Download as PDF, PPTX
























![MORPHLINES EXAMPLE CONFIG
Example Input
<164>Feb 4 10:46:14 syslog sshd[607]: listening on 0.0.0.0 po
Output Record
syslog_pri:164
syslog_timestamp:Feb 4 10:46:14
syslog_hostname:syslog
syslog_program:sshd
syslog_pid:607
syslog_message:listening on 0.0.0.0 port 22.
morphlines : [
{
id : morphline1
importCommands : ["com.cloudera.**", "org.apache.solr.**"]
commands : [
{ readLine {} }
{
grok {
dictionaryFiles : [/tmp/grok-dictionaries]
expressions : {
message : """<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %
{DATA:syslog_program}(?:[%{POSINT:syslog_pid}])?: %{GREEDYDATA:syslog_message}"""
}
}
}
{ loadSolr {} }
]
}](https://image.slidesharecdn.com/solrhadoop-131118140701-phpapp02/85/The-First-Class-Integration-of-Solr-with-Hadoop-32-320.jpg)



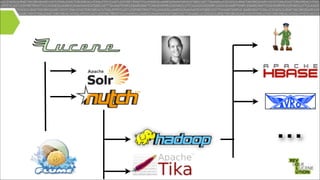
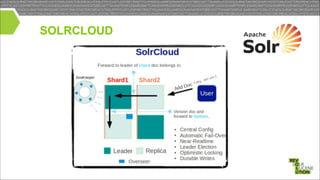
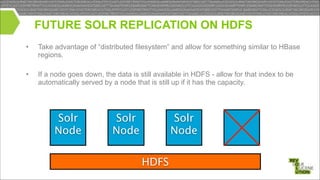
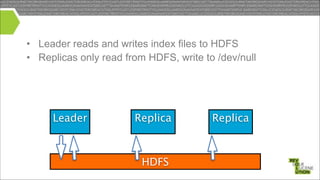
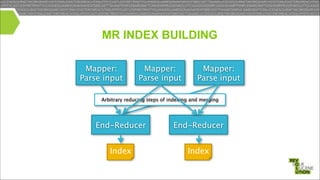
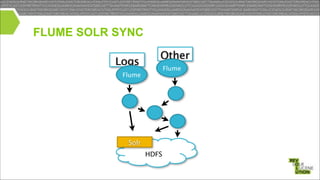
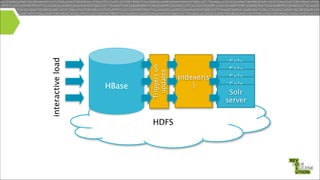
Mark Miller, a Cloudera employee and Lucene/Solr committer, discusses the integration of Solr with Hadoop, focusing on how Solr operates efficiently with Hadoop's HDFS for scaling, replication, and indexing. The document highlights the collaborative efforts to create high-quality integrations between these systems, emphasizing features like SolrCloud, MapReduce index building, and Flume for data synchronization. Future plans include enhancing Solr replication capabilities on HDFS and improving the overall usability and performance of the system.






















































































