Download as PDF, PPTX






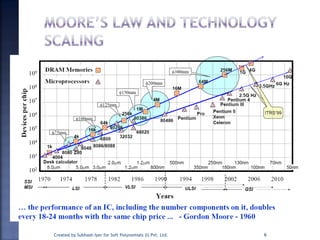
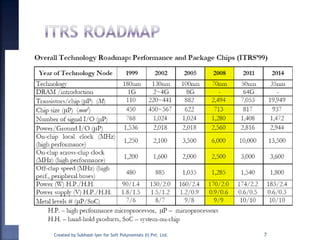







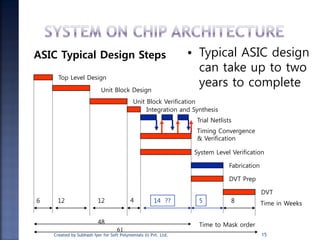
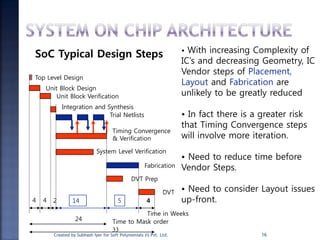




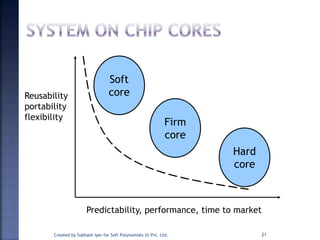

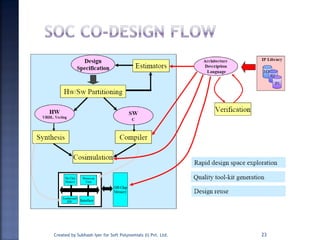

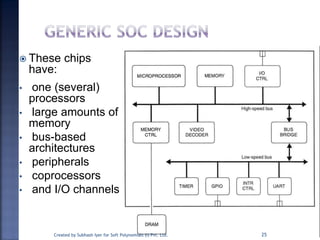






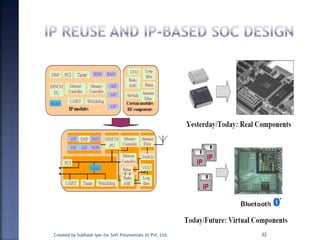




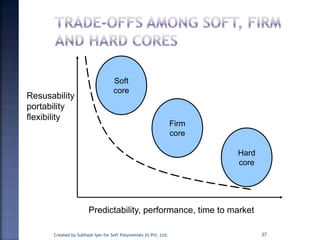





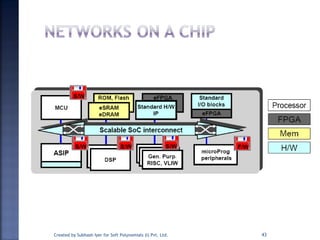
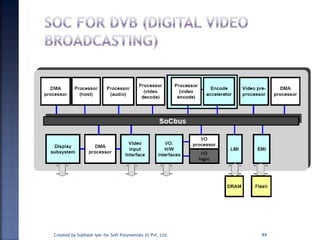
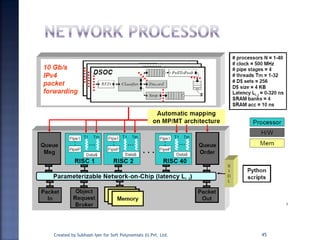






