Downloaded 122 times










![Query
INFO: [core1] webapp=/solr path=/admin/ping params={}
status=0 QTime=2
Apr 23, 2012 5:42:46 PM org.apache.solr.core.SolrCore execute
INFO: [core1] webapp=/solr path=/select
params={wt=json&rows=100&json.nl=map&start=0&q=searchKey
word:ipad2} hits=48 status=0 QTime=0](https://image.slidesharecdn.com/solr-120424220529-phpapp01/75/Solr-18-2048.jpg)
![Query
INFO: [] webapp=/solr path=/select
params={wt=json&rows=20&json.nl=map&start=0&sort
=volume+desc&q=CId:50011744+AND+price:
[100+TO+*]} hits=1547 status=0 QTime=41
q=CId:50011744+AND+price:[100+TO+*]
sort=volume+desc
start=0
rows=20
hits=1547 status=0 QTime=41](https://image.slidesharecdn.com/solr-120424220529-phpapp01/75/Solr-19-2048.jpg)
![Query
q - 查询字符串,必需
fl - 指定返回那些字段内容,用逗号或空格分隔多个。
start - 返回第一条记录在完整找到结果中的偏移位置, 0 开始,一般分页用
。
rows - 指定返回结果最多有多少条记录,配合 start 来实现分页。
sort - 排序,格式: sort=<field name>+<desc|asc>[,<field
name>+<desc|asc>]… 。示例:( inStock desc, price asc )表示先
