Download as KEY, PPTX






![Query
• Faceted Search, the queries could be a problem?
– Exemple
http://localhost:8983/solr/select?
q=video&rows=0&facet=true&facet.field=inStock
&facet.query=price:[*+TO+500]
&facet.query=price:[500+TO+*]
&facet.prefix=xx&facet.limit=5&facet.mincount=1](https://image.slidesharecdn.com/solr1-4-120804134141-phpapp02/75/Solr-7-2048.jpg)




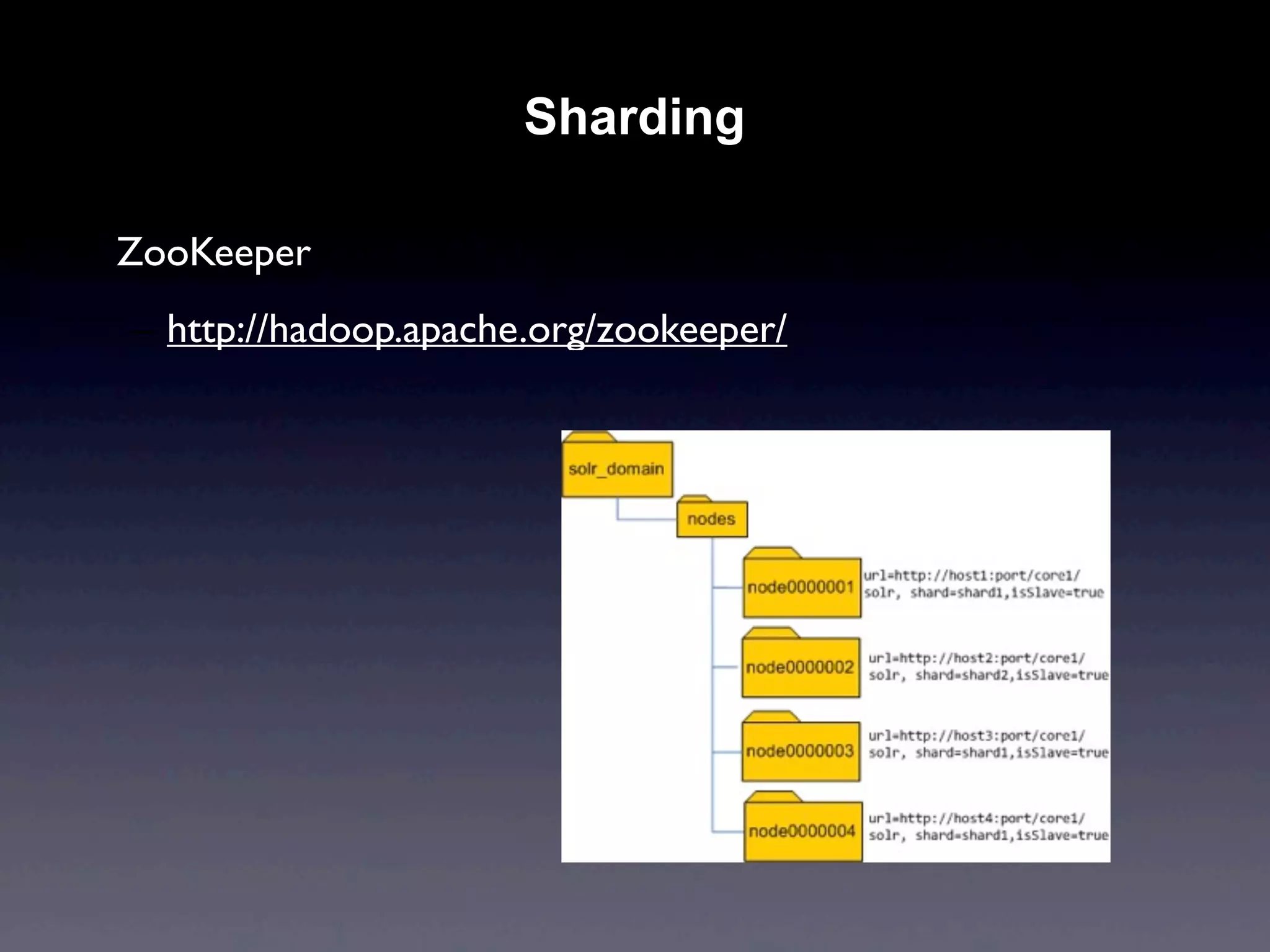




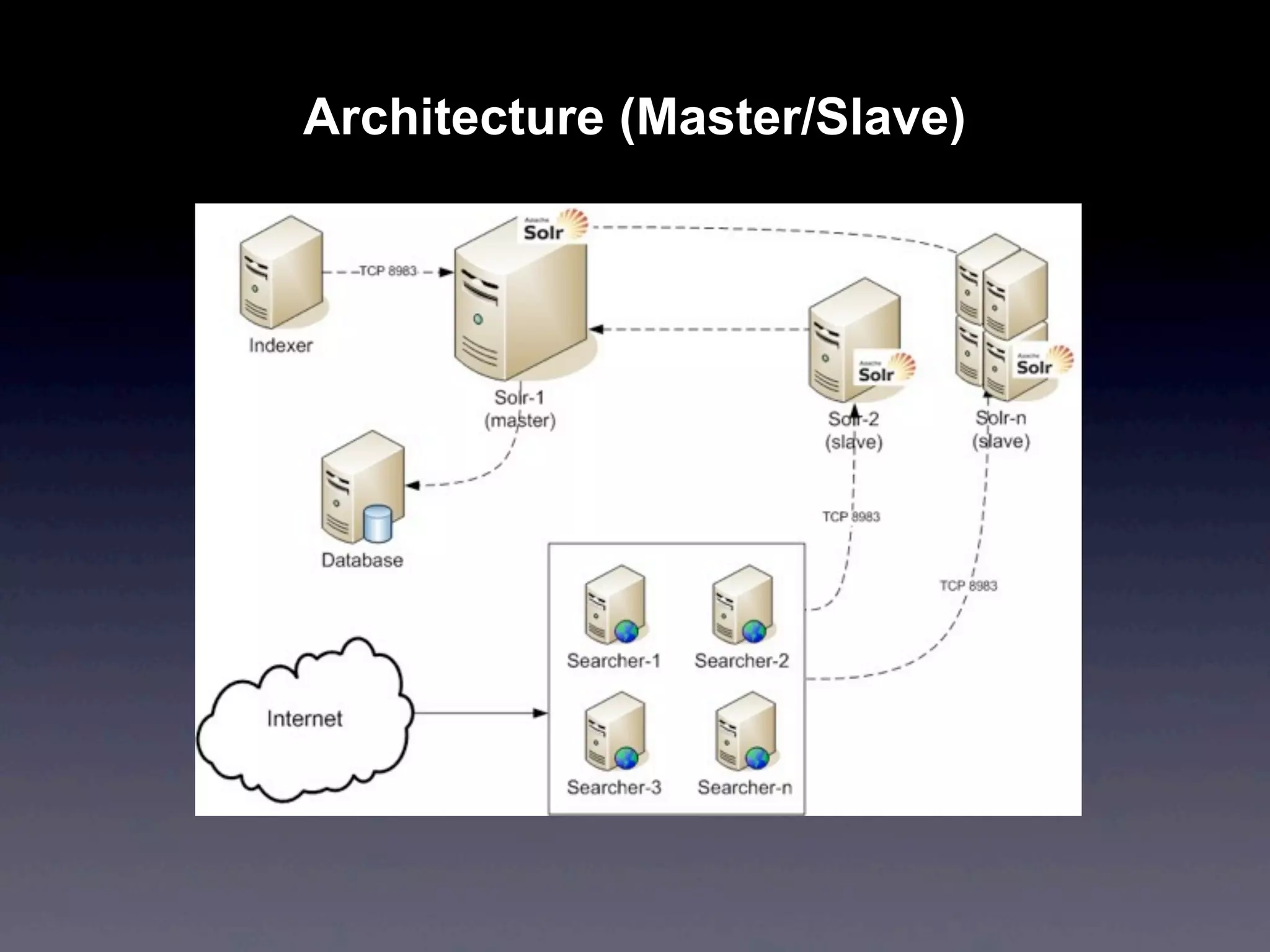
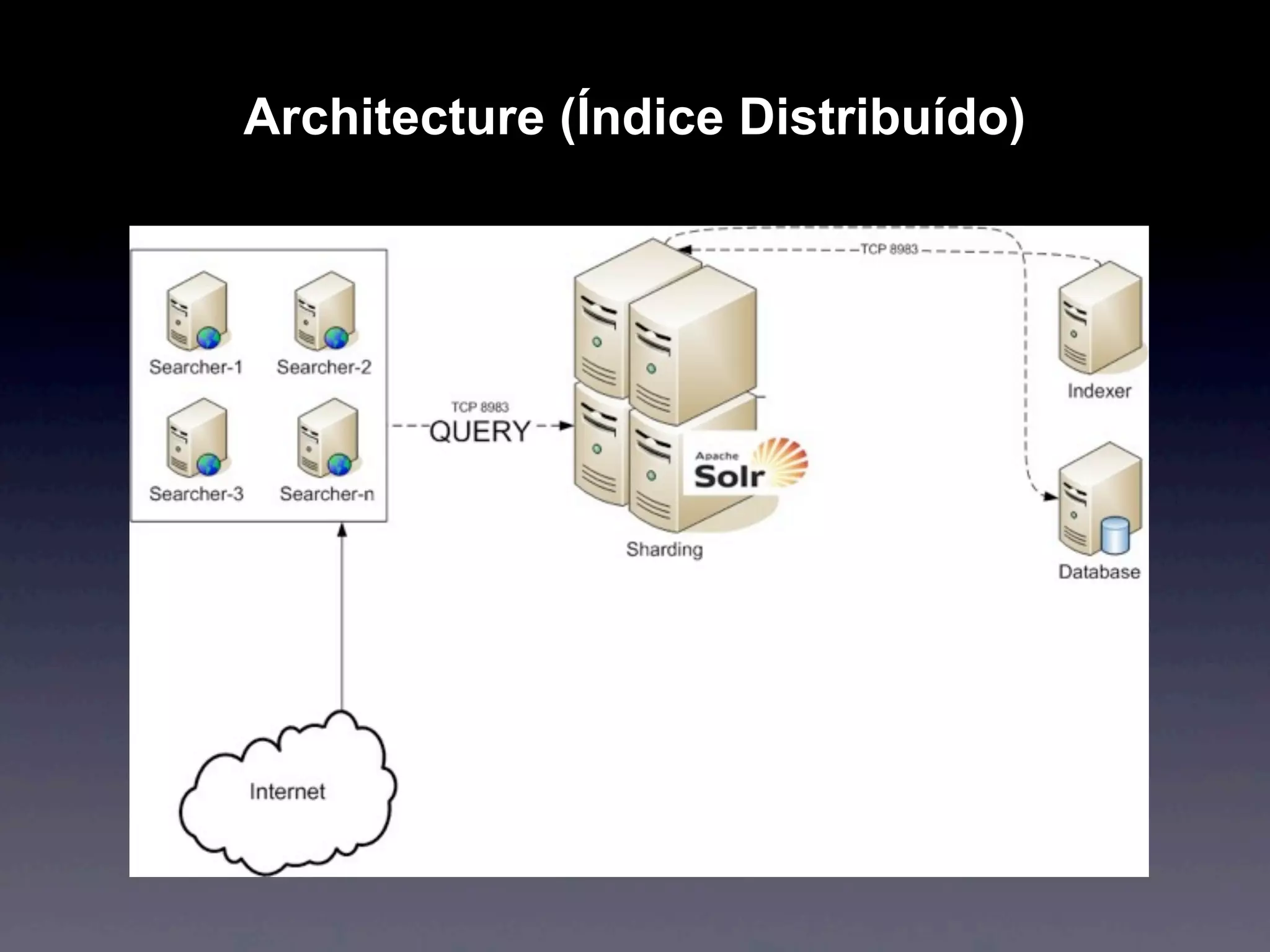

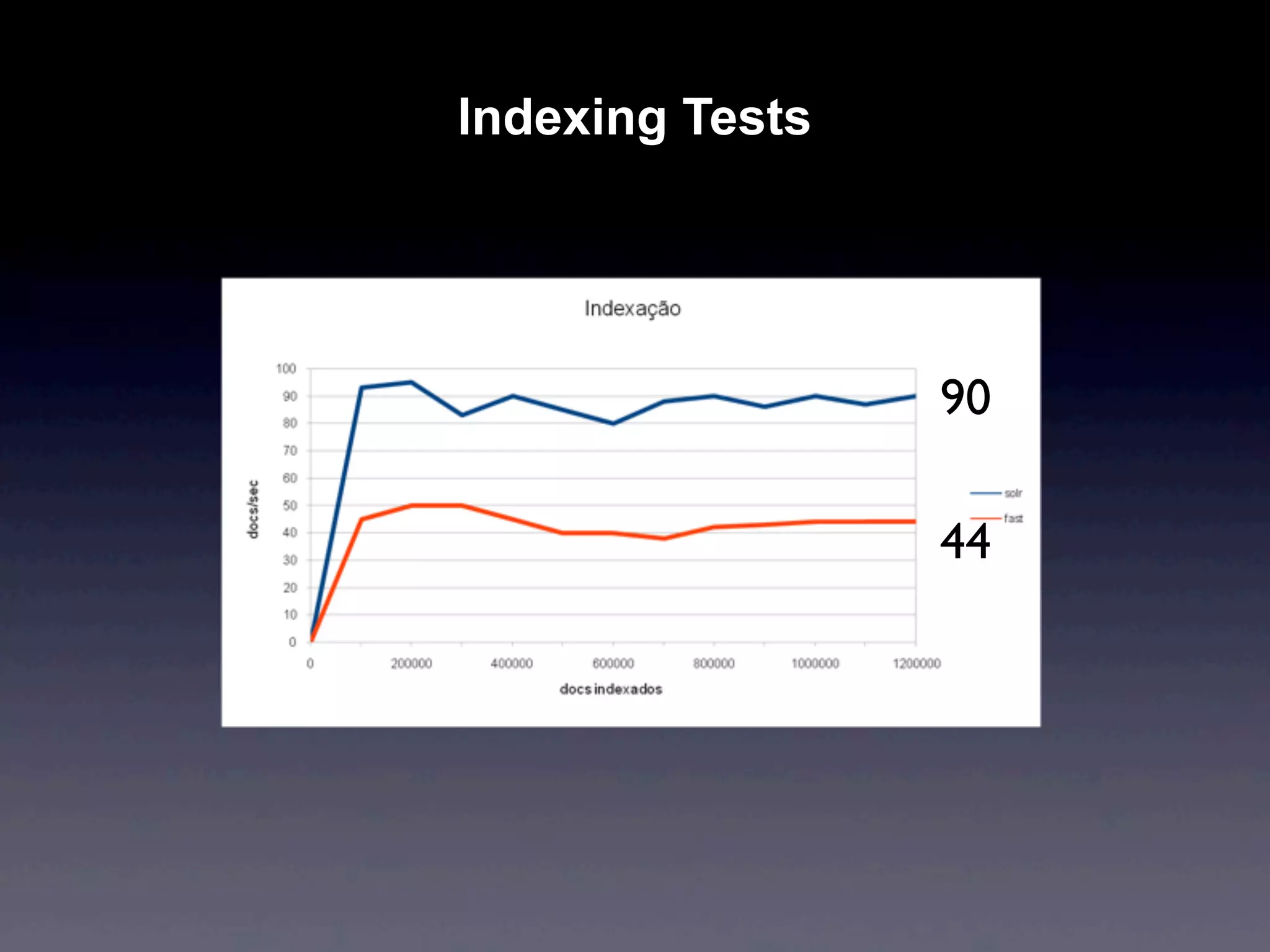
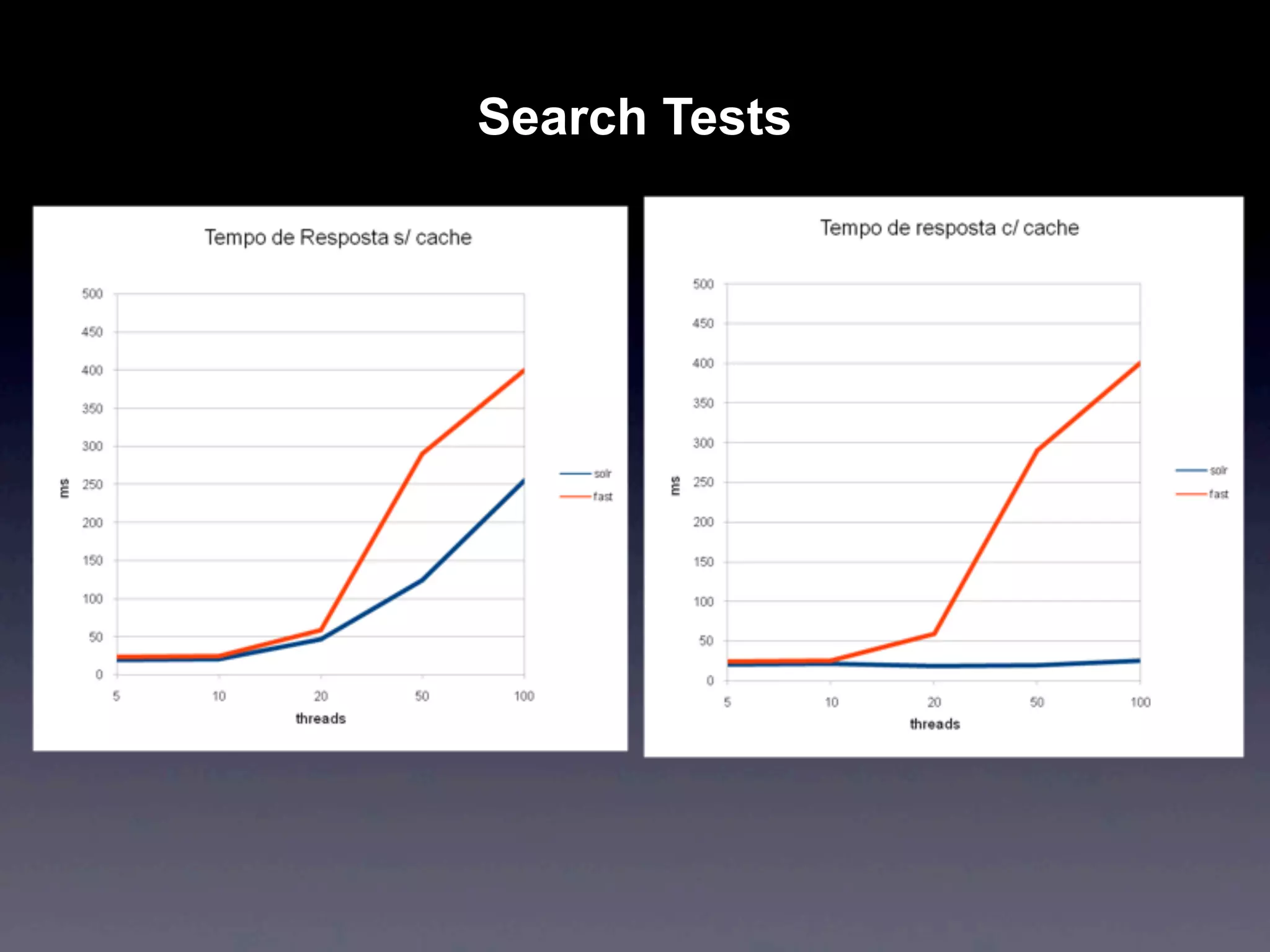
