Downloaded 91 times











![Solr JSON
POST to /update/json
[
{"id" : "TestDoc1", "title" : "test1"},
{"id" : "TestDoc2", "title" : "another test"}
]
14](https://image.slidesharecdn.com/introductiontosolr-111203091214-phpapp02/75/Introduction-to-Solr-14-2048.jpg)



















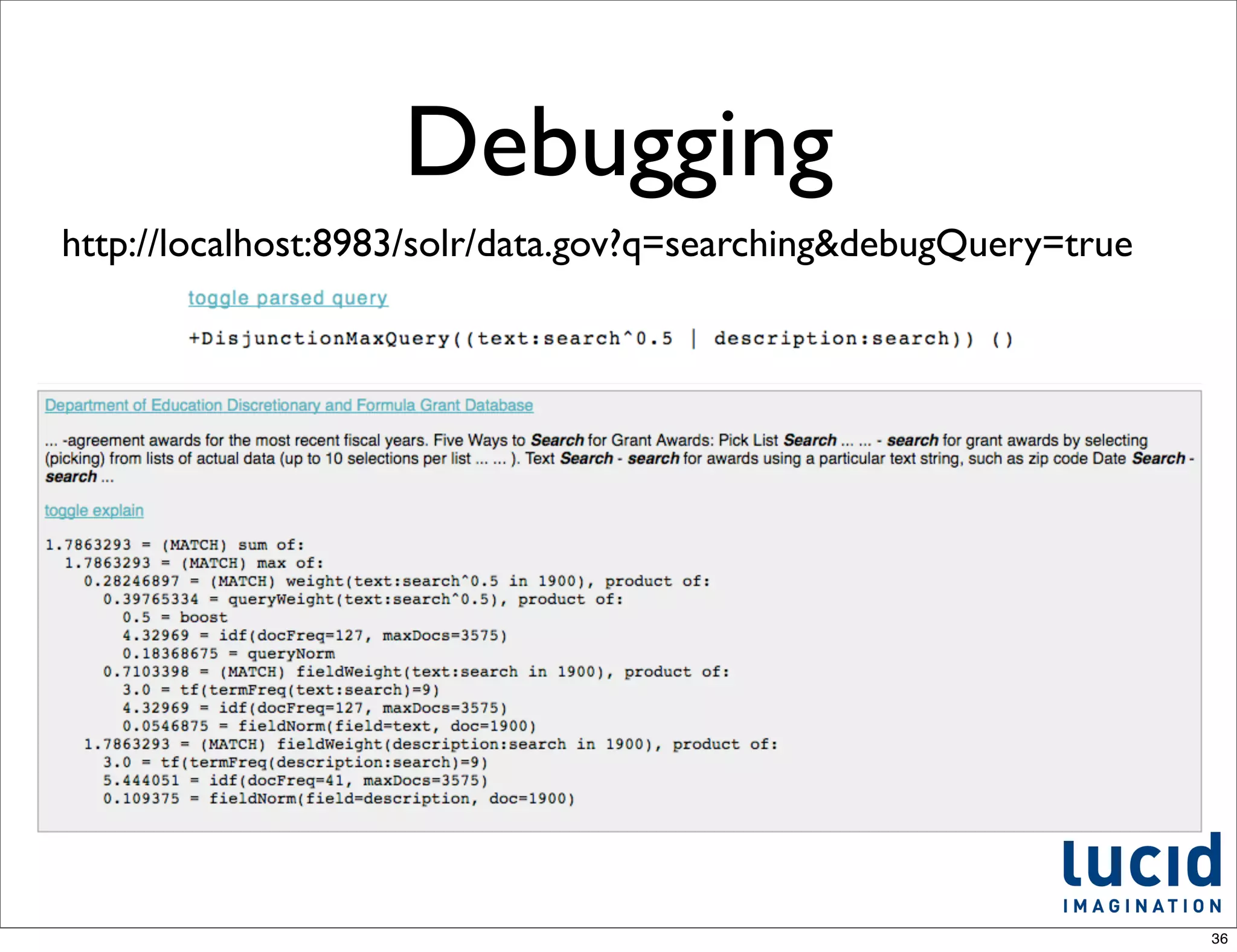