“ inStock” 降序 , 再 “ price” 升序,默认是相关性降序。
wt - (writer type) 指定输出格式,可以有 xml, json, php, phps, 后面 solr
1.3 增加的,要用通知我们,因为默认没有打开。
fq - ( filter query )过滤查询,作用:在 q 查询符合结果中同时是 fq 查询
符合的,例如: q=mm&fq=date_time:[20081001 TO 20091031] ,找关键
字 mm ,并且 date_time 是 20081001 到 20091031 之间的。
More: http://wiki.apache.org/solr/CommonQueryParameters](https://image.slidesharecdn.com/solr-120424220529-phpapp01/75/Solr-20-2048.jpg)










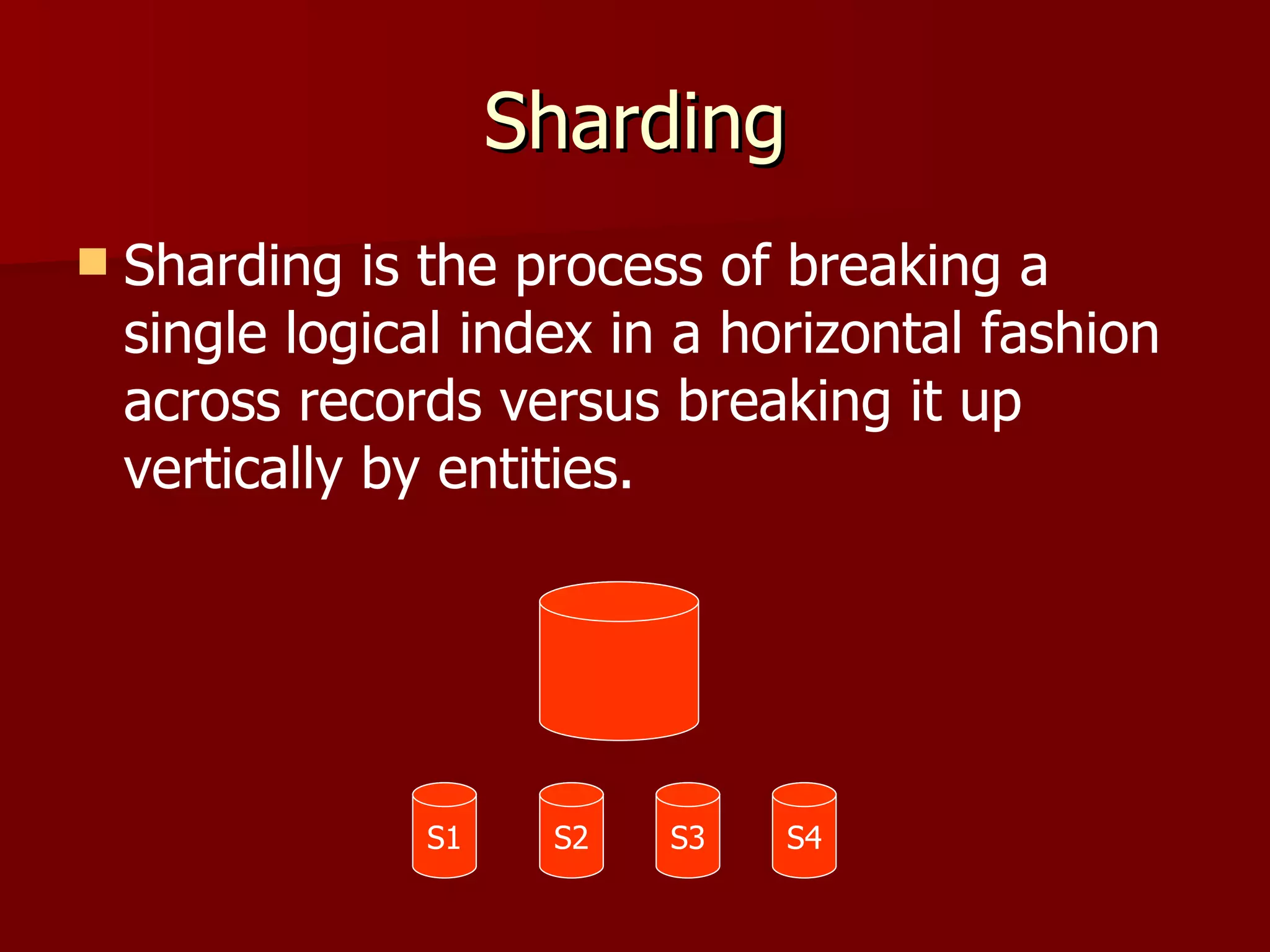
![Sharding-Indexing
SHARDS =
['http://server1:8983/solr/',
'http://server2:8983/solr/']
unique_id = document[:id]
if unique_id.hash % SHARDS.size == local_thread_id