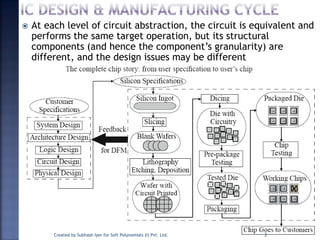


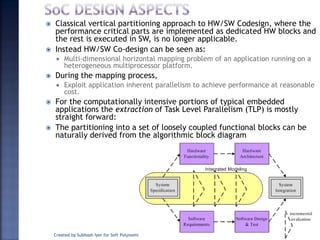

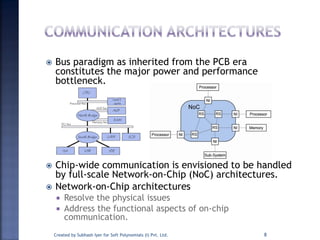




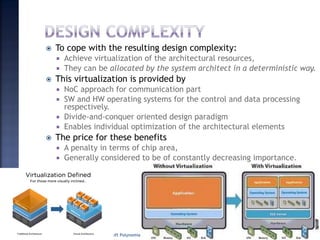



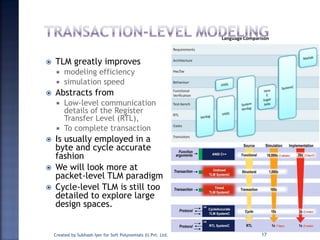






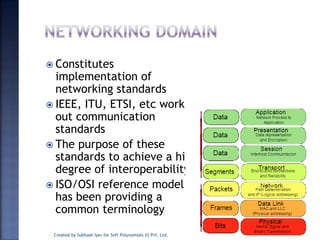




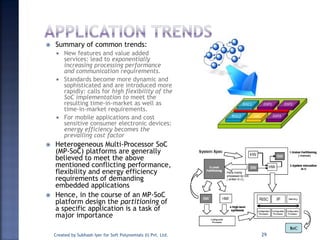

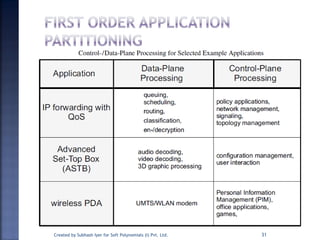
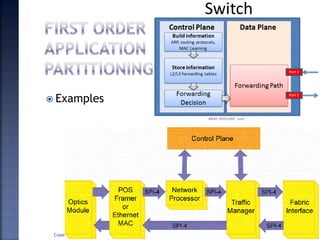







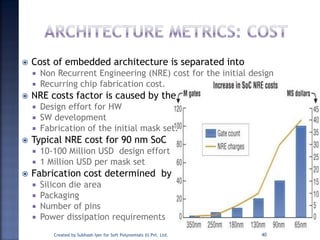
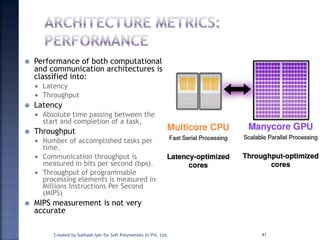




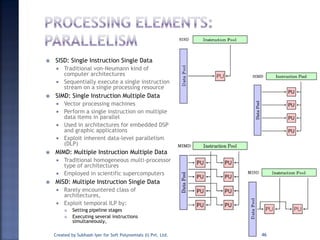



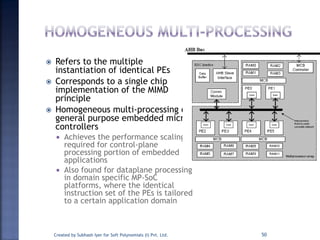


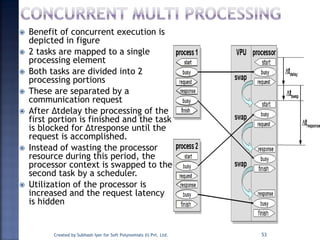


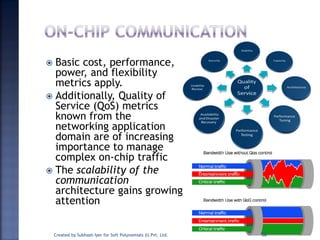

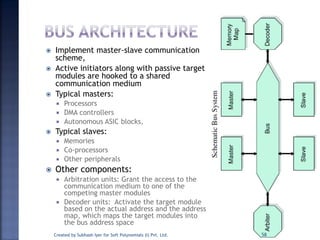

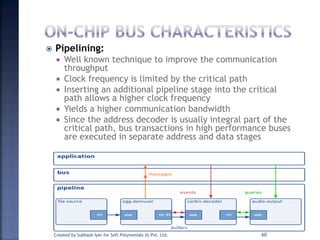
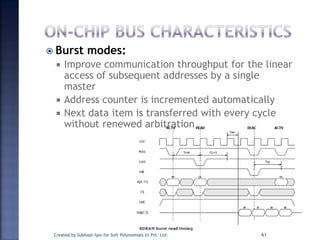



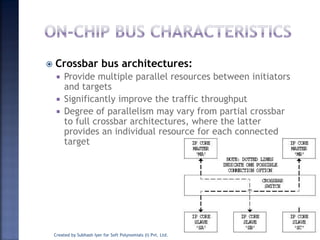
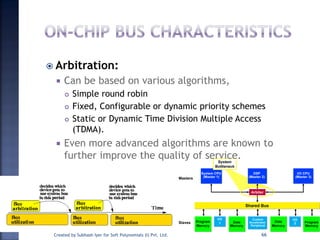




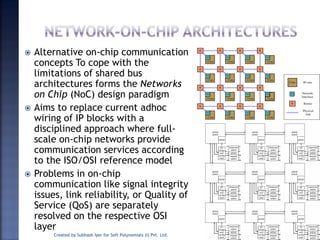
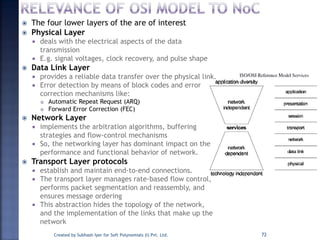
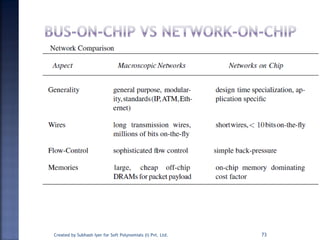

