Downloaded 510 times




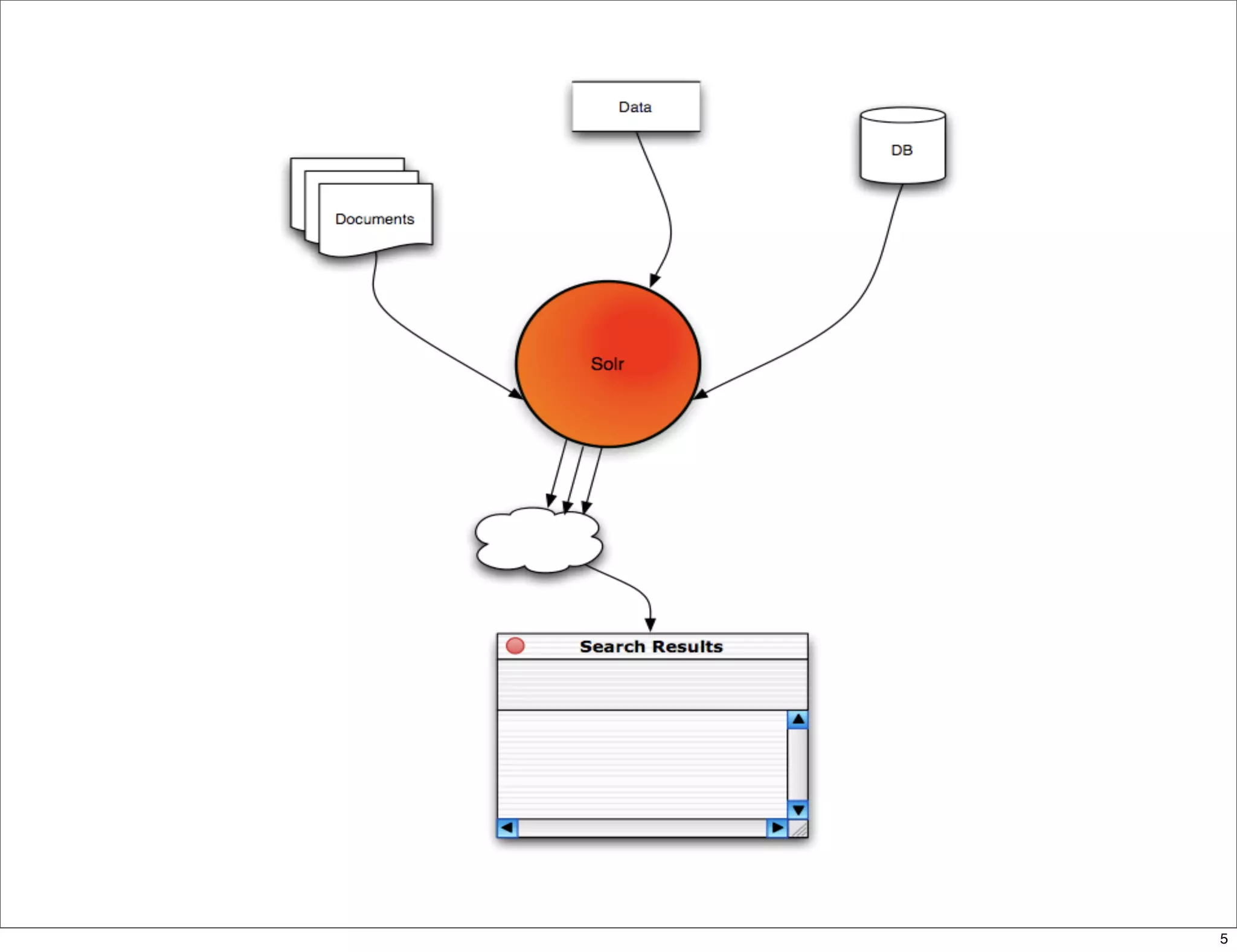















![Request handlers
• mini-“servlets”
• SearchHandler extensions chain search
components
• Flexible response formatting:
• &wt=[json, ruby, xslt, php, phps, javabin,
python,velocity]
22](https://image.slidesharecdn.com/novajug-dec09-091217093934-phpapp02/75/Solr-Powered-Lucene-22-2048.jpg)














![Solr Query Parser
• http://lucene.apache.org/java/2_9_1/
queryparsersyntax.html+ Solr extensions
• Kitchen sink parser, includes advanced user-
unfriendly syntax
• Syntax errors throw parse exceptions back to
client
• Example: title:ipod* AND price:[0 TO 100]
• http://wiki.apache.org/solr/SolrQuerySyntax
37](https://image.slidesharecdn.com/novajug-dec09-091217093934-phpapp02/75/Solr-Powered-Lucene-37-2048.jpg)