# index to shard
end](https://image.slidesharecdn.com/solr-120424220529-phpapp01/75/Solr-40-2048.jpg)

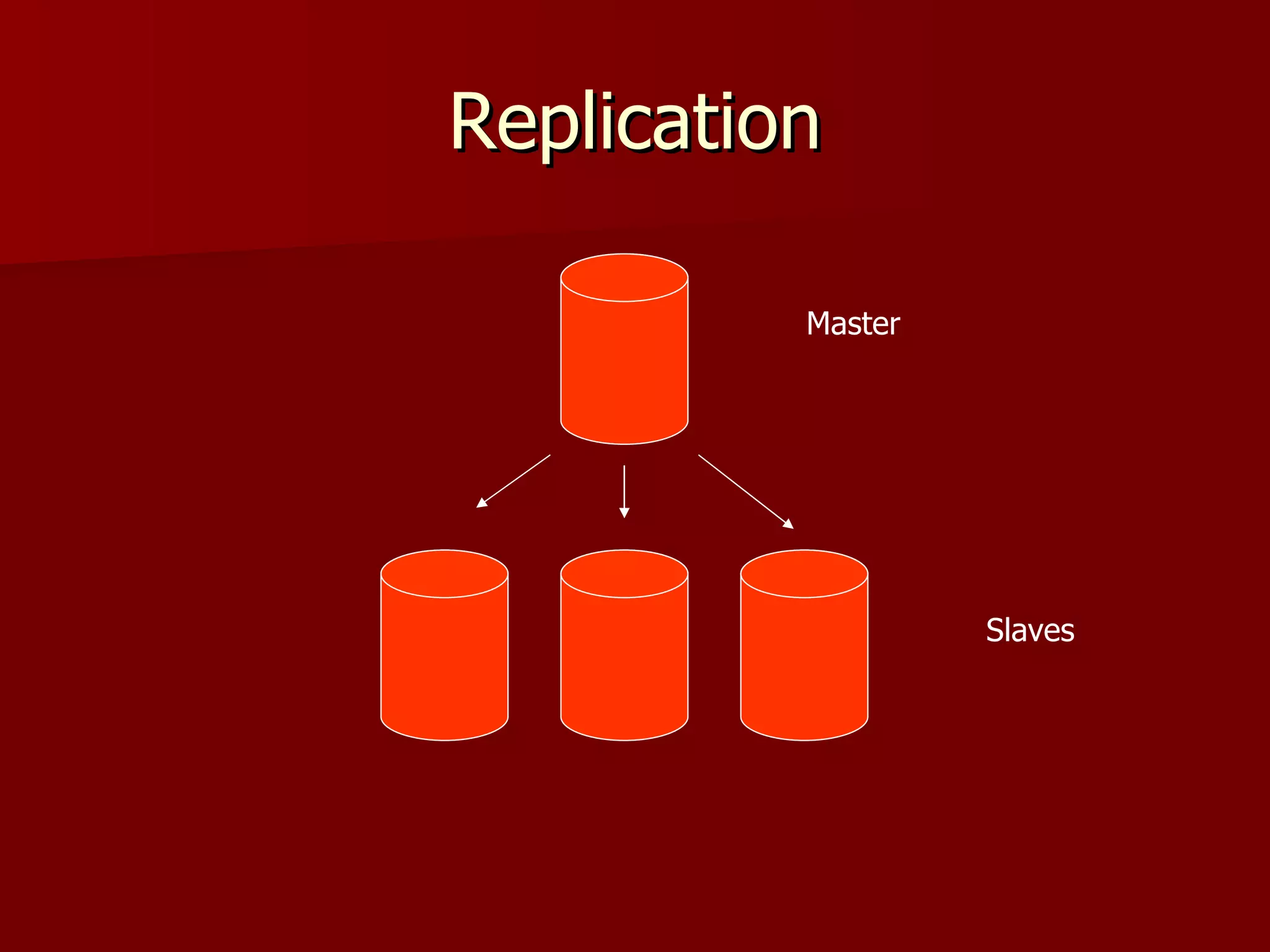
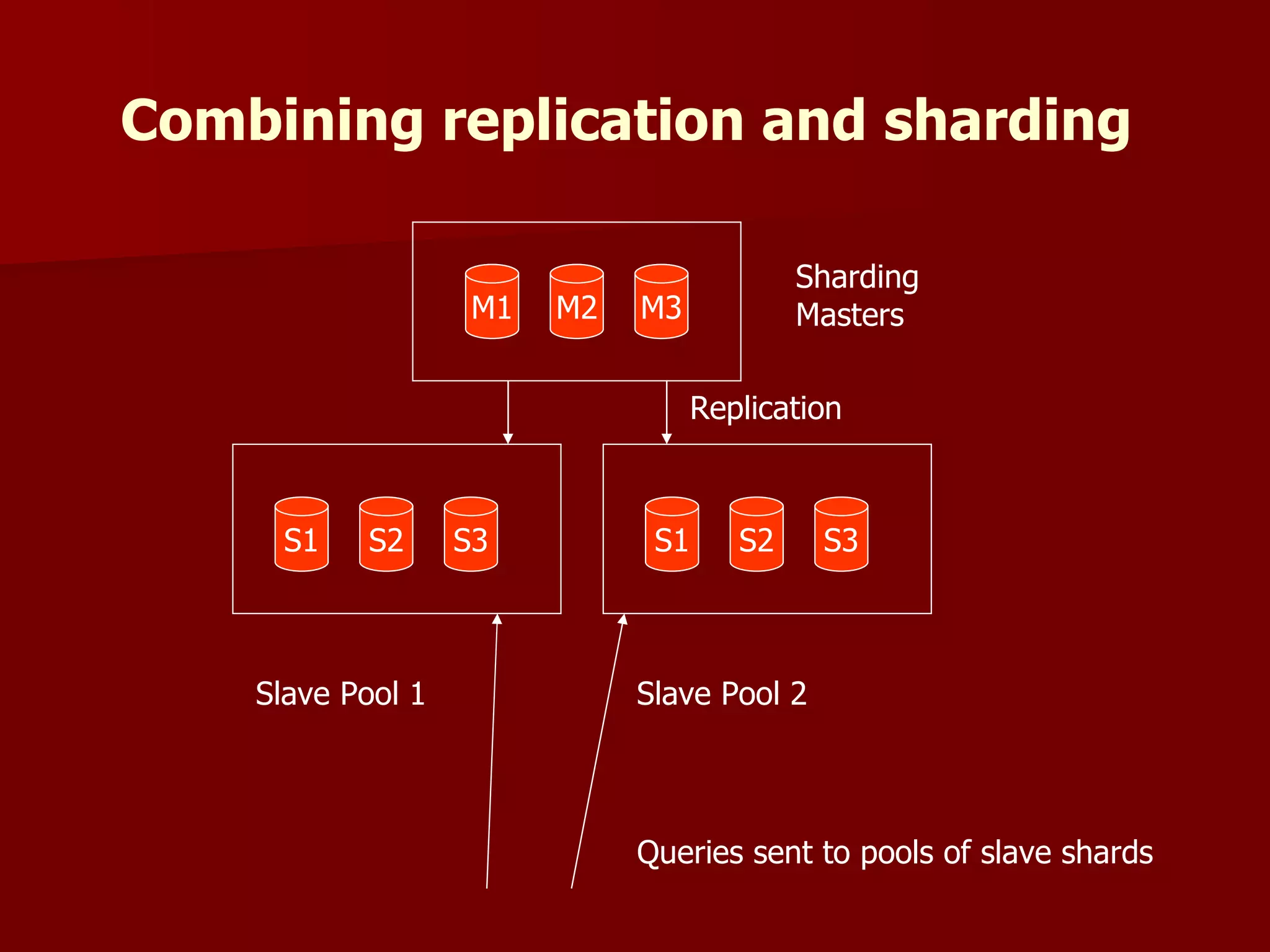
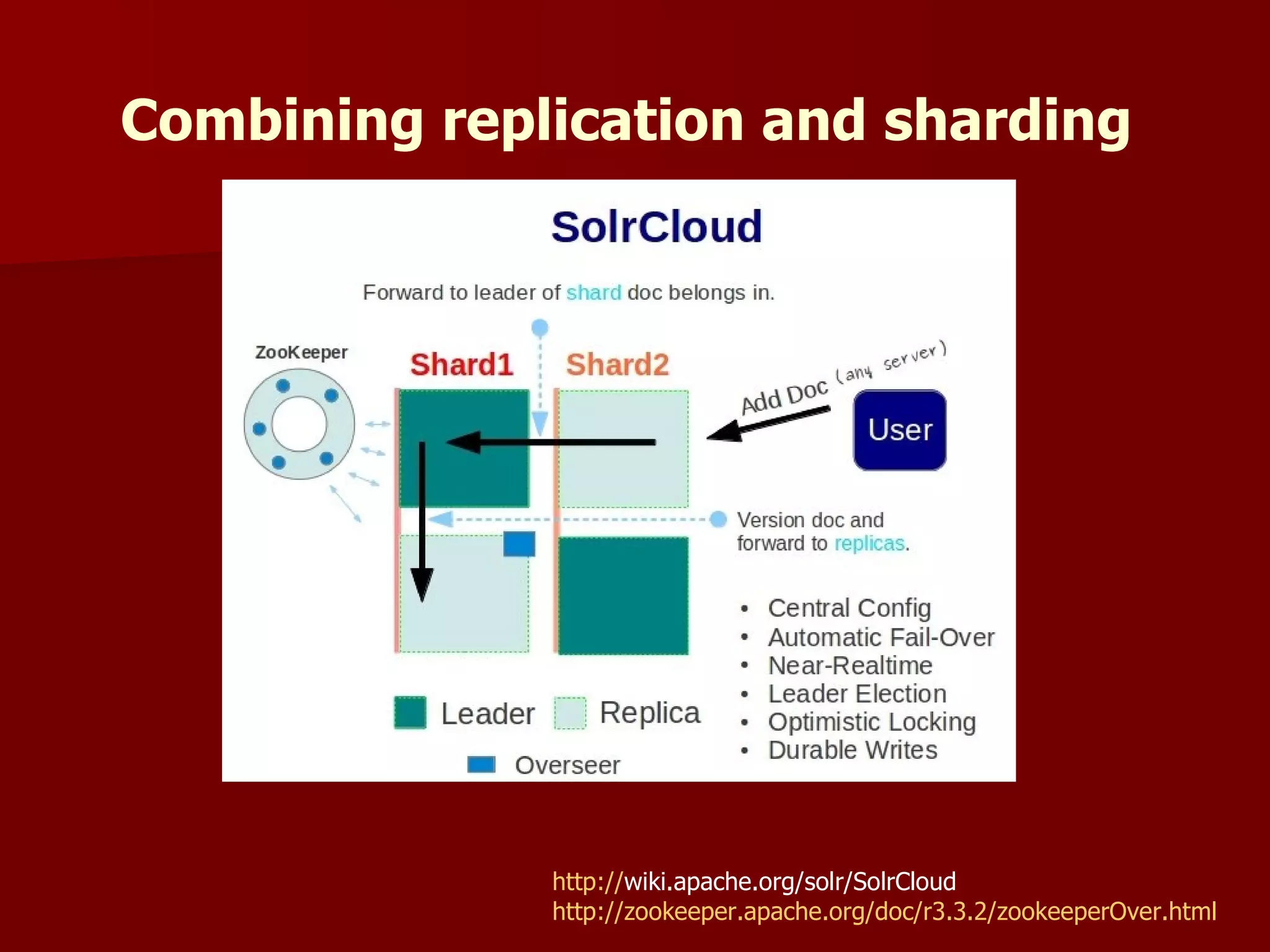





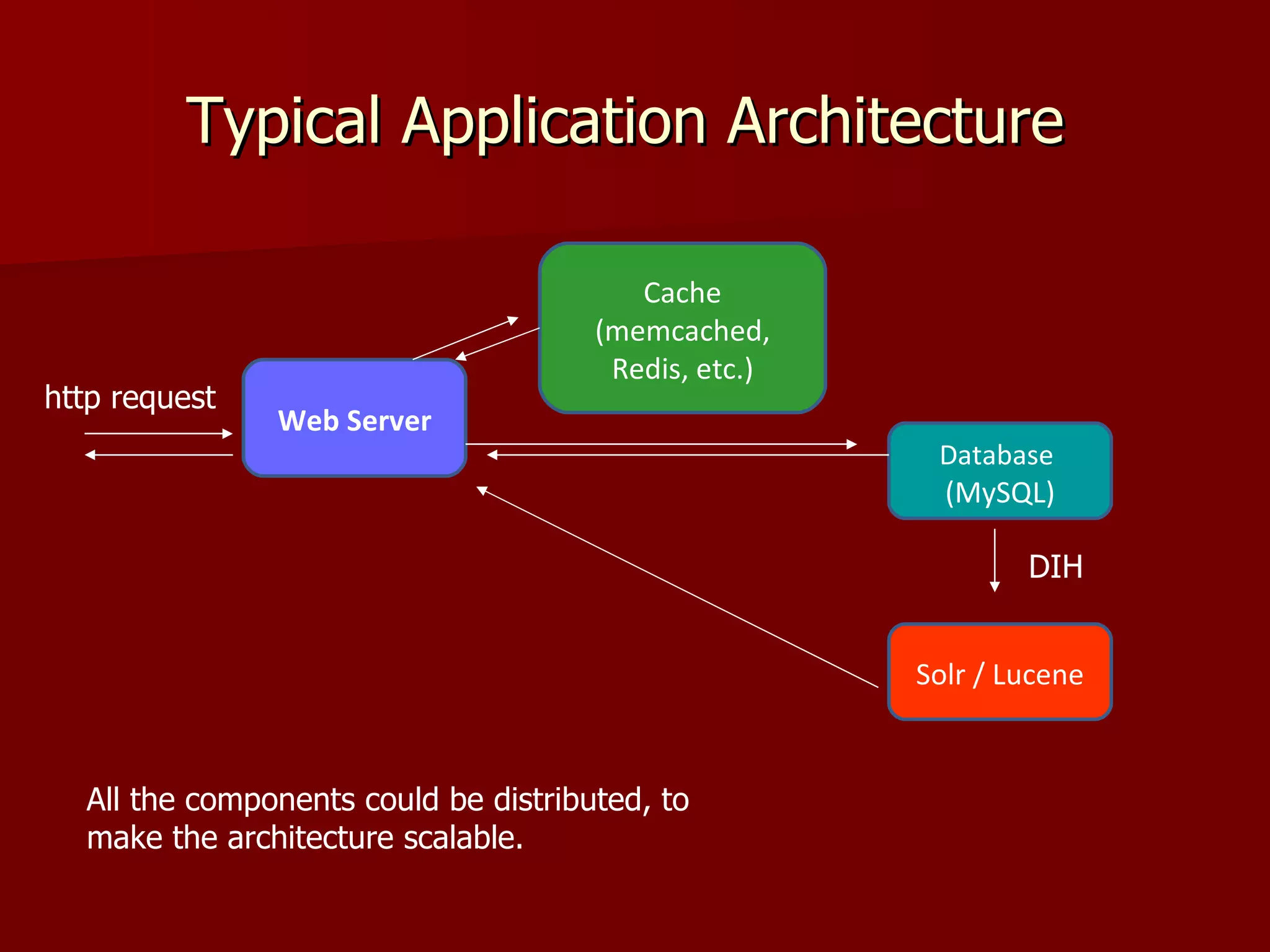
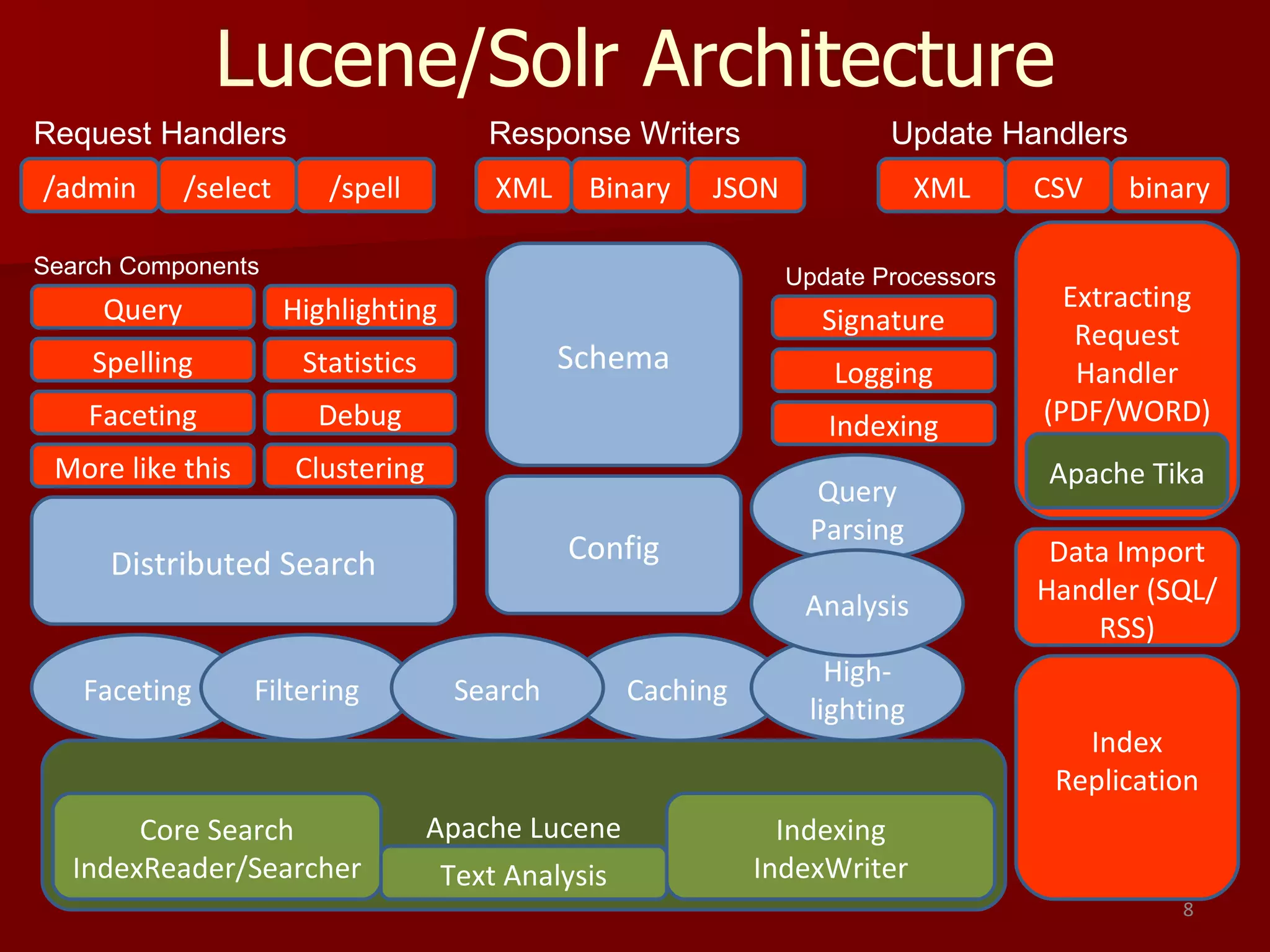