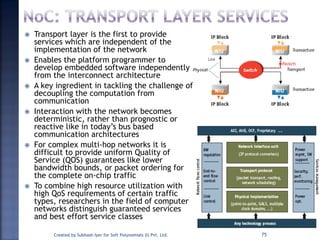




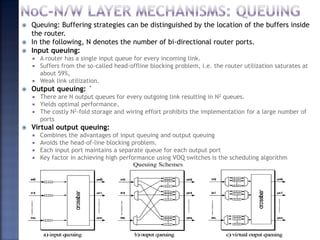






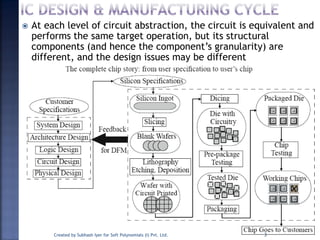
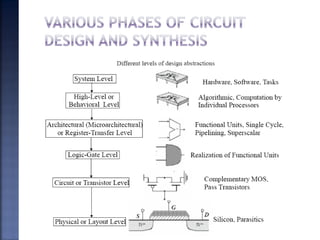


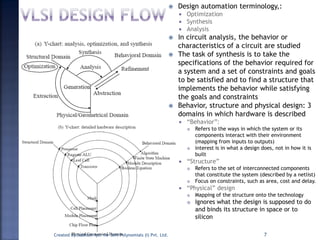
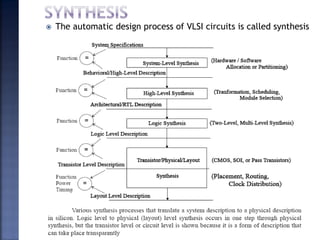



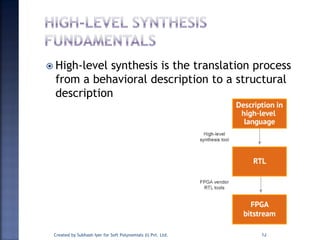
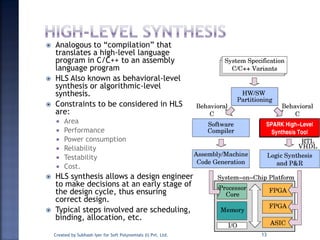

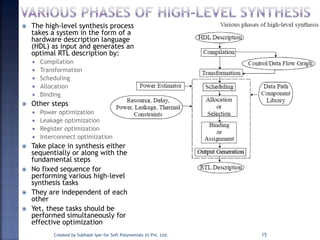






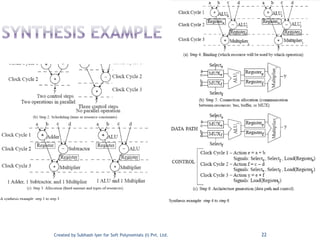







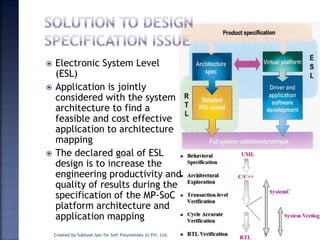
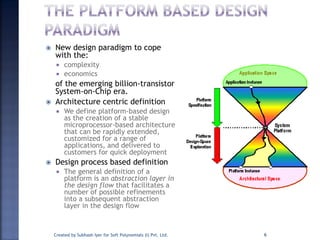








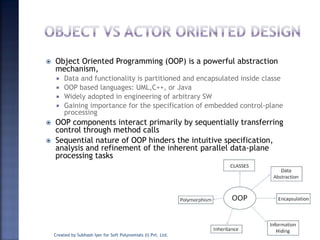
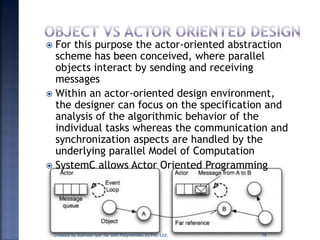






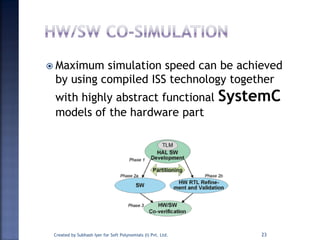







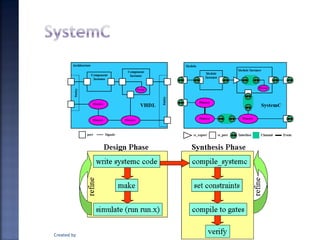
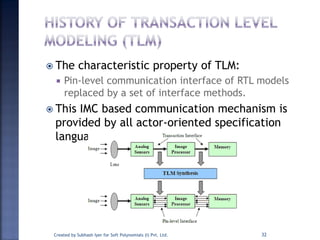










The document discusses System on Chip (SoC) design. It explains that advances in VLSI technology now allow millions of transistors to be integrated onto a single chip, enabling various components that were previously on a printed circuit board to be integrated onto a single die. This has led to the development of SoC design, where custom logic, processors, memory and I/O interfaces are implemented on the same chip. The document discusses some key characteristics and applications of SoCs.















