![Faceting
• Counts per subset within results
• Facet on: field terms, queries,
date ranges
• &facet=on
&facet.field=cat
&facet.query=price:[0 TO 100]
• http://wiki.apache.org/solr/
SimpleFacetParameters
42](https://image.slidesharecdn.com/novajug-dec09-091217093934-phpapp02/75/Solr-Powered-Lucene-42-2048.jpg)




















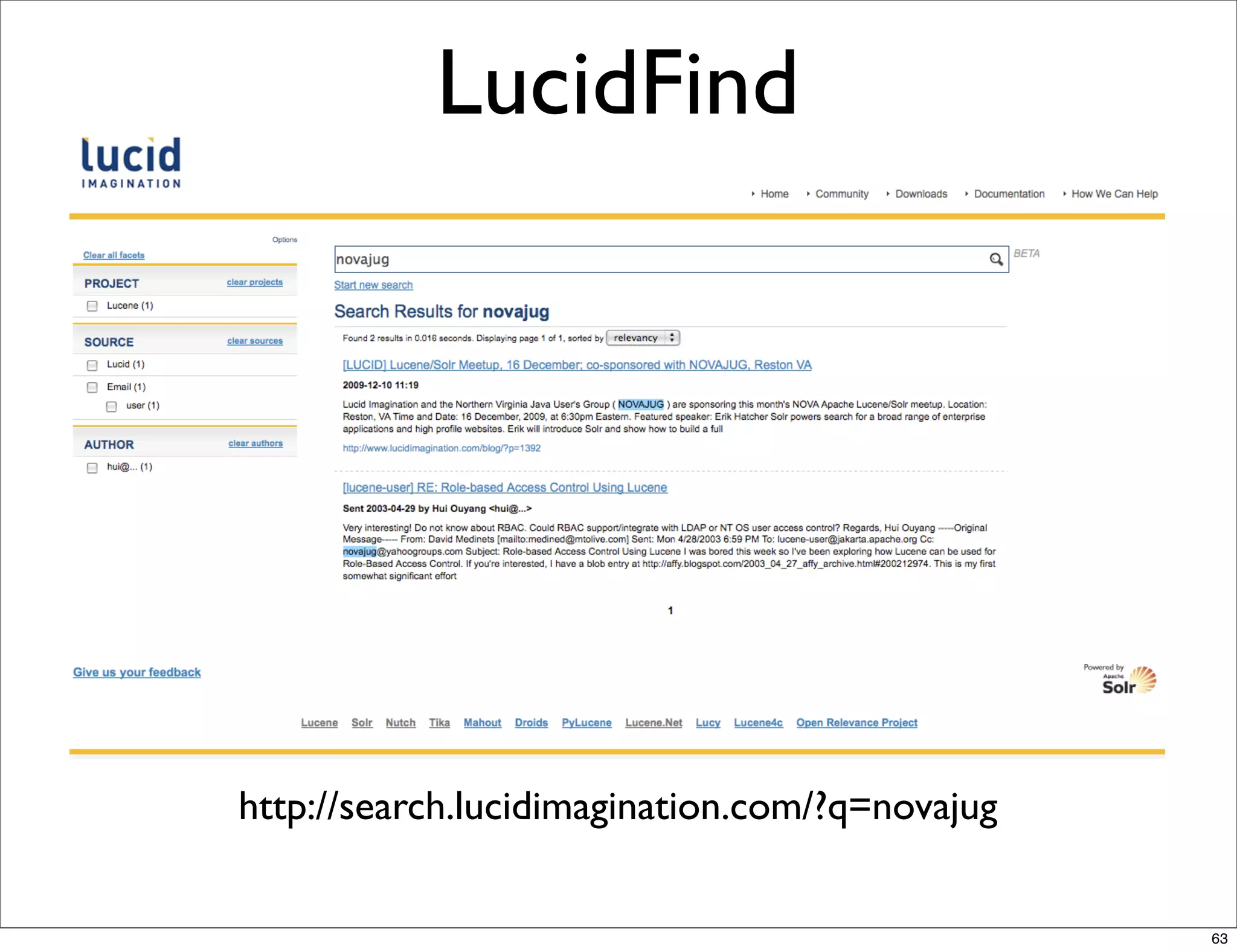


Erik Hatcher presented on Solr and Lucene. He discussed what Solr is, how it is built on Apache Lucene, and how it provides a search server with features like scalability, fast performance, and extensibility. He provided examples of starting Solr, indexing and searching documents, and the various configuration files and components used.



















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













