมวลผลการควบคุมขอมูลนําเขาเปนการกระทํา เพื่อใหเกิดความมั่นใจวาขอมูลนําเขามีความถูกตองเชื่อถือได เพราะถาขอมูล นําเขาไมมีความถูกตองแลวถึงแมจะใชวิธีการวิเคราะหและประมวลผลขอมูลที่ดี เพียงใด ผลลัพธที่ไดก็จะไมมความถูกตอง หรือนําไปใชไมได ขอมูลนําเขา ี จะตองเปนขอมูลที่ผานการตรวจสอบวาถูกตองแลว ขอมูลบางอยางอาจตอง แปลงใหอยูในรูปแบบที่เครื่องคอมพิวเตอรสามารถเขาใจไดอยางถูกตอง ซึง ่ อาจตองพิมพขอมูลมาตรวจเช็คดวยมือกอน การประมวลผลถึงแมวาจะมีการ ตรวจสอบขอมูลนําเขาแลวก็ตาม ก็อาจทําใหไดขอมูลที่ผดพลาดได เชน เกิด ิ จากการเขียนโปรแกรมหรือใชสตรคํานวณผิดพลาดได ดังนันจึงควรกําหนด ู ้ วิธีการควบคุมการประมวลผลซึงไดแก การตรวจเช็คยอดรวมที่ไดจากการ ่ ประมวลผลแตละครั้ง หรือการตรวจสอบผลลัพธที่ไดจากการประมวลผลดวย เครื่องคอมพิวเตอรกับขอมูลสมมติที่มีการคํานวณดวยวามีความถูกตองตรงกัน หรือไม
7.
ขอมูลตรงตามความตองการของผูใช (relevancy) ไดแก การเก็บเฉพาะขอมูลที่ผใชตองการเทานั้น
ไมควร เก็บขอมูลอื่น ๆ ู ที่ไมจําเปนหรือไมเกี่ยวของกับการใชงาน เพราะจะทําใหเสียเวลา และเสียเนื้อที่ในหนวยเก็บขอมูล แตทั้งนี้ขอมูลที่เก็บจะตองมีความ ครบถวนสมบูรณดวย ขอมูลมีความทันสมัย (timeliness) ขอมูลที่ดีนั้นนอกจาก จะเปนขอมูลที่มีความถูกตองเชื่อถือไดแลวจะ ตองเปนขอมูลที่ ทันสมัย ทั้งนี้เพื่อใหผูใชสามารถนําเอาผลลัพธทไดไปใชได ี่ ทันเวลา นั่นคือจะตองเก็บขอมูลไดรวดเร็วเพื่อทันความตองการ ของผูใช
8.
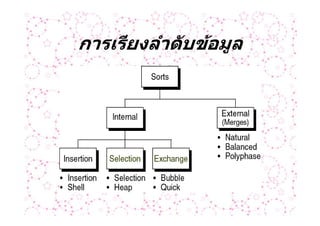
การเรียงลําดับขอมูล
9.
การคนหาขอมูล
ปจจุบันนี้เสิรชเอ็นจิ้น (search engine) กลายมาเปนสิ่งจําเปน สําหรับการทองโลกอินเตอรเนต เพราะหากไมมีบริการชวยคนหาขอมูล เหลานี้เราตองใชเวลานับหลายชัวโมง หรือเปนวันที่จะคนหาขอมูล ที่เรา ่ ตองการ จะใชงานครบซึ่งเสิรชเอ็นจิ้น ก็มีมากมาย หลายเจา ใหเราได เลือกใชงานกันซึ่งแตละเจาก็มีวิธีการที่ใชคนหาาขอมูลที่แตกตางกัน เรา สามารถแบง เว็บไซต ที่ใหบริการคนหาขอมูลออกเปนประเภทใหญ ๆ ได 2 ประเภท ไดแก การบริการคนหาโดยใช อินเด็กซ (index) การบริการคนหา ขอมูลตามหมวดหมู (directory)
10.
การคนหาโดยใชอินเด็กซ
เราคง เคยไดยนชื่อ เสิรช เอ็นจิ้น อยาง อัลตาวิสตา ิ (AltaVista/www.altavista.digital.com) และฮ็อทบ็อท (HotBot/www.hotbot.com) ทั้งสอง เปนตัวอยางของเสิรช เอ็นจิ้นนี้ หลักการคือ เขาจะมีโปรแกรมตัวหนึ่ง เปนตัวสแกน ไปตามเว็บไซตตาง ๆ เรียกวา โปรแกรม สไปเดอร การคนหา ขอมูลโดยใ ช อินเด็กซ การคนหาตามหมวดหมู เสิรช เอ็นจิ้น ชือดังอีก 2 ตัว ไดแก ยาฮู (Yahoo!/www.yahoo.com)และ ่ แมกเจลแลน (Magellan/www.magellan.com) เลือกใชเทคนิคนี้ โดยใชมนุษย เปนคนจัดหมวดหมู ของเว็บไซต และคอย ปรับปรุงใหขอมูล ทันสมัยอยูเสมอ เนื่องจากบัญชี รายชื่อเว็บไซต ไดผานการจัด หมวดหมูโดยมนุษย ดังนั้น ในรายชื่อ ก็จะมี รายละเอียด คราว ๆ เกี่ยวกับเว็บไซต ที่เพิ่มเติม ลงไป ขอของการคนหาแบบ นี้คือ จะสามารถตีกรอบผลลัพธ ออกมาตรง กับความ ตองการ มากขึ้น เชน เราลอง ใสคําวา "Spider" ในยาฮู! คนหาดู เราจะไดรายการของ หมวดหมูออกมา
Download