Downloaded 429 times


















![Index XML documentsUse the command line tool for POSTing raw XML to a SolrOther options:-Ddata=[files|args|stdin]-Durl=http://localhost:8983/solr/update-Dcommit=yes(Option default values are in red)Example:java -jar post.jar *.xmljava -Ddata=args -jar post.jar "<delete><id>42</id></delete>"java -Ddata=stdin -jar post.jarjava -Dcommit=no -Ddata=args-jar post.jar "<delete><query>*:*</query></delete>"Confidential21](https://image.slidesharecdn.com/apachesolr-13106095364892-phpapp01-110713215051-phpapp01/75/Apache-Solr-21-2048.jpg)





![Default Query SyntaxLucene Query Syntax [; sort specification]mission impossible; releaseDatedesc+mission +impossible –actor:cruise“mission impossible” –actor:cruisetitle:spiderman^10 description:spidermandescription:“spiderman movie”~10+HDTV +weight:[0 TO 100]Wildcard queries: te?t, te*t, test*Confidential27](https://image.slidesharecdn.com/apachesolr-13106095364892-phpapp01-110713215051-phpapp01/75/Apache-Solr-27-2048.jpg)





![Faceted Browsing34computer_type:PCproc_manu:Intel= 594memory:[1GB TO *]proc_manu:AMDintersection Size()= 382computerprice ascSearch(Query,Filter[],Sort,offset,n)price:[0 TO 500]= 247price:[500 TO 1000]section of ordered results= 689Unordered set of all resultsmanu:Dell= 104DocListDocSetmanu:HP= 92manu:Lenovo= 75Query Response](https://image.slidesharecdn.com/apachesolr-13106095364892-phpapp01-110713215051-phpapp01/75/Apache-Solr-34-2048.jpg)








Solr is an open source enterprise search platform that provides powerful full-text search, hit highlighting, faceted search, database integration, and document handling capabilities. It uses Apache Lucene under the hood for indexing and search, and provides REST-like APIs, a web admin interface, and SolrJ for indexing and querying. Solr allows adding, deleting, and updating documents in its index via HTTP requests and can index documents in various formats including XML, CSV, and rich documents using Apache Tika. It provides distributed search capabilities and can be configured for high availability and scalability.
Introduction to the presentation on enterprise search utilizing Solr, showcasing speaker Minh Tran.
