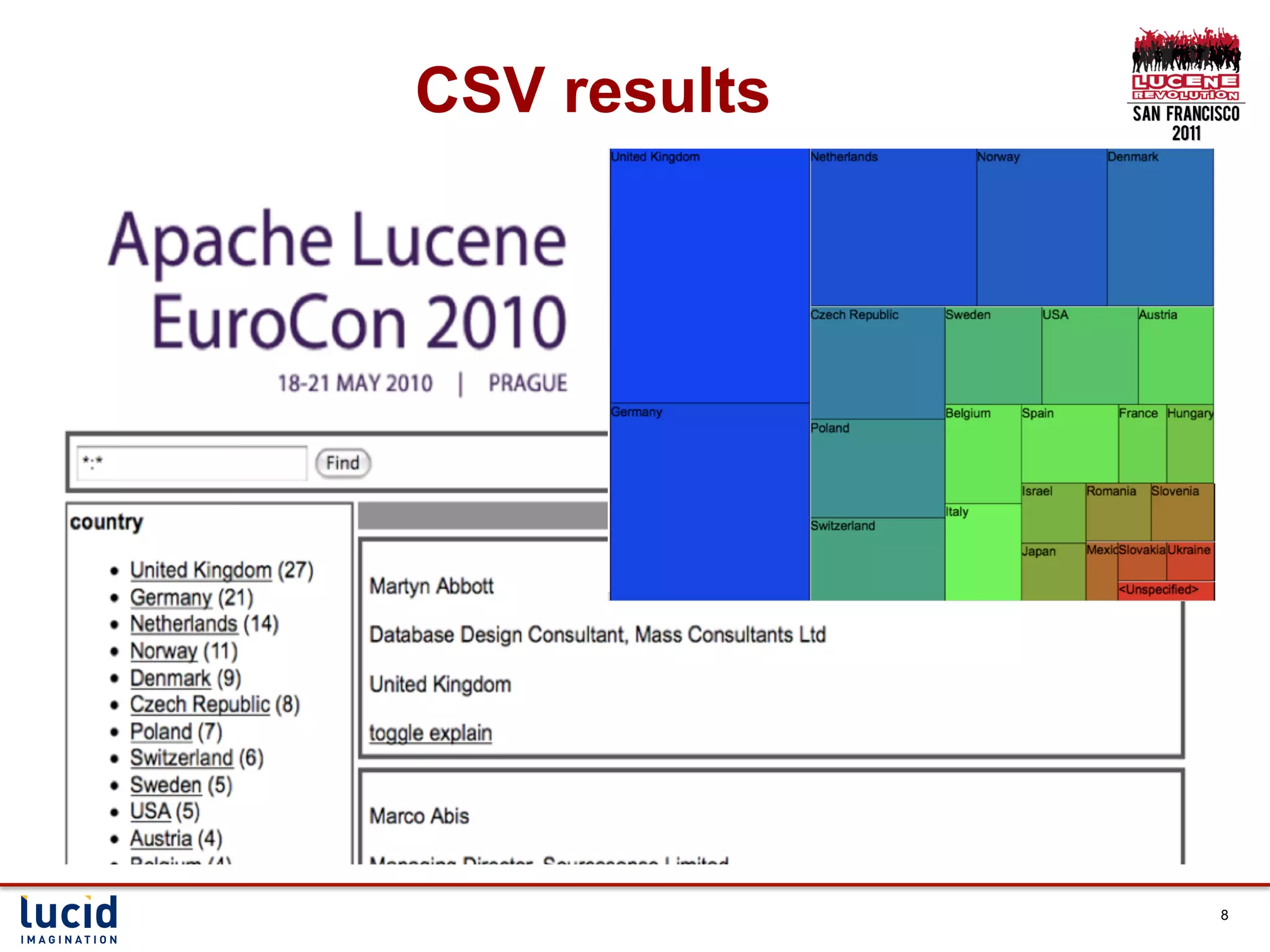
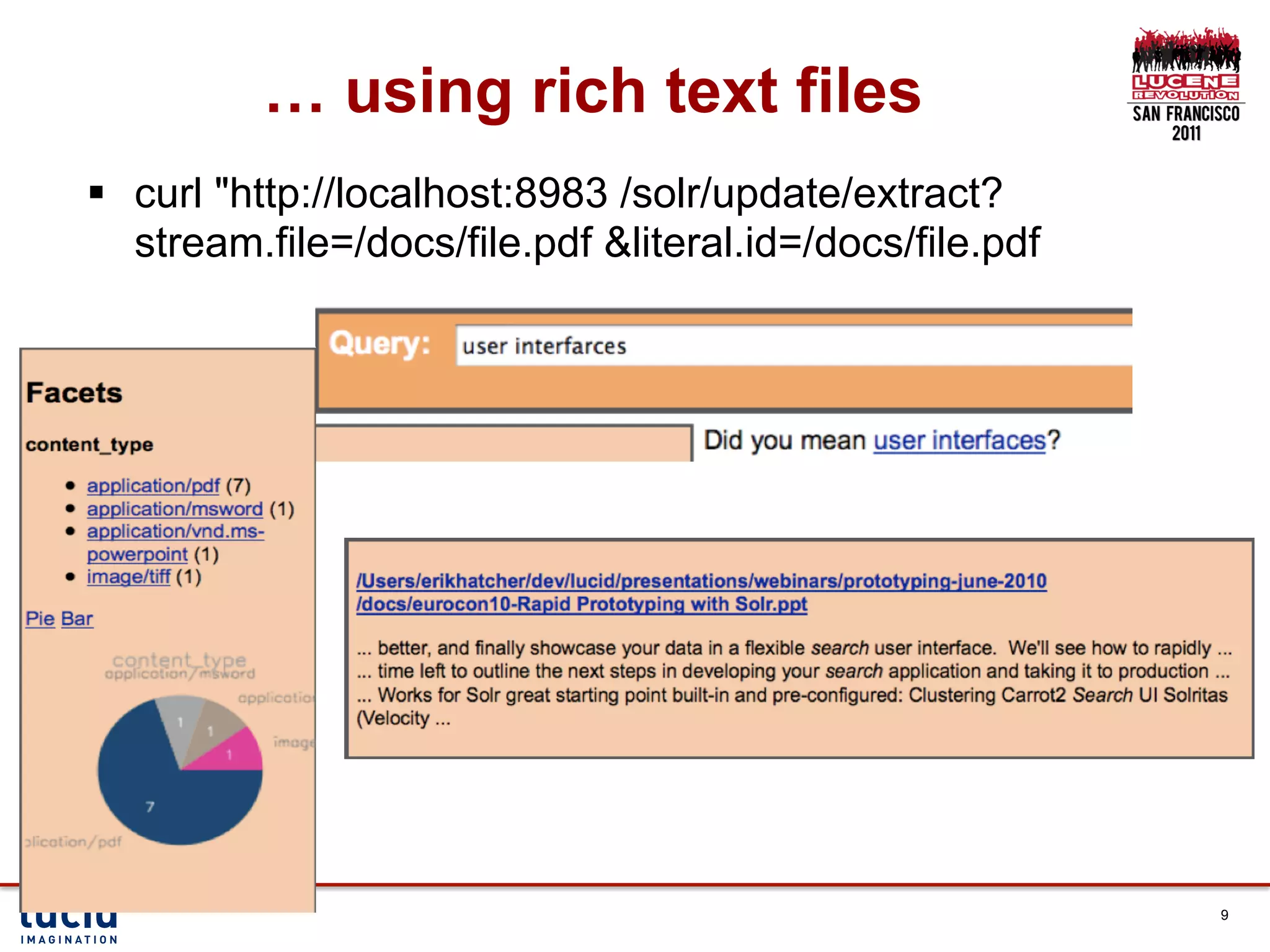
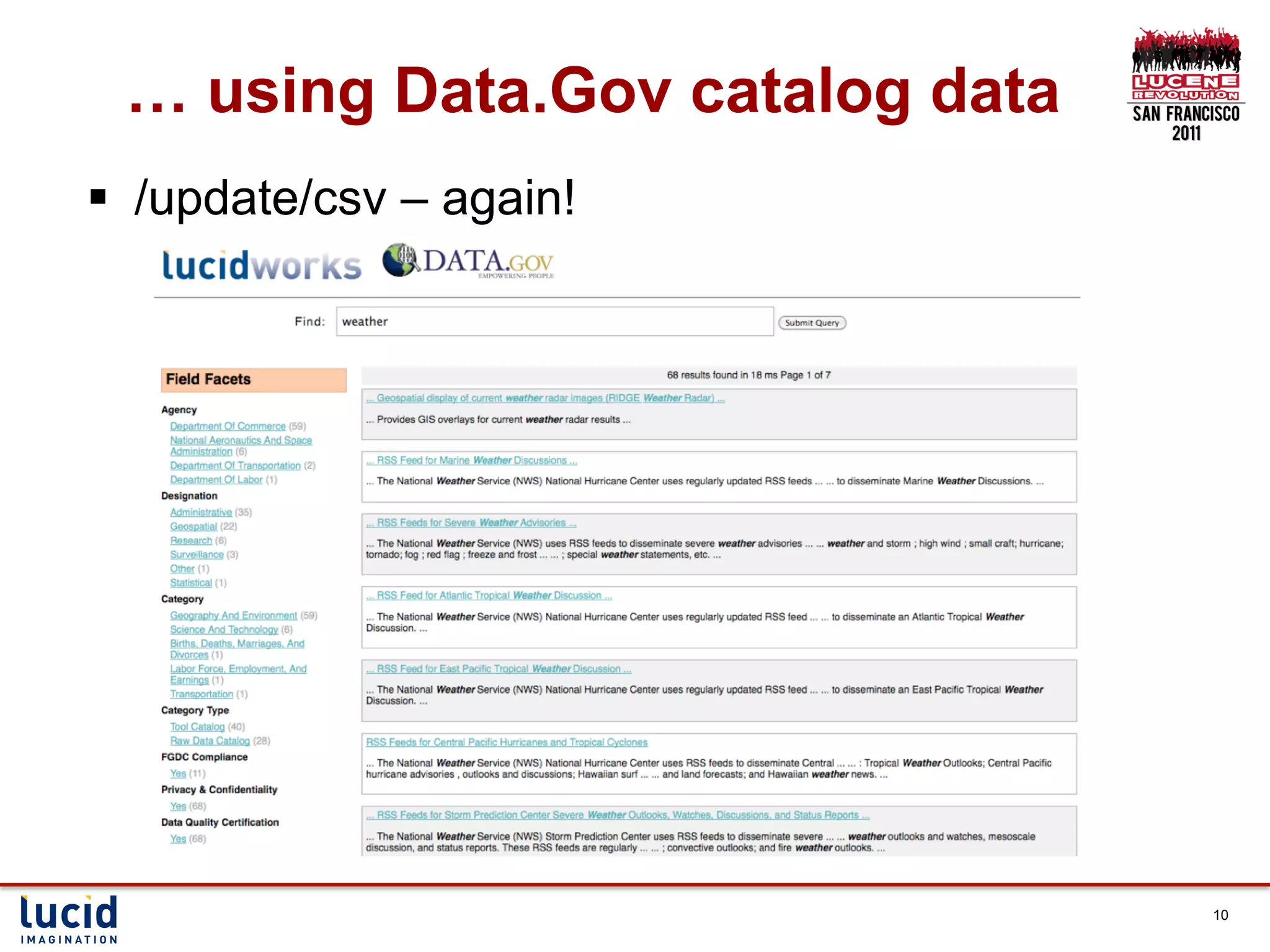
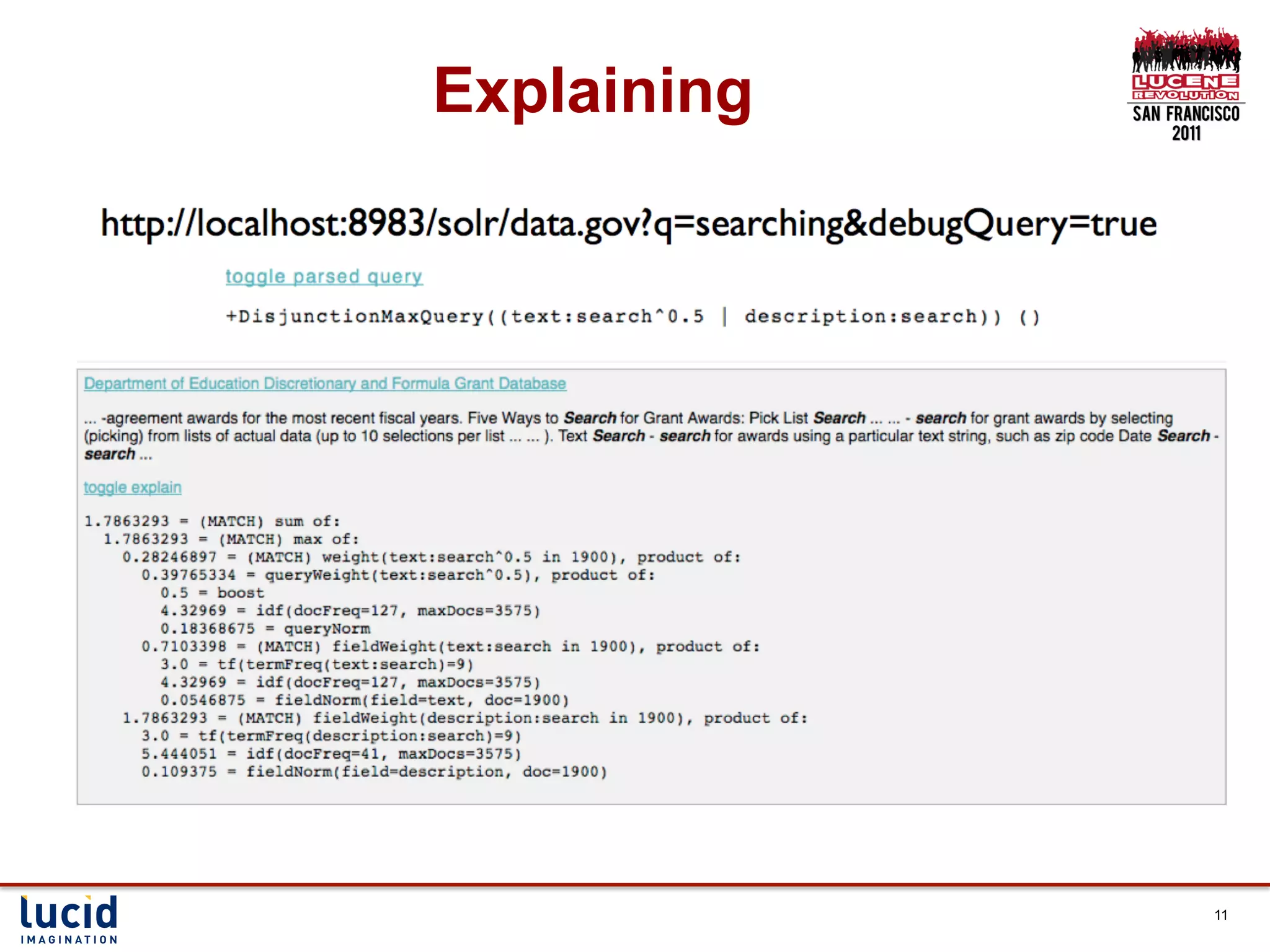
