Download as PDF, PPTX






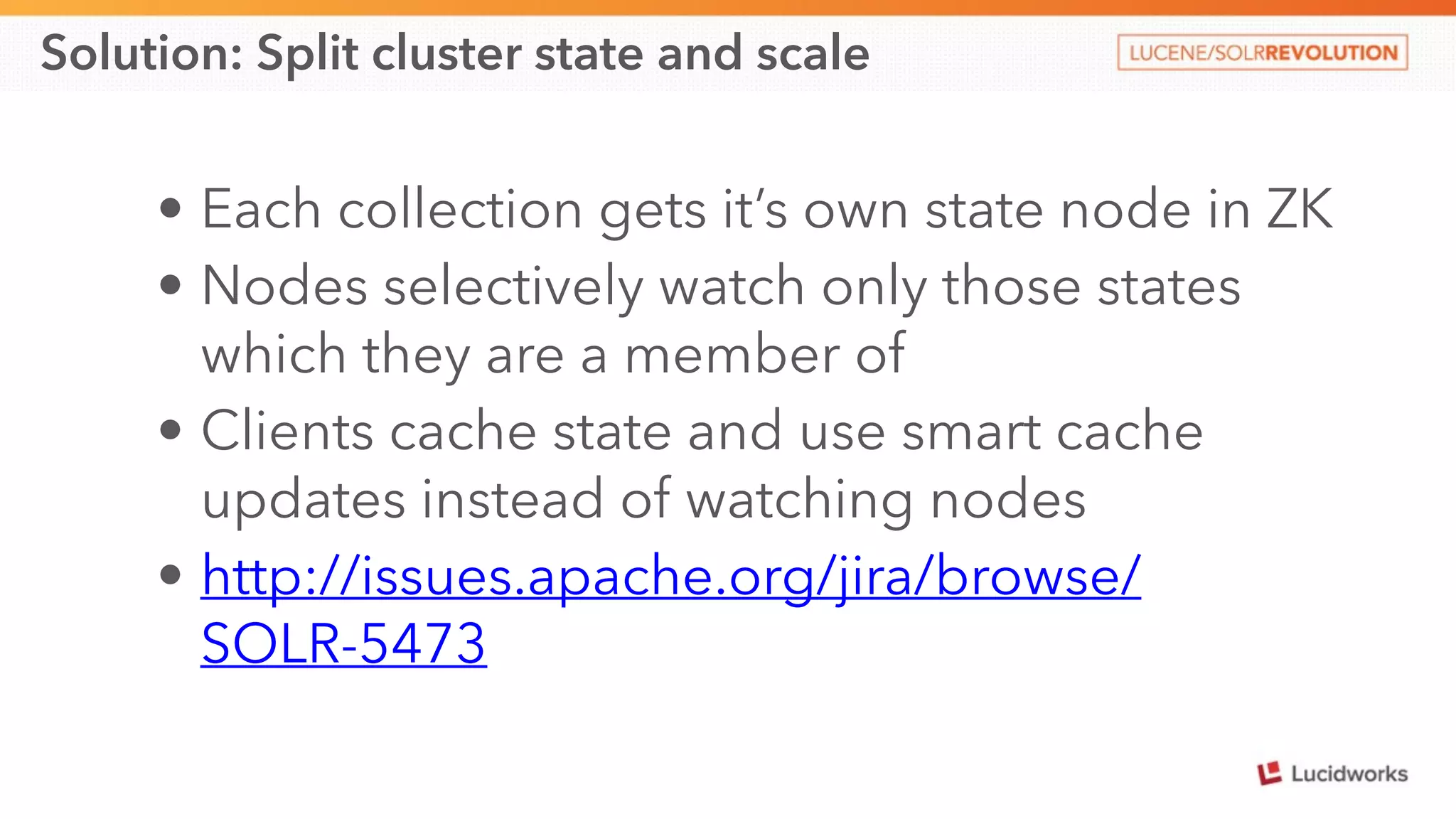





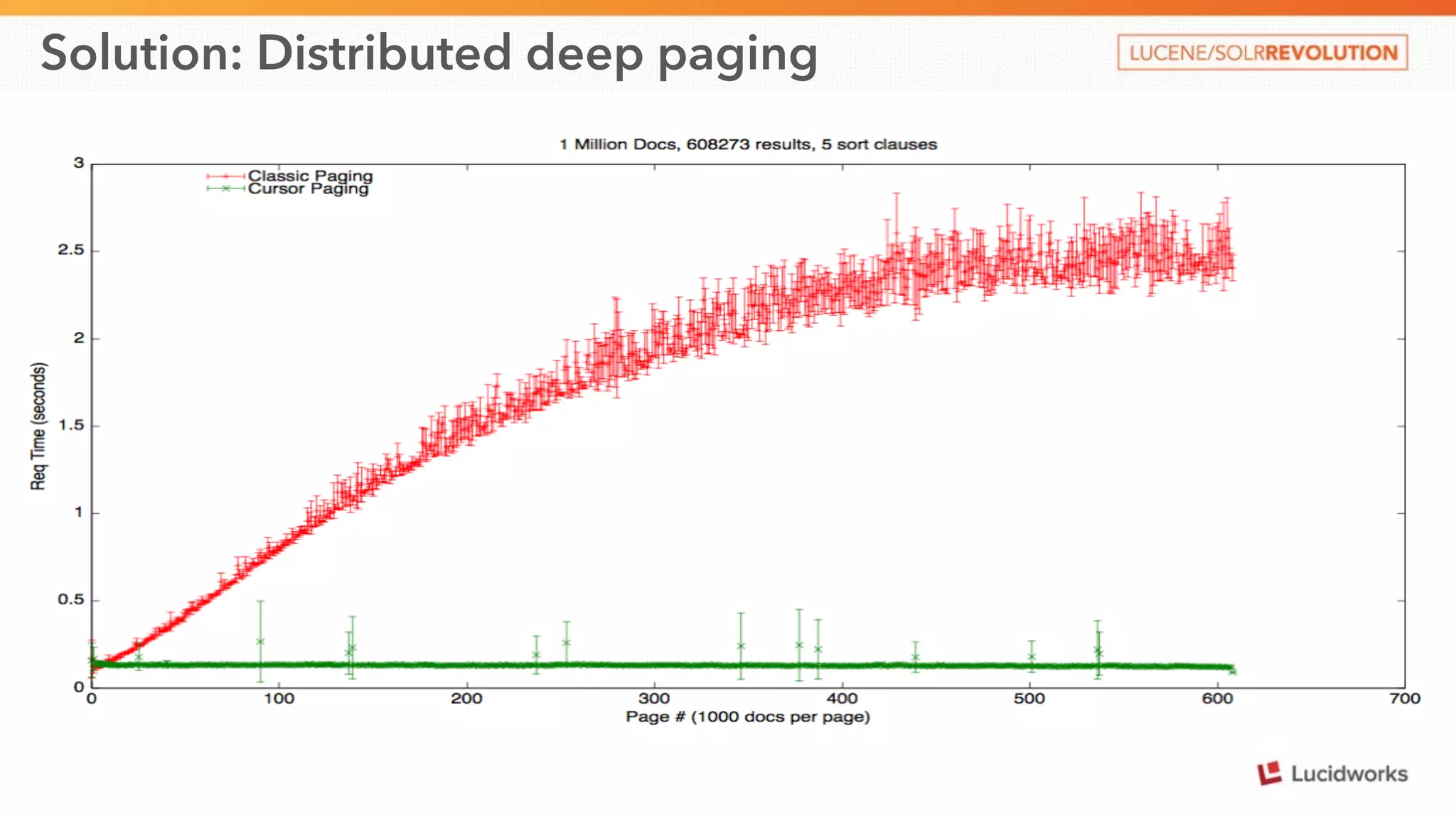

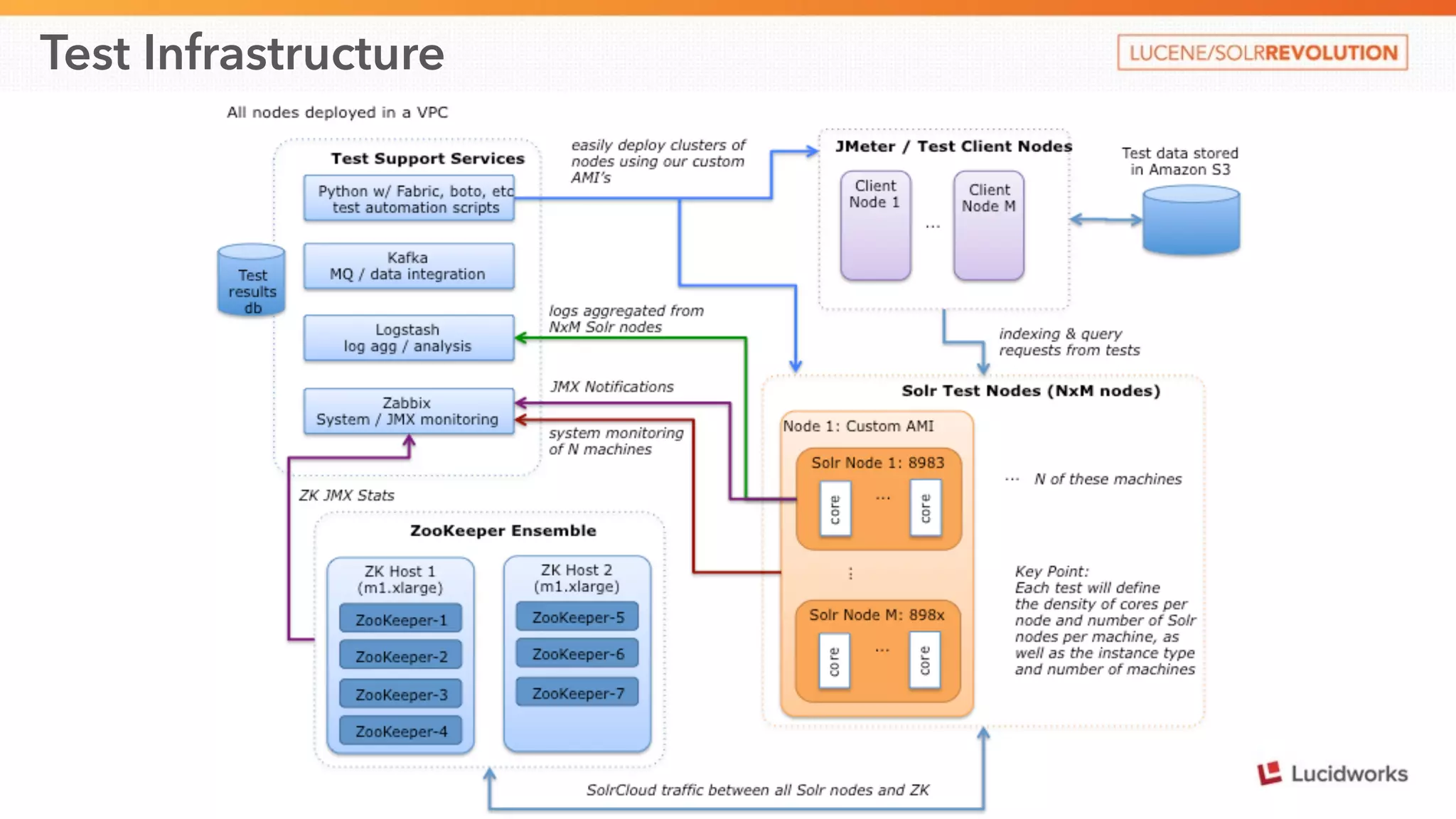
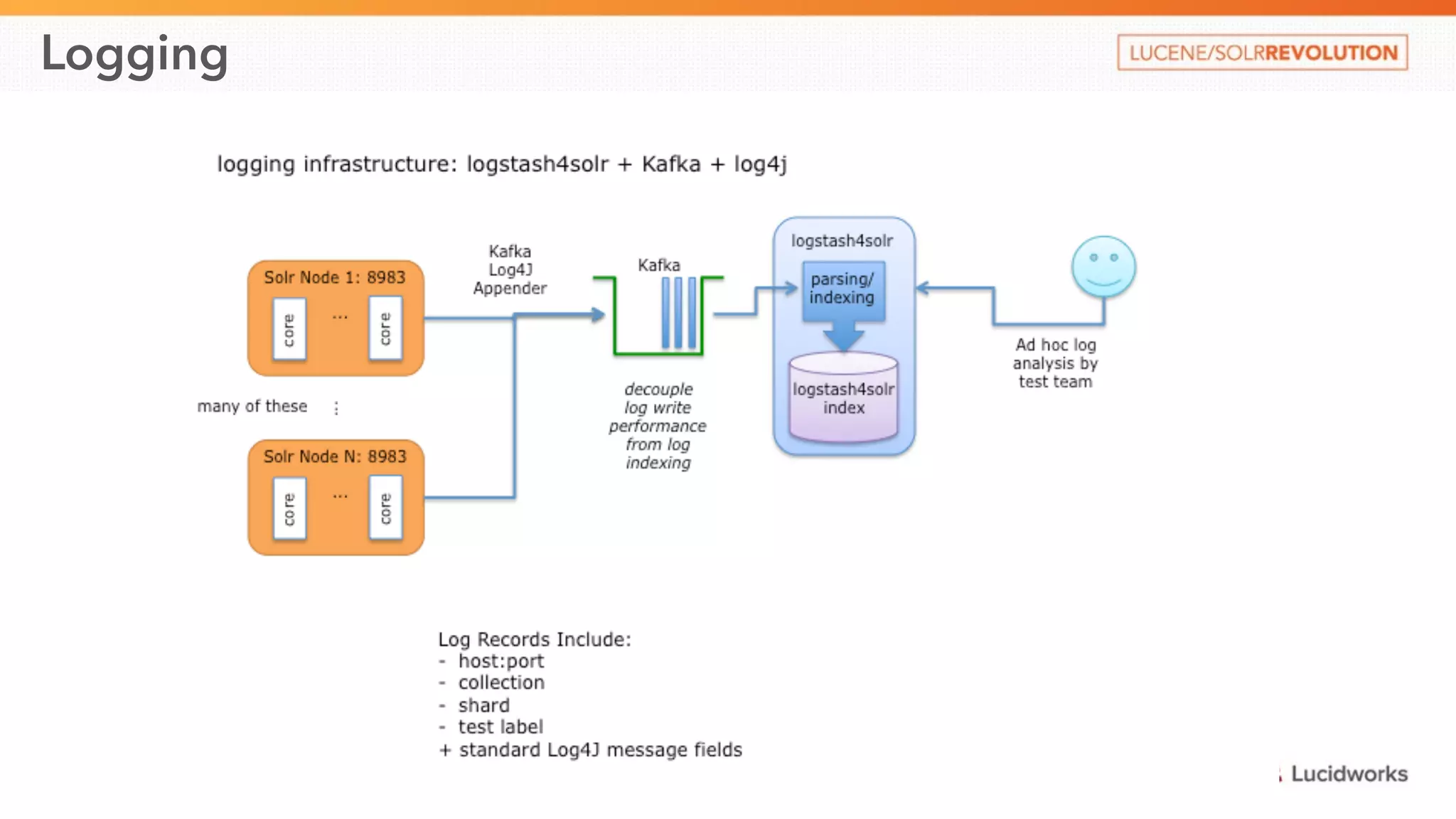