Discusses the evolution of user search behavior, emphasizing the shift from traditional navigation to search boxes.
Introduces Solr as an open-source search platform based on Apache Lucene, detailing its features like full-text search, APIs, and document handling.
Highlights major public websites using Solr such as Digg, CNet, Zappos, and Netflix to showcase its effectiveness.
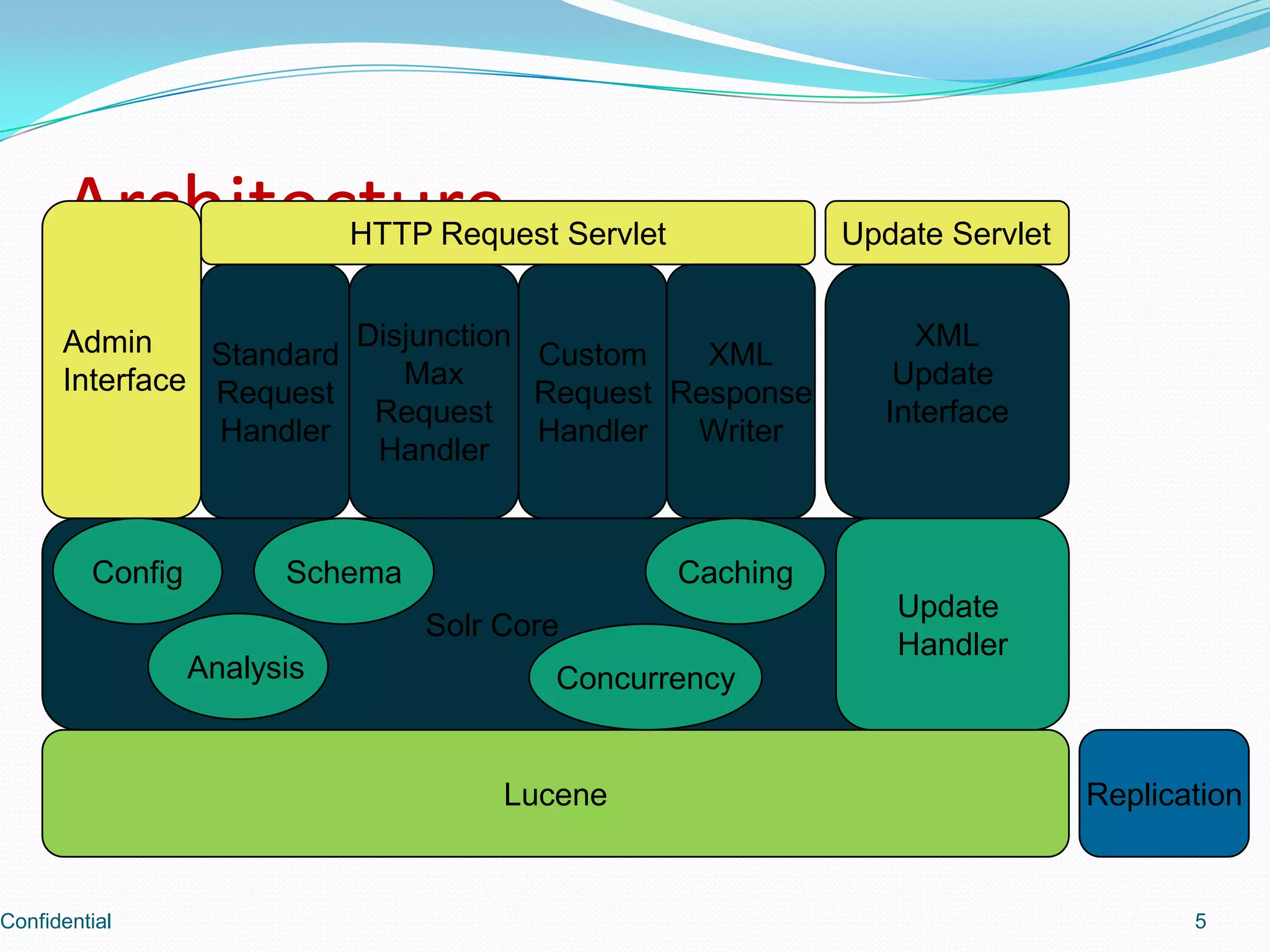
Describes Solr's architecture, including components like the admin interface, request handlers, and core functionalities.
Details on starting Solr including necessary configurations for solr.home and solr.data.dir.
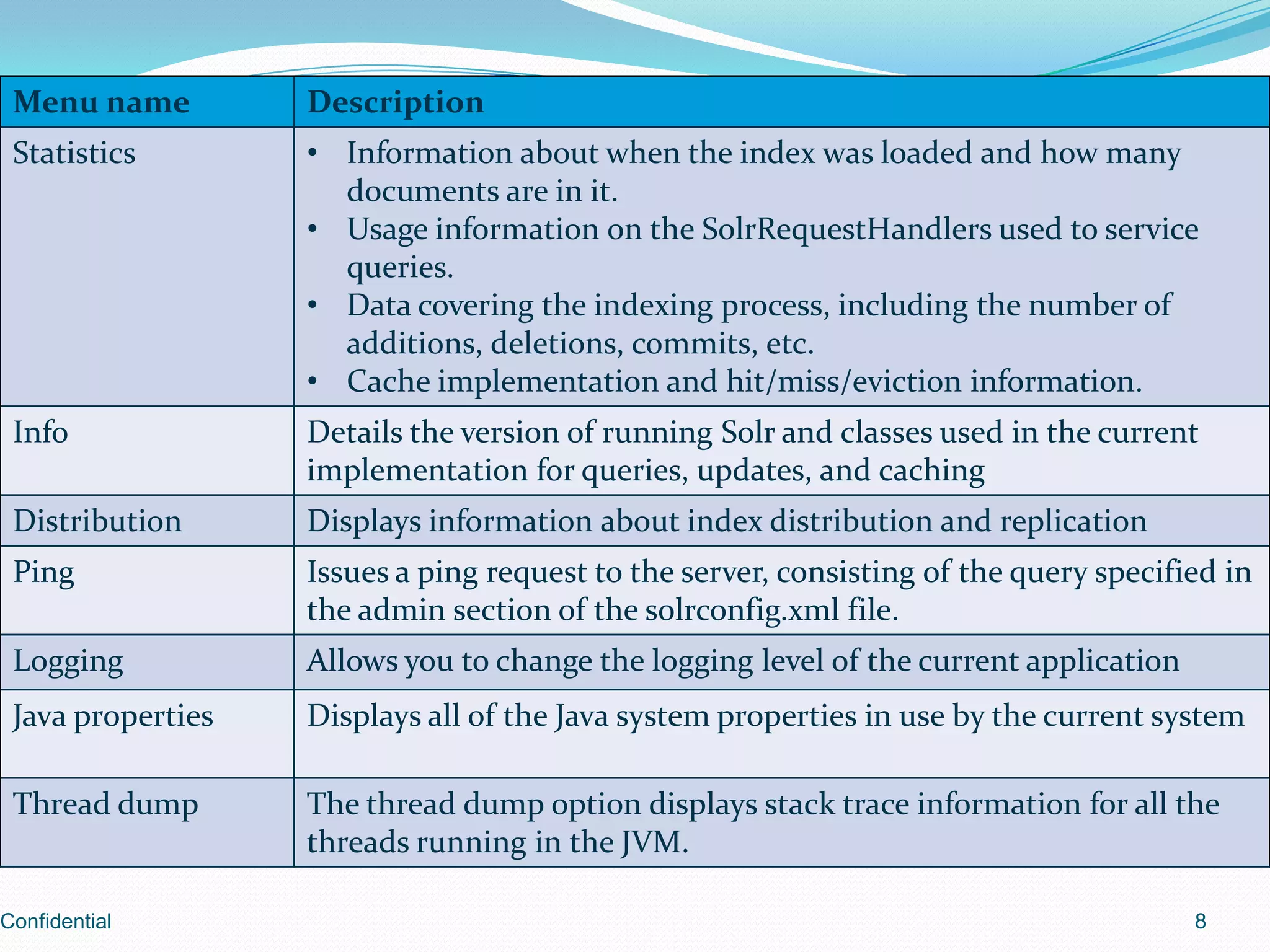
Introduction to the web admin interface of Solr.
Explains how Solr constructs an index using documents and fields, including data handling metadata.
Discusses field analyzers used during document indexing and querying, including tokenization examples.
Overview of schema.xml configuration in Solr outlining key sections like Types and Fields.
Examples of how to define a TextField type in Solr's schema.
