Download as PDF, PPTX



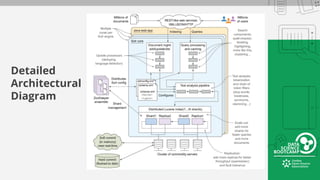
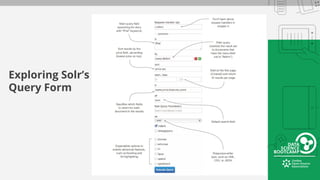
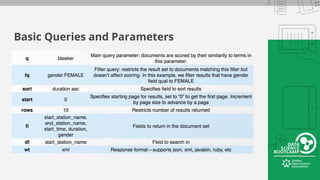
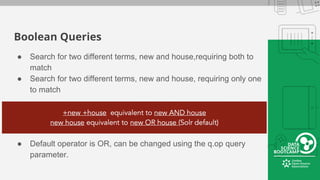
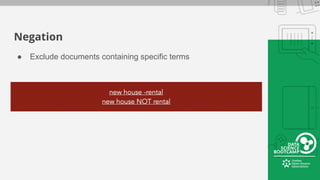

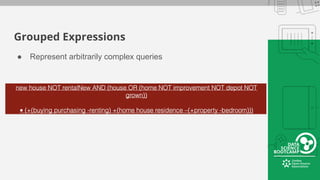
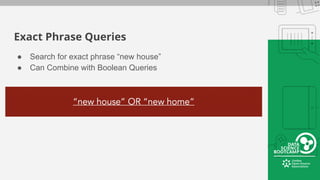
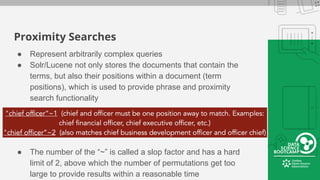

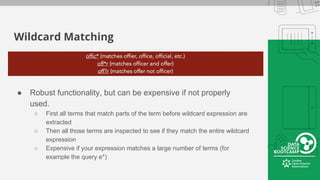
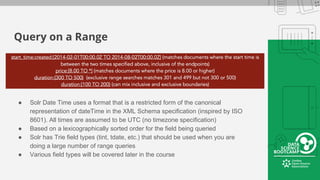
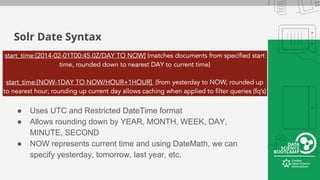



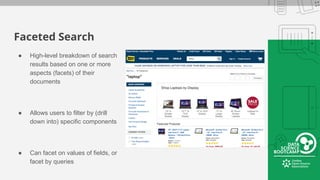
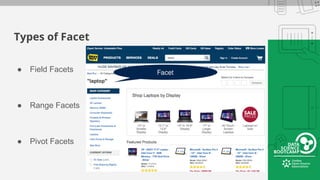

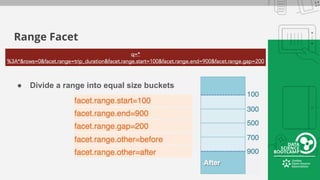
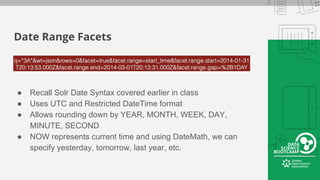
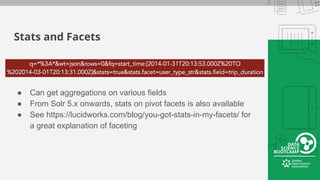
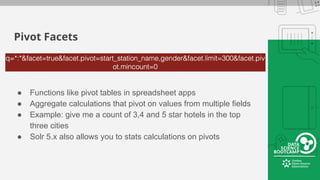
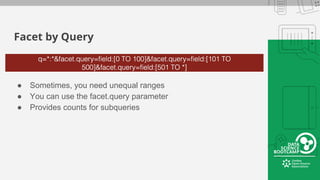
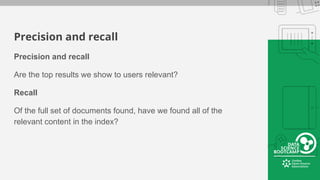



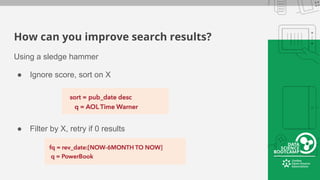
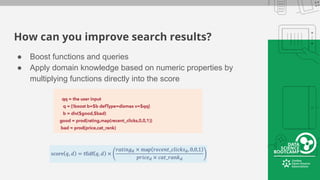


This document provides an overview of how to retrieve information from Apache Solr. It discusses various query types and parameters including basic queries, matching multiple terms, fuzzy matching, range searches, sorting, faceting, and techniques for tuning relevance. The topics are covered through examples and explanations of Solr's query syntax and how it handles indexing and searching documents.







































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



