Download as PDF, PPTX











![Solr JSON
POST to /update/json
[
{"id" : "TestDoc1", "title" : "test1"},
{"id" : "TestDoc2", "title" : "another test"}
]](https://image.slidesharecdn.com/nfjs-boston-2011-introductiontosolr-110911094517-phpapp01/75/Introduction-to-Solr-14-2048.jpg)



















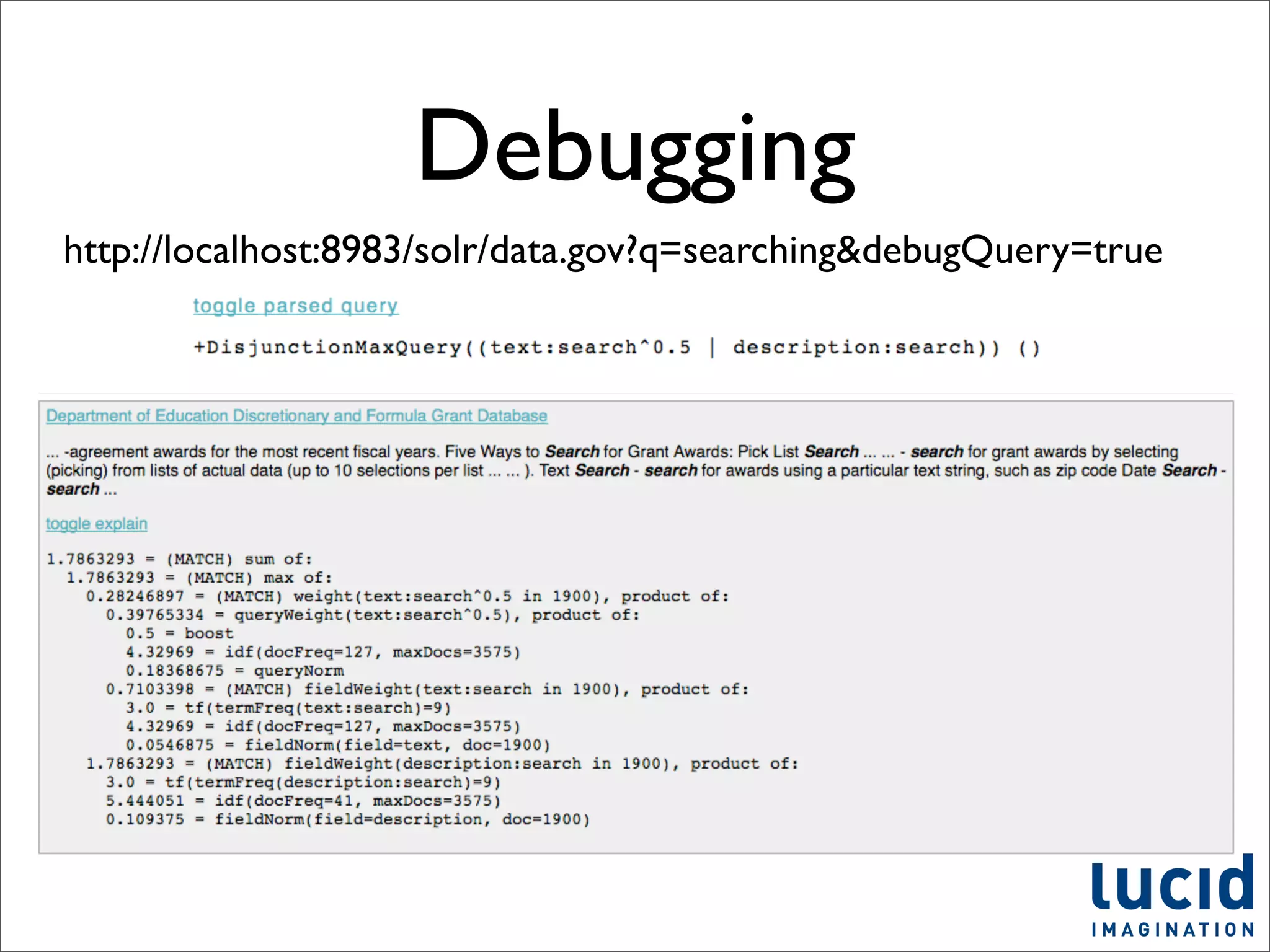