Explains various filter factories for token manipulation such as StopFilter, WordDelimiterFilter, and stemming examples.
Describes field attributes in Solr including indexed and stored fields along with their functionalities.
Discusses how to define field attributes and dynamic fields in Solr schema.
Explains unique field declaration in schema and the concept of the default search field.
Shows various data formats available for interaction with Solr, including XML, CSV, and JSON.
Details HTTP POST structure to add or update documents within Solr, with XML structure examples.
Instructions for deleting documents in Solr by ID and by query string.
Describes the importance of committing and optimizing index for performance improvement.
Methods to POST raw XML data to Solr for indexing.
Demonstrates how to index CSV files using HTTP POST commands.
Describes the remote streaming method of indexing CSV files and related configurations.
Explains how Solr uses Apache Tika to index rich document formats such as PDFs and HTML.
Details the configuration required to update Solr index using JSON format.
Overview of search capabilities, including spellcheck and scaling with distributed search.
Demonstrates the default query syntax used for making searches within Solr.
Outlines query arguments for HTTP requests when interacting with Solr's /select endpoint.
Shows the structure of a sample search result response from Solr.
Explains how query responses are formatted using different writers and how to specify them.
Details the aggressive caching strategies Solr employs for query consistency and speed.
Explains how to set up field types and analyzers to improve search relevancy.
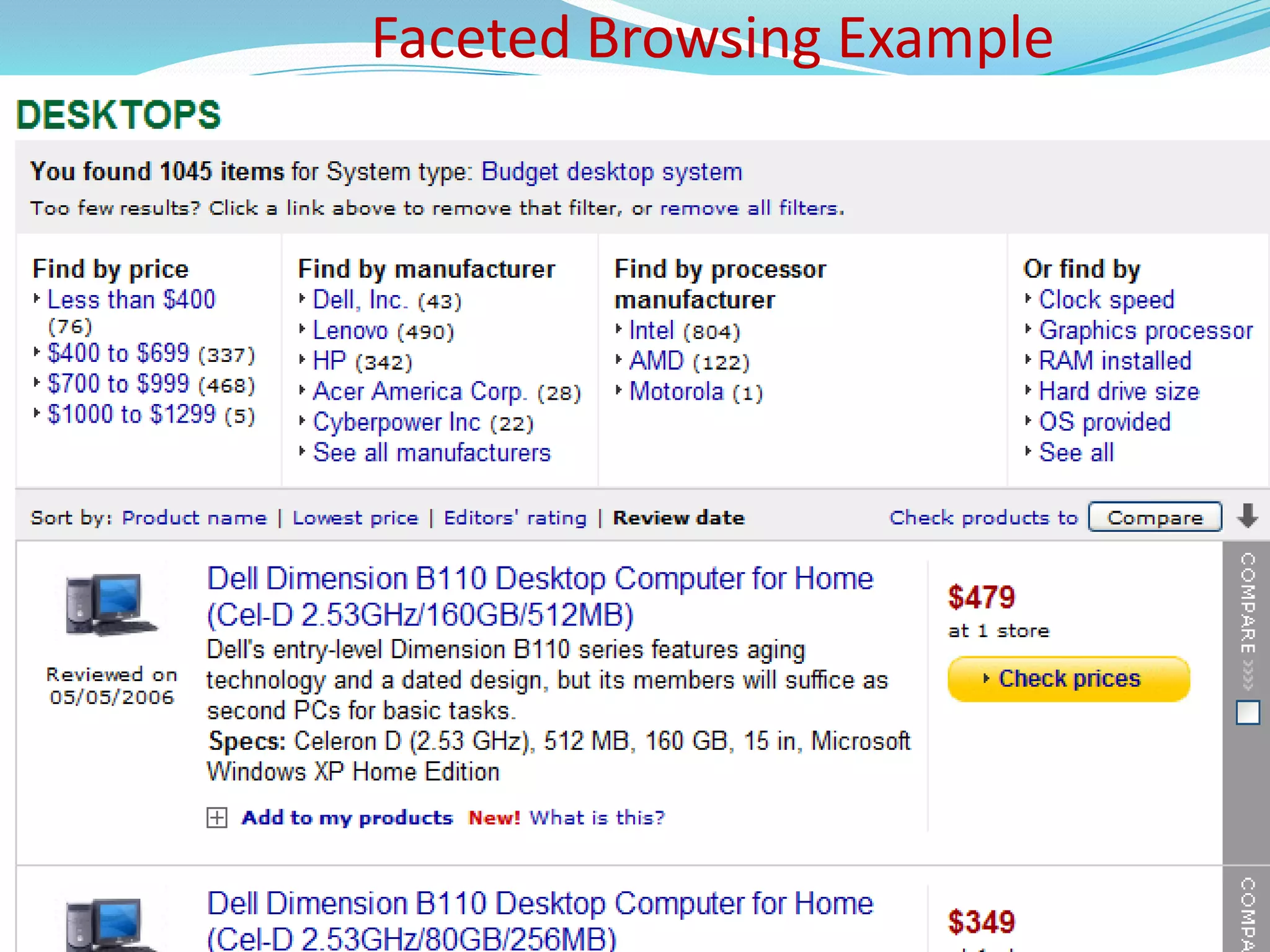
Introduction to faceted browsing and its implications for user search experiences.
Demonstrates complex faceted search queries and their impact on results.
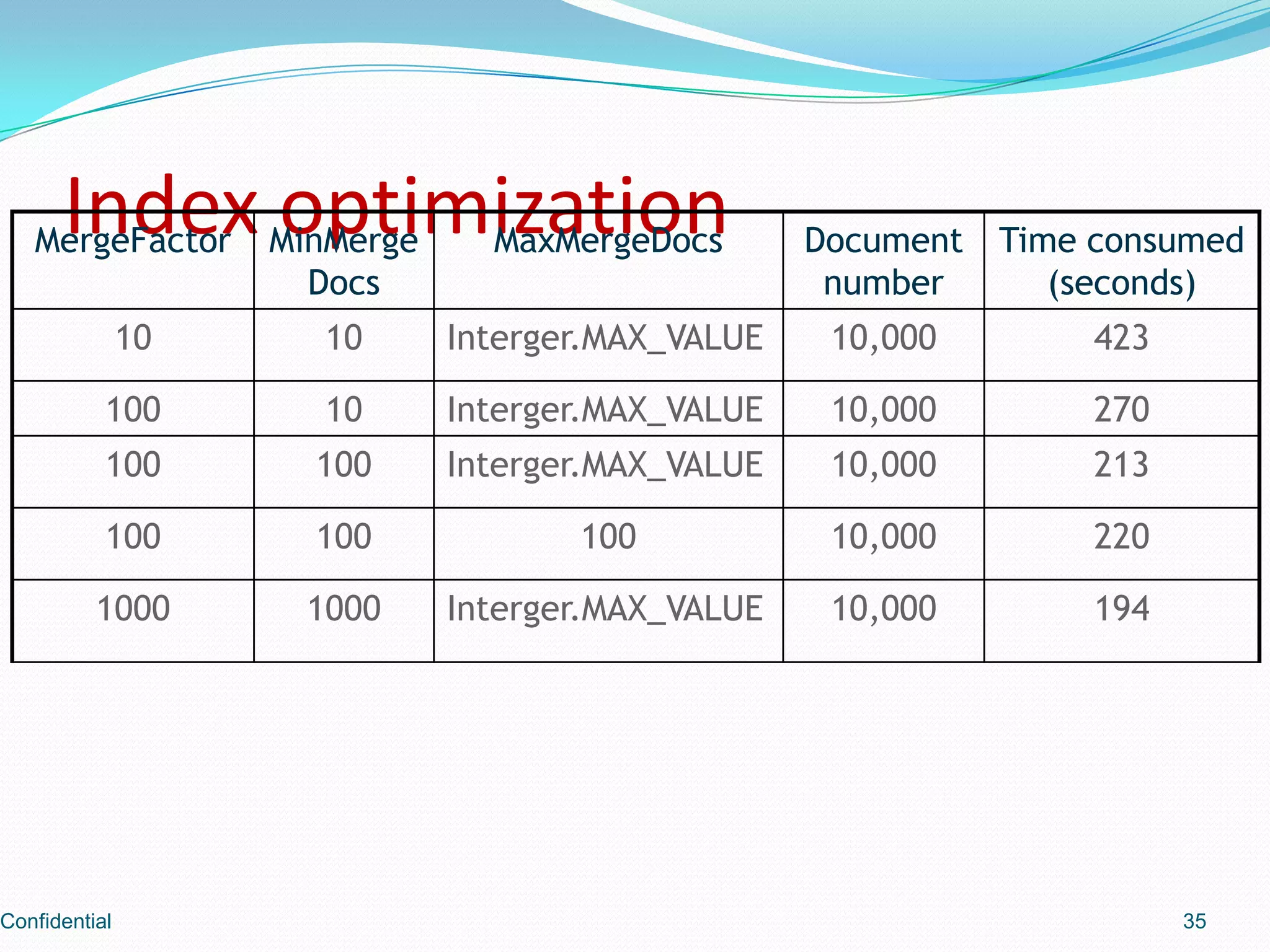
Overview of optimization methods and their importance for efficient indexing.
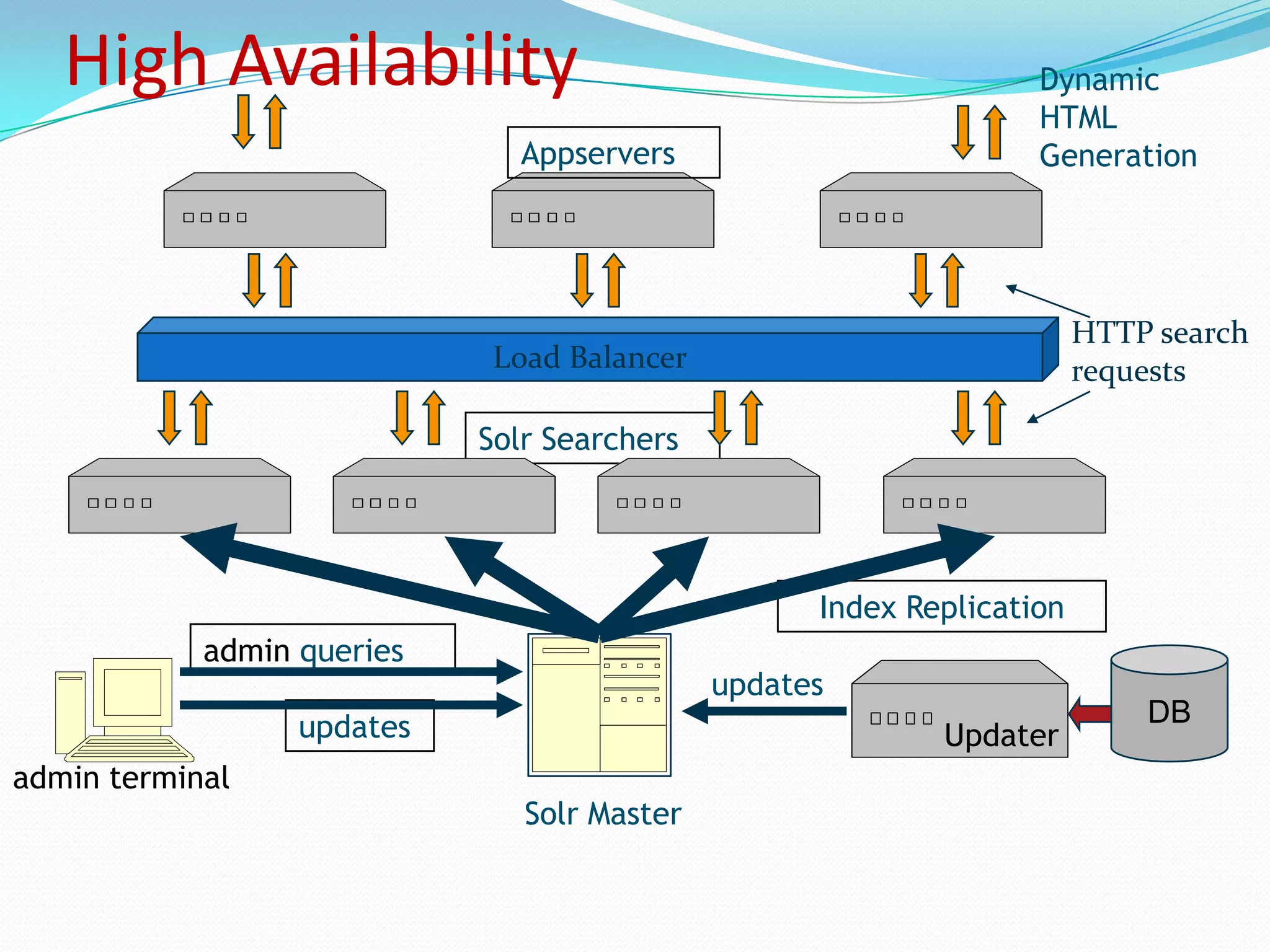
Discusses Solr’s architecture supporting high availability through load balancing and replication.
