Download as PDF, PPTX










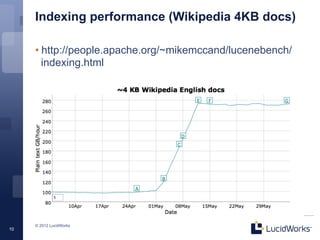
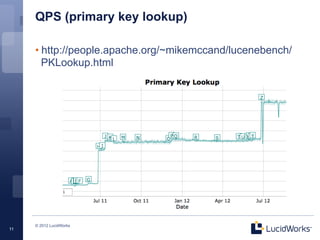
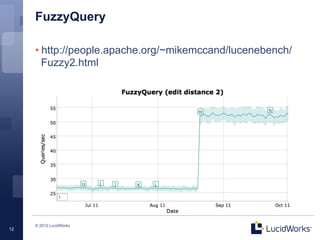










Solr 4.0 showcases significant enhancements in scalability, performance, and flexibility, driven by an upgraded Lucene architecture enabling near real-time search capabilities. Key improvements include pluggable scoring mechanisms, more efficient memory usage, and the introduction of SolrCloud for robust distributed indexing and search functionality. Additional features such as faster querying, improved document responses, and automatic recovery processes further streamline operations compared to previous Solr versions.

































































