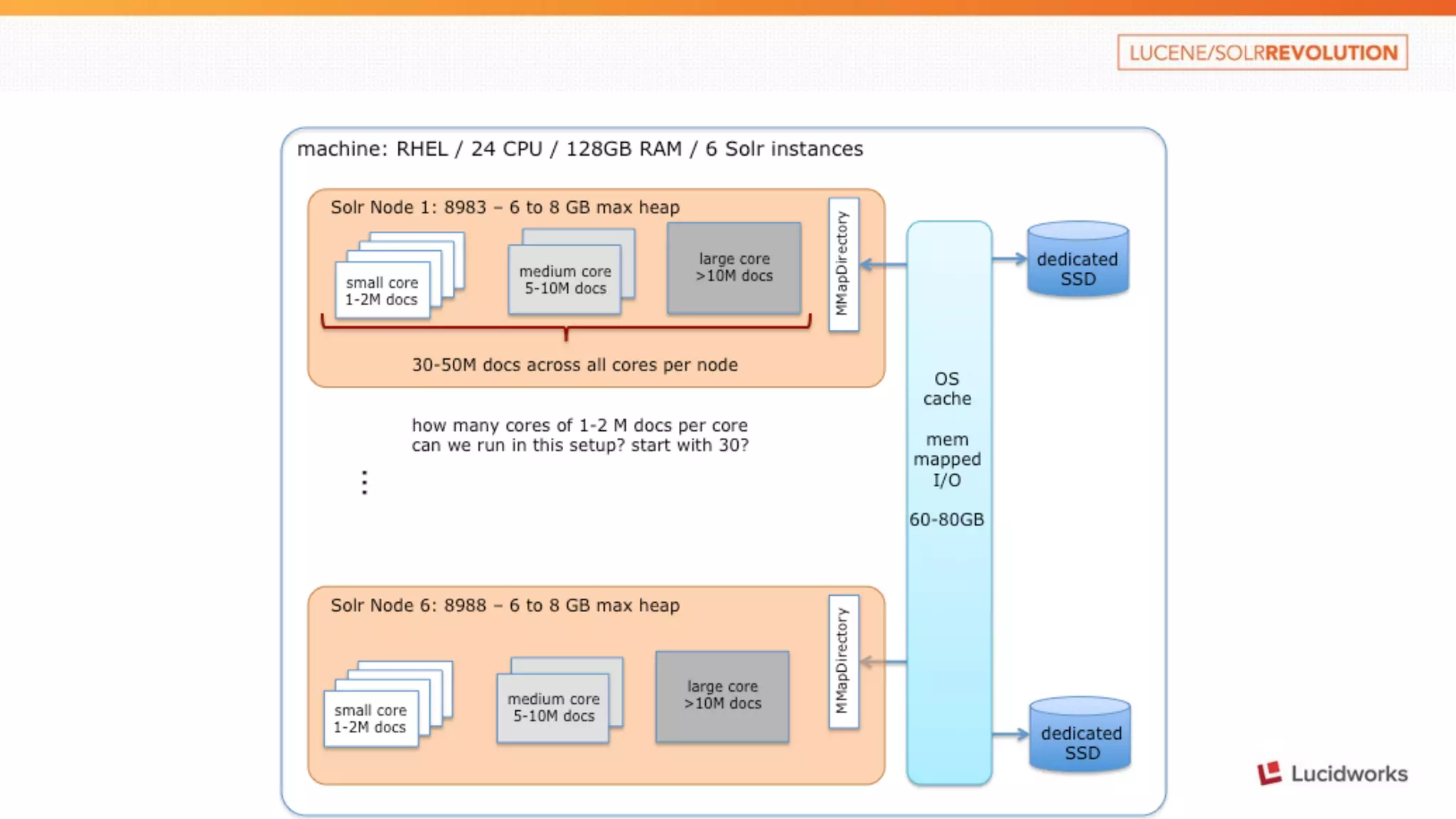




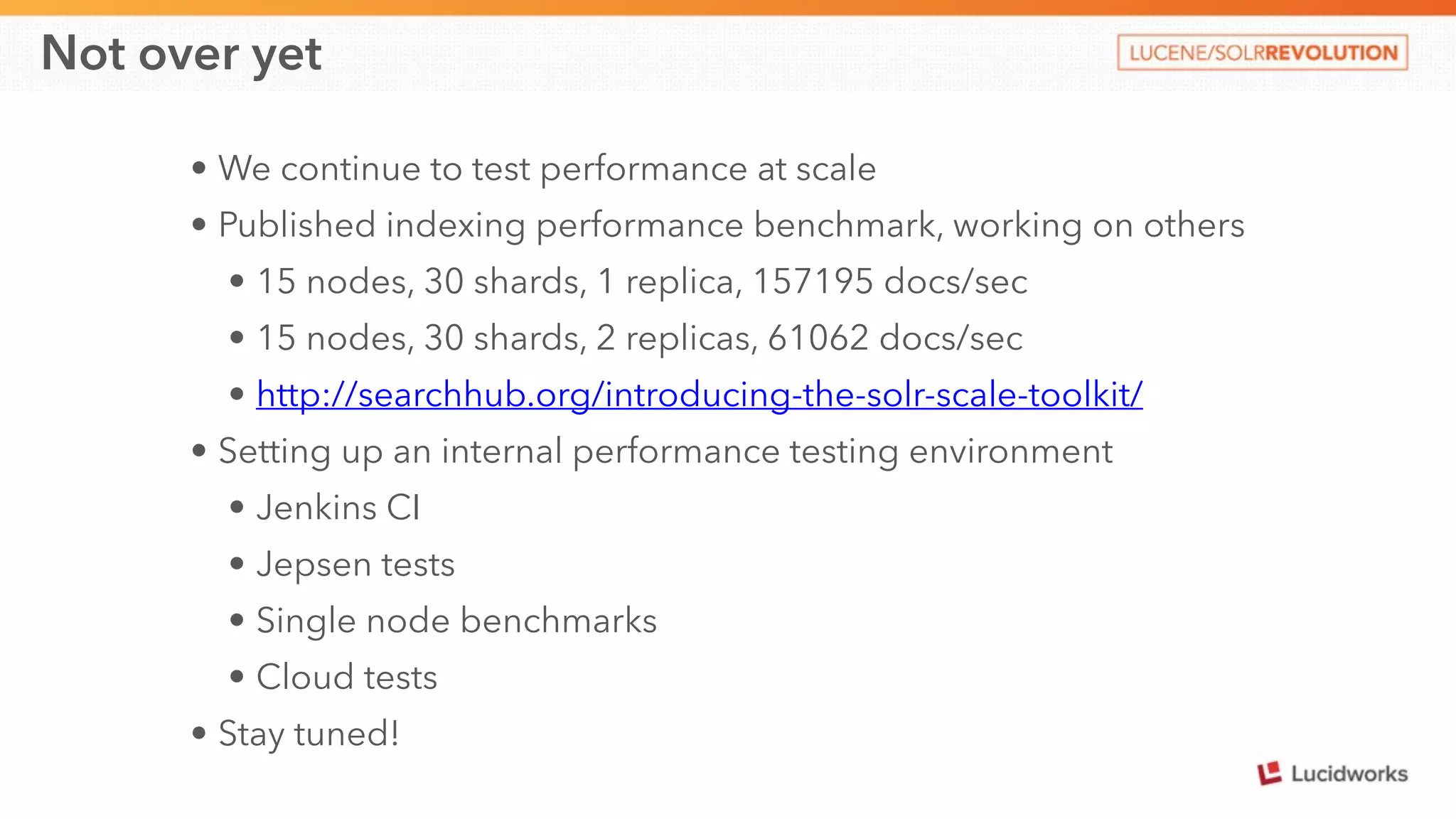
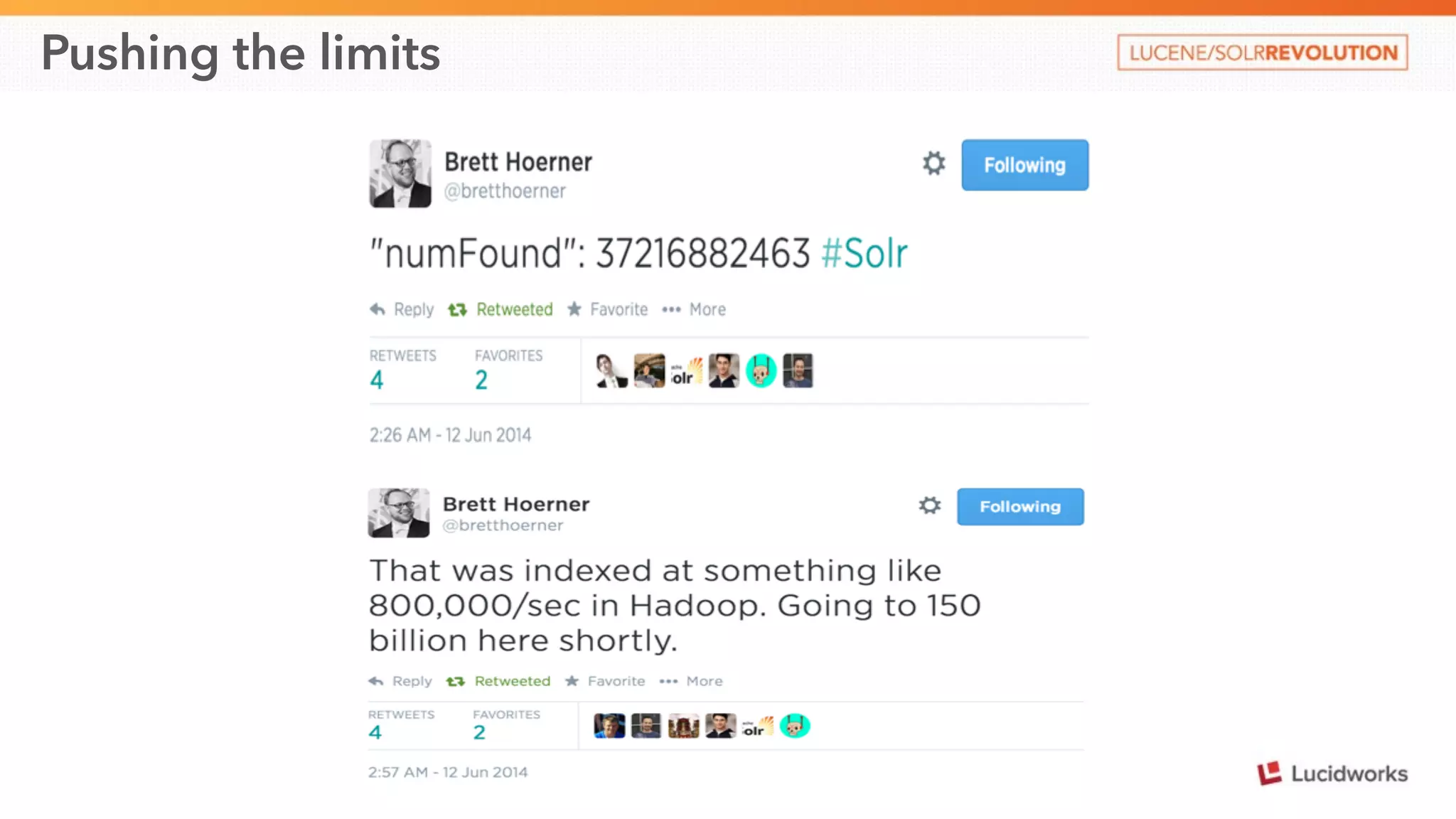



This document discusses scaling SolrCloud to support a large number of collections. It identifies four main problems in scaling: 1) large cluster state size, 2) overseer performance issues with thousands of collections, 3) difficulty moving data between collections, and 4) limitations in exporting full result sets. The document outlines solutions implemented to each problem, including splitting the cluster state, optimizing the overseer, improving data management between collections, and enabling distributed deep paging to export full result sets. Testing showed the ability to support 30 hosts, 120 nodes, 1000 collections, over 6 billion documents, and sustained performance targets.



















































![[Hic2011] using hadoop lucene-solr-for-large-scale-search by systex](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011usinghadoop-lucene-solr-for-large-scale-searchbysystex-111205021544-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)

































