









![Lucene syntax Required search term – use a “+” +ipod +belkin Field-specific searching – use fieldName name:ipod manu:belkin Wildcard searching – use * or ? ip?d belk* *deo (currently requires modifying solr source) Range searching timestamp:[2006-07-16T12:30:00Z to *] Time needs to be full ISO Proximity searching – use a “~” "video ipod"~3 – up to 3 words apart Fuzzy searches – use a “~” ipod~ will find ipod and ipods belkin~0.7 will find words close spellings](https://image.slidesharecdn.com/solrpresentation-1227829338471545-9/75/Solr-Presentation-13-2048.jpg)
![Default Query Syntax Lucene Query Syntax [; sort specification] 1. mission impossible; releaseDate desc 2. +mission +impossible –actor:cruise 3. “mission impossible” –actor:cruise 4. title:spiderman^10 description:spiderman 5. description:“spiderman movie”~10 6. +HDTV +weight:[0 TO 100] 7. Wildcard queries: te?t, te*t, test*](https://image.slidesharecdn.com/solrpresentation-1227829338471545-9/75/Solr-Presentation-14-2048.jpg)





![Schema Lucene has no notion of a schema Sorting - string vs. numeric Ranges - val:42 included in val:[1 TO 5] ? Lucene QueryParser has date-range support, but must guess. Defines fields, their types, properties Defines unique key field, default search field, Similarity implementation](https://image.slidesharecdn.com/solrpresentation-1227829338471545-9/75/Solr-Presentation-21-2048.jpg)












The document provides instructions for installing Solr on Windows by downloading and configuring Tomcat and Solr. It describes downloading Tomcat and Solr, configuring server.xml, extracting Solr to c:\web\solr, copying the Solr WAR file to Tomcat, and accessing the Solr admin page at http://localhost:8080/solr/admin to verify the installation.
Introduction to Solr and its installation process on Windows using Tomcat. Key steps include downloading Tomcat, configuring server.xml, and setting up Solr directories.
Explains Solr's indexing system, including the roles of Documents and Fields. Key attributes of Fields and the necessary directory structure for Solr Home are also discussed.
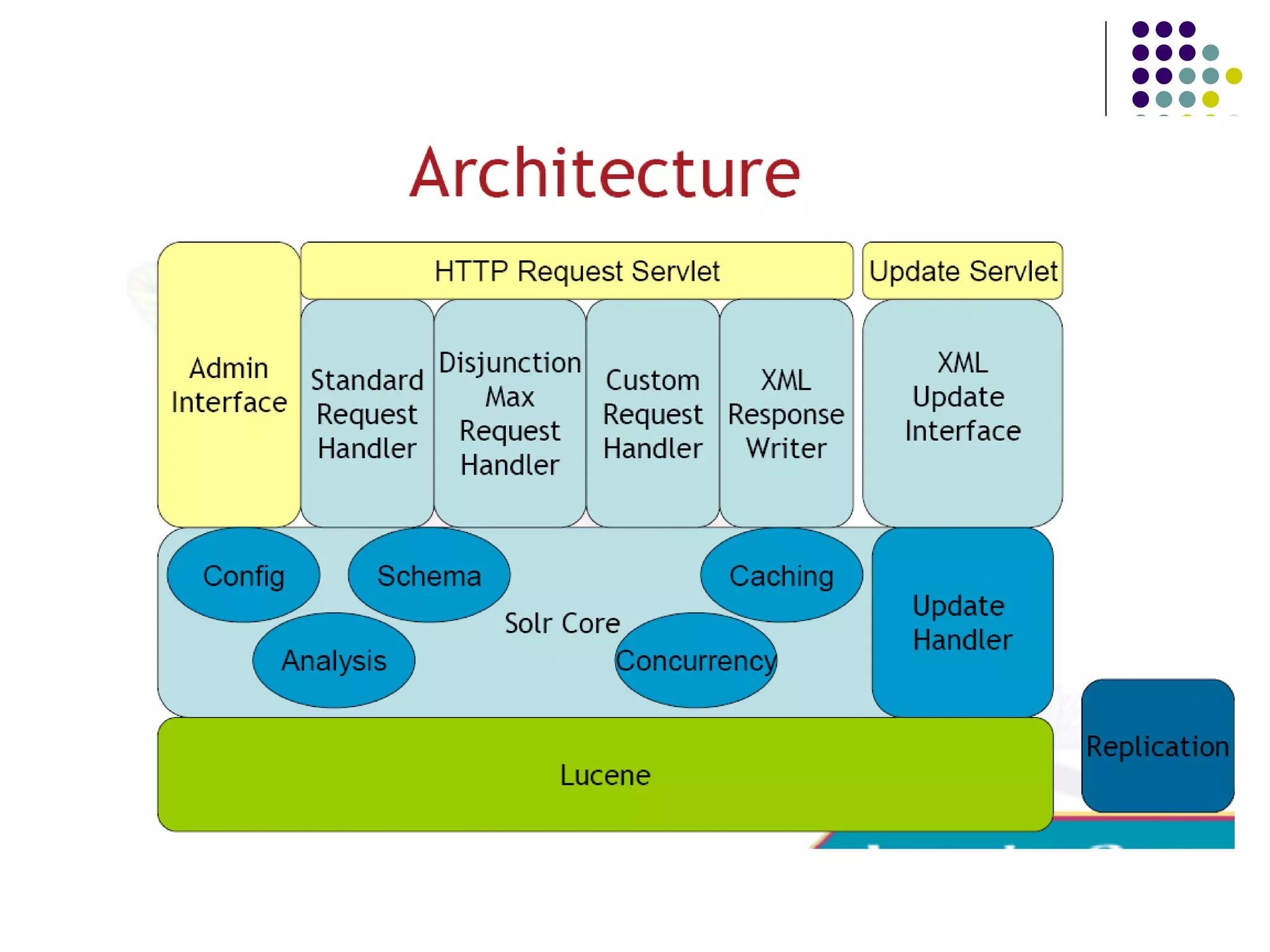
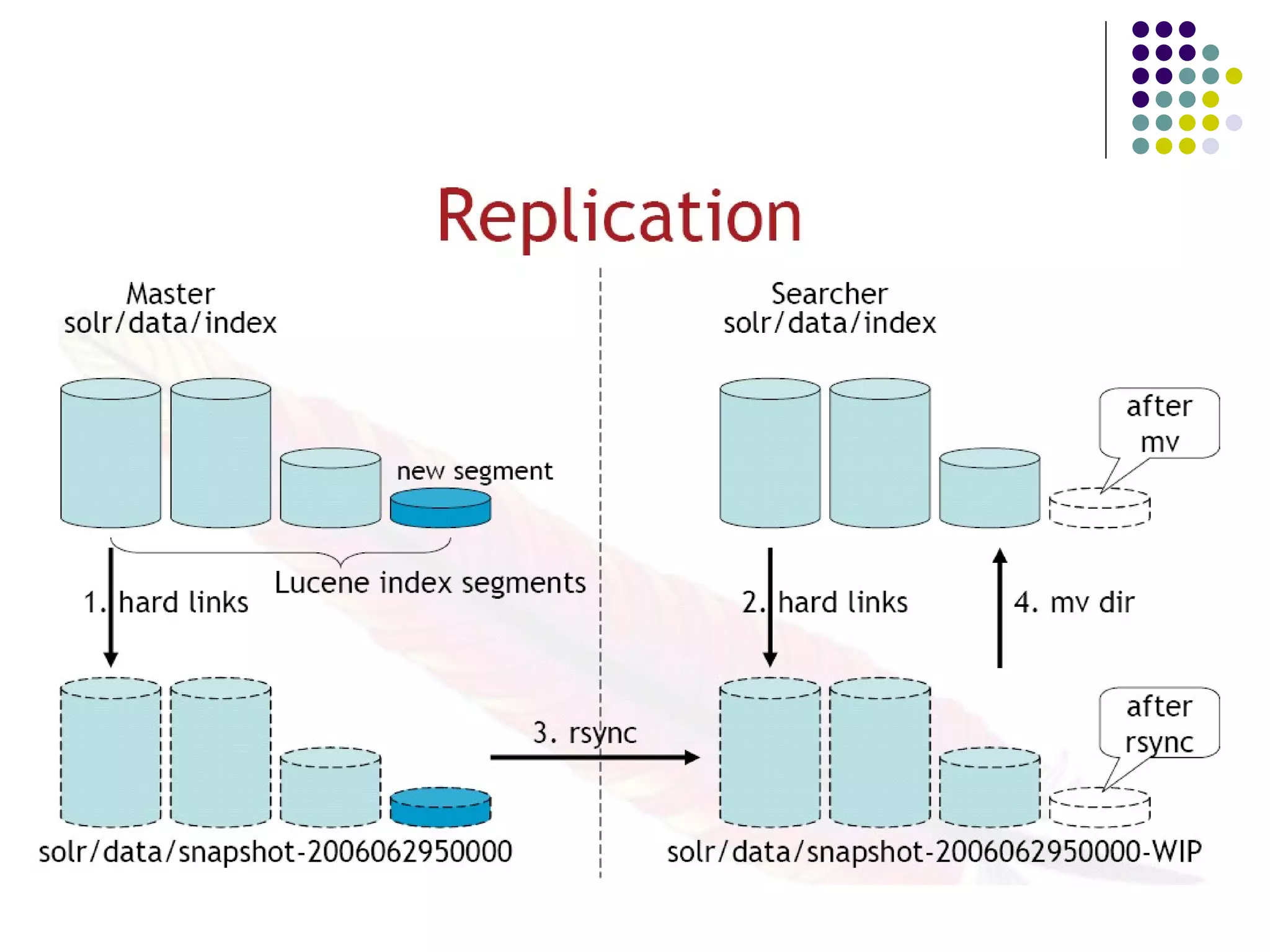
Defines Solr as a REST layer for Lucene, highlighting its robust search features and capabilities such as full-text search, XML/HTTP interfaces, and extensive caching.