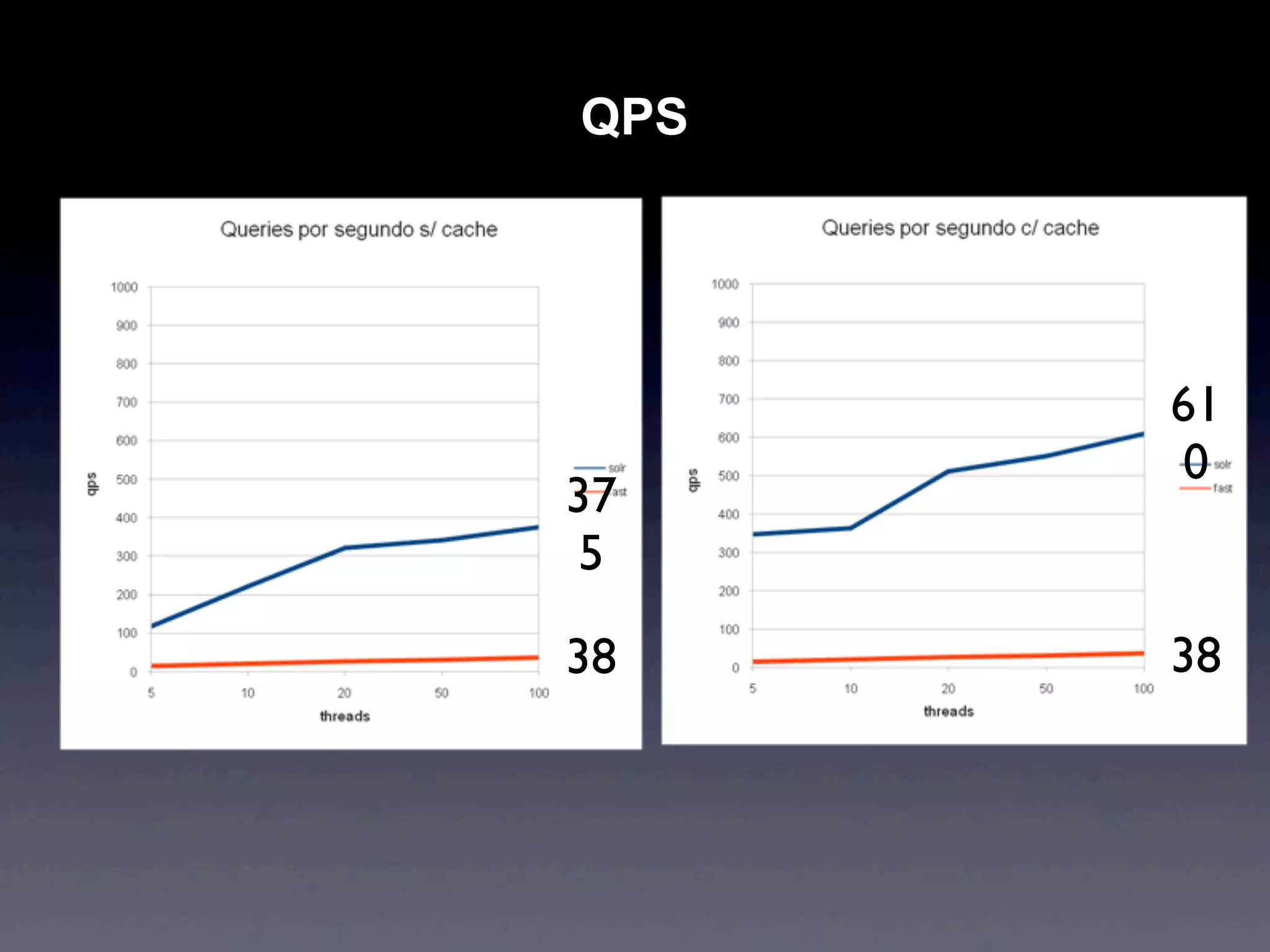


Apache Solr is an open source search engine based on Apache Lucene. It provides features like hit highlighting, faceted search, indexing and searching large amounts of data from databases or XML files. Solr is written in Java and can be run on Tomcat, JBoss or Jetty. It allows searching and filtering of data through queries and faceted navigation. Solr supports sharding and replication across multiple servers for high performance and scalability.























































