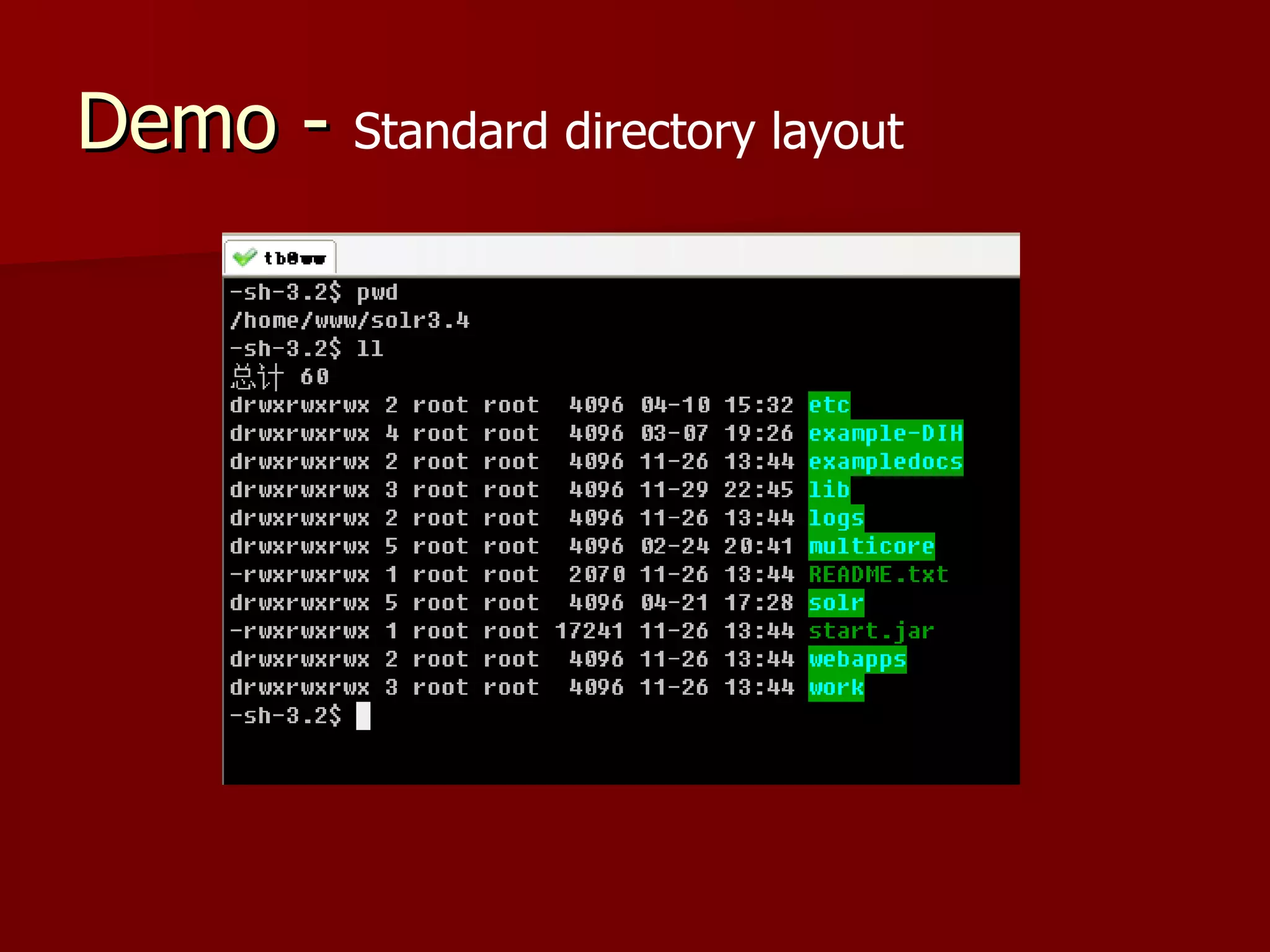
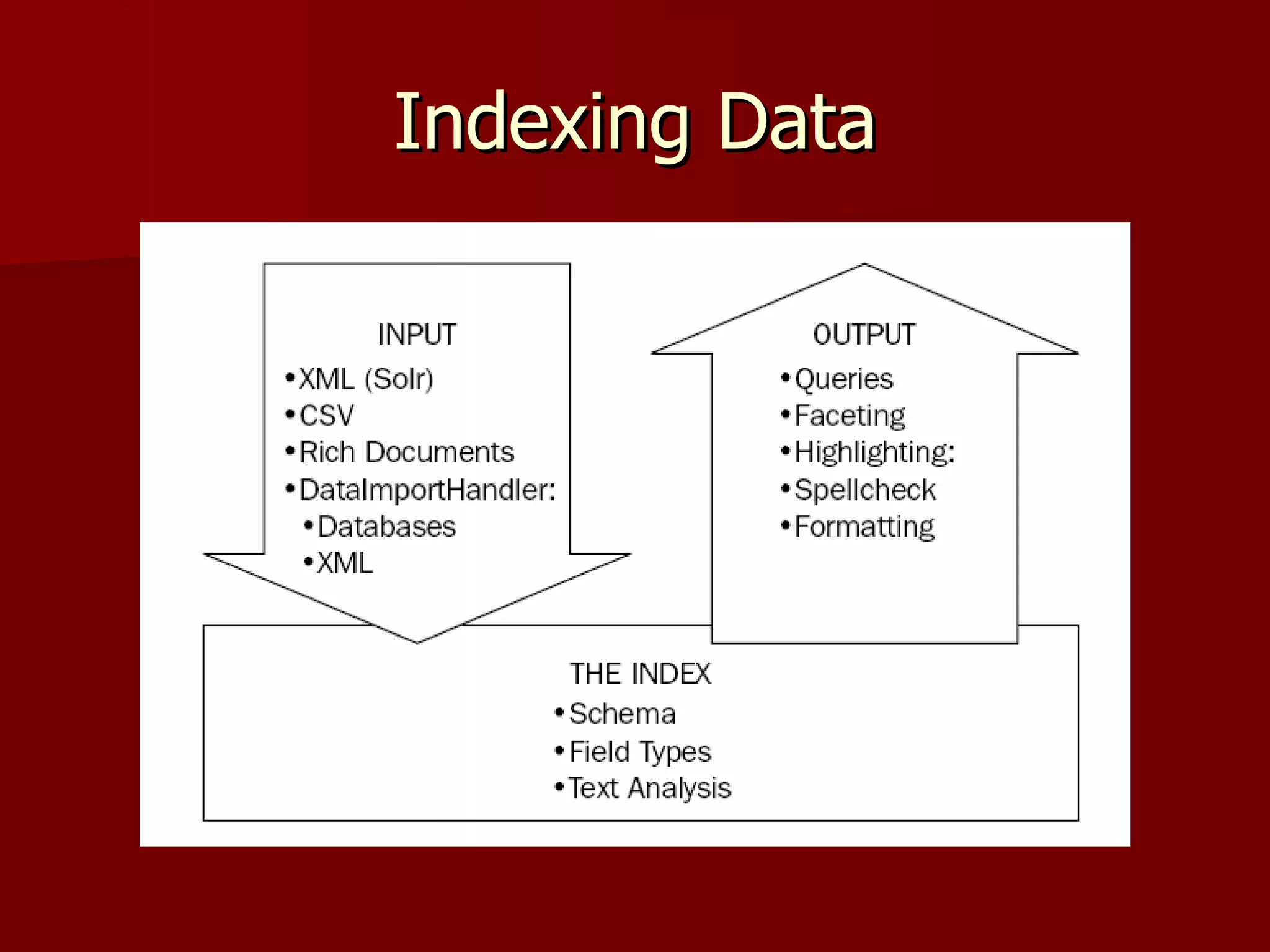
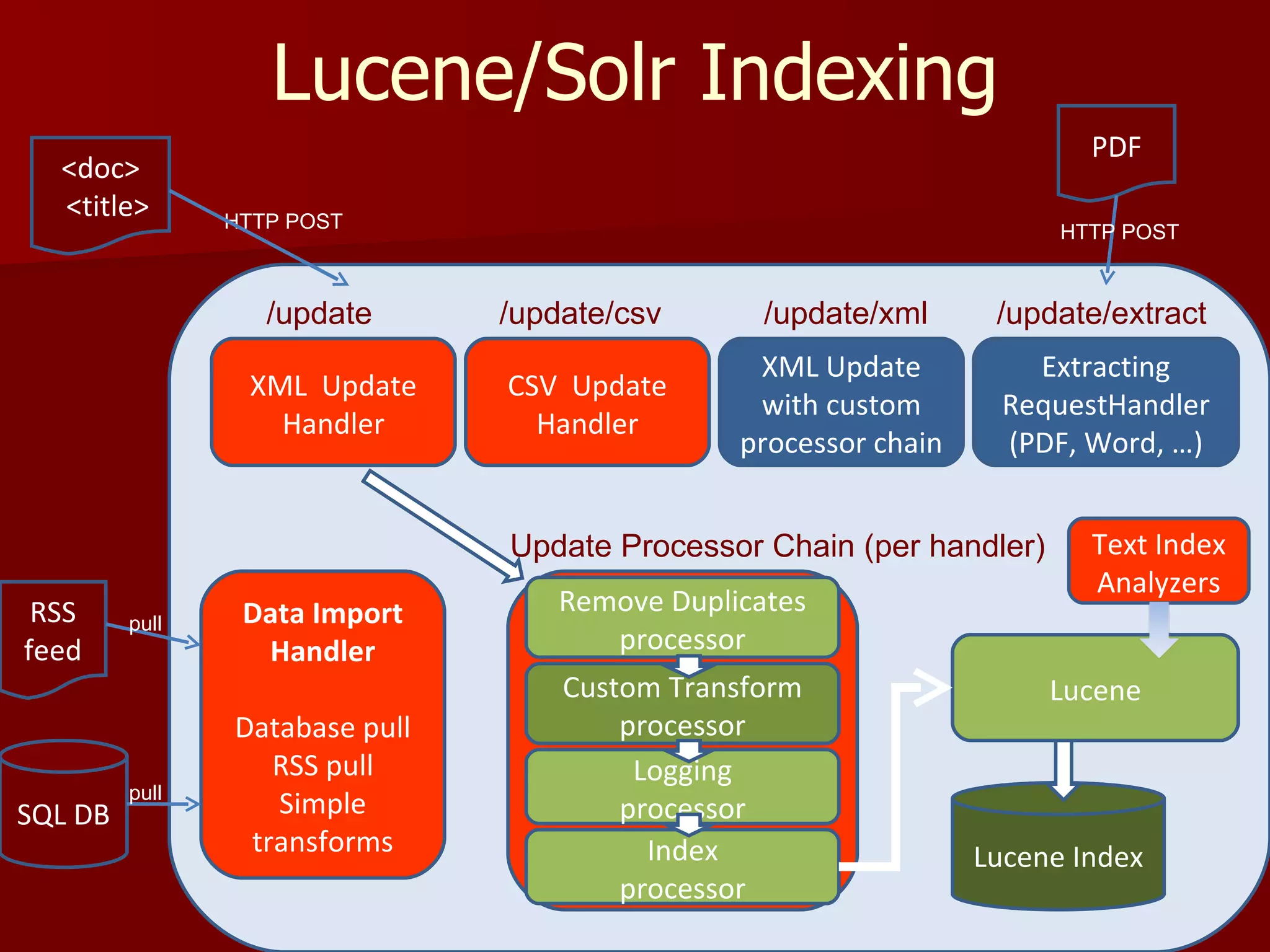
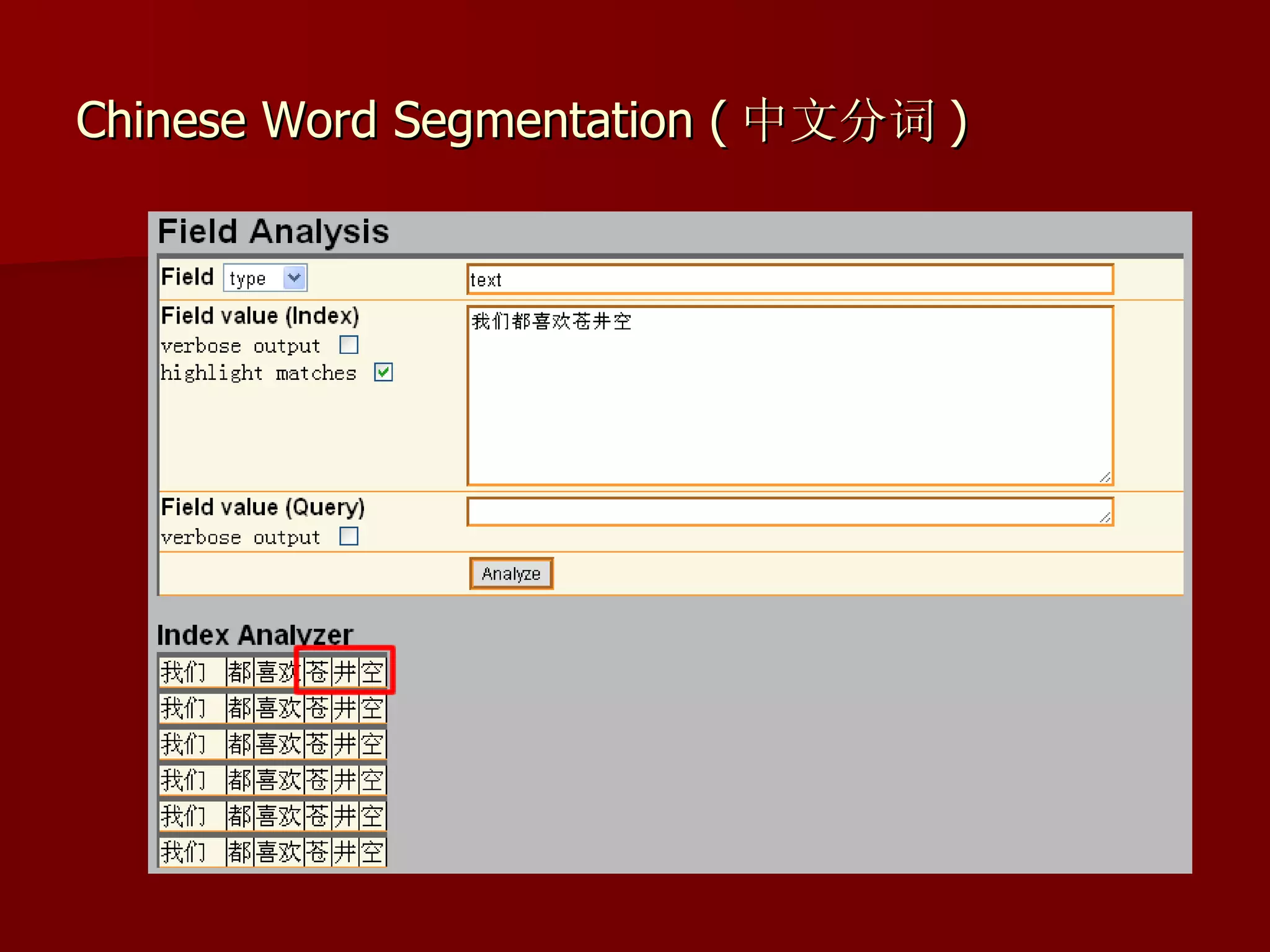
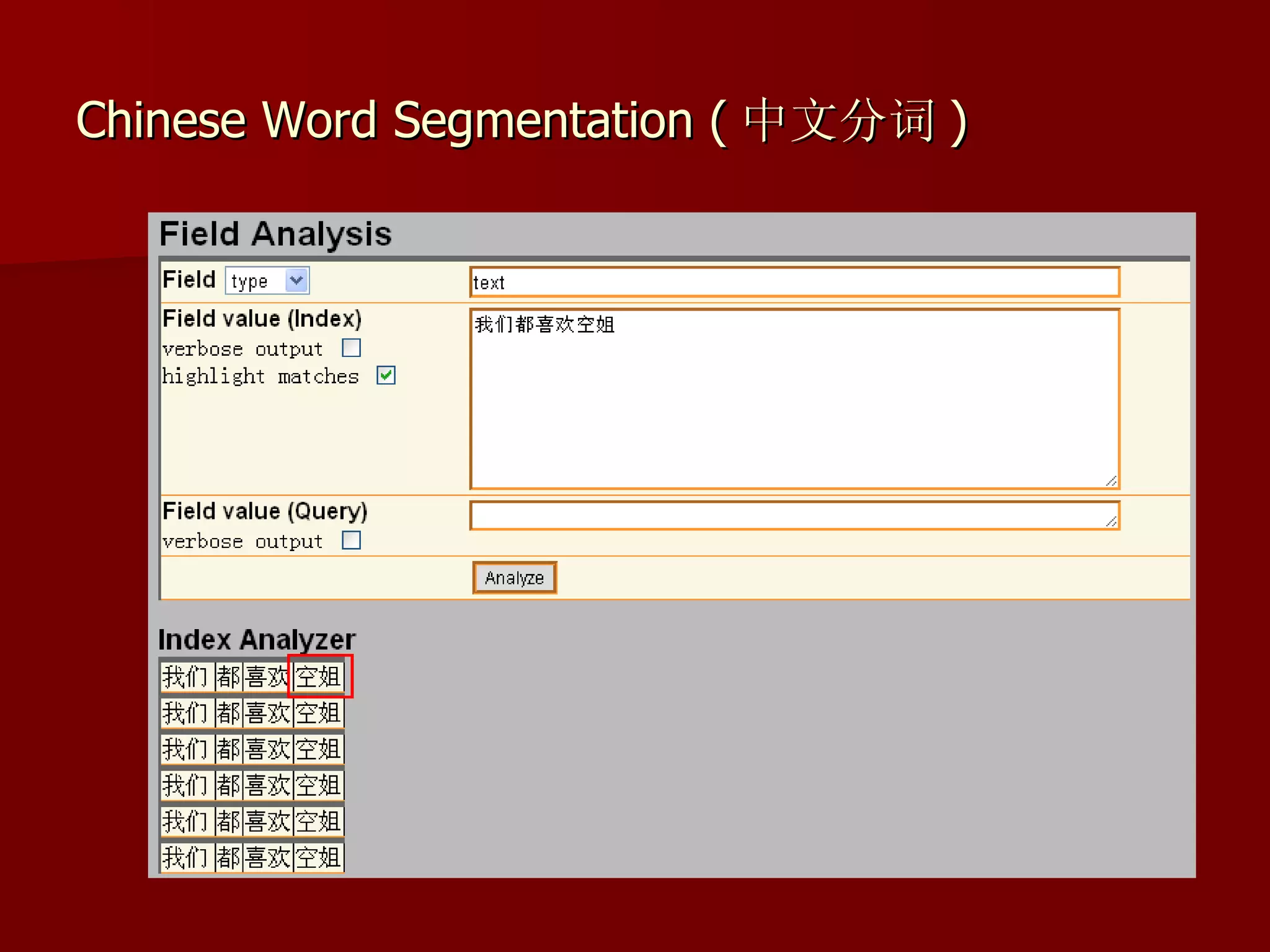
Solr is an open source enterprise search platform built on Apache Lucene. It provides powerful full-text search, hit highlighting, faceted search, dynamic clustering, database integration, and rich document (e.g., word, pdf) handling. Solr powers the search capabilities of many large websites and is highly scalable, fault tolerant, and easy to use.




















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