Describes methods for adding and deleting documents in Solr, including HTTP POST commands for updating and committing changes to the index.
Covers Lucene query syntax and advanced searching techniques in Solr, including field-specific searching, fuzzy searches, and output configurations.
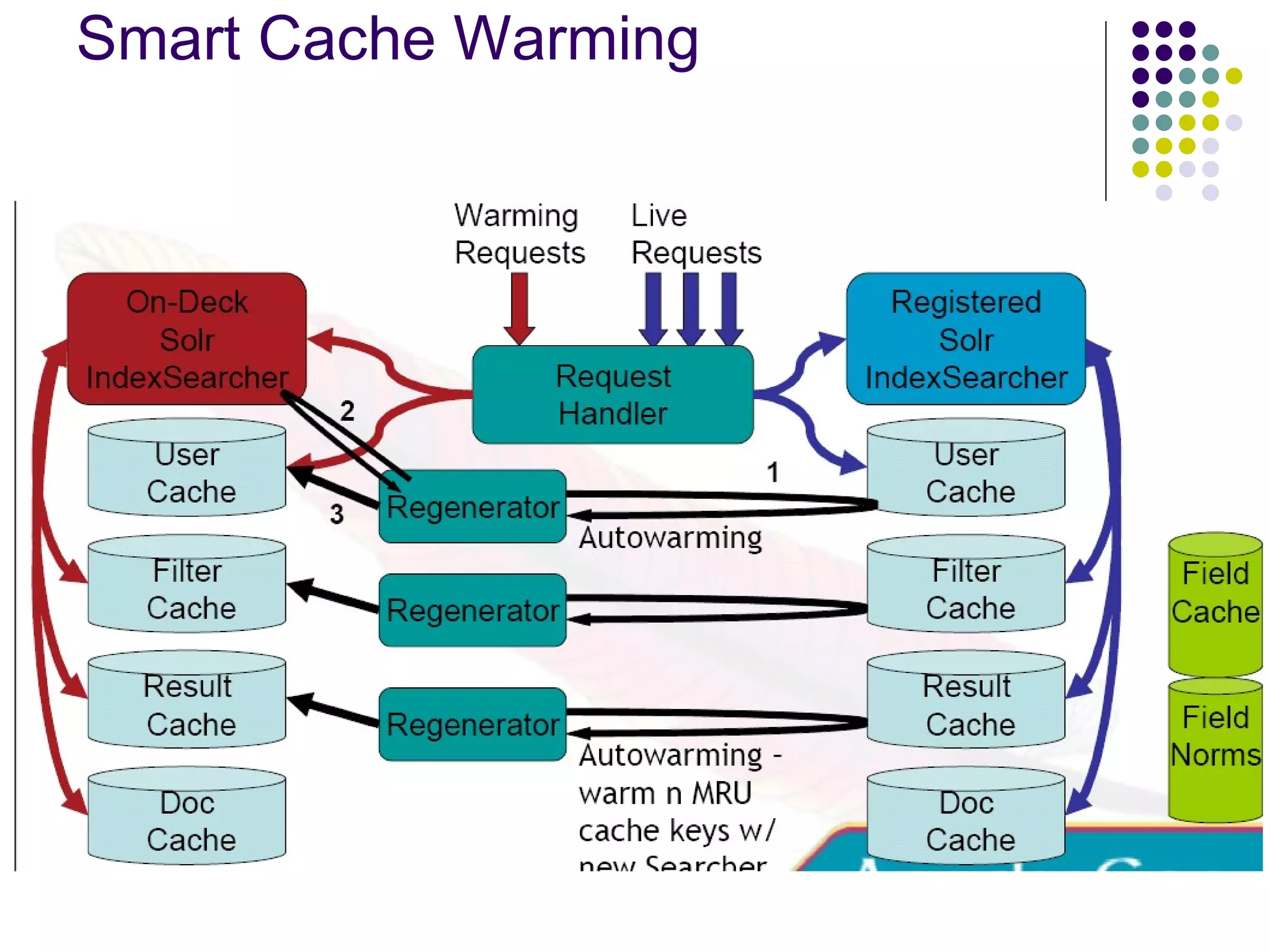
Details default parameters for queries and caching behavior in Solr, including aggressive caching and the importance of warming mechanisms for speed.
Discussion of Schemas in Solr, including sorting, defining field properties, and managing dynamic fields to tailor search capabilities.
Strategies for enhancing search relevancy in Solr. Discusses copyField functionality and field enhancement through various analyzers.
Overview of the Solr Web Admin interface for managing configurations, statistics, and analyzers. Highlights selling points of Solr and community support.
Envisions future enhancements for Solr including faceted browsing, database indexing, and integration with various APIs for expanded functionality.























































