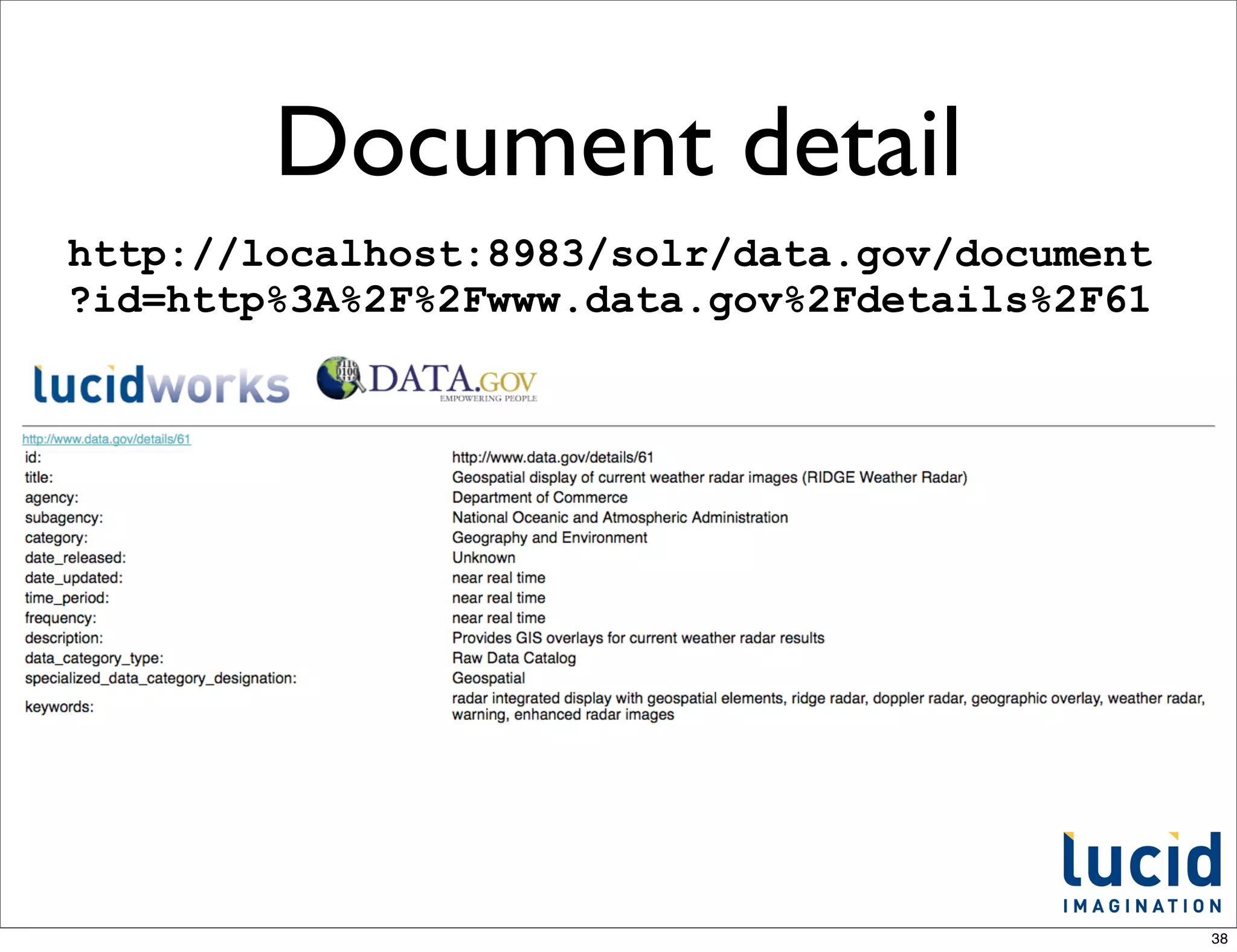

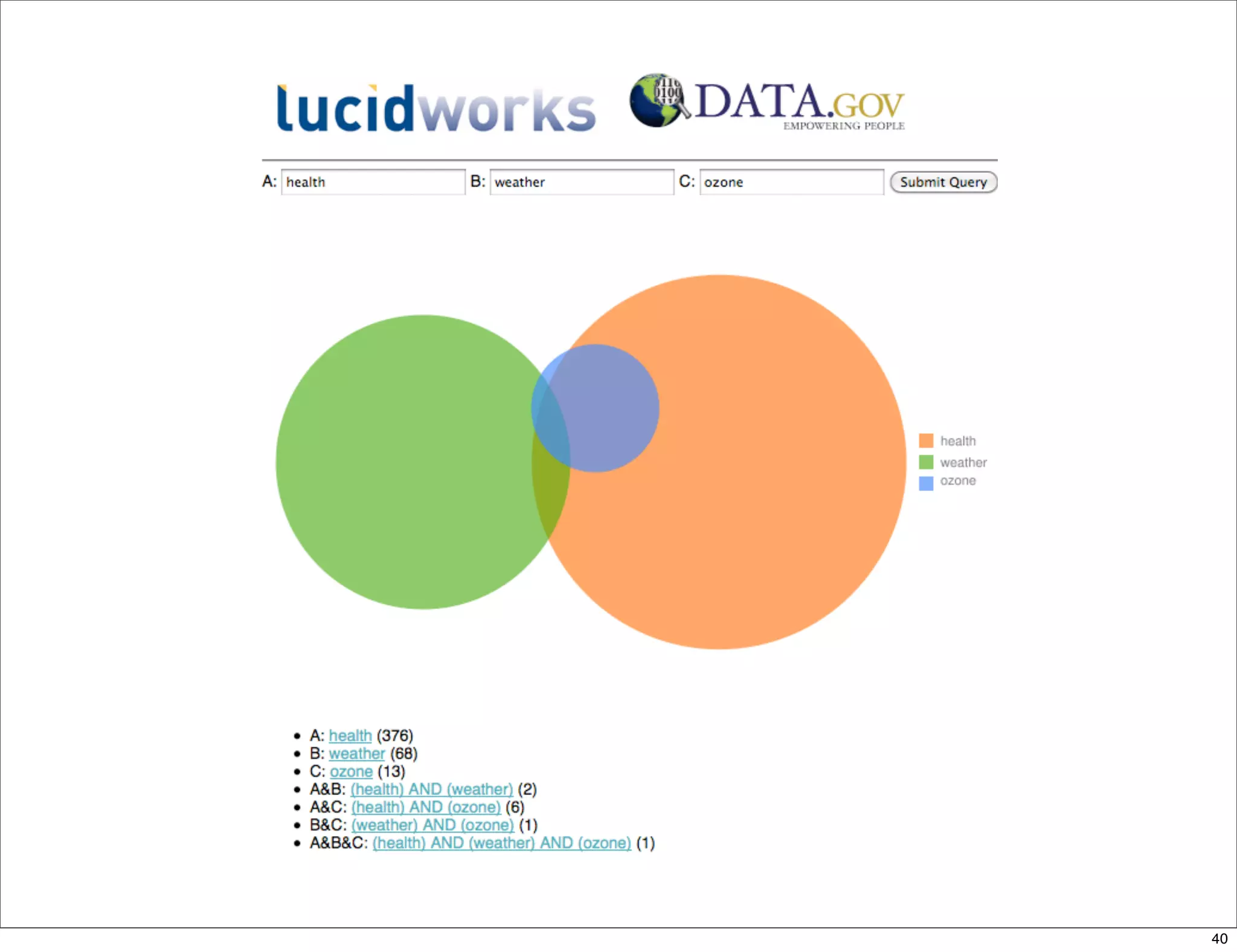


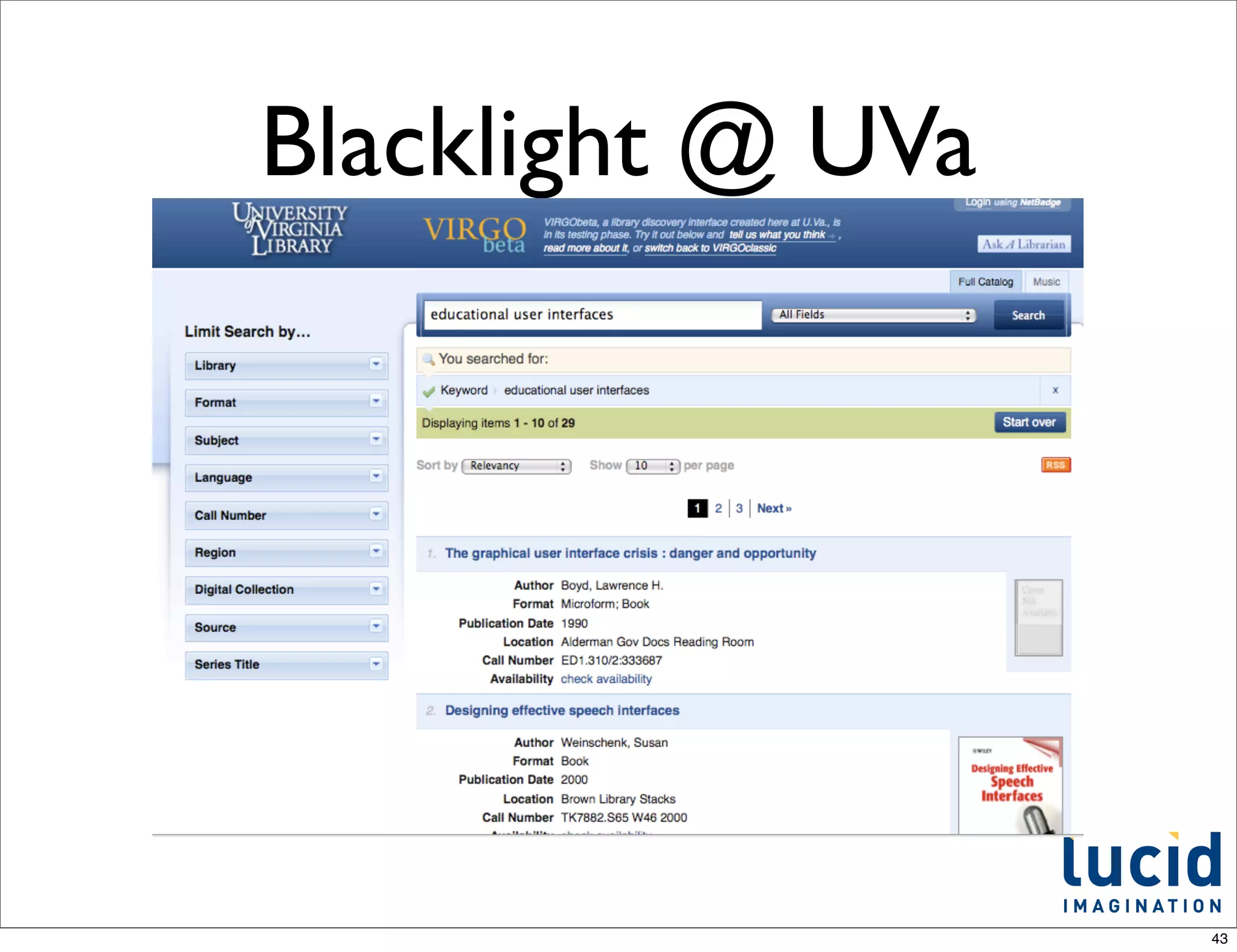
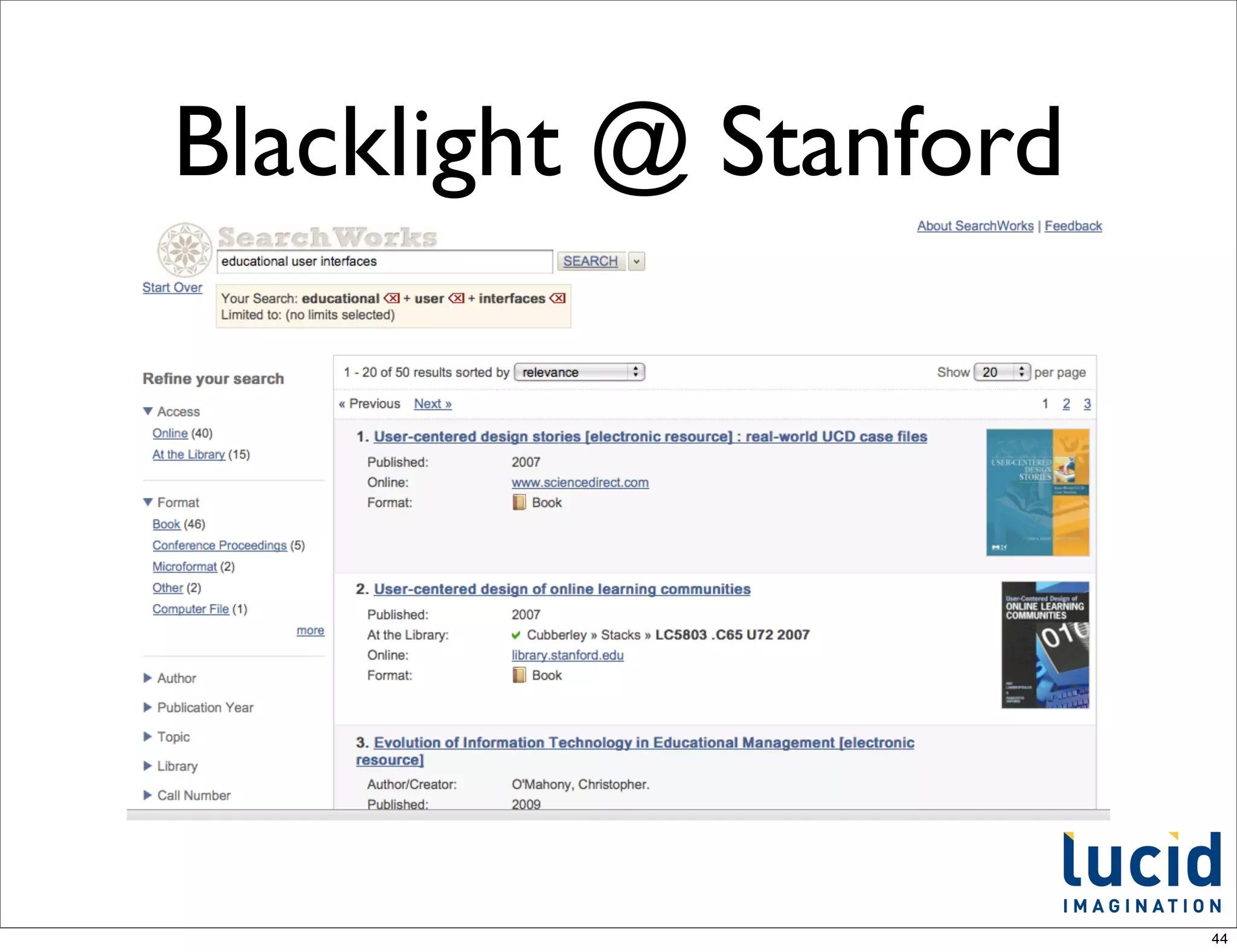