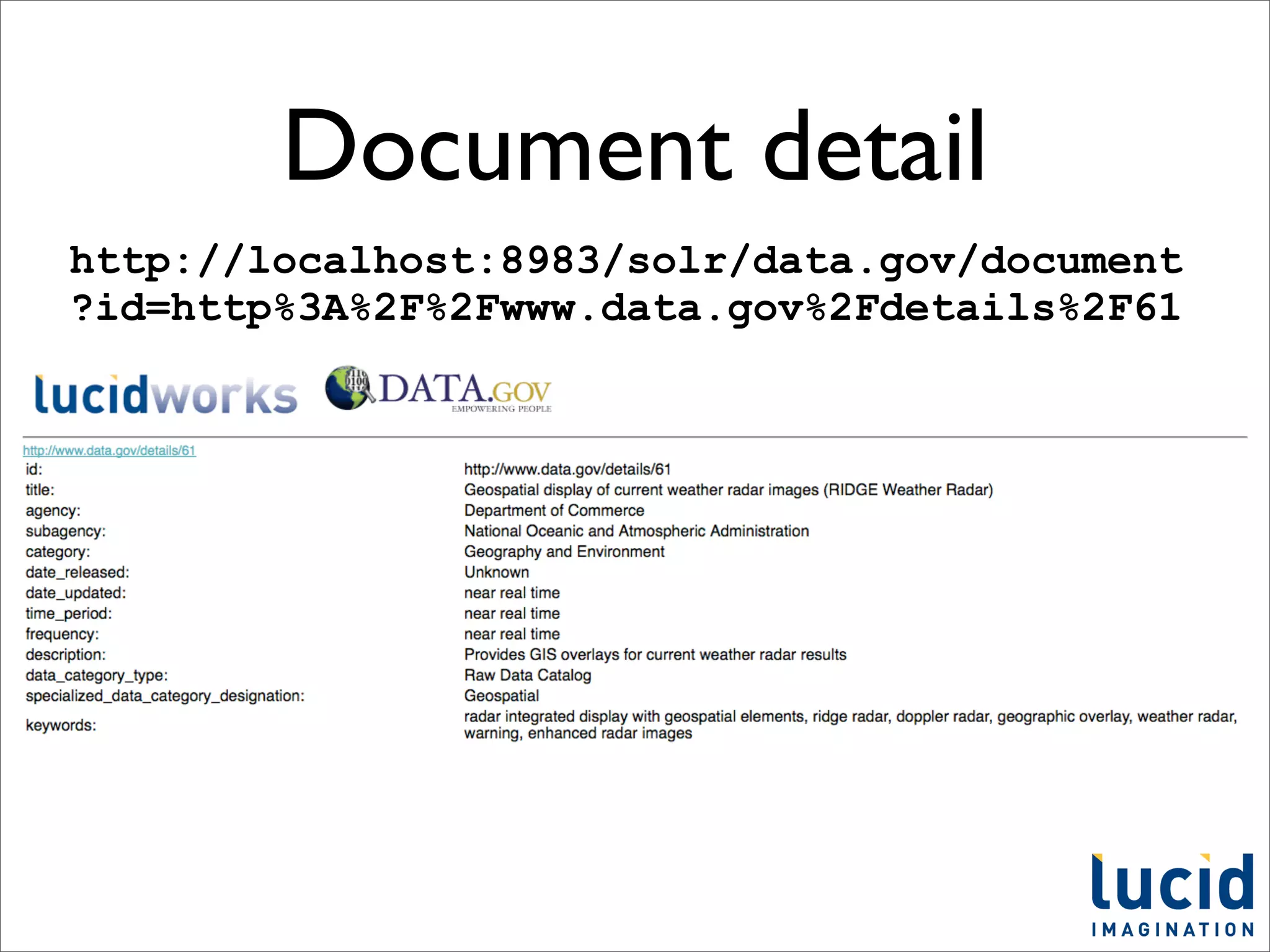

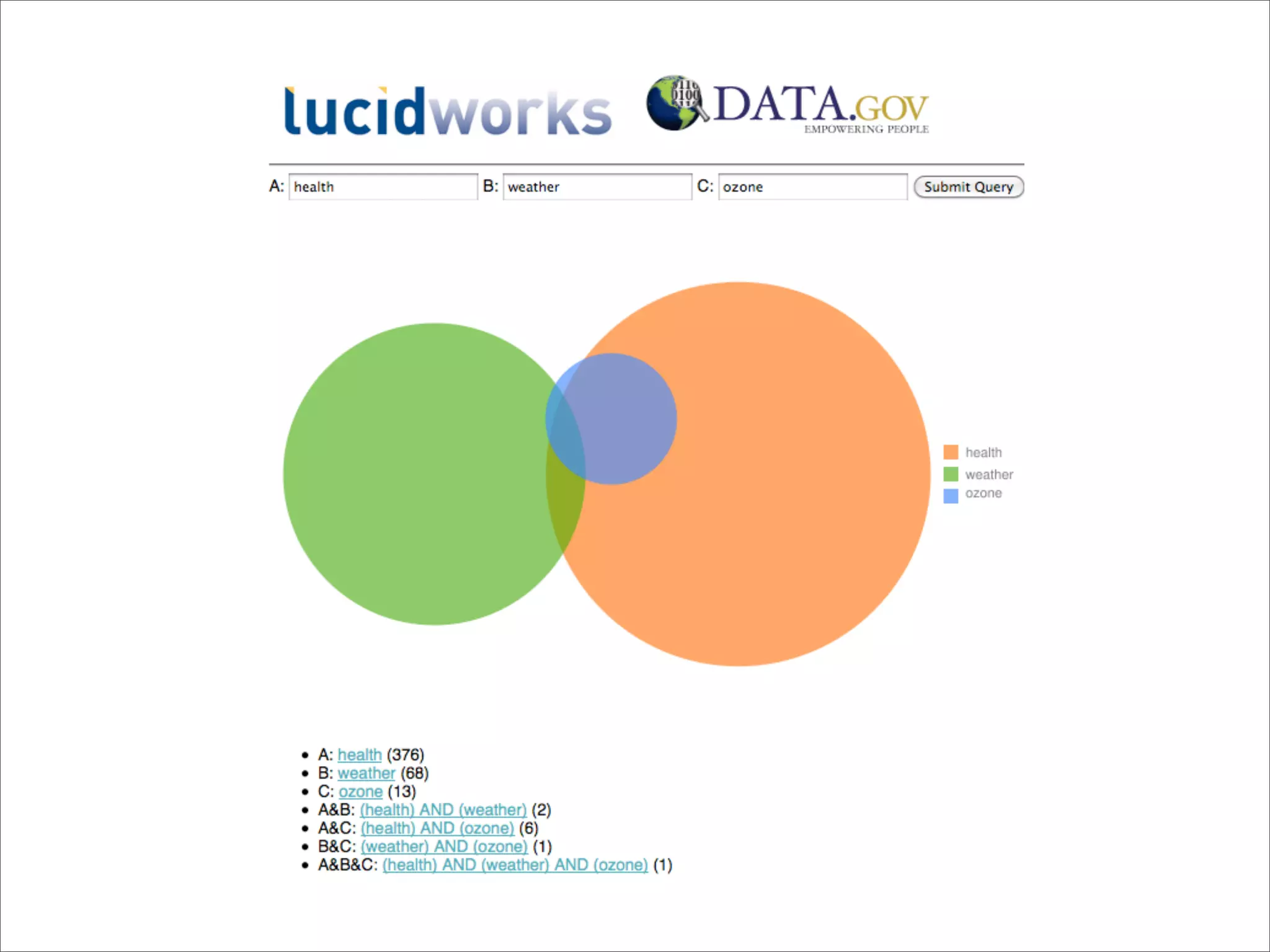


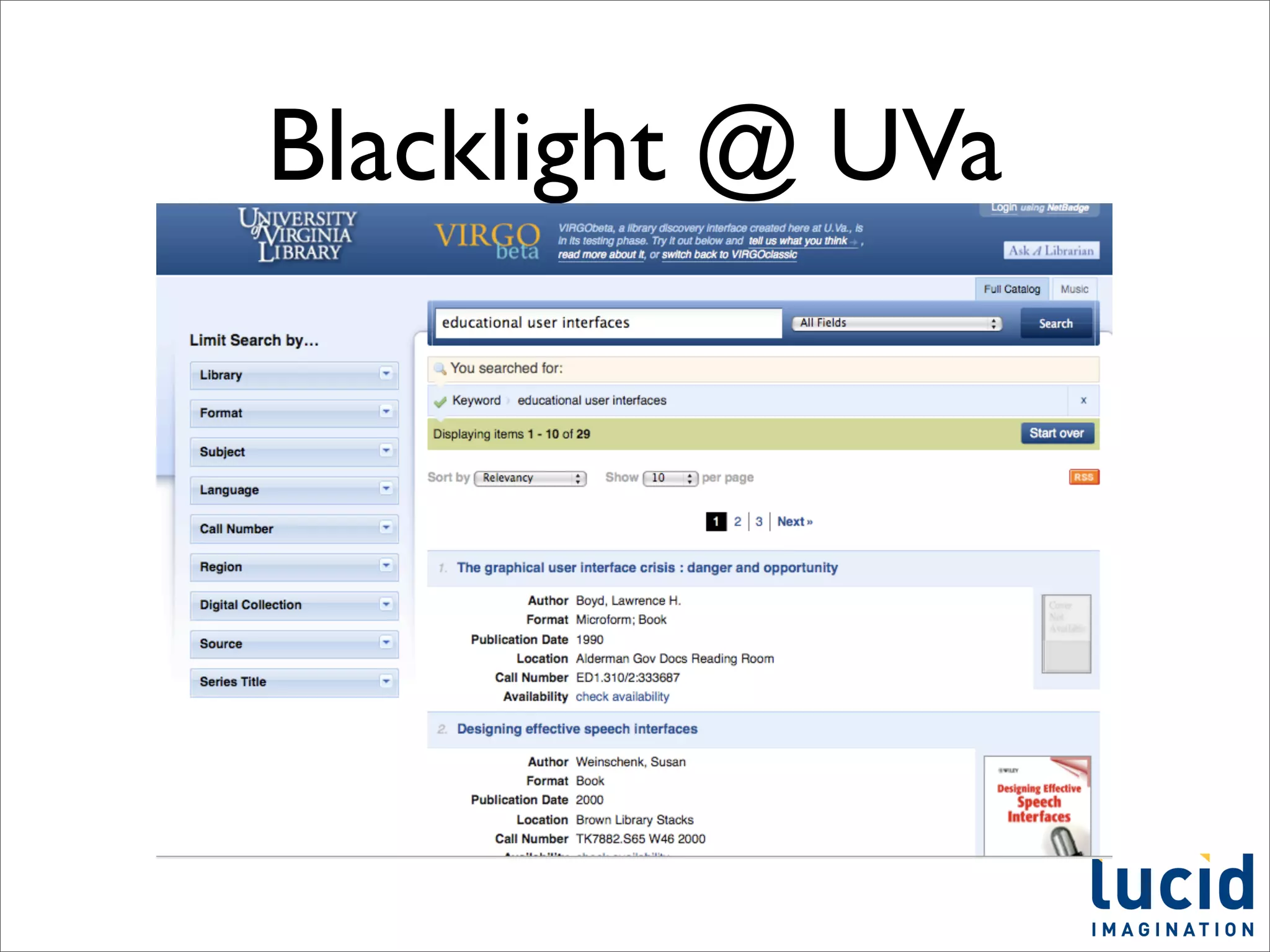
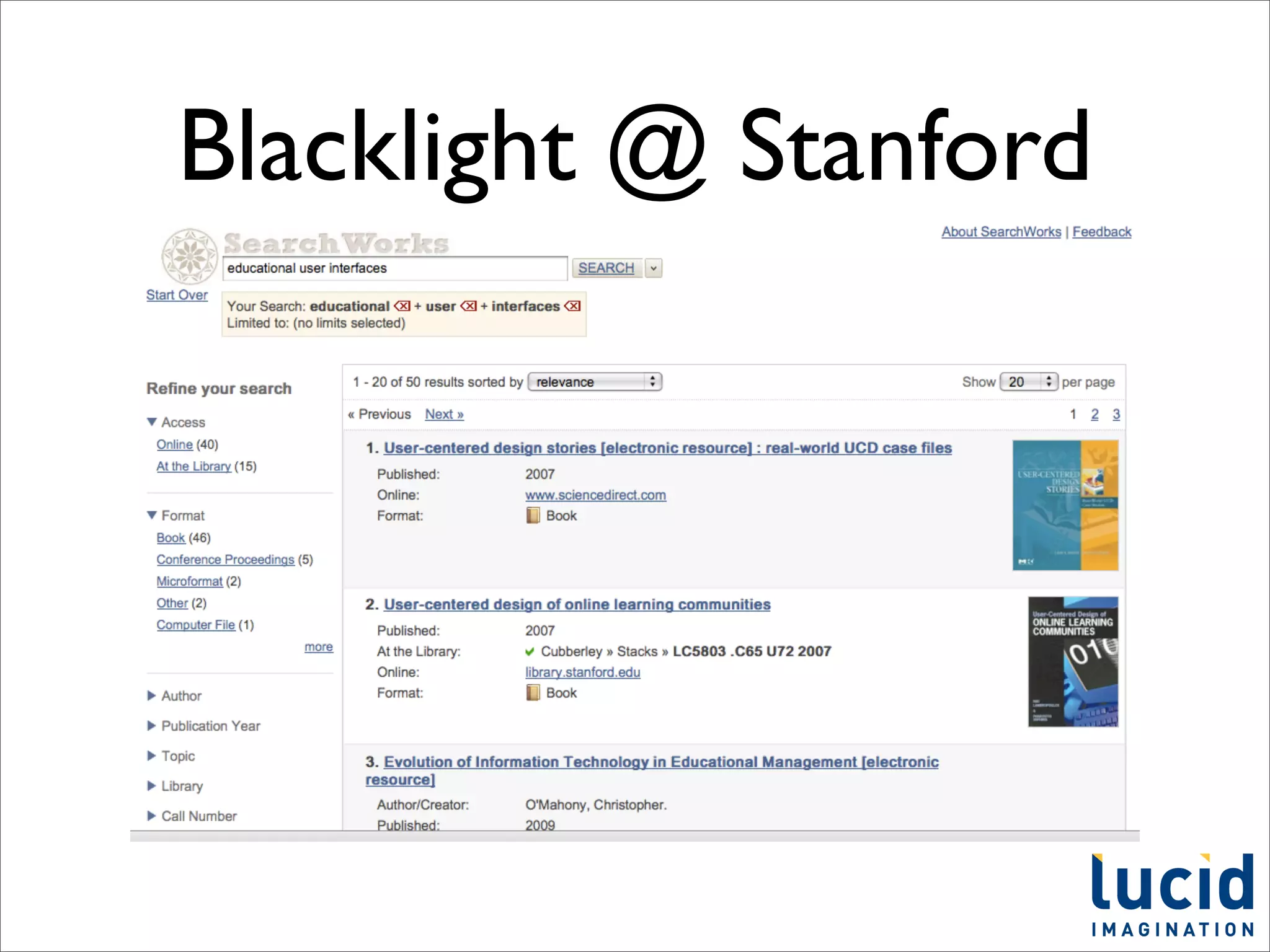

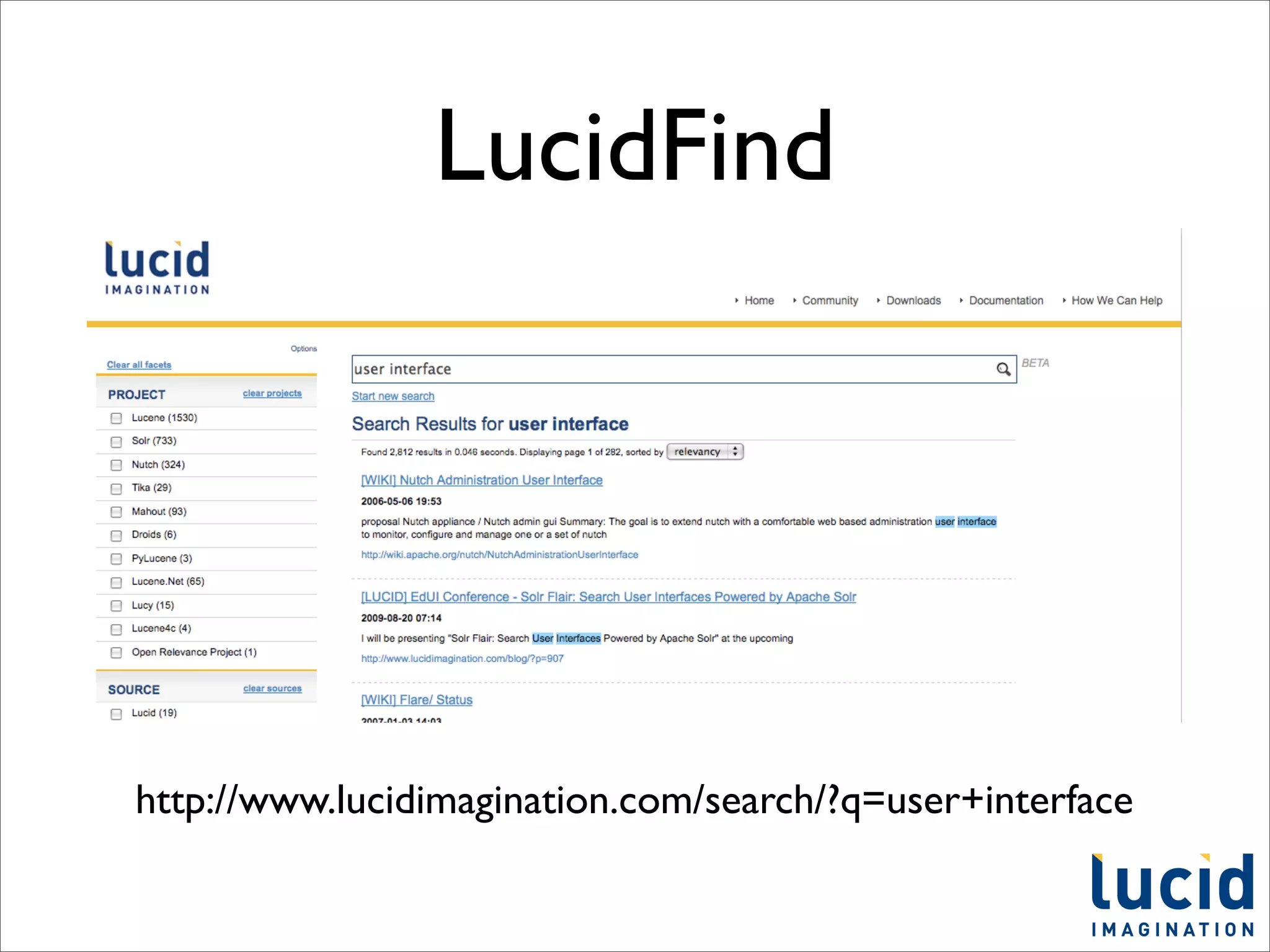


This document provides a summary of the Solr search platform. It begins with introductions from the presenter and about Lucid Imagination. It then discusses what Solr is, how it works, who uses it, and its main features. The rest of the document dives deeper into topics like how Solr is configured, how to index and search data, and how to debug and customize Solr implementations. It promotes downloading and experimenting with Solr to learn more.























































