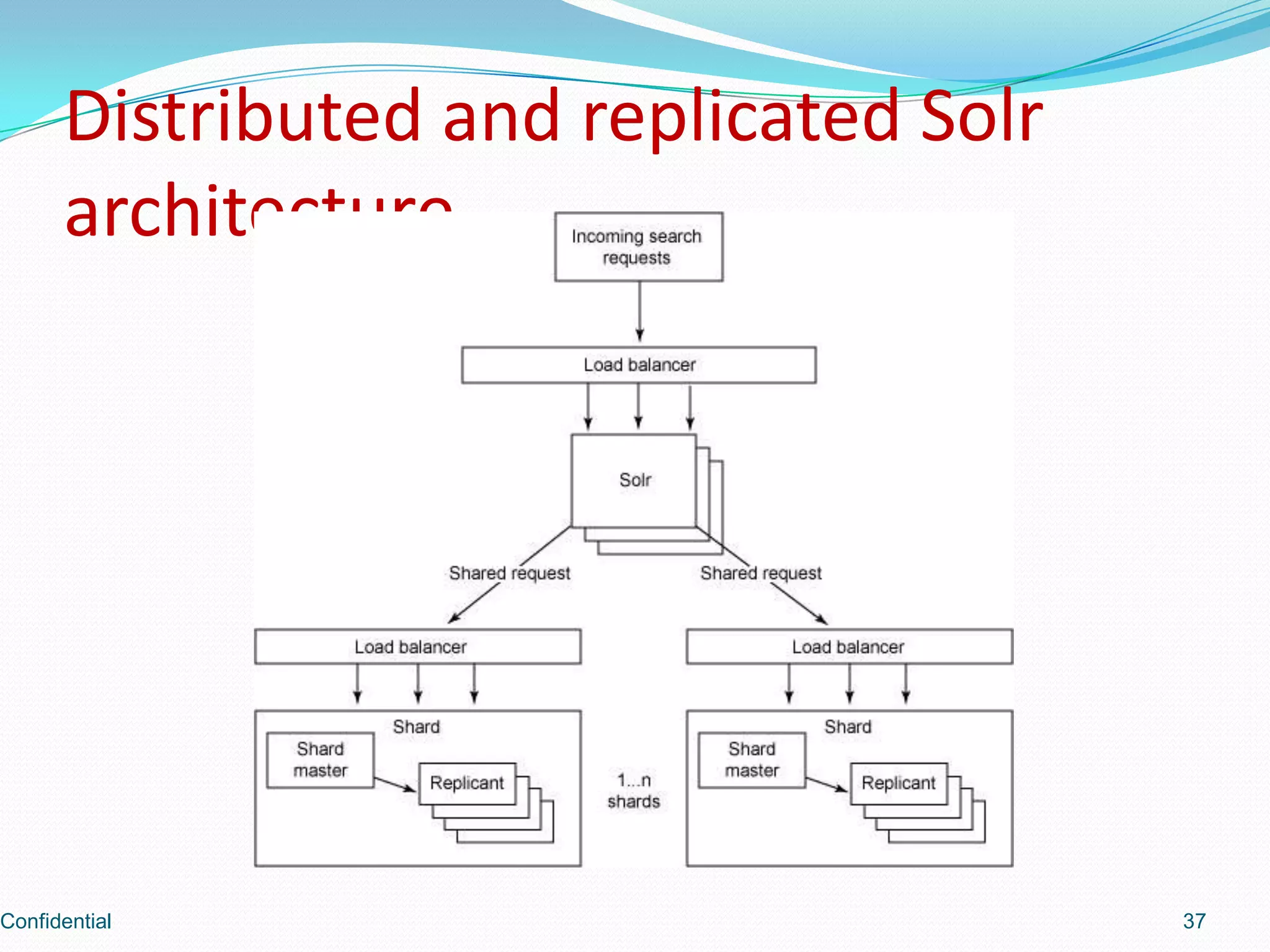
Insights into the distributed architecture for Solr with a focus on replication.