Download as PDF, PPTX






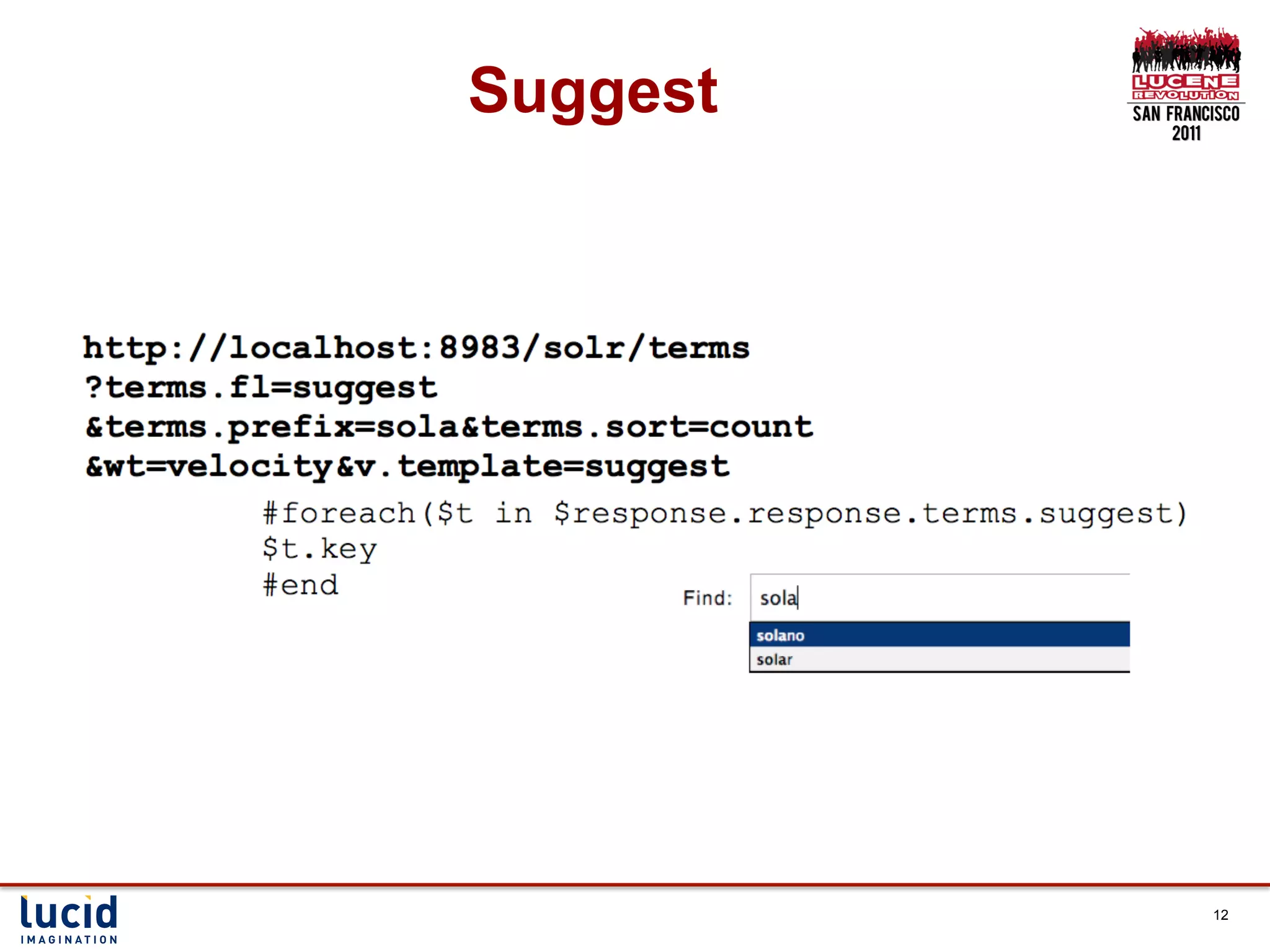
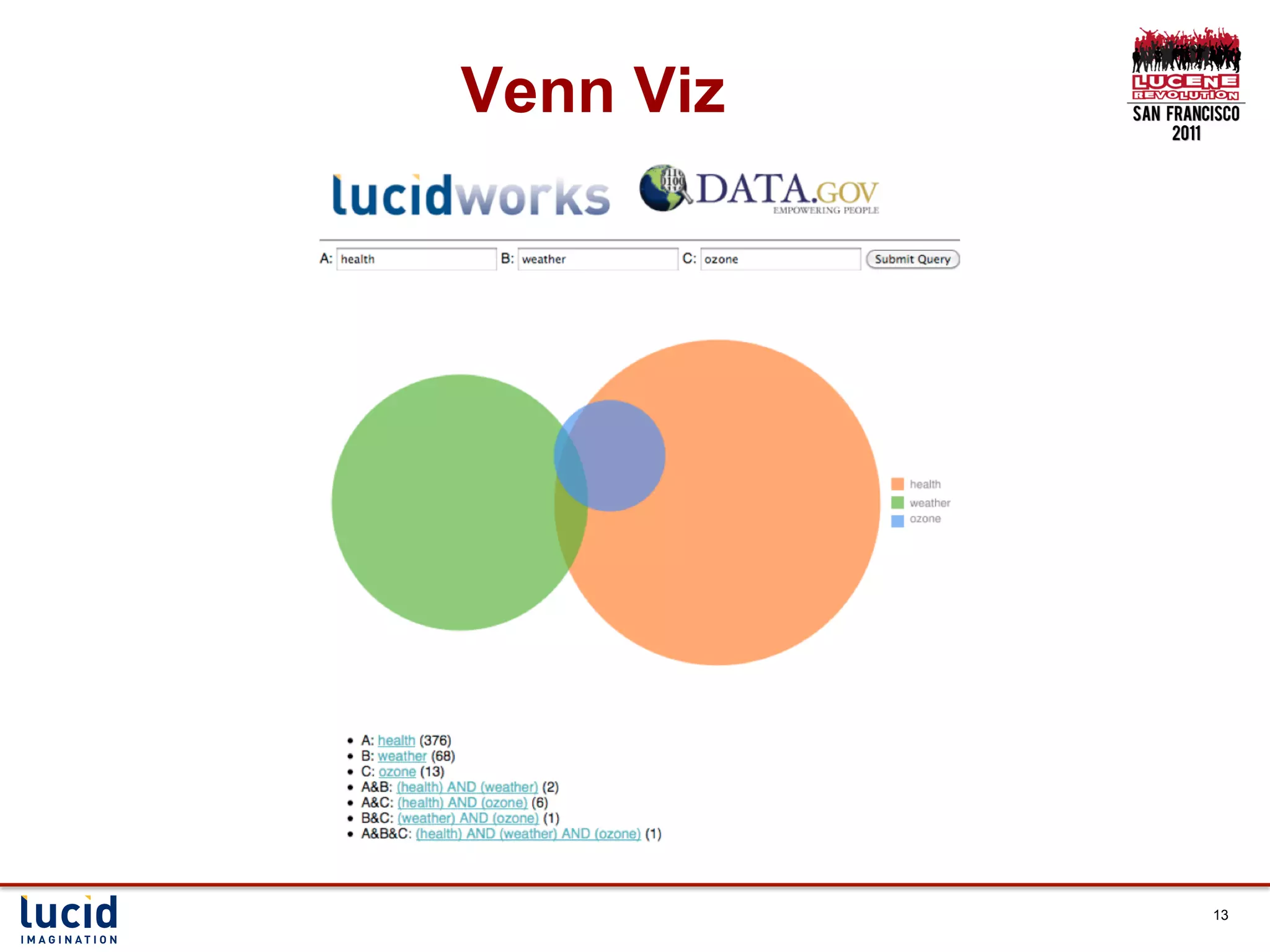

![Ingesting the data
require 'solr’!
#...!
1.upto(max_pages) do |page|!
puts "Processing page #{page}"!
json = fetch_page(page)!
!
response = JSON.parse(json, :symbolize_names=>true)!
puts "Total products: #{response[:total]}" if page == 1!
!
mapping = {!
:id => :sku,!
:name_t => :name,!
:thumbnail_s => :thumbnailImage,!
:url_s => :url,!
:type_s => :type,!
:category_s => Proc.new {|prod| !
prod[:categoryPath].collect {|cat| cat[:name]}.join(' >> ')},!
:department_s => :department,!
:class_s => :class,!
:subclass_s => :subclass,!
:sale_price_f => :salePrice!
}!
!
Solr::Indexer.new(response[:products], mapping, !
{:debug => debug, :buffer_docs => 500}).index!
end!
