






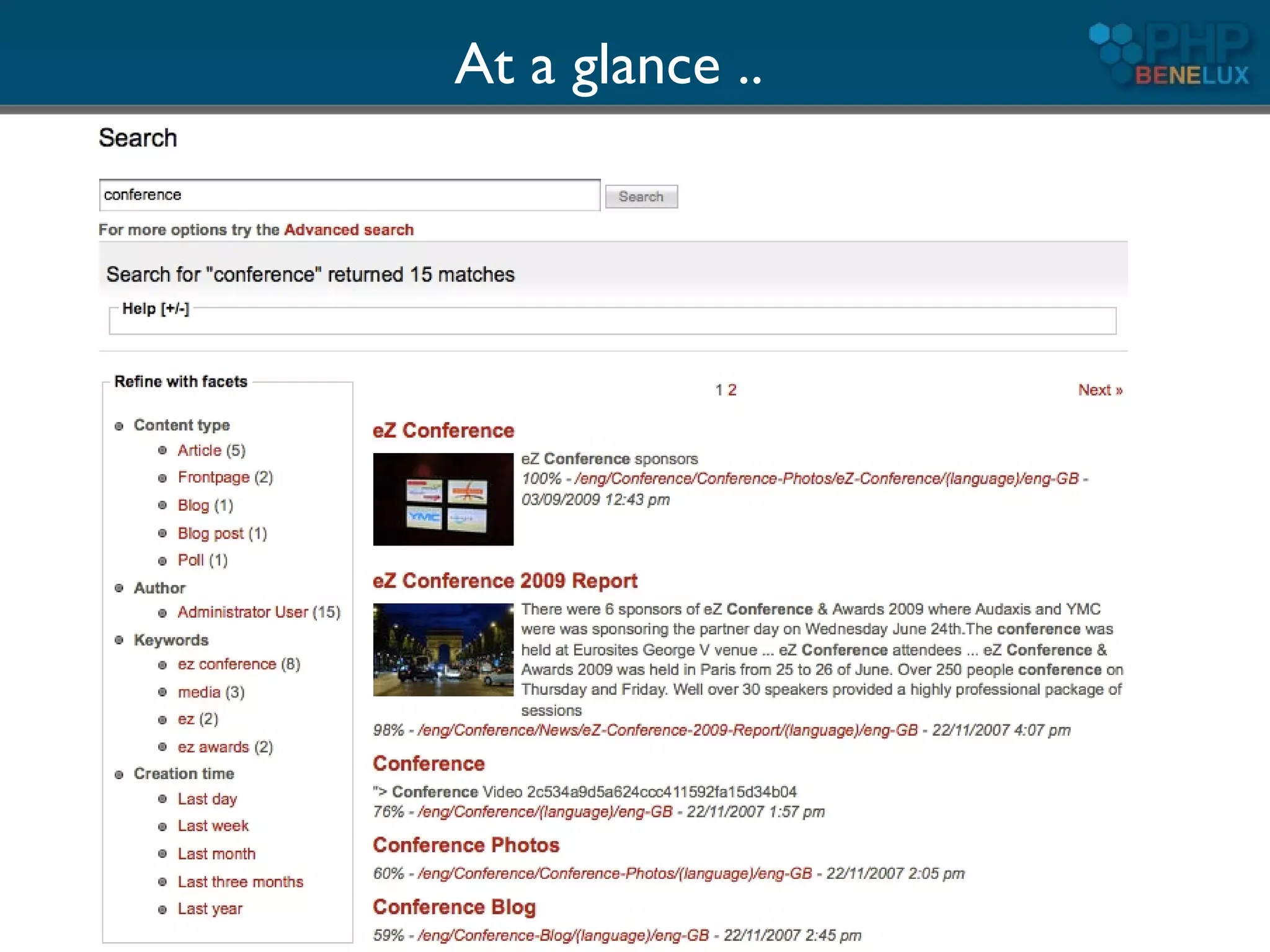



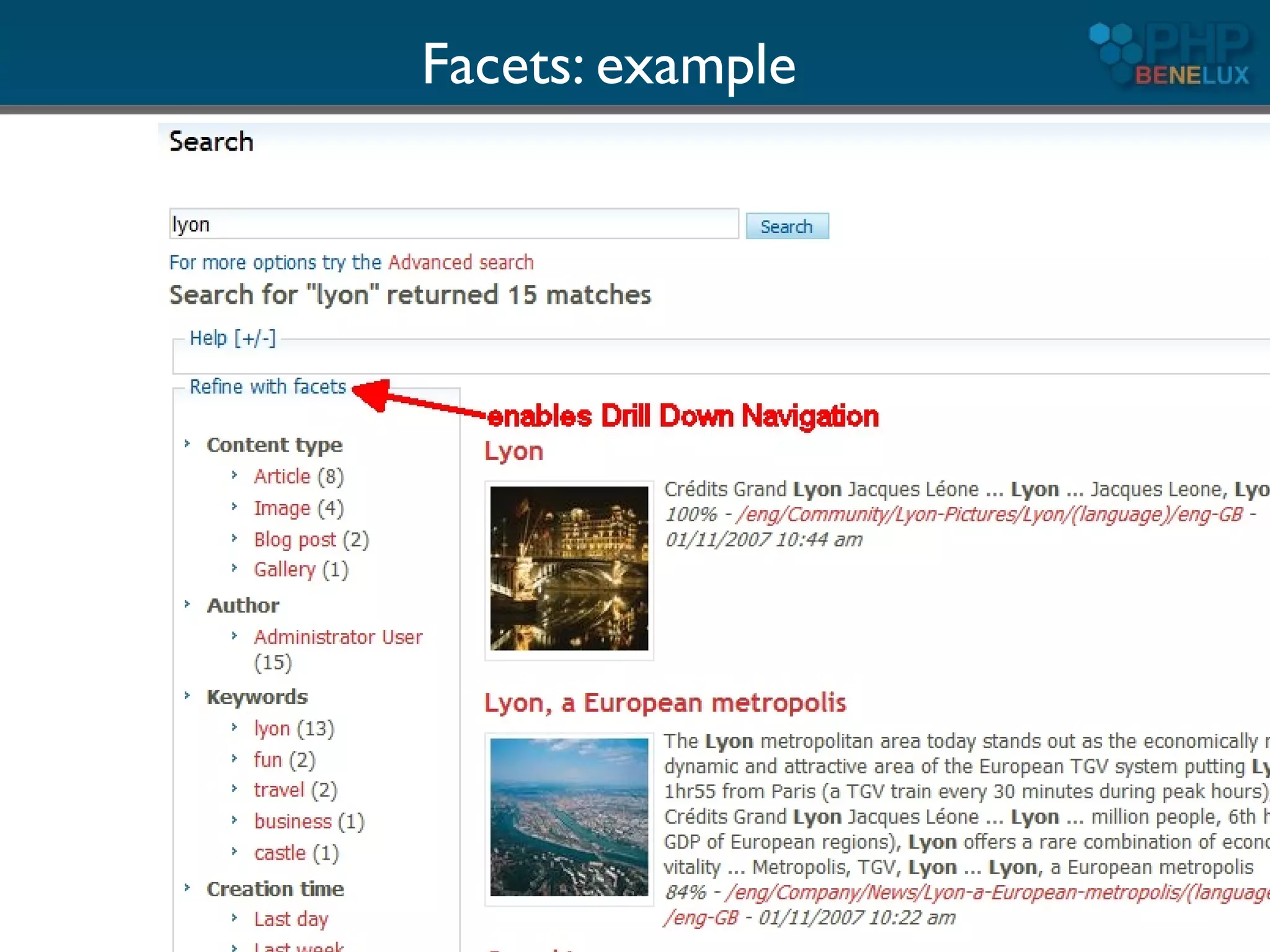

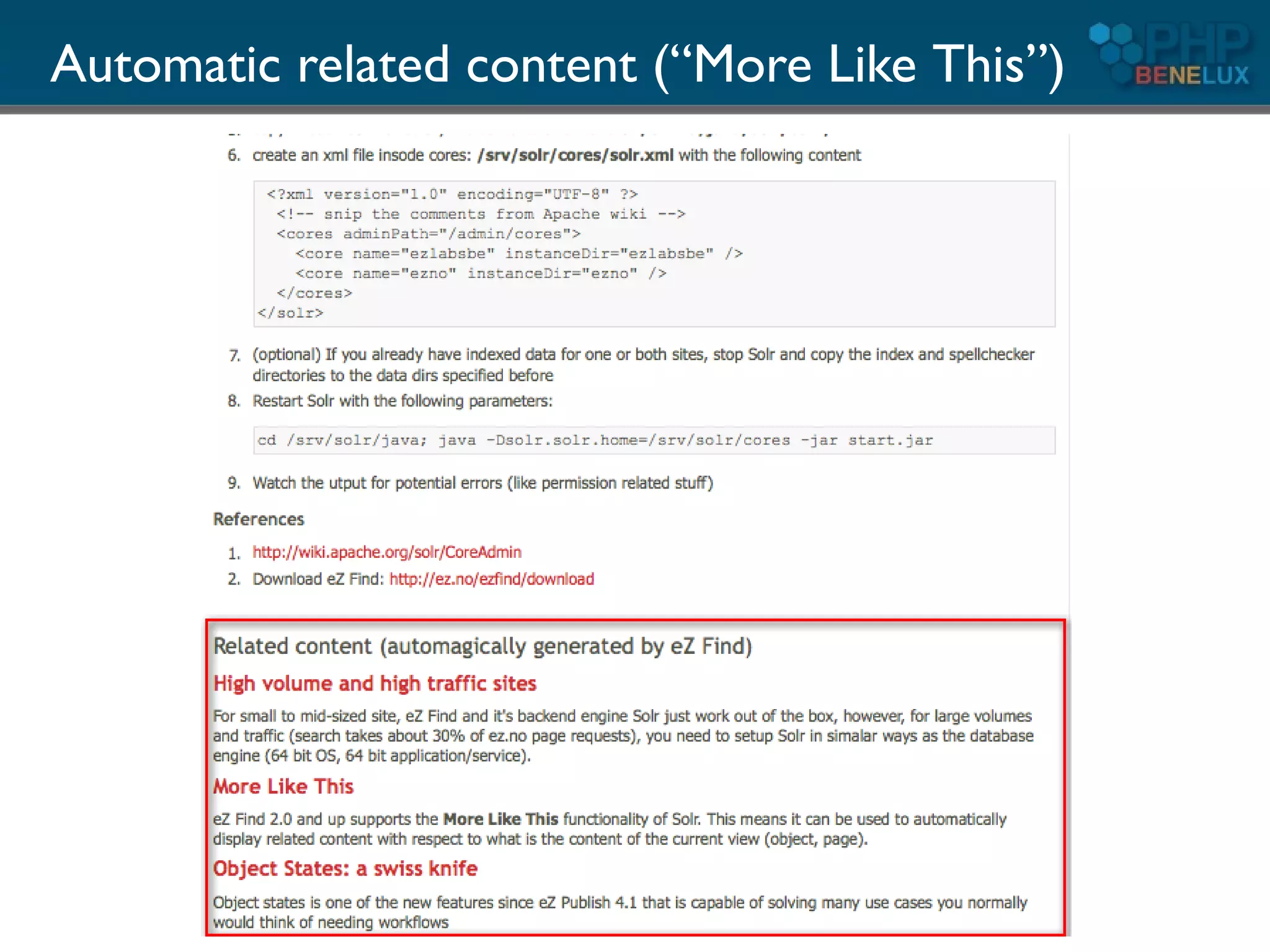






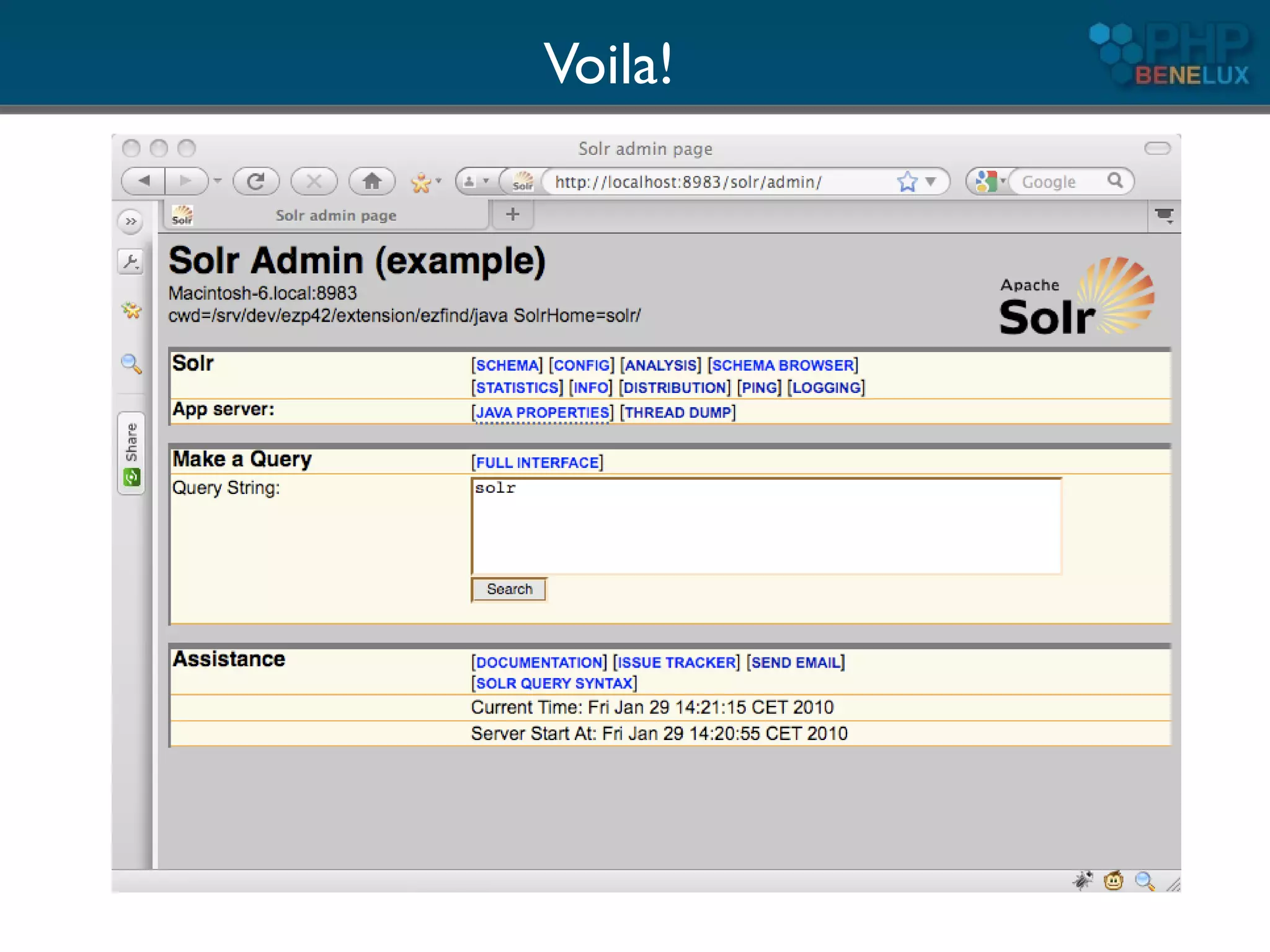




























The document provides an overview of utilizing Apache Solr search with PHP, detailing its features, installation steps, and integration with PHP applications. It covers Solr's capabilities, including full-text search, relevancy ranking, and analysis of text, as well as backend setup and schema configuration with examples. Additionally, it presents tips for enhancing performance, multilingual support, and resources for further exploration.






































![Sed petrolgy[1]](https://cdn.slidesharecdn.com/ss_thumbnails/sedpetrolgy1-150125210722-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
















