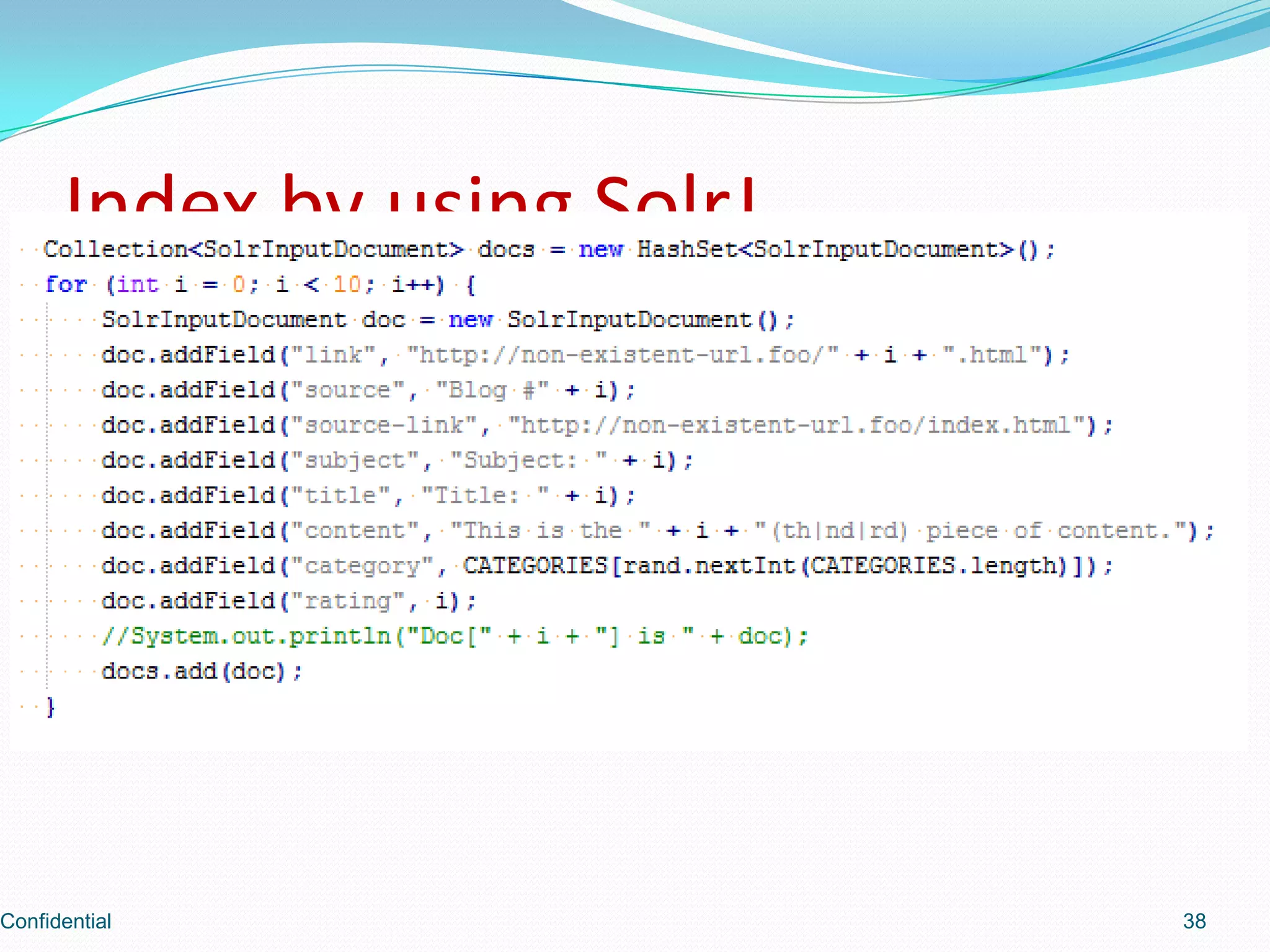
Shows how to index data using SolrJ, a Java client for Solr.
