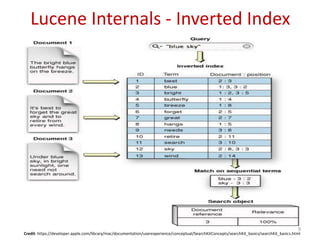
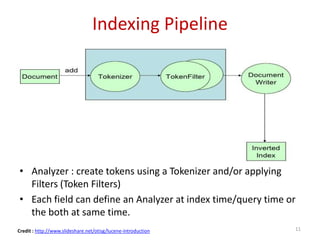
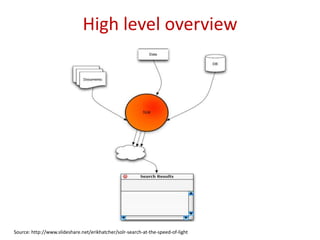
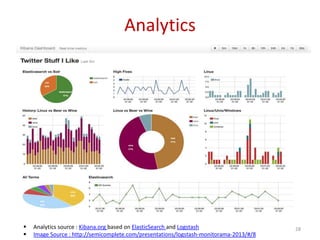
Downloaded 270 times









![Analysis Process - Tokenizer
WhitespaceAnalyzer
Simplest built-in analyzer
The quick brown fox jumps over the lazy dog.
[The] [quick] [brown] [fox] [jumps] [over] [the] [lazy] [dog.]
Tokens](https://image.slidesharecdn.com/introductiontoapachelucenesolr-140412130758-phpapp02/85/Introduction-to-Apache-Lucene-Solr-12-320.jpg)
![Analysis Process - Tokenizer
SimpleAnalyzer
Lowercases, split at non-letter boundaries
The quick brown fox jumps over the lazy dog.
[the] [quick] [brown] [fox] [jumps] [over] [the] [lazy] [dog]
Tokens](https://image.slidesharecdn.com/introductiontoapachelucenesolr-140412130758-phpapp02/85/Introduction-to-Apache-Lucene-Solr-13-320.jpg)








![Query Types
• Single and multi term queries
• ex fieldname:value or title: software engineer
• +, -, AND, OR NOT operators.
• ex. title: (software AND engineer)
• Range queries on date or numeric fields,
• ex: timestamp: [ * TO NOW ] or price: [ 1 TO 100 ]
• Boost queries:
• e.g. title:Engineer ^1.5 OR text:Engineer
• Fuzzy search : is a search for words that are similar in
spelling
• e.g. roam~0.8 => noam
• Proximity Search : with a sloppy phrase query. The
close together the two terms appear, higher the score.
• ex “apache lucene”~20 : will look for all documents where
“apache” word occurs within 20 words of “lucene”
23](https://image.slidesharecdn.com/introductiontoapachelucenesolr-140412130758-phpapp02/85/Introduction-to-Apache-Lucene-Solr-23-320.jpg)



![Faceting
Source: www.career9.com, www.indeed.com 27
• Grouping results based on field
value
• Facet on: field
terms, queries, date ranges
• &facet=on
&facet.field=job_title
&facet.query=salary:[30000 TO
100000]
• http://wiki.apache.org/solr/Sim
pleFacetParameters](https://image.slidesharecdn.com/introductiontoapachelucenesolr-140412130758-phpapp02/85/Introduction-to-Apache-Lucene-Solr-27-320.jpg)



This document provides an introduction to Apache Lucene and Solr. It begins with an overview of information retrieval and some basic concepts like term frequency-inverse document frequency. It then describes Lucene as a fast, scalable search library and discusses its inverted index and indexing pipeline. Solr is introduced as an enterprise search platform built on Lucene that provides features like faceting, scalability and real-time indexing. The document concludes with examples of how Lucene and Solr are used in applications and websites for search, analytics, auto-suggestion and more.

















































