15](https://image.slidesharecdn.com/hatchererik-rapidprototypingwithsolr-110615055827-phpapp02/75/Rapid-Prototyping-with-Solr-14-2048.jpg)
![solr-ruby’s secret power
§ Solr::Indexer.new(
source, mapping, options
).index
§ “Quacks like a duck”
§ source simply #each’s
§ mapping simply #[]’s
16](https://image.slidesharecdn.com/hatchererik-rapidprototypingwithsolr-110615055827-phpapp02/75/Rapid-Prototyping-with-Solr-15-2048.jpg)


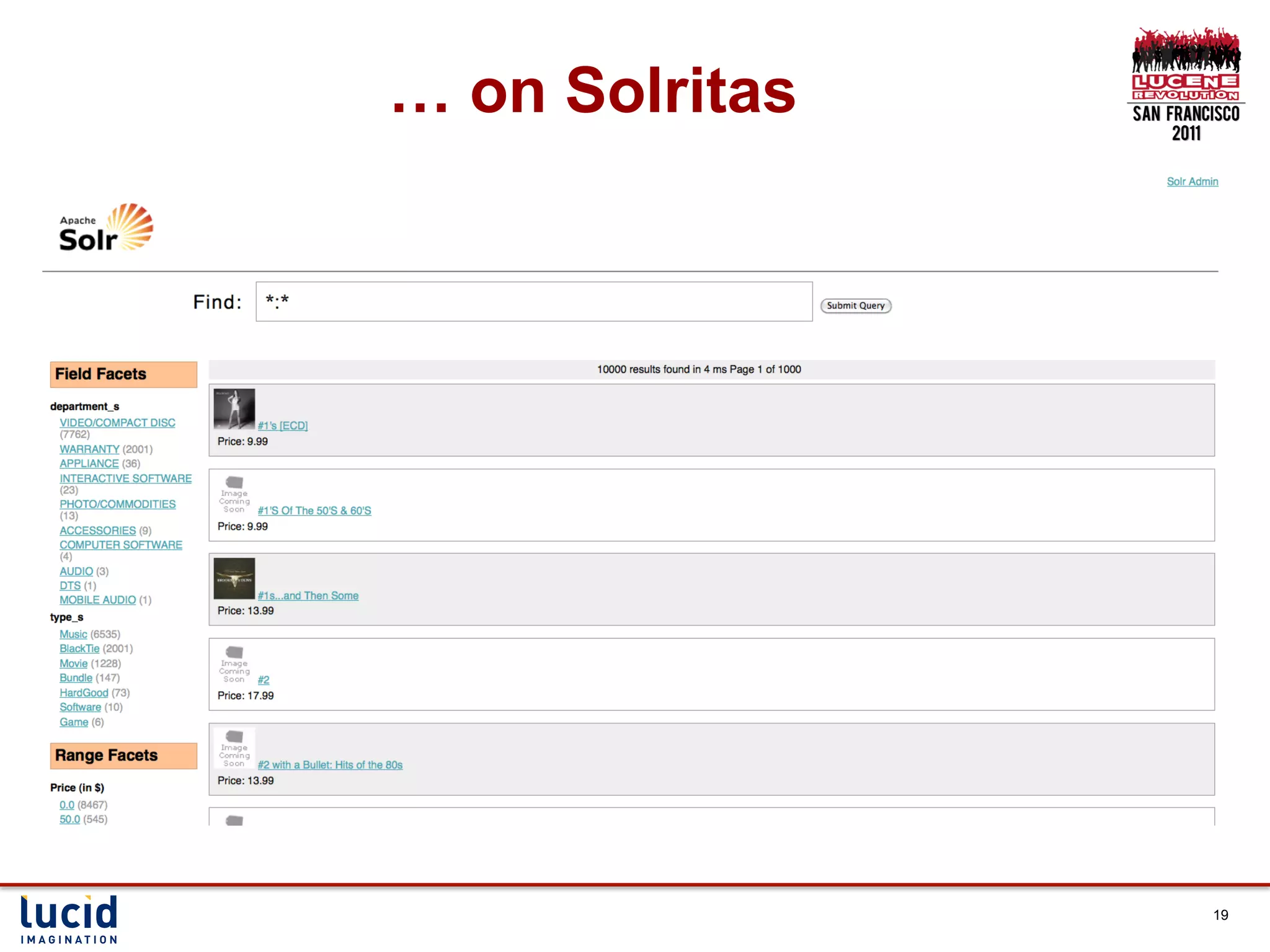

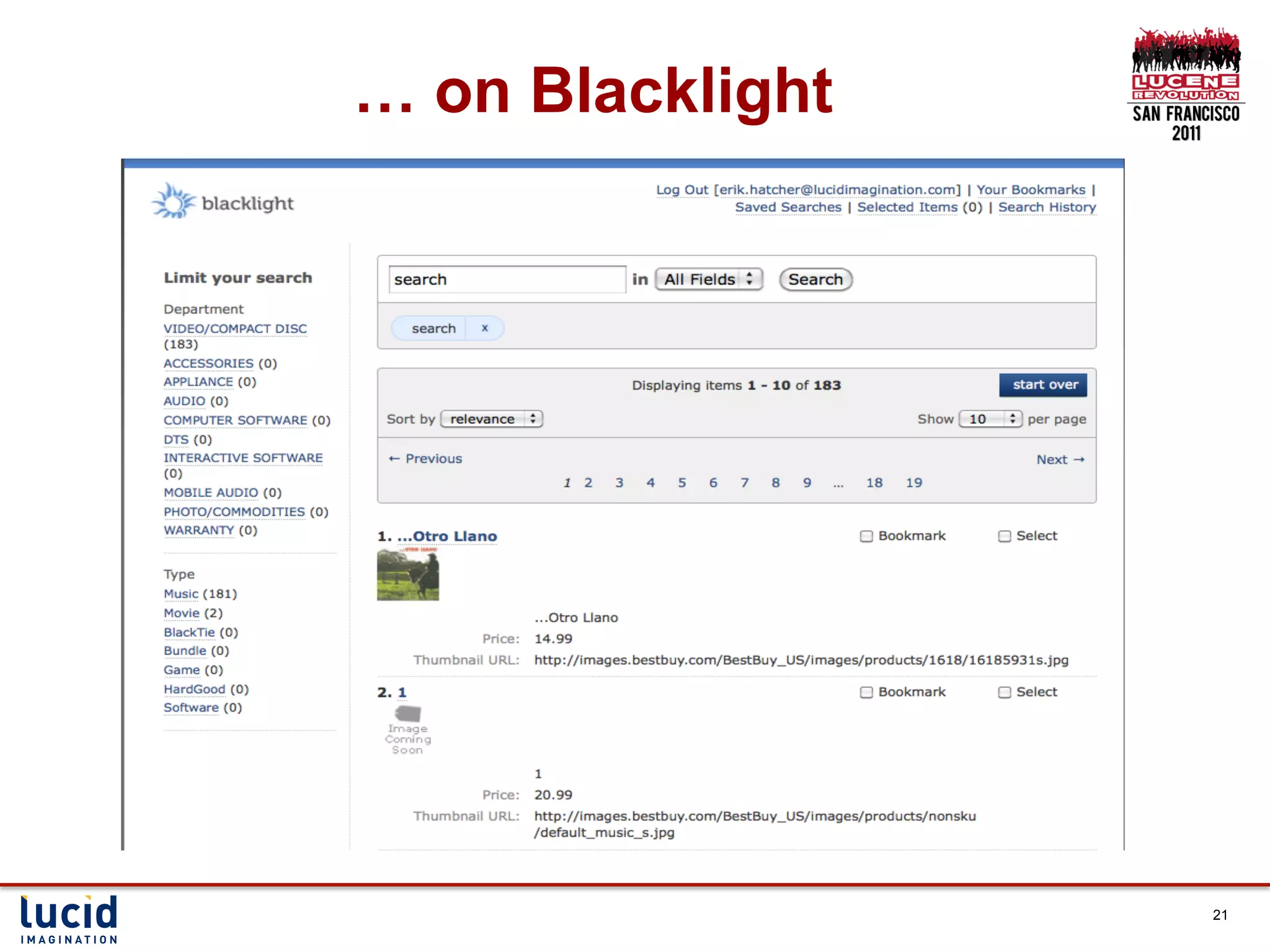






This document presents a session on rapid prototyping with Solr, showcasing how to quickly make data searchable and develop a user-friendly interface. It includes techniques for getting data into Solr, customizing its schema, and utilizing features like faceting and highlighting. Additionally, it emphasizes the importance of user engagement and iterative development in building effective search applications.























































































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)




![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