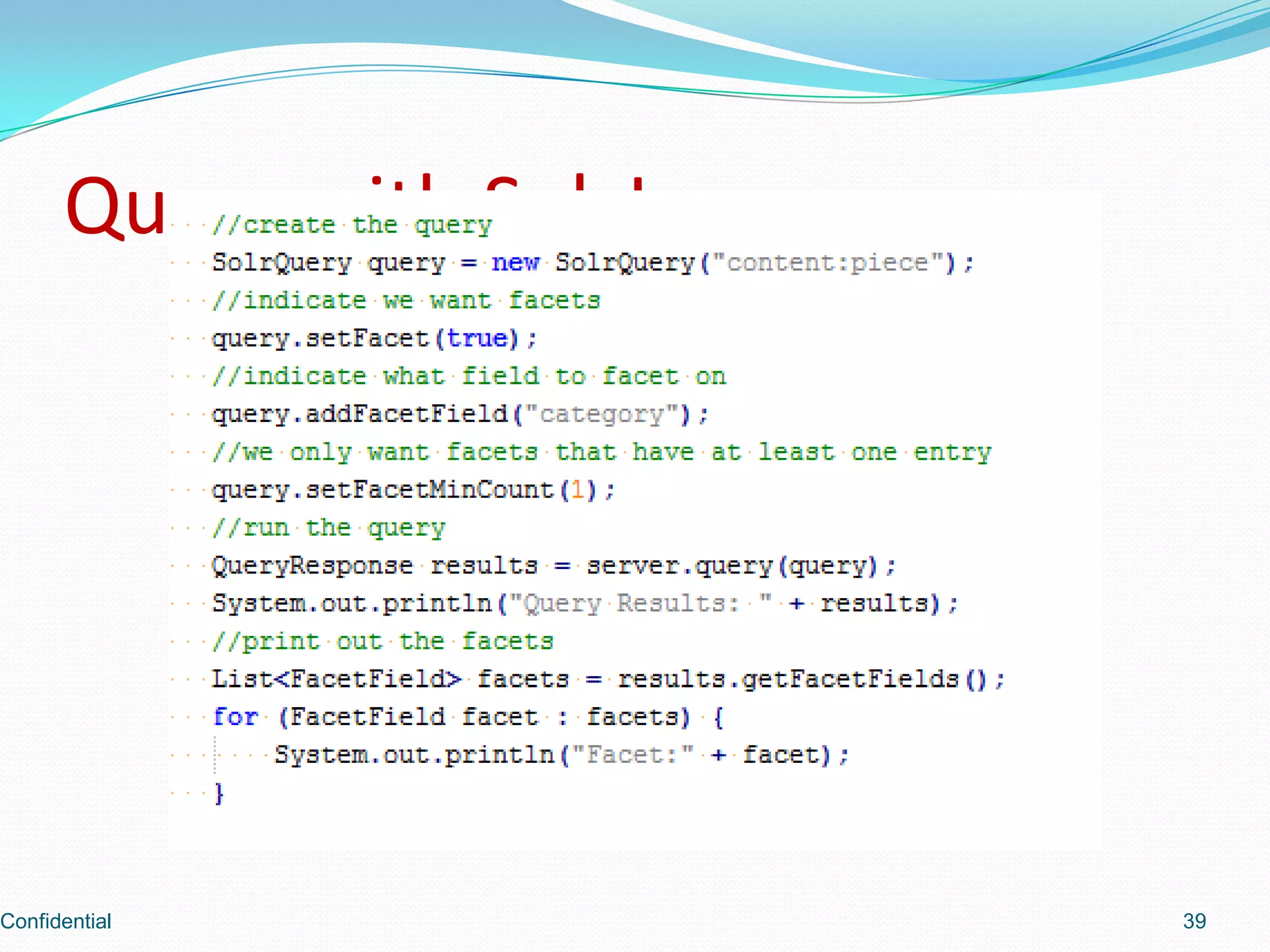
Demonstrates how to perform queries using SolrJ.
Discusses machine capabilities for indexing in a distributed setting including capacity limits.
Explores advanced functionalities like data import handlers and support for various programming languages.
Mentions other open source search servers like Sphinx and Elastic Search as alternatives to Solr.
Provides links to resources and documentation for further learning about Solr.
Continues with more resources and information about Solr and its capabilities.
Sections marked confidential, presumably containing sensitive or proprietary information.



































