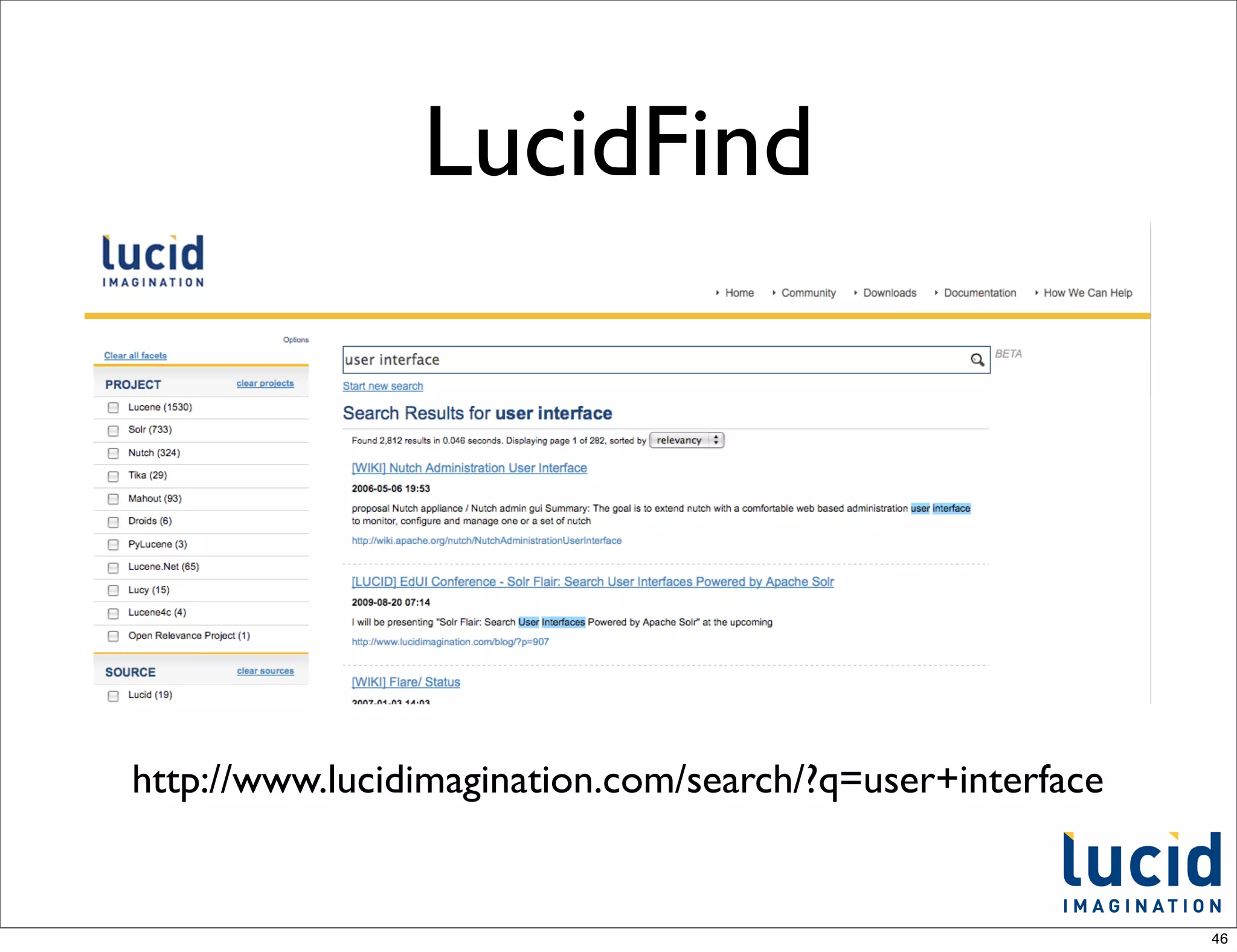


This document provides an introduction to Apache Solr, an open-source enterprise search platform built on Apache Lucene. It discusses how Solr indexes content, processes search queries, and returns results with features like faceting, spellchecking, and scaling. The document also outlines how Solr works, how to configure and use it, and examples of large companies that employ Solr for search.






























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

